







第二天 ORACLE查询
注意:
1、and的优先级比or大,所以我们需要用 ( ) 来改变优先级。
2、HAVING 子句不能离开GROUP BY 子句单独使用,HAVING 子句无法完成代替WHERE 子句
3、在SELECT 列表中所有****未包含在聚合函数*中的*列****都应该包含在 GROUP BY 子句中。反之,包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
4、**在分组时使用Where子句和Having子句的本质区别:**使用having子句过滤,是先分组,再过滤,注意:分组的时候是全表扫描的,效率较低。使用where子句过滤,是先过滤再分组,注意:分组的时候仅需要扫描部分数据,效率较高。结论:从语法上看,两者选择简单归纳为,就是group by分组之后需要的条件中有组函数的,就必须得用having,其他都可以直接用where。从性能上看,实际开发中,使用分组的时候尽量先加一个where 的过滤条件。没有组函数的情况下,尽量选择where
5、rowid:物理地址行;使用场景:用来做去重复记录。rownum:返回查询结果的行号。可以限制查询结果集中返回的行数。
第一章 单表查询(掌握)
1、简单条件查询
1、精准查询
需求:查询水表编号为30408的业主记录
-- 查询水表编号为30408的业主记录
select * from t_owners where watermeter = 30408;
查询结果:

2、模糊查询
需求:查询业主名称包含“刘”的业主记录
查询语句:
-- 查询业主名称包含 “刘”的业主记录
select * from t_owners where name like '%刘%'
查询结果:

3、and运算符
需求:查询业主名称包含“刘”的并且门牌号包含5的业主记录
查询语句:
-- 查询业主名称包含“刘”的并且门牌号包含5的业主记录
select * from t_owners where name like '%刘%' and housenumber like '%5%'
查询结果:

4、or运算符
需求:查询业主名称包含“刘”的或者门牌号包含5的业主记录
查询记录:
-- 查询业主名称包含“刘”的或者门牌号包含5的业主记录
select * from t_owners where name like '%刘%' and housenumber like '%5%'
查询结果:

5、and 与 or 运算符混合使用
需求:查询业主名称包含“刘”的或者门牌号包含5的业主记录,并且地址编号为3的记录。
语句:
-- 查询业主名称包含“刘”的或者门牌号包含5的业主记录,并且地址编号为3的记录。
select * from t_owners where
(name like '%刘%' or housenumber like '%5%') and addressid = 3
因为and的优先级比or大,所以我们需要用 ( ) 来改变优先级。
查询结果:

6、范围查询
需求:查询账单记录中用水字数大于等于10000,并且小于等于20000的记录
我们可以用>= 和 <= 来实现:
--查询账单记录中用水字数大于等于10000,并且小于等于20000的记录
select * from t_account where usenum >= 10000 and usenum <= 20000;
我们也可以用between … and … 来实现:
-- 使用 between ... and ..
select * from t_account where usenum between 10000 and 20000;
查询结果:

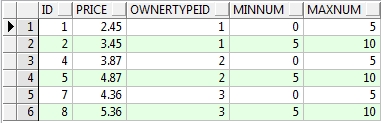
7、空值查询
需求:查询T_PRICETABLE表中MAXNUM为空的记录
语句:
-- 查询T_PRICETABLE表中MAXNUM为空的记录
select * from t_pricetabel where maxnum is null;
查询结构:

需求:查询T_PRICETABLE表中MAXNUM不为空的记录
语句:
-- 查询T_PRICETABLE表中MAXNUM不为空的记录
select * from t_pricetabel where maxnum is not null;
查询结果:
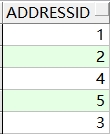
2、去掉重复记录
需求:查询业主表中得地址ID ,不重复显示
语句:
-- 查询业主表中得地址ID ,不重复显示
selct distinct addressid from t_owners
查询结果:
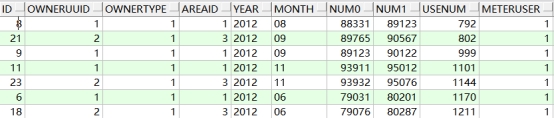
3、排序查询
1、升序排序
需求:对T_ACCOUNT表按使用量进行升序排序
语句:
--需求:对T_ACCOUNT表按使用量进行升序排序
select * from t_account order by usenum -- 默认为升序 ASC
查询结果:
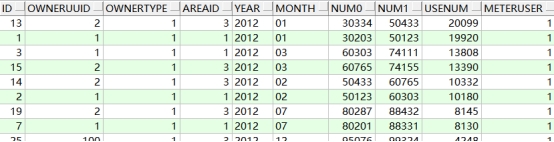
2、降序排序
需求:对T_ACCOUNT 表按使用量进行降序排序
语句:
-- 对T_ACCOUNT 表按使用量进行降序排序
select * from t_account order by usenum DESC -- DESC为降序关键字
查询结果:
问题:SELECT语句的执行效率
select * from t_owners;-- 数据库进行全字段扫描,在查询
select id,name,addressid,housenumber,
watermeter,adddate,ownertypeid from t_owners; -- 指定字段后省去了数据库的全字段扫描
-- 结论:在开发中尽量指定sql语句的字段
4、聚合统计
ORACLE的聚合统计是通过分组函数来实现的,与mysql一致。
1、聚合函数
(1)求和 sum
需求:统计2012年所有用户的用水量总和
-- 统计 2012年所有用户的用水量总和
select sum(usenum) from t_account where year = '2012'
查询结果如下:

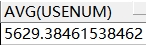
(2)求平均 avg
需求:统计2012 年所有用水量(字数)的平均值
-- 统计 2012年所有用水量(字数)的平均值
select avg(usenum) from t_account where year = '2012';
查询结果如下:
(3)求最大值 max
需求:统计2012年最高用水量(字数)
-- 统计2012年最高用水量(字数)
select max(usenum) from t_account where year = '2012';
查询结果如下: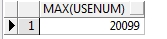
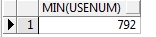
(4)求最小值min
需求:统计2012年最低用水量(字数)
-- 统计2012年最低用水量(字数)
select min(usenum) from t_account where year = '2012';
查询结果如下:
(5)统计记录个数 count
需求:统计业主类型ID为1的业主数量
-- 统计业主类型ID为1的业主数量
select count(*) from t_owbers where ownertypeid =1 ;
查询结果如下:

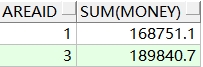
*2. 分组聚合Group by*
需求:按区域分组统计水费合计数
语句:
-- 按区域分组统计水费合计数
select areaid,sum(money) from t_account group by areaid
查询结果:
注意:
在select 列表中所有未包含在聚合函数中的列都应该包含在GROUP BY 子句中。
反之,包含在 GROUP BY子句中的列不必包含在select类表中
*3. 分组后条件查询 having*
需求:查询水费合计大于169000的区域及水费合计
语句:
-- 查询水费合计大于169000的区域及水费合计
select areaid,sum(money) from t_account group by areaid having sum(money)>169000;
查询结果:

注意事项:
HAVING 子句不能离开GROUP BY 子句单独使用,HAVING 子句无法完成代替WHERE
子句
在分组时使用where 子句和having子句的本质的区别:
使用having子句过滤,是先分组,再过滤,注意:分组的时候是全表扫描的,效率较低。
使用where子句过滤,是先过滤在分组,注意:分组的时候仅需要扫描部分数据,效率较高。
结论:
从语法上看,两者选择简单的归纳为,就是group by 分组之后需要的条件中有组函数的,就
必须得用having,其他都直接用where
从性能上述看:实际开发中,使用分组的时候尽量先加一个where的过滤条件。没有组函数的情况下,尽量选择where
5、基于伪劣的查询
在oracle的表的使用过程中,实际表中还有一些附加的列,称为虚拟列(虚拟列)。
伪列就像表中的列一样,但是在表中并不存储。伪列是由oracle进行维护和管理的,用户只能查询,不能进行增删改操作。在sql语句中想要获取伪列的值必须要显式指定伪列。
接下来学习两个伪列:ROWID 和 ROWNUM。
1、ROWID
表中的每一行在数据文件中都有一个物理地址,ROWID伪列返回的就是该行的物理地址。使用ROWID可以快速的定位表中的某一行。ROWID值可以唯一的标识表中的一行。由于ROWID返回的是该行的物理地址,因此使用ROWID可以显示行是如何存储的。
查询语句:
-- 查询时使用ROWID,需要注意:必须显式的指定POWID
select rowid,t.* from t_area t;
--在查询时指定了列名后,就不能直接使用*,如果要使用,必须是:表的名称.*
查询结果如下:
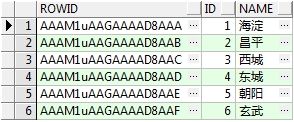
我们可以通过指定ROWID来查询记录
select rowID,T.*
from T_AREA t
where ROWID='AAAM1uAAGAAAAD8AAC';
查询结果如下:

ROWID的组成:
数据对象编号 AAAM1u 数据对象制定的就表
相对数据文件号 AAG 文件号就是指定数据文件编号
数据块号 AAAAD8
数据行号 AAC
rowidd的使用场景:用来做去重记录。
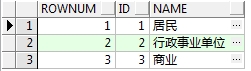
2、ROWNUM
在查询的结果集中,ROWNUM为结果集中每一行标识一个行号,第一行返回1,第二行返回2,以此类推。通过ROWNUM伪列可以限制查询结果集中返回的行数。
查询语句:
select rownum,t.* from T_OWNERTYPE t
查询结果如下:
第二章连接查询(重点)
在MYSQL数据库中接触:内连接、左外连接、右外连接、完全外连接(左连接+右连接)
1. 多表内连接查询
(1)需求:查询显示业主编号,业主名称,业主类型名称,如下图:
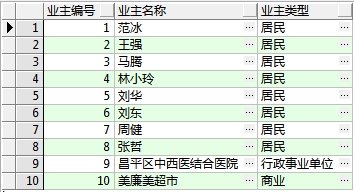
查询语句:
-- 查询显示业主编号,业主名称,业主类型名称
/*
业主表(o):业主编号、业主名称 业主类型id
业主类型表(ot):业主类型名称 id
*/
select o.id "业主编号",o.name "业主名称",ot.name "业主类型名称"
from t_owners o ,t_ownertype ot
where o.ownertypeid = ot.id
(2)需求:查询显示业主编号,业主名称、地址和业主类型,如下图
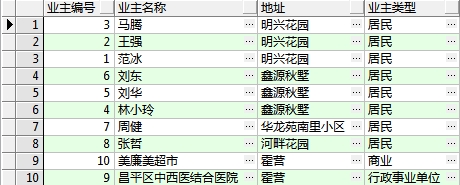
分析:此查询需要三表关联查询。分别是业主表,业主分类表和地址表
语句:

(3)需求:查询显示业主编号、业主名称、地址、所属区域、业主类型,如下图:
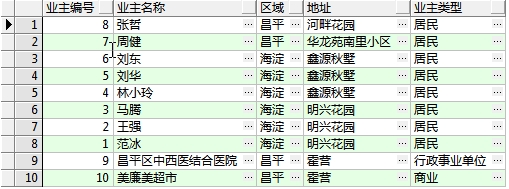
分析:这里需要四个表关联查询,比上边多了一个区域表(T_AREA)
查询语句:

(3)需求:查询显示业主编号、业主名称、地址、所属区域、业主类型,如下图:
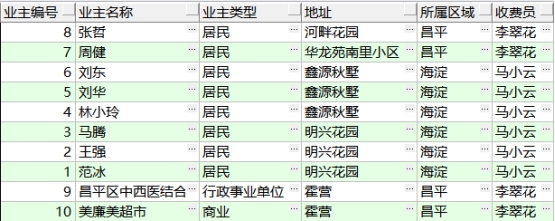
(4)需求:查询显示业主编号、业主名称、地址、所属区域、收费员、业主类型,如下图:
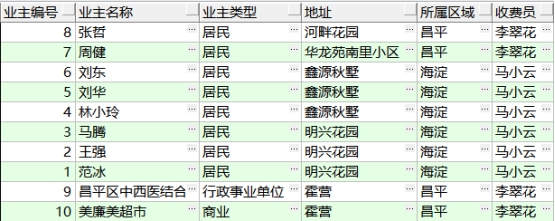
分析:此查询比上边又多了一个表 T_OPERATOR
语句:

2、左外连接查询
需求:查询业主的账务记录,显示业主编号、名称、年、月、金额。如果此业主没有账务记录也要列出姓名。
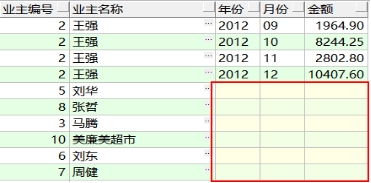
按照SQL1999标准的语法,查询语句如下:

按照ORACLE提供的语法,就很简单了:
SELECT ow.id,ow.name,ac.year ,ac.month,ac.money FROM T_OWNERS ow,T_ACCOUNT ac
WHERE ow.id=ac.owneruuid(+)
如果是左外连接,就在左表所在的条件一端填上(+)
3. 右外连接查询
需求:查询业主的账务记录,显示业主编号、名称、年、月、金额。如果账务记录没有对应的业主信息,也要列出记录。如下图:
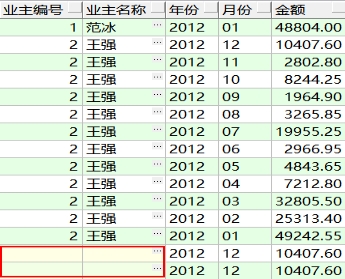
SQL1999标准的语句

ORACLE的语法

如果是右外连接,就在左表所在的条件一端填上(+)**
第三章 子查询 (掌握)
子查询:在一个查询中包含另外一个查询语句
例如:select * from(select id,name from User)
select id ,(select name from user) from 表
1、单行子查询
- 内部查询只返回一条记录
- 单行操作符
需求:查询2012年1月用水量大于平均值的账单记录
语句
-- 查询2012年1月用水量大于平均值的账单记录
/*
分析:
账单表:年月、月份
条件:用水量大于平均值
*/
select * from t account where year='2012' and month = '01'
and usenum>(select avg(usenum)from t_account where year = '2012' and month = '01')
查询结果:

平均值为:

2、多行子查询
- 内部查询返回了多条记录
- 多行操作符

1、in 运算符
(1)需求:查询地址编号为1 、3、4 的业主记录
分析:如果我们用or运算符编写,sql非常繁琐,所以我们用in来进行查询
语句如下:
--查询地址编号为1 、3、4 的业主记录(使用or运算符)
select * from t_owners where addressid = 1 or address = 3 or addressid =4;
--查询地址编号为1 、3、4 的业主记录(使用in)
select * from t_owners where address in(1,3,4);
查询结果如下:

(2)需求:查询地址含有“花园”的业主的信息
语句:
-- 查询地址含有“花园”的业主信息
select * from t_owners where addressid
in (SELECT ID FROM t_address where name like '%花园%');
查询结果:

(3)需求:查询地址不含有“花园”的业主的信息
语句:
-- 查询地址含不有“花园”的业主信息
select * from t_owners where addressid
not in (SELECT ID FROM t_address where name like '%花园%');
查询结果:

2、all运算符
需求:查询2012年账单中,使用量大于2012年3月最大使用量的账单数据
分析:此查询除了可以用max函数来实现查询
-- 查询2012年账单中,使用量大于2012年3月最大使用量的账单数据
-- 外查询:查2012年账单信息; 条件:使用量大于2012年3月最大使用量
-- 子查询:查询2012年3月最大使用量
select * from t_account where usenum >
(select maxz(usenum) from t_account where year='2012' and month = '03');
此处之外,还可以使用all运算符来实现相同的效果,语法如下:
select * from t_account where
usenum > all(select usenum from t_account where year = '2012' and month = '03');
查询结果如下:

第四章 分页查询(重点)
MySQL中的分页语句:select * from T_OWNERS LIMIT 3,3;
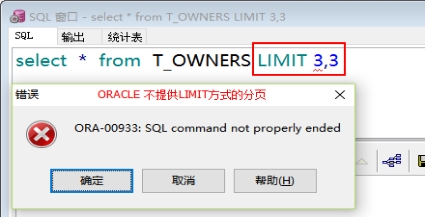
1、简单分页
需求:分页查询账单表T_ACCOUNT,每页10条记录
分析1:我们在ORACLE进行分页查询,需要用到伪列ROWNUM 。
我们首先显示前10条记录,语句如下:
/*简单分页
分页查询账单表 T_ACCOUNT,每页10 条记录
*/
-- 首先:先显示前10条记录
select rownum,t.* from t_account t where rownum <=10;
显示结构如下;
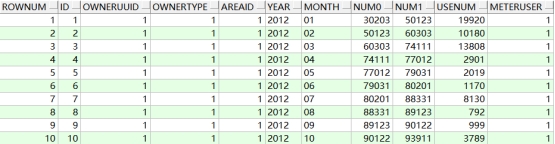
那么我们显示第11条到第20条的记录呢?编写语句:
-- 显示第11条到第20条的记录
select rownum,t.* from t_account t where rownum > 10 and rownum <= 20;
查询结果:

嗯?怎么没有结果?
这是因为rownum是在查询语句扫描每条记录时产生的,所以不能使用“大于”或“大于等于”符号,只能使用“小于”或“小于等于” 。(只用“等于”也不行)
ROWNUM产生过程: rownum是基于ORACLE在扫描表中每条记录时产生,表中的记录是逐行扫描,每扫描到一行,rownum就赋予一个行号
那怎么办呢?
分析2:在oracle中进行分页查询,除了要用到伪列rownum,还需要嵌入查询(子查询)。
-- 使用伪列rownum和嵌套查询,进行分页(第11条到第20条的记录)
select * from
(select rownum rm,t.* from t_account t where rownum <=20 )
where rm>10;
查询结果如下:
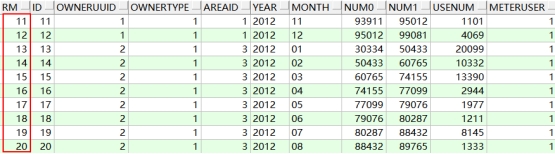
2、基于排序的分页
需求:分页查询账单表T_ACCOUNT,每页10条记录,按使用字数(usenum)降序排序。
我们查询第2页数据,如果基于上边的语句添加排序,语句如下:
/*基于排序的分页
分页查询账单表T_ACCOUNT,每页10条记录,按使用字数(USENUM)降序排序
*/
-- 查询第二页;第10条记录到第20条记录
select * from
(select rownum rm,t.* from t_account t where rownum <= 20 order by usenum desc)
where rm > 10;
查询结果如下:
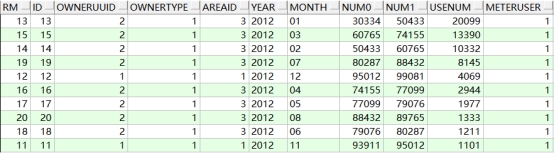
经过验证,我们看到第2页的结果应该是下列记录
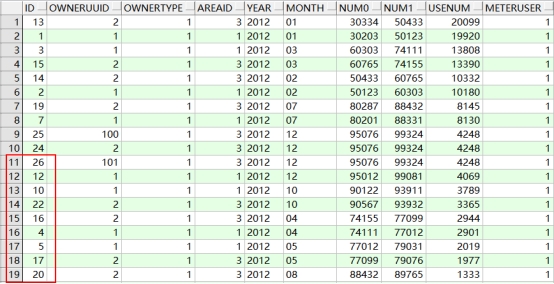
所以推断刚才的语句是错误的!那么什么是错误的呢?
我们可以先单独执行嵌套查询里面的那句话
select rownum r,t.* from T_ACCOUNT t where rownum<=20 order by usenum desc
你会看到查询结果如下:
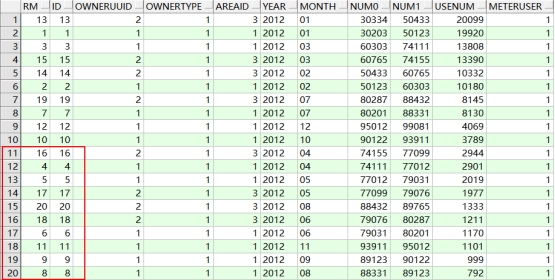
你会发现排序后的rownum是乱序的。这是因为rownum伪列的产生是在表记录扫描时产生的,而排序是后进行的,而排序是后进行的,排序时ROWNUM已经产生了,所以排序后rownum是乱的。
那该如何写呢?
很简单,我们只要再嵌套一层循环(一共三层),让结果先排序,然后对排序后的结果再产生ROWNUM,这样就不会乱了。
语句如下:
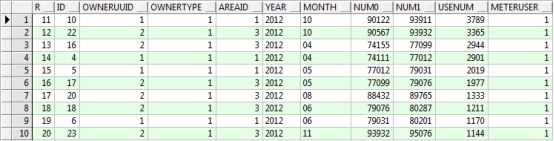
select * from
(select rownum r,t.* from
(select * from T_ACCOUNT order by usenum desc) t
where rownum <=20
)
where r>10
结果如下:
第五章 单行函数(掌握)
1、字符函数
| *函 数* | *说 明* |
|---|---|
| ASCII | 返回对应字符的十进制值 |
| CHR | 给出十进制返回字符 |
| CONCAT | 拼接两个字符串,与 || 相同 |
| INITCAP | 将字符串的第一个字母变为大写 |
| INSTR | 找出某个字符串的位置 |
| INSTRB | 找出某个字符串的位置和字节数 |
| LENGTH | 以字符给出字符串的长度 |
| LENGTHB | 以字节给出字符串的长度 |
| LOWER | 将字符串转换成小写 |
| LPAD | 使用指定的字符在字符的左边填充 |
| LTRIM | 在左边裁剪掉指定的字符 |
| RPAD | 使用指定的字符在字符的右边填充 |
| RTRIM | 在右边裁剪掉指定的字符 |
| REPLACE | 执行字符串搜索和替换 |
| SUBSTR | 取字符串的子串 |
| SUBSTRB | 取字符串的子串(以字节) |
| SOUNDEX | 返回一个同音字符串 |
| TRANSLATE | 执行字符串搜索和替换 |
| TRIM | 裁剪掉前面或后面的字符串 |
| UPPER | 将字符串变为大写 |
常用的字符函数讲解:
(1)求字符串长度LENGTH
语句:
-- 求字符串长度 LENGTH
select length('ABCD') from dual;
-- 说明:dual 是ORACLE 的内部表(虚表),表中仅有一行一列。
显示结果为:

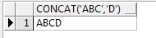
(2)字符串拼接CONCAT
语句:
-- 字符串拼接concat
select concat('ABC','D') from dual;
查询结果如下
我们也可以用||对字符串进行拼接
-- 字符串拼接,使用“||”符号
select 'ABC' || 'D' FROM DUAL;

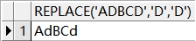
(3)字符串替换REPLACE
语句:
-- 字符串替换 replace
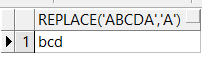
select replace('ADBCD','D','d') from dual;
查询结果如下:
问题:请问 select replace(‘ADBCD’,‘D’) from dual 执行结果?
答案:把姓名中所有的A全部删除掉
select replace('ADBCD','D') from dual ;
(4)求字符串的子串substr
语句:
-- 获取子字符串substr(字符串,起始位置,截取长度)
select substr('ABCD',2,2) from dual;
显示结果为:

问题:以下查询执行完成后,结果是什么?
select substr('Jackie',2) from dual;-- 从左边位置2开始截取,截取到最后
select substr('Jackie',2,0) from dual;-- 从左边位置2开始截取,截取0个,就相当于没有截取。取值为空字符串
select substr('Jackie',2.9,3.2) from dual;-- 先把小数转为整数(不会四舍五入),在截取
select substr('Jackie',-4,2) from dual; -- 从右边位置开始截取2位;参数2:从右边取n位;参数3:取出的结果要m个值
面试题:请问substr()函数截取时下标是从0 还是从1开始?
答案:对oracle来说,substr下标从0或从1都不会有问题,而下标还可写成负数形式,表示从后向取值

