







hadoop实时day23–Apache Kafka
今日内容大纲
1、消息传递语义
至多一次 丢失风险
至少一次 重复风险
精准一次 不丢不重
2、kafka如何保证消息不丢失(重要!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!)
A、生产者如何保证?
ack机制
发送重试机
幂等性机制
B、kafka broker如何保证?
分区+副本机制
分区机制
生产者发送消息分区策略
消费着组分配分区数据再平衡
深入聊副本机制
副本数据如何同步
底层消息存储机制
C、消费者如何保证?
自己维护消费偏量
3、kafka日志数据清理
日志删除、日志合并(压缩 compact)
4、kafka可视化工具--Kafka-eagle
-------
5、kafka事务编程
6、kafka和flume集成
7、kafka为什么这么快?
磁盘顺序写
pagecache
zero copy
消息传递语义
-
所谓传递语义:保证通信双方发送接收消息是否安全。
-
At most once:至多一次
数据会有丢失风险 -
At least once:至少一次
数据会有重复的风险 -
Exactly Once:精准一次性
数据不丢不重复
-
kafka监控工具–Kafka-Eagle
-
概述
- 提供了一个web UI页面 可以查看kafka集群相关信息
- 主题信息查看和维护
- 生产者信息
- 消费者信息
- 集群硬件资源使用情况
-
安装部署
见附属资料—《kafka-eagle安装步骤.md》
kafka如何保证消息不丢失–生产者端
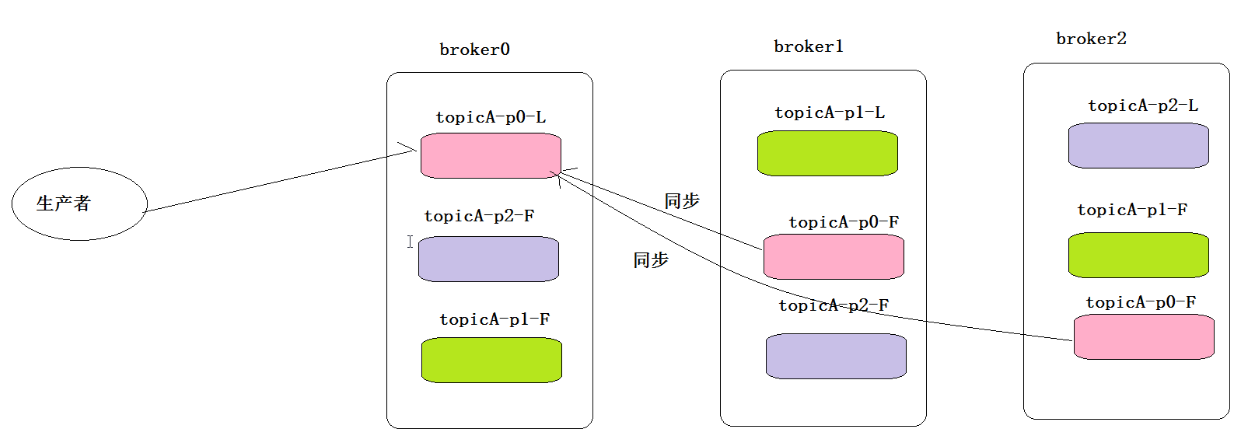
-
ACK机制
-
生产者往kafka broker写数据如何才算成功。
-
前提:
- 生产着只会和leader进行数据交互
- follower只是进行数据同步
-
3个选项
- 0 不等待broker响应 直接发生下一条 数据容易丢失
- 1(默认):等待leader保存消息完毕 发送确认消息
- -1(all):等待所有的副本同步完毕 发送确认消息
-
如何设置
props.put("acks", "all"); -
retry重试机制
-
代码
props.put("retries", "0"); //指定重试发送几次 默认不重试 -
默认情况下 发送失败 客户端不会重试
-
但是针对有些可以恢复的错误 如果不重试 让客户端去处理错误 未免不值得。可以开启重试机制 再次发送消息。
-
-
==幂等性==操作(idempotence)
-
通俗解释:操作多次的结果和操作一次的结果是一样的。不跟次数有关系。这样的操作叫做幂等性操作。
-
幂等性就可以保证数据不重复问题。
-
kafka如何实现幂等性
-
用户使用来说极其简单 开启幂等性操作
props.put("enable.idempotence",true); 如果幂等性配置为true,那此时默认会把acks设置为all,所以一旦设置了幂等性,就不再需要配置 ACK了 -
注意:开启幂等性操作之后 最终目标就十分明确。实现精准一次性。此时会自动把ack设置为all 保证数据不丢失 再加之幂等性保证 数据不重复。
-
原理
- PID :Producer ID 每个生产者编号。
- Sequence Number:针对每个生产者 每个主题的每个分区 自动维护。
-
问题:跨分区之后 就无法实现幂等性操作。 全局==事务==的概念。
-
-
kafka如何保证消息不丢失–broker端
-
1、分区机制
-
在kafka中 消息是以topic归类的 topic可以指定分区存储在不同的broker上。
-
分区好处:
- 分布式存储topic 存不存的下问题
- 同时读写操作 提高并发。
-
生产者发送消息分发策略
-
背景:生产者发送消息到主题的时候 发送给哪个分区呢?
