







文章目录
一、线性回归:就是找一条线
输入[数据,标签],使用最小二乘法(1/2n乘(预测值与真实值之差的平方和))进行训练,线性回归模型即sklearn中的linear_model.LinearRegression()
from sklearn import linear_model,datasets
digits=datasets.load_digits()# 加载手写数字数据集
clf=linear_model.LinearRegression()# 基于最小二乘法的线性回归计算
x,y=digits.data[:-1],digits.target[:-1] #x为数据,y为标签
clf.fit(x,y)#将x、y放入模型中,进行训练
y_gred=clf.predict([digits.data[-1]])# 预测
y_true=digits.target[-1]# 真实数据
print(y_gred,y_true)
二、SVM(支持向量机):求分隔数据的超平面
svm.SVC 指定两个参数
from sklearn import svm,datasets
digits=datasets.load_digits()
# C代表分类器对噪声的容忍度,C越大,容忍度越小,但容易出现过拟合的问题
# gamma值越大,支持向量就越少,支持向量的个数影响训练与预测的速度。
clf=svm.SVC(gamma=0.001,C=100)
clf.fit(digits.data[:-1],digits.target[:-1])
y_gred=clf.predict([digits.data[-1]])# 预测
y_true=digits.target[-1]# 真实数据
print(y_gred,y_true)
三、k近邻算法:每个节点 找与自己相近的k个邻居
用最近的邻居(k)来预测未知数据点。k 值是预测精度的一个关键因素,无论是分类还是回归,衡量邻居的权重都非常有用,较近邻居的权重比较远邻居的权重大。
KNN 算法的缺点是对数据的局部结构非常敏感。计算量大,需要对数据进行规范化处理,使每个数据点都在相同的范围。
sklearn.neighbors import KNeighborsClassifier
指定邻居数
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
digits=datasets.load_digits()
clf=KNeighborsClassifier(n_neighbors=6)
clf.fit(digits.data[:-1],digits.target[:-1])
y_gred=clf.predict([digits.data[-1]])# 预测
y_true=digits.target[-1]# 真实数据
print(y_gred,y_true)
四、逻辑回归算法 Logister Regression
计算某件事情发生的概率值。
优点:计算代价不高易于实现 缺点:容易过拟合,分类精度不高
LogisticRegression 无参数
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
digits=datasets.load_digits()
clf=LogisticRegression()
clf.fit(digits.data[:-1],digits.target[:-1])
y_gred=clf.predict(digits.data[:-1])# 预测
y_true=digits.target[:-1]# 真实数据
print(y_gred,y_true)
如果报错:D:\python\anacon\lib\site-packages\sklearn\linear_model_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT。
不需要理会,解决办法:增加数据的迭代次数或者更新库
五、决策树
递归地选择最优特征,并根据该特征对训练数据进行分割,使得每个子数据集有一个最好的分类过程。
构造过程:
1.开始:构造根节点,将所有训练数据都放在根节点,选择一个最优特征,按着这一特征将训练数据集分割为子集,使得各个子集有一个在当前条件下最好的分类
2.如果子集可以被基本正确分类,那么构造叶节点,并将这些子集分到所对应的叶节点
3.如果子集还不能被正确地分类,那么就选择新的最优特征,继续分隔,构建相应的节点。指导所有训练子集被基本正确分类,或没有合适的特征。
4.每个子集都分到叶节点,即都有明确类,生成一颗决策树
第一种计算分裂的方法:
信息熵:Ent(D)=负求和(pi*log2pi)信息熵越小,纯度越高。
信息增益Gain(D,a)=Ent(D)-求和((|Dm|/|D|)*Ent(Dm))
属性的信息增益越大就意味着以用该属性进行划分所带来的纯度增加越大,在每个结点选择信息增益最大的属性进行划分而形成的算法是ID3算法.
