







Python数据处理
1 numpy数组操作
numpy库概述
是高性能科学计算和数据分析的基础包,支持维度数组、矩阵计算等
ndarray概述
N维数组对象ndarray,用来存放同类型元素的多维数组
数组与矩阵的区别是:数组内的元素可以是字符等,而矩阵只能是数。
- 创建数组
import numpy as np
a = [1, 2, 3, 4]
b = np.array(a)
print(a) #列表,元素间用逗号隔开
print(b)#数组,元素间用空格隔开
c = np.array([[1, 2], [3, 4]])
print(c)#这是一个两行两列的数组
d = np.array(['a', 'b', 1])
print(d)#数组可以包含字符
print(np.zeros(3))#输出元素全是0的数组,后面代表数组的形状,3输出结果为[0. 0. 0.]
print(np.zeros((3, 1)))#输出3行1列的数组,[[0.]
[0.]
[0.]]
print(np.ones((1, 2)))#输出元素全是1的数组
# print(np.ones(2, 4))#这样输出就会出错,若是二维的数组应该加括号
# 创建随机数组
# 均匀分布
print("***************************")
print(np.random.rand(10)) #生成10个随机数,构成1行10列的数组
print(np.random.rand(10, 10)) #构成一个10行10列的数组
print(np.random.randint(0, 100)) #生成一个0-100内的整数
print(np.random.randint(0, 100, 5)) #生成5个0-100内的数
print(np.random.uniform(0, 100, (1, 3))) #生成一个元素在0-100内的1行3列的数组
# 正态分布
print(np.random.normal(1.75, 0.1, (2, 3))) #给定均值/标准差/维度,生成一个数组
print(np.random.standard_normal(5)) #生成5个服从正态分布的数
print(np.random.standard_normal((3, 5))) #生成一个元素符合正态分布的3行5列的数组
- ndarry数组的属性
import numpy as np
a = np.array([[1, 2, 3], [1, 1, 1]])
b = np.array([1, 2, 3])
print('数组a内元素的个数为:{}'.format(a.size))
print('数组a的形状为:{}'.format(a.shape))
print('数组a的维度为:{}'.format(a.ndim))
print('数组b的维度为:', b.ndim)
print('数组a内元素类型为:', a.dtype)
print('数组内元素字节大小:', a.itemsize)
# 更改数组的形状
x = a.reshape(3, 2)
print('将数组a的形状改为3行2列:', x)
- ndarray数组的运算
import numpy as np
x = np.array([[1, 2, 3], [2, 2, 2]])
print('数组x与x的差为:', x-x)
print('数组x与x的乘积为:', x*x)#对应行乘以对应列
print('数组与整数的乘积:', x*2)#所有元素都乘以这个数
- ndarray数组的索引与切片
mport numpy as np
x = np.array([[1, 2, 3], [1, 1, 1]])
print('数组x的形状为:{}'.format(x.ndim))
print('数组x的0号元素为:', x[0])#x为一个两维的数组
print('数组x的第0行第0列的元素:', x[0][0])#这就相当于第一维的0号元素,再取第二维的0号元素
- ndarray数组的基本统计方法
import numpy as np
x = np.random.randn(3, 4)
print('数组x为:{}'.format(x))
print('数组x内元素之和为:{}'.format(sum(x)))# 按列求和 = x.sum(axis=0)
print('数组x内所有元素之和为:{}'.format(x.sum()))#这才是所有元素求和
print('数组x内元素的平均值为:{}'.format(x.mean()))#按行计算平均值axis=1;按列计算平均值axis=0
print('数组x的标准差为:{},方差为:{}'.format(x.std(), x.var()))
print('数组x的最大值为:{},最小值为:{},最大值索引为:{},最小值索引为:{}'.format(x.max(), x.min(), x.argmax(), x.argmin()))
print('数组x按列累加:', x.cumsum(0))
print('数组x按行累加:', x.cumsum(1))#同理累乘为x.cumprod()
2 numpy矩阵操作
矩阵操作
numpy.matlib
- 生成矩阵
import numpy as np
x = np.matrix([[1, 2, 3], [1, 1, 1]]) # 矩阵
x2 = np.array([[1, 2, 3], [1, 2, 2]]) # 数组
print(type(x))
print('数组x的[0, 0]号元素为:', x[0, 0])# 输出的是[1]
print('数组x的[0][0]号元素为:', x[0][0])# 输出的是[[1 2 3]]
print('数组x2的[0][0]号元素为:', x2[0][0])# 输出的是1
import numpy.matlib
import numpy as np
print('生成一个随机元素的2行3列的矩阵:', np.matlib.empty((2, 3)))
print('生成一个元素为0的2行2列的矩阵:', np.matlib.zeros((2, 2)))
print('生成一个元素为1的3行3列的矩阵:', np.matlib.ones((3, 3)))
# 生成单位矩阵
# eye()方式生成对角元素为1,其余元素为0的矩阵,行列可以不相同
print('生成一个单位矩阵:', np.matlib.eye(3, 4, k=0, dtype=int))
