









Scrapy简介
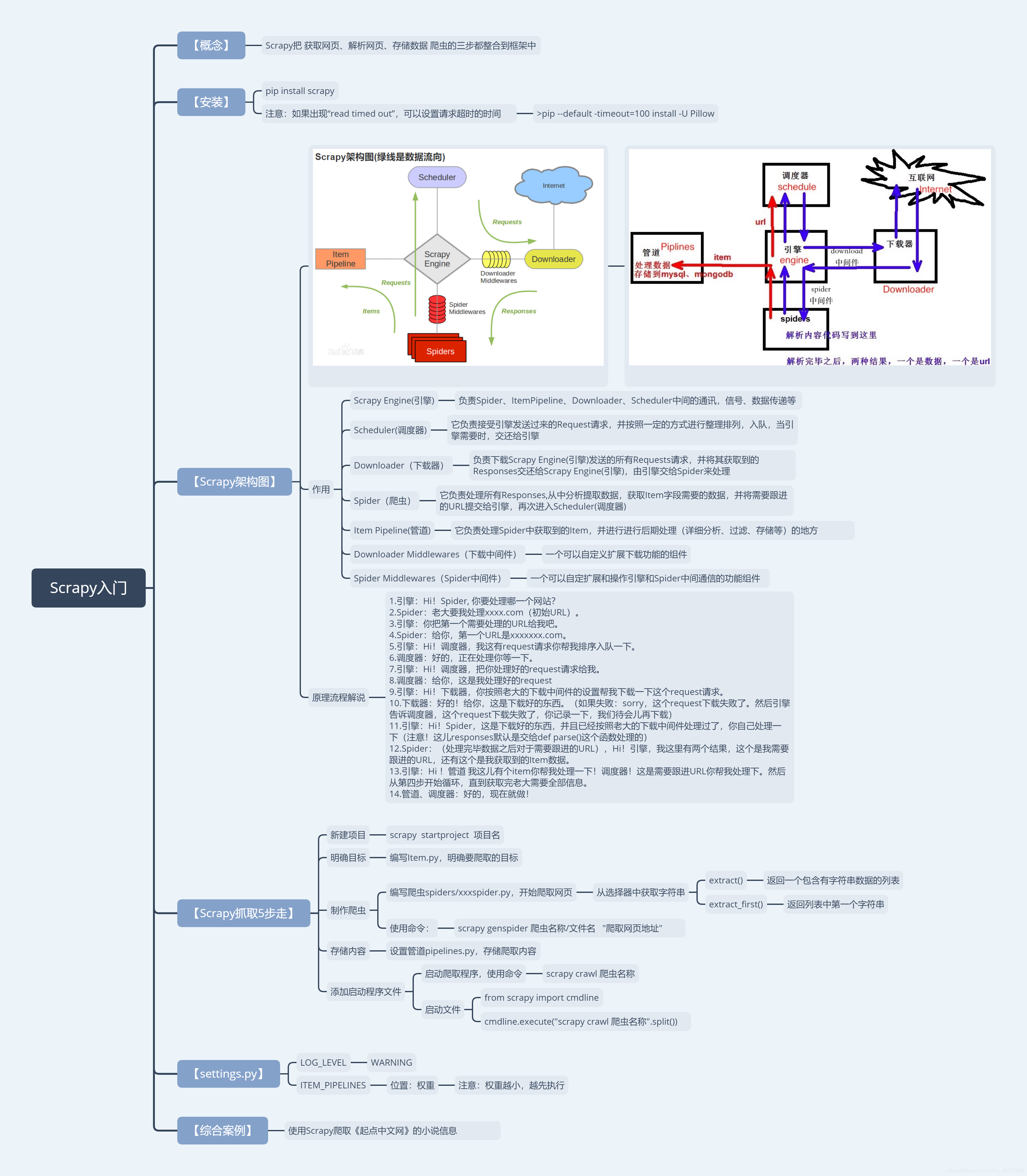
Scrapy主要包括了以下组件:()
引擎(ScrapyEngine)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
安装scrapy:pip install scrapy
如果下载超时出现read timed ot,那么就执行pip --default -timeout=100 install -U Pillow
入门案例
首先安装scrapy:pip install scrapy
创建项目命令:scrapy startproject 项目名
创建好后我们用PyCharm打开我们的项目,start文件是我们自己加的,用来启动项目的
start.py
from scrapy import cmdline
cmdline.execute("scrapy crawl xs".split())
这是最终项目目录
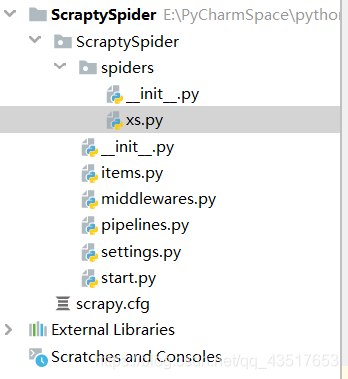
然后我来解释一下今天要用到的配置文件
settings就是你的一些基本配置:UA、header这些
pipelines:管道,定义你如何存放数据的方法
item:声明你需要存储数据的属性,比如一本书有:书名、作者价格等等,就是在这个里面定义
然后我们写爬取代码就是在spiders里面具体写.py文件
然后我们开始写案例,要执行的命令都能在Terminal这个窗口执行,当然你也能在cmd执行
然后我们创建一个scrapy爬取文件:scrapy genspider 文件名 “爬取网址(不需要www)”
当然你也可以直接创建py文件,它就不会帮你生成一些东西

