






ID3 决策树算法(简便)
数据挖掘之ID3决策树算法
在数据挖掘课程中,相对难一点的就是决策树,在这将自己的代码附上
流程
ID3算法就是根据信息增益来选去节点属性的一个过程
作者语言表达能力堪称灾难,因此附加 B站相关 链接
https://www.bilibili.com/video/BV1Cq4y1S7k1/?share_source=copy_web&vd_source=d18d890b799ea5622e279f4146f1a1cc
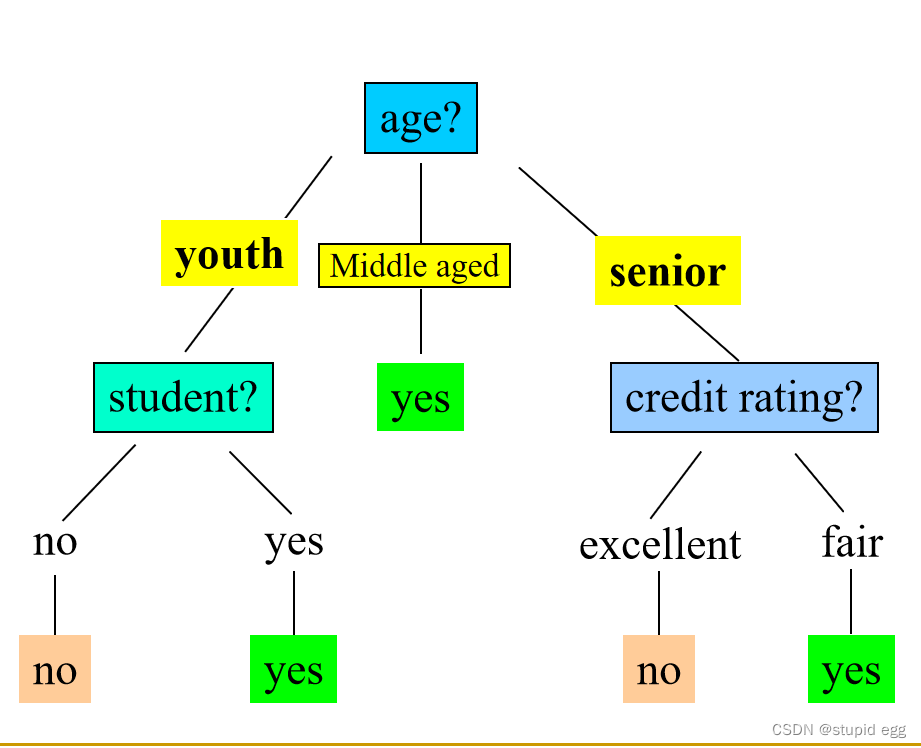
结果展示
数据展示
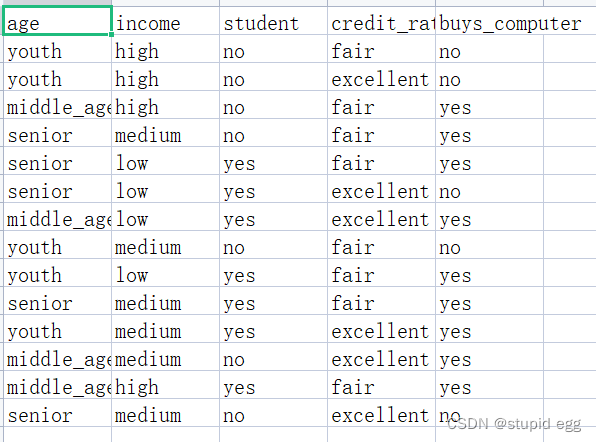
预期分类
实际分类

用字典的形式展示出决策树的构造
代码
下面展示一些 内联代码片。
import csv
import math
# 从csv 文件内读取文件
def csvread(file):
with open(file) as f:
reader = csv.reader(f)
header_row = next(reader)
list = []
for row in reader:
list.append(row)
return list
#获取某个元祖的分类 集合无重复 用于终止循环判断
def fenlei(x,data):
s=set()
for i in data:
s.add(i[x])
return s
# 计算 期望
def zuihouz(data):
n=len(data[0])
s=fenlei(n-1,data)
dict={}
for i in s:
dict[i]=0
j=0 # 获取数据总数
for i in data:
dict[i[n-1]]+=1
j+=1
sum=0
for key in dict:
sum+=-math.log(dict[key]/j,2)*dict[key]/j
return j,sum
#获取最大信息增益
def sumt(x,list=[]): #求出类中一个组
sum=0
z=0
for i in list:
sum+=i
j=0
while j<len(list):
if list[j]==0:
j+=1
continue
z=z-(math.log(list[j]/sum,2)*list[j]/sum)
j+=1
return sum/x*z
def zY(x,data): # x : 总列数 data: 数据
list=[]
n=len(data[0]) # n 表示列数
i=0
while i<n-1: # 一列一列的求
s=fenlei(i,data)
list1=[] #用来存储集合中的签
for a in s:
list1.append(a)
list2=[] # 用来存储个数
for e in s:
list2.append([0,0])
j = 0 # j 为行数
while j<len(data):
b=0
while b<len(list1):
if data[j][i] == list1[b] and data[j][n - 1] == 'yes':
list2[b][0] += 1
elif data[j][i] == list1[b] and data[j][n - 1] == 'no':
list2[b][1] += 1
b += 1
j+=1
i+=1
sum=0
for f in list2:
sum += sumt(x, f)
list.append(sum)
return(list)
def zuidazenyi(x,data):
i=1
max=x-data[0]
j=0
while i<len(data):
y=x-data[i]
if y>max:
j=i
max=y
i+=1
return j # 返回最大增益对应的标签
# 更新子树数据集
def genX(x,value,data): # x: 位置 value : 元祖值 data: 列表
list=[]
for i in data:
if i[x]==value:
temp=i[:x]
temp.extend(i[x+1:])
list.append(temp)
return list
#建树
def creatTree(label,data):
l=len(data[0])-1
s1=fenlei(l,data)
if len(s1)==1:
element=s1.pop()
return element
tree={}
temp={}
llength,shang=zuihouz(data)
list=zY(llength,data)
x=zuidazenyi(shang,list) #获取下标
list2=label[:x] # 更新标签
list2.extend(label[x+1:])
s2=fenlei(x,data)
for a in s2:
list3=genX(x,a,data)
temp[a]=creatTree(list2,list3)
tree[label[x]]=temp
return tree
if __name__=='__main__':
file = '' # 这里输入文件路径
data= csvread(file)
label=['age','income','student','credit_rating']
tree=creatTree(label,data)
print(tree)
PS
作者的代码只在本题目上的验证,并未在其他问题上进行验证,因此准确性大小未知,如有错误,欢迎指正。















 4044
4044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