print(np.matlib.eye(2))# 默认生成的是一个单位矩阵,行列相同等于输入的数
# identity()方式生成单位矩阵
print('单位矩阵为:', np.matlib.identity(3))# 只有一个值,方阵
# 生成随机矩阵
print('生成一个3行2列的随机矩阵:', np.matlib.rand(3, 4))# 随机填充0-1间的数
- 矩阵的常用操作
import numpy as np
import numpy.matlib
x = np.matrix('1, 2; 3, 4')# 生成矩阵
y = np.asarray(x)# 矩阵转数组
z = np.asmatrix(y)# 数组转矩阵
print(x)
print(type(y))
x2 = np.matrix([[1, 2, 3], [1, 1, 1]])
print('x2的转置为:', x2.T)
# 查看矩阵特征
print('矩阵x2所有元素平均值为{},所有元素的和为:{}:'.format(x2.mean(), x2.sum()))
print('矩阵x2纵向(列)的平均值为:{},和为:{}。 '.format(x2.mean(0), x2.sum(0)))
print('矩阵x2横向(行)的平均值为:{},和为:{}。'.format(x2.mean(1), x2.sum(1)))
print('矩阵x2按行最大值为:{},对应的索引为:{}。'.format(x2.max(1), x2.argmax(1)))
print('矩阵x2的对角线元素为:{}'.format(x2.diagonal()))
- 矩阵的运算
# 矩阵的运算
import numpy as np
import numpy.matlib
a = np.matrix([[1, 2], [3, 4]])
b = np.matrix([[11, 12], [13, 14]])
print(np.dot(a, b))
# 当元素都为数时,array数组也可以表示矩阵
a2 = np.array([[1, 2], [3, 4]])
b2 = np.array([[11, 12], [13, 14]])
print('矩阵的点乘为:', np.dot(a2, b2))
print('矩阵的内积为:', np.vdot(a2, b2))
print('矩阵a2的逆矩阵为:', np.linalg.inv(a2))
# 求解矩阵形成的线性方程组的解
x = np.array([[1, 1, 1], [0, 2, 5], [2, 5, -1]])
y = np.array([6, -4, 27])
xx = np.linalg.solve(x, y)
print('线性方程组的解为:', xx)
3Pandas数据结构
解决数据分析
常常与numpy和matplotlib一同使用
Pandas的两大核心数据结构:Series(一维数据)、DataFrame(多维特征 数据)
Series(变长字典)
- 创建函数
import pandas as pd
import numpy as np
# python数组创建
print(pd.Series([11, 12], index=['北京', '上海']))
# numpy数组创建
print(pd.Series(np.arange(3, 6), index=['A','B','C']))
print(pd.Series(list(range(5)), index=['A', 'B', 'C', 'D', 'E']))
print(pd.Series(np.array(['jiwei', 1, 3])))
# python字典创建
print(pd.Series({'北京': 12, '上海': 22}))
- Series的操作
import pandas as pd
import numpy as np
x = pd.Series([4, 7, -5, 3])
print('值value:', x.values)
print(type(x.values))# Series的值为数组形式
print('键key:', x.index)
print(x.keys())# 和上面的index是一样的结果,所以说Series结构的前面数据可以叫键也可以叫索引
# 索引
print('x的2号元素为:', x[2])
print('x的多个索引的值:\n', x[[0, 1, 3]])# 多个索引 按照Series的格式输出
# 修改制定索引位的值
x[1] = 8
print('将x的1号位值改为8:{}'.format(x))
# 有标签的索引
x2 = pd.Series([2, 4, -1, 9], index=['a', 'b', 'c', 'd'])
print('x2:', x2)
print('x2的a上的值为:', x2['a'])
print('x2的前三位的值为:', x2[['a', 'b', 'c']])
# 自动对齐不同索引的数据
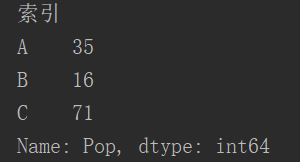
a1 = pd.Series({'A': 35, 'B': 16, 'C': 71})
a2 = pd.Series({'O': np.nan, 'A': 35, 'B': 17})
print(a1 + a2) #没有对上的元素显示NAN
# 修改.name属性
a1.name = 'Pop'
print(a1)
a1.index.name = '索引'
print(a1)
DataFrame(数据框)
- 创建DataFrame
import pandas as pd
# 创建空的DataFrame
a = pd.DataFrame()
print(a)
# 单个列表创建DataFrame
data = list(range(5))
b = pd.DataFrame(data)
print(b)
# 从嵌套列表中创建DataFrame
data2 = [['Alex', 10], ['Bob', 12], ['Clarke', 13]]
c = pd.DataFrame(data2, columns=['name', 'age'], dtype=float)
print(c)
# 由等长的列表或numpy数组组成的字典创建DataFrame
data3 = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
d = pd.DataFrame(data3)
print(d)