-
前提:一条消息有哪些数据组成的。ProducerRecord
private final String topic; //主题 private final Integer partition; //分区 private final Headers headers; private final K key; //消息key private final V value;//消息value private final Long timestamp; -
分发策略
-
用户指定分区 发送到指定的分区。
-
用户指定消息key
key.hashcode % 分区个数 =分区编号 -
如果用户不指定消息key –轮询策略
-
自定义分区策略
用户写类继承Partitioner 重写自己的分区规则。
-
-
-
消费者分区分配策略–rebalance
-
kafak中有消费者概念的存在 组内有多个不同的消费者。
-
订阅主题的时候 是以组的形式订阅 就会涉及组内消费者如何分配。
-
一个主题的一个分区 只能分配给同一个消费者组内一个消费者。
-
最理想的情况下:
消费者个数 ==主题分区的个数 -
现实中 因为会涉及消费者故障、加入新的消费者、订阅新的主题等动作 导致 rebalance策略。
-
策略
-
Range范围分配策略(默认的分配策略)
- 基于每个topic
-
RoundRobin轮询策略
- 基于所有topic 字典序排序
-
Stricky粘性分配策略
核心思想:前两种策略在发送rebalance的时候 动静太大 会进行重写再分配。
设计目标:已经分配好的保持不动。 发生变化的进行再分配。
具体:
在rebalance之前 策略和RoundRobin类似。
在rebalance的时候 之前分配的保持不动 把需要重新分配的进行RoundRobin即可。
-
-
-
-
2、副本机制
-
背景:针对分区的数据 可以设置副本数(副本因子) 可以解决在分区出现故障之后 副本继续服务。
-
分类
- leader副本:所有的读写操作都是由leader处理。
- follower副本:所有的follower都复制leader的日志数据文件中,如果leader出现故障时,follower就会被选举为leader。
-
核心概念
-
AR:所有副本的集合,包括leader和follower
Assigned Replicas——已分配的副本 -
ISR:同步副本。至少有leader+0或者多个follower
- 注意 只有ISR中副本才有资格选举成为新的leader.
所有与leader副本保持一定程度同步的副本。 ISR副本集合是一个可以动态变化的。 如果跟的leader脚本 就加入进来。 如果落后太多太久,就剔除ISR. #条件: 1、活着。 2、上次同步至今时间差。 10s 注意:上次同步不是指的是follower来拉取数据同步的时间 而是拉取数据并且保存成功之后的时间。 -
OSR:非同步副本
由于follower副本同步滞后过多的副本(不包括 leader 副本) -
结论
- AR=ISR+OSR
- 理想情况下 OSR为空的 所有的副本应该都会跟上节奏。
-
-
副本中leade选举
-
kafka集群中每个节点进程实例叫做broker 。
-
在所有的broker有一个叫做主broker : controller
-
关于kafka集群中 哪一个broker会成为controller 是有zk选举产生。
get /crontroller -
谁先启动 谁先注册成功 谁就是kafka集群的主角色,也就是controller。
-
-
副本中 谁是leader副本 leader出现故障之后 选择谁成为新的leader 都是由controller.
-
在ISR副本中第一个副本就会被优先选举为leader.
