







Hive中join有三种
1、commonjoin 也称为shuffleJoin 走的是shuffle端的join,适合大表join大表,key的value值如果相等就进行join
2、mapjoin
-
大小表连接:如果一张表的数据很大,另外一张表很小(<1000行),将数据量小的表放在内存中,在map端做join。(join on)
-
需要做不等值join操作(a.x<b.y或者a.x like b.y等)hvie中不支持不等值join操作,如果吧不等值写到where里会造成笛卡尔积,数据异常增大,速度会很慢。甚至会任务无法跑成功,根据mapjoin的计算原理,mapjoin会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,这种情况下即使笛卡尔积也不会对任务运行速度造成太大效率影响。而且hive的where条件本身就是在map阶段进行的操作,所以在where里写入不等值比对的话,也不会造成额外负担。
-
mapjoin结合unionall
-
原始sql
select a.*,coalesce(c.categoryid,’NA’) as app_category from (select * from t_aa_pvid_ctr_hour_js_mes1 ) a left outer join (select * fromt_qd_cmfu_book_info_mes ) c on a.app_id=c.book_id;速度很慢,老办法,先查下数据分布:
select *
from
(selectapp_id,count(1) cnt
fromt_aa_pvid_ctr_hour_js_mes1
group by app_id) t
order by cnt DESC
limit 50;
数据分布如下:
NA 617370129
2 118293314
1 40673814
d 20151236
b 1846306
s 1124246
5 675240
8 642231
6 611104
t 596973
4 579473
3 489516
7 475999
9 373395
107580 10508
我们课看到除了NA是有问题的异常值,还有appid=1-9的数据也是很多,而这些数据是可以关联到的,所以这里不能简单的随机函数了。
而t_qd_cmfu_book_info_mes这张app库表,又有几百万数据,太大以致不能放入内存使用mapjoin。
解决方法:首先将appid=NA和1到9的数据存入一组,并使用mapjoin与维表(维表也限定appid=1-9,这样内存就放得下了)关联,而除此之外的数据存入另一组,使用普通的join,最后使用union all放在一起
select a.*,coalesce(c.categoryid,’NA’) as app_category
from --if app_id isnot number value or <=9,then not join
(select * fromt_aa_pvid_ctr_hour_js_mes1
where cast(app_id asint)>9
) a
left outer join
(select * fromt_qd_cmfu_book_info_mes
where cast(book_id asint)>9) c
on a.app_id=c.book_id
union all
select /*+ MAPJOIN(c)*/
a.*,coalesce(c.categoryid,’NA’) as app_category
from –if app_id<=9,use map join
(select * fromt_aa_pvid_ctr_hour_js_mes1
where coalesce(cast(app_id as int),-999)<=9) a
left outer join
(select * fromt_qd_cmfu_book_info_mes
where cast(book_id asint)<=9) c
--if app_id is notnumber value,then not join
on a.app_id=c.book_id
设置:
当然也可以让hive自动识别,把join编程合适的map join
注:当设置为true的时候,hive会自动获取两张表的数据,判定哪个是小表,然后放在内存中
set hive.auto.convert.join=ture;
select count(*) from store_sales join time_dim on
SMB(Sort-Merge-Buket) Join
场景:
大表对小表应该使用Map join,但是如果是大表对大表,如果进行shuffle,那是要人命的,慢且易异常,既然是两个表进行join,肯定有相同的字段。
tb_a - 5亿(按排序分成五份,每份1亿放在指定的数值范围内,类似于分区表)
a_id
100001 ~ 110000 - bucket-01-a -1亿
110001 ~ 120000
120001 ~ 130000
130001 ~ 140000
140001 ~ 150000tb_b - 5亿(同上,同一个桶只能和对应的桶内数据做join)
b_id
100001 ~ 110000 - bucket-01-b -1亿
110001 ~ 120000
120001 ~ 130000
130001 ~ 140000
140001 ~ 150000注:实际生产环境中,一天的数据可能有50G(举例子可以把数据弄大点,比如说10亿分成1000个bucket)。
原理:
在运行SMB join的时候会重新创建两张表,当然这是在后天默认做的,不需要用户主动去创建,如下
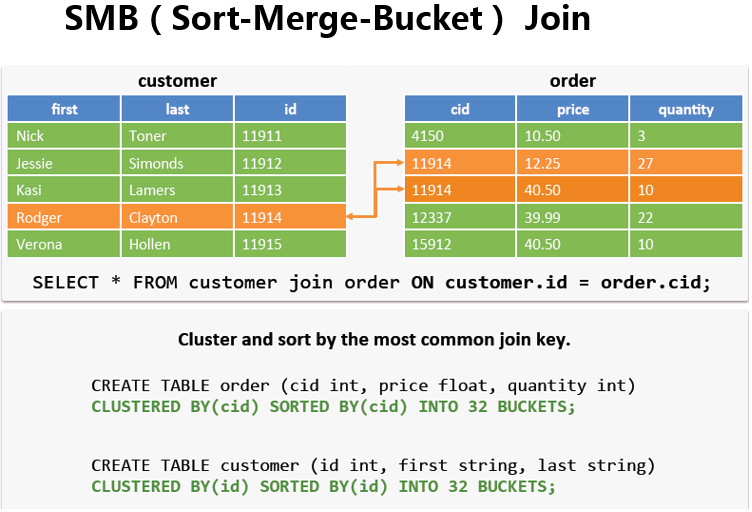
设置(默认是false):
set hive.auto.convert.sortmerge.join=true
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
总结:
其实在写程序的时候,我们就可以知道哪些是大表哪些是小表。
转自:http://www.cnblogs.com/raymoc/p/5323824.html
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