第二种:增益率:Gain_ratio(D,a)=Gain(D,a)/IV(a)
IV(a)=-求和((|D的m次幂|/|D|)*log2(|D的m次幂|/|D|))为a的固有值,属性取值越多,即M越大,该值会越大。
当有些属性取值过多时,可能会导致ID3算法误选取值较多的属性,此时使用增益率作为指标是一个很好的选择,这叫做C4.5决策树
第三种:基尼指数
1.基尼系数:Gini(D)=求和(k和k’)(pk*pk’)=1-求和(pk^2)基尼系数反映了从数据集 D 中随机抽取两个样本, 其类别标记一致的概率;Gini(D) 越小, 则数据集 D 的纯度越高
2.基尼指数Gini_index(D,a)=求和v((|Dm|/|D|)*Gini(Dv))
以基尼指数作为划分依据的决策树算法称为CART决策树
import sys
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import sklearn.tree as tree
from sklearn import preprocessing # 对数据进行处理
from sklearn.model_selection import train_test_split # # 用来拆分训练集和数据集
from sklearn import metrics
import matplotlib.pyplot as plt
# 首先读取数据 数据你们可以自行下载一下 设置分隔符
my_data=pd.read_csv('drug200.csv',decimal=',')
# 第二步 获取数据中标签的值
X=my_data[['Age','Sex','BP','Cholesterol','Na_to_K']].values
# 第三步 对数据进行处理:因为决策树不处理分类变量,应将其转为数值
le_sex=preprocessing.LabelEncoder()
# 对F和M进行转换
le_sex.fit(['F','M'])
#第一列的所有数据进行转换
X[:,1]=le_sex.transform(X[:,1])
# 对第二列的数据进行转换操作
le_BP=preprocessing.LabelEncoder()
le_BP.fit(['HIGH','LOW','NORMAL'])
X[:,2]=le_BP.transform(X[:,2])
# 对第三列的数据进行转换操作
le_Chol=preprocessing.LabelEncoder()
le_Chol.fit(['HIGH','NORMAL'])
X[:,3]=le_Chol.transform(X[:,3])
# 第四步 提出因变量
y=my_data['Drug']
# 第五步 构建决策树 # 函数返回四个不同的参数:x训练集,x测试集,y训练集,y测试集 test_size是测试数据集比例,radmon_state确保获得相同拆分
X_trainSet,X_testSet,Y_trainSet,Y_testSet=train_test_split(X,y,test_size=0.3,random_state=3)
# 第六步构建模型 entropy信息增益
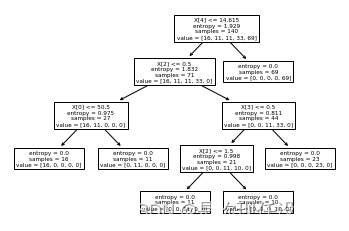
drugTree=DecisionTreeClassifier(criterion='entropy',max_depth=4)
drugTree.fit(X_trainSet,Y_trainSet)
# 第六步预测
predTree=drugTree.predict(X_testSet)
print (predTree [0:5])
print (Y_testSet [0:5])
# 第七步 评估模型
print('准确率为:',metrics.accuracy_score(Y_testSet,predTree))
tree.plot_tree(drugTree)
plt.show()
六、K-means:划分类
算法把 n 个点(可以是样本的一次观察或一个实例)划分到 k 个集群(cluster),使得每个点都属于离他最近的均值(即聚类中心,centroid)对应的集群
执行过程如下:
1.首先随机选取k个样本作为初始均值向量
2.计算每个样本和均值向量之间的欧式距离,选取与当前样本欧式距离最小均值向量的类别作为当前样本的类别
3.计算每一个类别的向量均值重新作为新的均值向量
4.重复2-3次直到均值向量没有变化或者达到一定的迭代次数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
%matplotlib inline
# 首先 创建数据
from sklearn.datasets import make_blobs
# # 生成300条数据,四类数据,方差越小,簇越集中,random_state:随机数种子
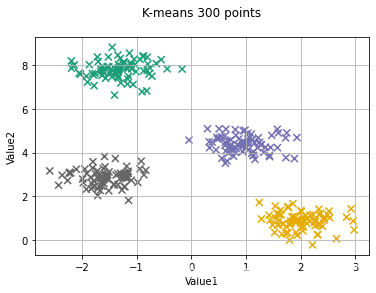
x,y_true=make_blobs(n_samples=300,centers=4,cluster_std=0.4,random_state=0)
# 第二步 构建模型
kmeans=KMeans(n_clusters=4)# 分类数
kmeans.fit(x)# 将数据投入模型中
y_kmeans=kmeans.predict(x)# 预测x的结果
centriods=kmeans.cluster_centers_# 聚类的中心点
# 展示
plt.scatter(x[:,0],x[:,1],c=y_kmeans,cmap='Dark2',s=50,marker='x')
plt.scatter(centriods[:,0],centriods[:,1],c=[0,1,2,3],cmap='Dark2',s=70,marker='o')
plt.title('K-means 300 points\n')
plt.xlabel('Value1')
plt.ylabel('Value2')
plt.grid()
七、随机森林
从样本容量为N的样本中有放回地抽取n个样本,作为决策树根节点。当节点需要分裂时,从节点的M个属性中随机选择m个属性,根据某种策略**(信息增益)** 选择一个属性作为该节点的分裂属性,若下一个选择的属性是使用过的,则认为该节点到叶子节点,不能再分裂了
优点:它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择 它可以判断特征的重要程度 可以判断出不同特征之间的相互影响 不容易过拟合 训练速度比较快,容易做成并行方法 实现起来比较简单 对于不平衡的数据集来说,它可以平衡误差。 如果有很大一部分的特征遗失,仍可以维持准确度。
缺点:随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris=datasets.load_iris()
df=pd.DataFrame(iris.data,columns=iris.feature_names)
df['is_train']=np.random.uniform(0,1,len(df))<=.75 #从一个均匀分布的区域中随机采样。0-1c采样df长度个
