







Linux性能优化实战
应该怎么理解“平均负载”?
当系统变慢时,第一件事就是执行top或者uptime来了解系统负载情况。
root@ubuntu:/home/ncnn-arm# uptime
18:41:32 up 4 min, 1 user, load average: 1.32, 1.66, 0.84
//18:41:32 当前时间
//up 4 min 系统运行时间
//1 user 当前用户数
//1.32 1分钟前的平均负载
//1.66 5分钟前的平均负载
//1.32 15分钟前的平均负载
简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。
既然平均的是活跃进程数,那么最理想的,就是每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。比如当平均负载为 2 时,意味着什么呢?
在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。
平均负载多少时合理
平均负载最理想情况是等于CPU个数,可通过以下命令得知
# 关于grep和wc的用法请查询它们的手册或者网络搜索
$ grep 'model name' /proc/cpuinfo | wc -l
可以认为当平均负载高于CPU数量70%时,应该排查负载高的问题。最推荐的方法是可以监控平均负载,当负载变化跟历史数据出现剧烈变化时分析排查。
平均负载与CPU使用率
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。
比如:CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
预先安装 stress 和 sysstat 包,如 apt install stress sysstat。在这里,我先简单介绍一下 stress 和 sysstat。
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
而 sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。我们的案例会用到这个包的两个命令 mpstat 和 pidstat。
场景一:CPU 密集型进程
模拟CPU使用率100%
$ stress --cpu 1 --timeout 600
第二个终端查看平均负载变化
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
..., load average: 1.00, 0.75, 0.39
第三个终端运行mpstat查看CPU使用率
# -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
$ mpstat -P ALL 5
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95
13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
可以看到一个CPU使用率100%,但其iowait只有0,说明平均负载升高是由于CPU使用率为100%
为确定哪个进程导致CPU使用率100%,我们使用pidstat查询
# 间隔5秒后输出一组数据
$ pidstat -u 5 1
13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command
13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress
可以看到stress进程CPU使用率为100%
场景二:I/O 密集型进程
首先还是运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync:
$ stress -i 1 --timeout 600
还是在第二个终端运行 uptime 查看平均负载的变化情况:
$ watch -d uptime
..., load average: 1.06, 0.58, 0.37
然后,第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
#显示所有CPU的指标,并在间隔5秒输出一组数据
$ mpstat -P ALL 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)13:41:28 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:41:33 all 0.21 0.00 12.07 32.67 0.00 0.21 0.00 0.00 0.00 54.84
13:41:33 0 0.43 0.00 23.87 67.53 0.00 0.43 0.00 0.00 0.00 7.74
13:41:33 1 0.00 0.00 0.81 0.20 0.00 0.00 0.00 0.00 0.00 98.99`
从这里可以看到,1 分钟的平均负载会慢慢增加到 1.06,其中一个 CPU 的系统 CPU 使用率升高到了 23.87,而 iowait 高达 67.53%。这说明,平均负载的升高是由于 iowait 的升高。
那么到底是哪个进程,导致 iowait 这么高呢?我们还是用 pidstat 来查询:
# 间隔5秒后输出一组数据,-u表示CPU指标
$ pidstat -u 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:42:08 UID PID %usr %system %guest %wait %CPU CPU Command
13:42:13 0 104 0.00 3.39 0.00 0.00 3.39 1 kworker/1:1H
13:42:13 0 109 0.00 0.40 0.00 0.00 0.40 0 kworker/0:1H
13:42:13 0 2997 2.00 35.53 0.00 3.99 37.52 1 stress
13:42:13 0 3057 0.00 0.40 0.00 0.00 0.40 0 pidstat
可以发现,还是 stress 进程导致的。
小结
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源。
pidstat:
常用的参数:
-u:默认的参数,显示各个进程的cpu使用统计
-r:显示各个进程的内存使用统计
-d:显示各个进程的IO使用情况
-p:指定进程号
-w:显示每个进程的上下文切换情况
-t:显示选择任务的线程的统计信息外的额外信息
-T { TASK | CHILD | ALL }
这个选项指定了pidstat监控的。TASK表示报告独立的task,CHILD关键字表示报告进程下所有线程统计信息。ALL表示报告独立的task和task下面的所有线程。
注意:task和子线程的全局的统计信息和pidstat选项无关。这些统计信息不会对应到当前的统计间隔,这些统计信息只有在子线程kill或者完成的时候才会被收集。
-V:版本号
-h:在一行上显示了所有活动,这样其他程序可以容易解析。
-I:在SMP环境,表示任务的CPU使用率/内核数量
-l:显示命令名和所有参数
示例一:查看所有进程的 CPU 使用情况( -u -p ALL)
pidstat
pidstat -u -p ALL
pidstat 和 pidstat -u -p ALL 是等效的。
pidstat 默认显示了所有进程的cpu使用率。

详细说明
PID:进程ID
%usr:进程在用户空间占用cpu的百分比,CPU使用率
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令
示例二: cpu使用情况统计(-u)
pidstat -u
使用-u选项,pidstat将显示各活动进程的cpu使用统计,执行”pidstat -u”与单独执行”pidstat”的效果一样。
示例三: 内存使用情况统计(-r)
pidstat -r
使用-r选项,pidstat将显示各活动进程的内存使用统计:

PID:进程标识符
Minflt/s:任务每秒发生的次要错误,不需要从磁盘中加载页
Majflt/s:任务每秒发生的主要错误,需要从磁盘中加载页
VSZ:虚拟地址大小,虚拟内存的使用KB
RSS:常驻集合大小,非交换区物理内存使用KB
Command:task命令名
示例四:显示各个进程的IO使用情况(-d)
pidstat -d

报告IO统计显示以下信息:
PID:进程id
kB_rd/s:每秒从磁盘读取的KB
kB_wr/s:每秒写入磁盘KB
kB_ccwr/s:任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
COMMAND:task的命令名
示例五:显示每个进程的上下文切换情况(-w)
pidstat -w -p 2831

PID:进程id
Cswch/s:每秒主动任务上下文切换数量
Nvcswch/s:每秒被动任务上下文切换数量
Command:命令名
示例六:显示选择任务的线程的统计信息外的额外信息 (-t)
pidstat -t -p 2831

TGID:主线程的表示
TID:线程id
%usr:进程在用户空间占用cpu的百分比
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令
mpstat:
%user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100
%nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
%sys 在internal时间段里,内核时间(%) (system/total)*100
%iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
%irq 在internal时间段里,硬中断时间(%) (irq/total)*100
%soft 在internal时间段里,软中断时间(%) (softirq/total)*100
%idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
CPU使用率
# 只保留各个CPU的数据
$ cat /proc/stat | grep ^cpu
cpu 280580 7407 286084 172900810 83602 0 583 0 0 0
cpu0 144745 4181 176701 86423902 52076 0 301 0 0 0
cpu1 135834 3226 109383 86476907 31525 0 282 0 0 0
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
system(通常缩写为 sys),代表内核态 CPU 时间。idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
而我们通常所说的 CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,用公式来表示就是:
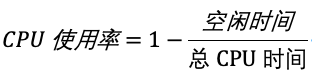
perf top
类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数
-p可指定进程
$ perf top
Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399
Overhead Shared Object Symbol
7.28% perf [.] 0x00000000001f78a4
4.72% [kernel] [k] vsnprintf
4.32% [kernel] [k] module_get_kallsym
3.65% [kernel] [k] _raw_spin_unlock_irqrestore
...
采样数(Samples)、事件类型(event)和事件总数量(Event count)
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
perf record 和 perf report
perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。
而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。
对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。















 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









