







5 Maxwell
用java编写的MySQL实时抓取工具,其抓取原理也是基于binlog。
5.1 Maxwell和canal对比
①功能对比
- Maxwell没有canal那种server-client模式,只有一个server把数据发送到消息队列或redis(发送到redis是做缓存分析用的)。
- Maxwell亮点功能:就是canal只能抓取最新的数据,对已存在的历史数据没有办法处理。而Maxwell有一个bootstrap功能,可以引导出完整的历史数据用于初始化,非常号用。
- Maxwell不支持HA,但是它支持断点续传。
- Maxwell只支持json格式,而canal如果使用server-client模式的话,可以自定义格式。
- Maxwell比canal更加轻量级。
②数据格式对比
执行insert测试语句
insert into z_user_info values(30, 'zhang3', '13897393803'),(31, 'li4', '1738939372')
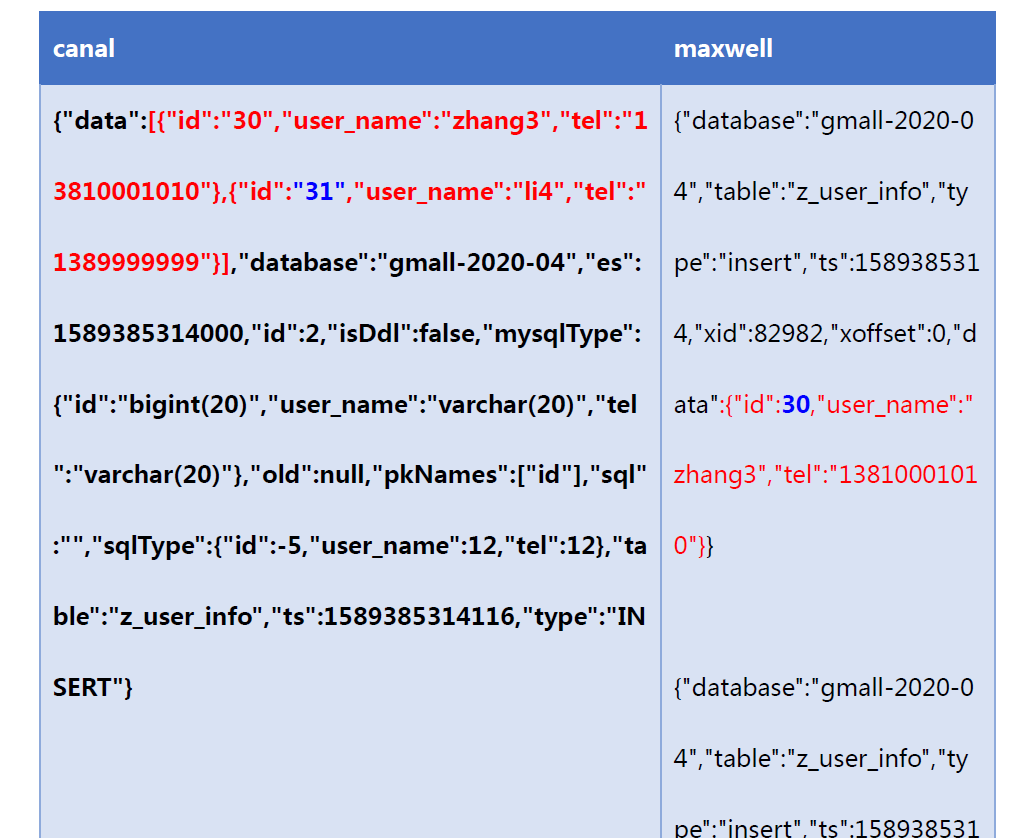
③总结数据特点
日志结构:
canal每一条SQL会产生一条日志
- 数据放在“data”字段的一个json数组中!
- 类型“type”: INSERT、UPDATE、DELETE
- 含有表的结构信息,比较繁琐
- 原始数据类型,转为字符串
maxwell执行的SQL每影响一条数据,就会产生一条日志
- 数据“data”,json对象
- 类型“type”:insert、update、delete
- 不含表的结构信息,更简洁
- 不改变原始数据类型
5.2 安装Maxwell
步骤1:将安装包上传到/opt/software
步骤2:解压安装包maxwell-1.25.0.tar.gz到/opt/module目录
[atguigu@hadoop102 software]$ tar -zxvf maxwell-1.25.0.tar.gz -C /opt/module/
[atguigu@hadoop102 module]$ mv maxwell-1.25.0/ maxwell
安装前MySQL准备
在数据库中建立一个maxwell库用于存储maxwell的元数据
mysql> create database maxwell;
分配一个账号可以操作该数据库
mysql> GRANT ALL ON maxwell.*TO 'maxwell'@'%' IDENTIFIED BY '123456';
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
--这个是MySQL的安全等级,需要设置一下
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
mysql> GRANT ALL ON maxwell.*TO 'maxwell'@'%' IDENTIFIED BY '123456';
分配这个账号可以监控其他数据库的权限
mysql> GRANT SELECT,REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO maxwell@'%';
步骤3:修改配置文件config.properties文件
[atguigu@hadoop102 maxwell]$ mv config.properties.example config.properties
修改内容:
# kafka的连接地址,发送到的主题
producer=kafka
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
kafka_topic=gmall_realtime_spark_db_m
# 连接的MySQL信息
host=hadoop102
user=maxwell
password=123456
# 需要添加,后续初始化会用!
client_id=maxwell_1
默认还是输出到指定kafka主题的一个kafka分区,因为分区并行可能会打乱binlog的顺序
如果要提高并行度,首先要设置kafka的分区数>1,然后设置producer_partition_ny属性,可选值有:database、table、primary_key、random、column
步骤4:启动maxwell
[atguigu@hadoop102 maxwell]$ bin/maxwell --config /opt/module/maxwell/config.properties
编写脚本启动maxwell:
cd ~/bin
vim maxwell.sh
maxwell启动脚本
#!/bin/bash
/opt/module/maxwell/bin/maxwell --config /opt/module/maxwell/config.properties > /dev/null 2>&1 &
增加可执行权限
chmod +x maxwell.sh
# 启动程序
maxwell.sh
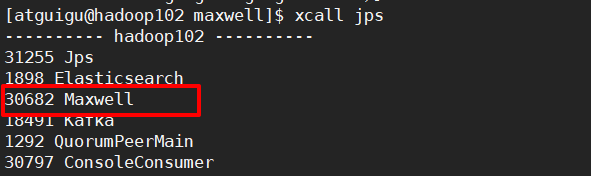
查看进程:
步骤5:启动kafka消费者,查看是否消费到数据
[atguigu@hadoop102 bin]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic gmall_realtime_spark_db_m
步骤6:生成业务数据
[atguigu@hadoop102 applog-db]$ java -jar gmall2020-mock-db-2020-12-23.jar
查看结果:

6 Maxwell版本的ODS层分流处理
/**
* 基于maxwell从kafka读取数据,进行分流,然后根据表名,发送到kafka不同的topic中
*/
object BaseDBMaxwellApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("BaseDBMaxwellApp")
val ssc = new StreamingContext(conf, Seconds(5))
val topic = "gmall_realtime_spark_db_m"
val groupId = "base_db_maxwell_group"
//TODO 1 从redis中获取偏移量
val offsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId)
//TODO 2 根据偏移量,从Kafka中获取数据DStream
var inputDStream: InputDStream[ConsumerRecord[String, String]] = null
if (offsetMap != null && offsetMap.size > 0){
inputDStream = MyKafkaUtil.getKafkaDStream(topic, ssc, offsetMap, groupId)
}else{
inputDStream = MyKafkaUtil.getKafkaDStream(topic, ssc, groupId)
}
//TODO 3 获取每个批次的偏移量
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val offsetDStream: DStream[ConsumerRecord[String, String]] = inputDStream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//TODO 4 对数据进行格式的转换ConsumerRecord ==> JsonObject
val jsonObjDStream: DStream[JSONObject] = offsetDStream.map {
record => {
//获取value值的json字符串
val jsonStr: String = record.value()
//将json字符串转换成json对象
val jsonObj: JSONObject = JSON.parseObject(jsonStr)
jsonObj
}
}
//
// jsonObjDStream.print(100)
//TODO 5 根据表名将数据分流,发送到不同的主题中
jsonObjDStream.foreachRDD{
rdd => {
rdd.foreach{
jsonObj => {
//获取类型
val opType = jsonObj.getString("type")
//获取数据
val dataObj = jsonObj.getJSONObject("data")
//判断数据不为空,并且不是删除操作!那就分流
if (dataObj != null && !dataObj.isEmpty && !"delete".equals(opType)){
//获取表名
val tableName = jsonObj.getString("table")
//拼劲要发送给到kafka的新主题
val sendTopic = "ods_" + tableName
//向kafka发送信息
MyKafkaSink.send(sendTopic, dataObj.toString())
}
}
}
//TODO 6 保存偏移量到redis
OffsetManagerUtil.saveOffset(topic, groupId, offsetRanges)
}
}
ssc.start()
ssc.awaitTermination()
}
}
6.2 测试
启动程序,然后生成数据
[atguigu@hadoop102 applog-db]$ java -jar gmall2020-mock-db-2020-12-23.jar
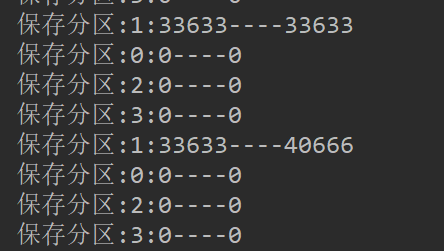
可以看到控制台输出偏移量的变化:
启动kafka的消费者,消费发送数据的主题:测试maxwell==> kafka
[atguigu@hadoop102 bin]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic gmall_realtime_spark_db_m
启动卡夫卡的消费者,消费某一个表的主题:测试kafka==>分流后新的topic
[atguigu@hadoop102 bin]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic ods_order_info















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