下面我就直接上我案例的代码了
items.py
import scrapy
class ScraptyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
我们在用管道存储数据的时候,需要在settings里面开启存储的优先级,值越小优先级越大
把这个注释给放开
ITEM_PIPELINES = {
'ScraptySpider.pipelines.ScraptyspiderPipeline': 300,
}
pipelines.py
import csv
class ScraptyspiderPipeline(object):
def __init__(self):
self.f = open("起点中文网.csv", "w", newline="")
self.writer = csv.writer(self.f)
self.writer.writerow(["书名", "作者", "简介"])
def process_item(self, item, spider):
# 保存到csv文件中
name = item["name"]
author = item["author"]
content = item["content"]
self.writer.writerow([name, author, content])
return item
xs.py
"""
爬取起点小说
"""
import scrapy
from ScraptySpider.items import ScraptyspiderItem
class XsSpider(scrapy.Spider):
name = "xs"
allowed_domains = ['qidian.com']
start_urls = ['https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=1']
def parse(self, response):
# 获取到网页返回的数据
# print(response.body.decode("UTF-8"))
# 解析网页数据 XPath
# li_list = response.xpath("//ul[contains(@class,'all-img-list')]/li")
li_list = response.xpath("/html/body/div[1]/div[5]/div[2]/div[2]/div/ul/li")
for li in li_list:
item = ScraptyspiderItem()
name = li.xpath(".//div[@class='book-mid-info']/h4/a/text()").extract_first()
author = li.xpath(".//div[@class='book-mid-info']/p[@class='author']/a/text()").extract_first()
content = str(li.xpath(".//div[@class='book-mid-info']/p[@class='intro']/text()").extract_first()).strip()
# copy的xpath路径
# name = li.xpath("/html/body/div[1]/div[5]/div[2]/div[2]/div/ul/li[1]/div[2]/h4/a/text()").extract_first()
# author = li.xpath("/html/body/div[1]/div[5]/div[2]/div[2]/div/ul/li[1]/div[2]/p[1]/a[1]/text()").extract_first()
# content = str(li.xpath("/html/body/div[1]/div[5]/div[2]/div[2]/div/ul/li[1]/div[2]/p[2]/text()").extract_first())
print(name)
print(author)
print(content)
item['name'] = name
item['author'] = author
item['content'] = content
yield item
# 获取下一页在超链接
# nextUrl = response.xpath("//*[@id='page-container']/div/ul/li[7]/a").extract_first()
nextUrl = response.xpath("//a[contains(@class,'lbf-pagination-next')]/@href").extract_first()
if nextUrl != "javascript:;":
yield scrapy.Request(url="http:"+nextUrl, callback=self.parse)
最后运行完start.py文件,就把数据拿下来了

并且我们的Excel文件也已经保存了

end…















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