- 基本操作
import pandas as pd
import numpy as np
# 按照指定的列顺序去排序,找不到的产生NAN值
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
data2 = pd.DataFrame(data, columns=['year', 'state', 'pop'])
print(data2)
data3 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five'])
print(data3)
print('data3的colums为:', data3.columns)
# 将DataFrame的列获取为一个Series
print(data3['state'])# DataFrame的一个列就是一个Series
# 通过赋值的方式修改
data3['debt'] = 16.5
print(data3)
data3['debt'] = np.arange(5)
print(data3)
# 将列表或数组赋值给某个列的时候,其长度必须与DataFrame长度匹配,若赋值为Series则精准匹配,空位为NAN
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
data3['debt'] = val
print(data3)
# 为不存在的列赋值会出现一个新的列,用del删除列
data3['eastern'] = data3.state=='Ohio'
print(data3)
del data3['eastern']
print(data3)
# 将嵌套字典传给DataFrame
pop = {'Nevada': {2001: 2.4, 2002: 2.9}, 'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.8}}
data4 = pd.DataFrame(pop)
print(data4)
# 转置
print(data4.T)
# 设置DataFrame的Index和columns.name属性
data4.index.name = 'year'
data4.columns.name = 'state'
print(data4)
4Pandas常用方法
数据读取与写入
import pandas as pd
# 粘贴板内容
# A B C
# x 1 4 p
# y 2 5 q
# z 3 6 r
# 从粘贴板读书节
df1 = pd.read_clipboard()
# 把数据放到粘贴板
df1.to_clipboard()
# 转换成csv格式
df1.to_csv('df1.csv')
# 转换成json格式
df1.to_json('df1.json')
# 转换成html格式
df1.to_html('df1.html')
# 转换成excel格式
df1.to_excel('df1.xlsx')
import pandas as pd
df = pd.read_csv('temp.csv')
print(df)
# print(type(df))
# 这样显示的DataFrame的索引是默认索引,如果想修改索引采用如下:
df = pd.read_csv('temp.csv', index_col=['S.NO'])
print(df)
# 数据类型转换使用dtype=设置,下面是将原来int类型的Salary转换成float类型
df = pd.read_csv('temp.csv', dtype={'Salary': np.float64})
print(df)
# 也可以使用dtypes去查看各列都是什么类型
print(df.dtypes)
# name:指定标题名称
df = pd.read_csv('temp.csv', names=['a', 'b', 'c', 'd', 'e'])
print(df)
# 这个时候虽然添加了新的标题名称,但是原来的标题也还在,可以使用header=0去删除原来标题
# skiprows:指定跳过多少行
df = pd.read_csv('temp.csv', skiprows=2)
print(df)
描述性统计方法
import pandas as pd
data = {'name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve', 'Minsu', 'Jack', 'Lee', 'David', 'Gasper', 'Betina', 'Andres']),
'age': pd.Series([25, 26, 25, 23, 30, 29, 23, 34, 40, 30, 51, 46]),
'rating': pd.Series([4.24, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8, 3.78, 2.98, 4.80, 4.10, 3.65])}
df = pd.DataFrame(data)
print(df, '\n')
print(df.sum(), '\n')# 列求和,默认axis=0,也就是默认是列求和
print(df.sum(axis=1), '\n')# 行求和
print(df.mean(), '\n')# 列求平均值
print(df.std(), '\n')# 列求标准差
print(df.describe(include=['number']))# 统计信息摘要
迭代与遍历
- 迭代遍历DataFrame
# 迭代与遍历
# 迭代DataFrame
import pandas as pd
import numpy as np
N = 5
df = pd.DataFrame({'D': pd.date_range(start='2019-01-01', periods=N, freq='M'),
'x': np.linspace(0, N-1, N),# 等差列表
'y': np.random.rand(N),
'z': np.random.choice(['Low', 'Medium', 'High'], N)})
print(df)
# 迭代遍历DataFrame的结果是DataFrame对象的每一列标签
for i in df:
print(i)

- 遍历iteritems()将每个列作为名称,将索引和值作为键和列值迭代为Series对象