df['species']=pd.Categorical.from_codes(iris.target,iris.target_names)# 类别替换 数字换成类别名
# 被训练的为train,未被训练的为test数据集
train,test=df[df['is_train']==True],df[df['is_train']==False]
features=df.columns[:4]# 前四列为特征
clf=RandomForestClassifier(n_jobs=2)# 设置并行计算数。n_estimators:森林中决策树的数量(100)。
# criterion:分裂节点所用的标准,可选“gini”, “entropy”, random_state:控制bootstrap的随机性以及选择样本的随机性。
y,_=pd.factorize(train['species'])#因式分解 获取数据与种类
clf.fit(train[features],y)
preds=iris.target_names[clf.predict(test[features])]
pd.crosstab(test['species'],preds,rownames=['actual'],colnames=['preds'])# 设置交叉表
八、朴素贝叶斯:相互独立
𝑝(𝐴|𝐵)=𝑝(𝐴,𝐵)𝑝(𝐵)=𝑝(𝐵|𝐴)⋅𝑝(𝐴)∑𝑎∈ℱ𝐴𝑝(𝐵|𝑎)⋅𝑝(𝑎)p(A|B)=p(A,B)p(B)=p(B|A)⋅p(A)∑a∈ℱAp(B|a)⋅p(a) 世间很多事都存在某种联系,假设事件A和事件B。人们常常使用已经发生的某个事件去推断我们想要知道的之间的概率。 可详细了解
对于连续性特征值,本文处理的方式是假设这些特征值服从正态分布,计算每一列特征值的均值和方差,从而得到他们的正态分布概率密度,通过概率密度就可以大致计算每个值对应的条件概率,然后就能得到数据成为某个标签的概率,然后选择对应概率最大的那个标签作为分类结果。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import scipy.stats as st # 导入统计函数库
# norm.rvs通过loc和scale参数生成服从分布的指定随机数 等np.random.normal(loc=0.0, scale=1.0, size=None)
# 求概率密度函数指定点的函数值st.norm.pdf(0,loc = 0,scale = 1) cdf正态分布累计概率密度函数
iris=pd.read_csv('iris.csv')
def cal_mean_and_variance(x_train,y_train):
labels=list(set(y_train))# 提取类别
mean_and_variance={}# 用来存储每个分类下的平均值
for label in labels:
sameClassData=x_train[y_train==label]#同一类别的数据
mean_and_variance[label]=[]
for i in range(0,sameClassData.shape[1]):
mean=sameClassData.iloc[:,i].mean()# 求平均值
std=sameClassData.iloc[:,i].std(ddof=1)#求无偏估计方差
mean_and_variance[label].append((mean,std))
return mean_and_variance
#计算预测准确率
def accuracy(pred,real):
pred_list=pred.to_list()
real_list=real.to_list()
corrNum=0#定义预测正确的个数
for i in range(0,len(pred_list)):
if pred_list[i]==real_list[i]:
corrNum+=1
accuracy=float(corrNum)/len(pred_list)
return accuracy
def classify(X,mean_and_variance,y_train):
probs=[]# 存储数据属于每个类别的概率值
labels=[]# 存储对应的类别
label_count=y_train.value_counts()
for key in mean_and_variance.keys():
cond_prob=1#以当前类别为条件的条件概率乘积
for i in range(0,len(mean_and_variance[key])):
# 连续型数据考虑概率密度函数,根据在i属性上的均值和方差进行衡量
prob_density=st.norm.pdf(X[i],mean_and_variance[key][i][0], mean_and_variance[key][i][1])
# 类条件概率进行拆分,这里采用拆分成连乘的形式
cond_prob=cond_prob*prob_density
prob=cond_prob*(float(label_count[key])/len(y_train))
probs.append(prob)
labels.append(key)
maxInd=np.argmax(probs)
return labels[maxInd]
if __name__ == '__main__':
x_train, x_test, y_train, y_test = train_test_split(iris.iloc[:,0:-1], iris.iloc[:,-1])
m_and_v = cal_mean_and_variance(x_train, y_train)
pred = x_test.apply(lambda x : classify(x, m_and_v, y_train), axis=1)
print(accuracy(pred, y_test)) # 打印准确率
十、降维算法PCA
1.将原始数据按列组成n行m列矩阵X 将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
2.求出协方差矩阵
3.求出协方差矩阵的特征值及对应的特征向量
4.将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P Y=PX即为降维到k维后的数据
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import pandas as pd
#加载数据集
iris=load_iris()
y=iris.data
y=iris.target
print('数组维度',x.shape)
iris_dataFrame=pd.DataFrame(x)
pca=PCA(n_components=1)#表示降维后需要的维度,也就是保留的特征数目
pca.fit(x)#拟合
x_new=pca.transform(x)# 获取新矩阵
print('降维后的维度',x_new.shape)















 5496
5496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









