






首先了解IO模型
引用链接:
5种IO模型、阻塞IO和非阻塞IO、同步IO和异步IO
关于阻塞:
阻塞其实是针对cpu来说,如果在请求读取数据时,没有数据就让出cpu,进行其他线程的处理,那就相当于把当前线程挂起,也就是阻塞。当如果让cpu轮询访问数据,问”来没来呀,来没来呀“,并不把当前线程进行阻塞,而且当前cpu一直消耗,就像是自旋锁一样,并不挂起当前线程,说不定一会就有数据了呢。线程阻塞再唤醒很消耗资源的,我们也不想要这么做,因此进行非阻塞。
因此阻不阻塞是针对当前线程来讲的。
关于同步:
同步其实是进程间的通信机制,在当前线程来讲同步:双方的动作是经过双方协调的,步调一致的。
异步:双方并不需要协调,都可以随意进行各自的操作。同步IO:用户进程发出IO调用,去获取IO设备数据,双方的数据要经过内核缓冲区同步,完全准备好后,再复制返回到用户进程。而复制返回到用户进程会导致请求进程阻塞,直到I/O操作完成。
异步IO:用户进程发出IO调用,去获取IO设备数据,并不需要同步,内核直接复制到进程,整个过程不导致请求进程阻塞。
其实也就是客户端请求数据,但这边还没有数据,那怎么办呢?有两种方式
- 等呗。只有拿到我想要的数据我才能继续工作。可以通过阻塞或非阻塞的方式获取数据,反正我不管,我只知道我只有获取数据才能继续执行下面的代码。注意,是当前线程的代码
- 不等。直到我要的数据到了,你再返回给我,我进行处理。但其间,我继续执行我之后的代码。
IO多路复用
没啥好说的,绝了
epoll原理详解及epoll反应堆模型


NIO
这里指的是new IO,而不是非阻塞IO
看这里
简单易懂的New IO 的详细讲解
Java NIO?看这一篇就够了!
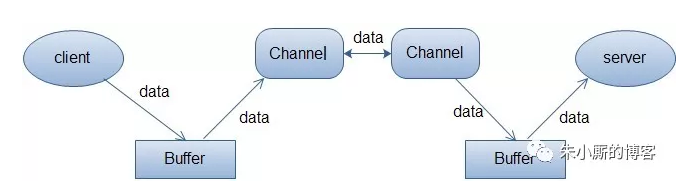
这里其实比较容易迷糊,只知道有Buffer ,channel和selector三个组件。那就先了解这三个组件。
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
传统IO:


需要经过两个缓冲区,并且都是阻塞的IO操作。
看NIO与IO的区别:
-
1.IO面向流,NIO面向缓冲区
Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。 此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。 这就增加了处理过程中的灵活性 -
2.IO是阻塞式的,NIO有非阻塞式的
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞, 所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。
-
3.IO没有选择器,NIO有选择器
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。因为epoll方法其实是linux的函数,而这个selector选择器是Java自带的方法。
public class NewIO {
public static void main(String[] args) {
//MyByteBuffer1();//简单的读写
MyByteBuffer2();//读写的基本方法
}
private static void MyByteBuffer2() {
ByteBuffer buffer = ByteBuffer.allocate(1024);//开辟容量1024字节
System.out.println("position:"+buffer.position());//0
System.out.println("limit:"+buffer.limit());//1024
/*
* position是5,说明写入了5个字节,position指向的是当前内容的结尾,方便接着往下写
*/
buffer.put("hello".getBytes());
System.out.println(buffer.position());//5
System.out.println(buffer.limit());//1024
//可以继续写
buffer.put("world".getBytes());
System.out.println(buffer.position());//10
//切换为读模式
/*这一步很重要 flip可以理解为模式切换 之前的代码实现的是写入操作
*当调用这个方法后就变成读取操作,那么position和limit的值就要发生变换
*此时capacity为1024不变
*此时limit就移动到原来position所在的位置,相当于把buffer中没有数据的空间
*"封印起来"从而避免读取Buffer数据的时候读到null值
*相当于 limit = position limit = 10
*此时position的值相当于 position = 0
*
*/
buffer.flip();
System.out.println("此时的Position:"+buffer.position());//0
System.out.println("此时的limit:"+buffer.limit());//10
/*
* clear():
* API中的意思是清空缓冲区
* 而是将缓冲区中limit和position恢复到初始状态
* 即limit和capacity都为1024 position是0
* 此时可以完成写入模式
*/
buffer.clear();
System.out.println("clear后:"+buffer.position());
System.out.println("clear后:"+buffer.limit());
//可以继续写
buffer.put("temp".getBytes());
//继续读
buffer.flip();
byte[] arr = new byte[buffer.limit()];
buffer.get(arr);
System.out.println("temp:"+new String(arr));
}
private static void MyByteBuffer1() {
//获取缓冲区
ByteBuffer buffer=ByteBuffer.allocate(1024);
//写入数据
buffer.put("Hello".getBytes());
//将写模式转换成读模式
buffer.flip();
//读取一个字节
// byte b=buffer.get();
// System.out.println((char)b);
//读取多个字节
//这里必须把上面的读取一个字节的代码注释掉,因为执行一次get后相当于指针已经指向了下标1,
//所以再继续读取buffer.limit个字符后越界.报错BufferUnderflowException
byte[] by=new byte[buffer.limit()];
buffer.get(by);
System.out.println(new String(by));
}
}
NIO与直接缓冲区与非直接缓冲区
直接缓冲区和非直接缓冲区其实设计的是NIO的缓冲区(buffer)部分。
内存映射文件
JAVA处理大文件,一般用BufferedReader,BufferedInputStream这类带缓冲的IO类,不过如果文件超大的话,更快的方式是采用MappedByteBuffer。
MappedByteBuffer是NIO引入的文件内存映射方案,读写性能极高。NIO最主要的就是实现了对异步操作的支持。其中一种通过把一个套接字通道(SocketChannel)注册到一个选择器(Selector)中,不时调用后者的选择(select)方法就能返回满足的选择键(SelectionKey),键中包含了SOCKET事件信息。这就是select模型。
SocketChannel的读写是通过一个类叫ByteBuffer来操作的.这个类本身的设计是不错的,比直接操作byte[]方便多了. ByteBuffer有两种模式:直接/间接.间接模式最典型(也只有这么一种)的就是HeapByteBuffer,即操作堆内存 (byte[]).但是内存毕竟有限,如果我要发送一个1G的文件怎么办?不可能真的去分配1G的内存.这时就必须使用"直接"模式,即 MappedByteBuffer,文件映射.
先中断一下,谈谈操作系统的内存管理.一般操作系统的内存分两部分:物理内存;虚拟内存.虚拟内存一般使用的是页面映像文件,即硬盘中的某个(某些)特殊的文件.操作系统负责页面文件内容的读写,这个过程叫"页面中断/切换". MappedByteBuffer也是类似的,你可以把整个文件(不管文件有多大)看成是一个ByteBuffer.MappedByteBuffer 只是一种特殊的ByteBuffer,即是ByteBuffer的子类。 MappedByteBuffer 将文件直接映射到内存(这里的内存指的是虚拟内存,并不是物理内存)。通常,可以映射整个文件,如果文件比较大的话可以分段进行映射,只要指定文件的那个部分就可以。
非直接缓冲区:通过allocate()方法分配缓冲区,将缓冲区建立在jvm内存中。
直接缓冲区:通过allocateDirect() 方法分配直接缓冲区,将缓冲区建立在物理内存中。可以提高效率。


由上图可知,直接缓冲区建立在操作系统的物理内存中。应用程序直接面对的是物理内存。所里效率比较高,但是在应用程序中开辟一个直接缓冲区是比较耗费资源的。还有一点:应用程序将文件写入直接缓冲区后,这个文件的数据就不归应用程序所管了。至于直接缓冲区中的数据在何时写入到磁盘中,那就由操作系统决定了。在销毁的时候 需要断开应用程序和 物理内存之间的引用,然后让垃圾回收机制进行回收,这个也是比较耗资源的。
注意是本机IO
- 字节缓冲区要么是直接的,要么是非直接的。如果为直接字节缓冲区,则java虚拟机会进最大的努力直接在此缓冲区上执行本机 I/O 操作,在每次调用基础操作系统的一个本机I/O操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容)。
- 直接字节缓冲区可以通过调用类的allocateDirect()工厂方法来创建。此方法返回的 缓冲区进行分配和取消分配的成本通常高于非直接缓冲区。直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此,他们对应用程序的内存需求要求造成的影响可能并不明显。所以建议将直接缓冲区主要分配给那些易受基础系统本机 I/O 操作影响的大型、持久的缓冲区。一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显得好处时分配他们。
- 直接字节缓冲区可以通过FileChannel的map()方法将文件直接映射到内存中来创建。该方法返回MappedByteBuffer。java平台的实现有助于通过JNI 从本机代码创建直接缓冲区。如果这些缓冲区中的某个缓冲区实例指的是不可方访问的内存区域。则试图访问该区域不会更改该缓冲去的内容,并且将会在访问期间或稍后的某个时间抛出不确定的异常。
- 字节缓冲区是直接缓冲区还是非直接缓冲区通过调用其isDirect()方法来确定。提供此方法是为了能在性能关机代码中执行显式缓冲区管理。
————————————————
版权声明:本文为CSDN博主「345丶」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baidu_40389775/article/details/89176736















 1630
1630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