# 遍历iteritems
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(4, 3), columns=['col1', 'col2', 'col3'], index=['A', 'B', 'C', 'D'])
print(df)
for key, value in df.iteritems():
print(key, value)

- 遍历iterrows()返回迭代器,产生每个索引值以及包含每行数据的序列
# 迭代iterrows()
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(4, 3), columns=['row1', 'row2', 'row3'], index=['A', 'B', 'C', 'D'])
print(df)
for row_index, row in df.iterrows():
print(row_index, row)

- 遍历itertuples()方法将DataFrame中每一行返回一个命名元组的迭代器,元组的第一个元素是行的相应索引值,而剩余的值是行值
# 遍历itertuples()
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(4, 3), columns=['row1', 'row2', 'row3'], index=['A', 'B', 'C', 'D'])
print(df)
for row in df.itertuples():
print(row)

排序
# 排序
import pandas as pd
import numpy as np
data_df = pd.DataFrame(np.random.rand(10, 2), columns=['A', 'B'], index=[1, 4, 6, 2, 5, 9, 8, 0, 7, 3])
print(data_df, '\n')
# 按照索引排序
sorted_df = data_df.sort_index(ascending=True)
print(sorted_df, '\n')
# 按照“B”列的值进行排序
sorted_df2 = data_df.sort_values(by='B')
print(sorted_df2)
缺失值处理
缺失值是指数据丢失的现象,也就是数据集中某一块数据不存在
缺失值标记、缺失值填充、缺失值插值
Pandas为了方便检测缺失值,将不同类型的数据的缺失均采用NAN标记
- 标记缺失值:用到isnull()和notnull()分别表示为是缺失值和不是缺失值,返回的是True和Flase布尔值
# 缺失值处理
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(4, 3), index=['a', 'c', 'e', 'f'], columns=['one', 'two', 'three'])
print(df, '\n')
df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f'])
print(df, '\n')
# 'one'列是空值的是
print(df['one'].isnull(), '\n')
# 'two'列不是空值的是
print(df['two'].notnull())
print(df.isnull())# 把整个DataFrame的值都判断是否是空值
- 填充缺失值
# 使用标量0去填充空值
print(df.fillna(0))
# 向前填充
print(df.fillna(method='pad'))
# 向后填充
print(df.fillna(method='backfill'))
# 用指定的一些值去替换,常常用作排除一些错误值
import pandas as pd
import numpy as np
df = pd.DataFrame({'one': [10, 20, 30, 40, 50, 20000], 'two': [1000, 0, 20, 30, 40, 60]})
print(df, '\n')
print(df.replace({1000: 10, 20000: 20}))
-
清除缺失值
# 清除缺失值 # 清除缺失值所在的行 print(df.dropna()) # 清除缺失值所在的列 print(df.dropna(axis=1)) -
在某一个缺失值的位置添加值
df.loc('行名', '列名') = 0.0 # 在某行(行名)某列(列名)的null值添加为0.0
异常值处理
查看异常数据的方法
1describe()方法
import pandas as pd
df = pd.read_excel('C:/python_course/ImoocNanjingUniversity/save/nan.xlsx')
print(df.describe())
输出结果:
A B C
count 4.00000 5.00000 4.000000
mean 60.12500 29.40000 49.125000
std 31.33426 13.96424 33.540262
min 23.40000 11.30000 23.300000
25% 39.67500 23.10000 30.575000
50% 63.55000 25.70000 37.550000
75% 84.00000 42.00000 56.100000
max 90.00000 44.90000 98.100000
5Pandas绘图方法
import numpy as np
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.rand(4, 3), columns=['col1', 'col2', 'col3'], index=['A', 'B', 'C', 'D'])
# 折线图
# df.loc[::, ['col2', 'col3']].plot()
# plt.show()
# 柱状图
ax = df.plot(kind='bar', x='col1', color='g')
ax.set(ylabel='Prace', title='num')
plt.show()















 7658
7658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