-
也只有在ISR集合中副本才有机会成为leader。
-
-
副本的同步机制
-
LEO:log end offset
每个副本最后一条消息的下一个偏移量。 举个栗子:比如p0 LEO=3 [0,1,2] #每个副本都是自己的LEO -
HW : high watermark 水位线
ISR集中中最小LEO的值。 -
同步机制
-
老版本中:基于HW同步的
-
新版本中:leader epoch
epoch:纪元 代表当前的leader是第几代leader 如果leader选举 此数字自动+1 每个副本都会集中存储一个数据 <leader_epoch, startoffset> 举个栗子:当前的leader_epoch =1 <0,0> :第一代leader 0--133offset <1,134>: 第二代leader 134-
-
-
-
kafka数据存储形式
-
kafka中的消息数据以文件的形式存储在linux上。
-
存储目录
############################# Log Basics ############################# # A comma seperated list of directories under which to store log files log.dirs=/export/data/kafka -
底层是以分区作为文件夹来存储数据的。
主题名--分区编号 -
注意:名称以–开头是kafka内置的主题 比如:消费记录的保存:__consumer_offsets-35
-
原理–画图
-
-
ZK在kafka中作用
1、kafka集群broker位置状态信息 2、给broker进行选举 选举controller 3、保存集群topic元数据 名称 分区 leader副本位置 ISR副本 4、保存消费者信息 老版本中 消费记录是保存zk中 新版本中 消费记录是保存在kafka自己内部主题中 5、kafka集群的一些配置参数
-
kafka如何保证消息不丢失–消费者端
-
背景:要想不丢失或者不重复 意味着消费者需要知道自己的消费记录。
-
消费记录也叫做消费偏移量。
-
消费offset可以保存在两个地方
- kafka内部记录保存
- 使用外部存储介质保存–mysql redis
-
拉取数据消费的时候 可以自动提交消费记录 也可以手动提交。
-
在使用内部存储消费offset的时候 不管是自动提交还是手动提交 都有可能出现数据丢失 数据重复的情况。
-
如果需要追求精准一次性 可以自己手动提交 存储在外部介质中 比如mysql
让处理数据的动作和提交动作绑定成为一个事务 通过mysql事务进行绑定。 1、把消费记录保存在mysql中。 topic 、partition、offset 2、消费者在拉取数据消费之前 先去mysql中查询 如果没有值 seek(0) 从零消费 如果有值 seek(数值) 从指定位置开始消费 3、在消费的时候 就开启事务 connection.beginTransaction 消费记录 把消费记录更新插入到mysql 执行成功 提交事务 执行失败 事务回滚
kafka数据存储清理
-
kafka作为消息队列 能够支持消息的存储 但是永久存储又不符合实际情况。
-
kafka提供了两种策略
-
日志删除(Log Deletion):按照指定的策略直接删除不符合条件的日志。
-
基于时间保留策略
log.retention.ms log.retention.minutes log.retention.hours #默认情况下 broker只有log.retention.hours = 168 7天 -
基于文件大小保留策略
log.retention.bytes = -1 #默认-1 表示无穷大 表示不以文件大小进行删除 -
基于日志起始偏移量保留策略
logStartOffset
-
-
日志压缩(Log Compaction):按照消息的key进行整合,有相同key的但有不同value值,只保
留最后一个版本。
-
kafka和Flume集成
-
flume:日志采集传输
-
kafka:消息传递中间件
-
如何搭配
数据源(文件、文件夹)---->flume---->kafka----->离线计算、实时计算 -
flume就相当于生产者。使用sink组件把数据下沉到kafka。
-
采集方案配置
- source:taildir
- channel:memory
- sink:kafka
-
示例–见附件资料
Kafka为什么这么快
- 磁盘数据顺序写 追加日志
- pagecache 页缓存—linux系统级别的缓存
- zero copy 零拷贝技术—linux socket通信优化
Kafka的事务
见附件资料
今日作业
-
名词解释
AR ISR OSR LEO HW LE topic partitions segment replicas leader follower broker controller producer consumer -
验证:生产者或者消费者和一个不存在的主题进行交互 会发生何种情况。
- 直接报错?
- 如果不存在,kafka会不会默认创建一个?
















 7311
7311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