2. 数值函数
| *函数* | *说明* |
|---|---|
| ABS(value) | 绝对值 |
| CEIL(value) | 大于或等于value的最小整数 |
| COS(value) | 余弦 |
| COSH(value) | 反余弦 |
| EXP(value) | e的value次幂 |
| FLOOR(value) | 小于或等于value的最大整数 |
| LN(value) | value的自然对数 |
| LOG(value) | value的以10为底的对数 |
| MOD(value,divisor) | 求模 |
| POWER(value,exponent) | value的exponent次幂 |
| ROUND(value,precision) | 按precision 精度4舍5入 |
| SIGN(value) | value为正返回1;为负返回-1;为0返回 0. |
| SIN(value) | 余弦 |
| SINH(value) | 反余弦 |
| SQRT(value) | value 的平方根 |
| TAN(value) | 正切 |
| TANH(value) | 反正切 |
| TRUNC(value,按precision) | 按照precision 截取value |
| VSIZE(value) | 返回value在ORACLE的存储空间大小 |
常用数值函数讲解:
(1)四舍五入函数ROUND
语句:
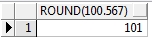
-- 数值函数:round(四舍五入)
select round(100.567) round dual;
查询结果如下:
语句:
-- 数值函数:round(数值,小数位数)
select round(100.567,2) from dual;
查询结果如下:
 **
**
(2)截取函数TRUNC
语句:
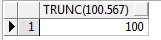
-- 数值函数:trunc 不会四舍五入,直接截取
select trunc(100.567) from dual;
查询结果:
 **
**
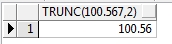
语句:
-- 数值函数:trunc
select trunc(100.567,2)from dual;
(3)取模MOD
语句:
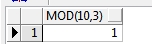
select mod(10,3) from dual;
结果:
3. 日期函数
| *函 数* | *描 述* |
|---|---|
| ADD_MONTHS | 在日期date上增加count个月 |
| GREATEST(date1,date2,. . .) | 从日期列表中选出最晚的日期 |
| LAST_DAY( date ) | 返回日期date 所在月的最后一天 |
| LEAST( date1, date2, . . .) | 从日期列表中选出最早的日期 |
| MONTHS_BETWEEN(date2,date1) | 给出 Date2 - date1 的月数(可以是小数) |
| NEXT_DAY( date,’day’) | 给出日期date之后下一天的日期,这里的day为星期,如: MONDAY,Tuesday等。 |
| NEW_TIME(date,’this’,’other’) | 给出在this 时区=Other时区的日期和时间 |
| ROUND(date,’format’) | 未指定format时,如果日期中的时间在中午之前,则将日期中的时间截断为12 A.M.(午夜,一天的开始),否则进到第二天。时间截断为12 A.M.(午夜,一天的开始),否则进到第二天。 |
| TRUNC(date,’format’) | 未指定format时,将日期截为12 A.M.( 午夜,一天的开始). |
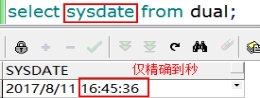
我们用sysdate这个系统变量来获取当前日期和时间。
语句如下:
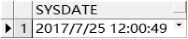
select sysdate from dual;--获取当前系统的日期时间
查询结果如下:
常见日期函数讲解:
(1)加月函数ADD_MODTHS:在当前日期基础上加指定的月
语句:
-- 日期函数:ADD_MODTHS 在指定日期的基础上增加或减少月份值
select add_months(sysdate,2) from dual;
查询结果如下:

问题:执行下面sql语句会显示什么?
select add_months(sysdate,-2) from dual;

(2)求所在月最后一天LAST_DAY
语句:
-- 日期函数:LAST_DAY获指定日期所属当月的最后一天
SELECT last_day(sysdate) from dual;
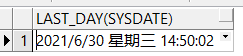
select last_day(add_months(sysdate,1)) from dual;

(3)日期截取TRUNC
语句:
-- 日期函数:trunc 截取指定日期中的指定值(可以是年、月、日、时、分、秒)
select trunc(sysdate) from dual;-- 截取掉时间值,保留日期值
查询结果如下:

语句:
select trunc(sysdate,'yyyy') from dual;-- 按年截取(保留年份,月和日为初始值1)
查询结果如下:

语句:
select trunc(sysdate,'mm') from dual;-- 按月截取(保留年和月,日的初始值为1)
查询结果如下:

select trunc(sysdate,'dd') from dual;-- 按日截取
select trunc(sysdate,'hh') from dual;-- 按时截取
select trunc(sysdate,'mi') from dual;-- 按分截取
4. 转换函数
| 函 数 | 描 述 |
|---|---|
| CHARTOROWID | 将 字符转换到 rowid类型 |
| CONVERT | 转换一个字符节到另外一个字符节 |
| HEXTORAW | 转换十六进制到raw 类型 |
| RAWTOHEX | 转换raw 到十六进制 |
| ROWIDTOCHAR | 转换 ROWID到字符 |
| TO_CHAR | 转换日期格式到字符串 |
| TO_DATE | 按照指定的格式将字符串转换到日期型 |
| TO_MULTIBYTE | 把单字节字符转换到多字节 |
| TO_NUMBER | 将数字字串转换到数字 |
| TO_SINGLE_BYTE | 转换多字节到单字节 |
常用转换函数
(1)数字转字符串TO_CHAR
语句:
-- 转换函数:to_char
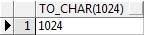
select to_char(1024) from dual; -- 把数字转为字符串
查询结果:
select to_char(123456789,'000,000,000') from dual; -- 把数字按格式转为字符串

(2)日期转字符串
语句:
-- 转换函数:把日期按照指定格式转为字符串
select to_char(sysdate,'yyyy-mm-dd') from dual;
查询结果:

语句:
select to_char(sysdate,'yyyy-mm-dd hh:mi:ss') from dual;
查询结果:

语句:
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual; --小时是按24小时制
查询结果:

语句:
select to_char(sysdate,'yyyy-fmmm-fmdd fmhh:fmmi:fmss') from dual;-- 转换的时候去除0
查询结果:
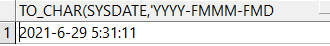
语句:
select to_char(sysdate,'yyyy') from dual; --截取年
查询结果: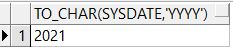
语句:
select to_char(sysdate,'yyyy"年"mm"月"dd"日"hh"时"mi"分"ss"秒"') from dual;
查询结果:

扩展内容:
使用to_char(sysdate,‘HH’); ‘HH’ 可以使用如下表中的参数替换
| *模板* | *描述* |
|---|---|
| HH | 一天的小时数 (01-12) |
| HH12 | 一天的小时数 (01-12) |
| HH24 | 一天的小时数 (00-23) |
| MI | 分钟 (00-59) |
| SS | 秒 (00-59) |
| SSSS | 午夜后的秒 (0-86399) |
| AM or A.M. or PM or P.M. | 正午标识(大写) |
| am or a.m. or pm or p.m. | 正午标识(小写) |
| Y,YYY | 带逗号的年(4 和更多位) |
| YYYY | 年(4和更多位) |
| YYY | 年的后三位 |
| YY | 年的后两位 |
| Y | 年的最后一位 |
| MONTH | 全长大写月份名(9字符) |
| Month | 全长混合大小写月份名(9字符) |
| month | 全长小写月份名(9字符) |
| MON | 大写缩写月份名(3字符) |
| Mon | 缩写混合大小写月份名(3字符) |
| mon | 小写缩写月份名(3字符) |
| MM | 月份 (01-12) |
| DAY | 全长大写日期名(9字符) |
| Day | 全长混合大小写日期名(9字符) |
| day | 全长小写日期名(9字符) |
| DY | 缩写大写日期名(3字符) |
| Dy | 缩写混合大小写日期名(3字符) |
| dy | 缩写小写日期名(3字符) |
| DDD | 一年里的日子(001-366) |
| DD | 一个月里的日子(01-31) |
| D | 一周里的日子(1-7;SUN=1) |
| W | 一个月里的周数 |
| WW | 一年里的周数 |
| CC | 世纪(2 位) |
| J | Julian 日期(自公元前4712年1月1日来的日期) |
| Q | 季度 |
(3)字符串转日期TO_DATE
语句:
select to_date('2017-01-01','yyyy-mm-dd') from dual; --把字符串按指定格式转为日期
查询结果如下:

(4)字符串转数字TO_NUMBER
语句:
select to_number('100') from dual;
5. 其它函数(重点)
(1)空值处理函数 NVL
用法:
NVL(检测的值,如果为null的值)
语句:
select NVL(NULL,0) from dual;
查询结果如下:
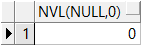
需求:
显示价格表中业主类型ID为1的价格记录,如果上限值为NULL,则显示9999999
语句:
--显示价格表中业主类型ID为1的价格记录,如果上限值为NULL,则显示9999999
select price,minnum,NVL(maxnum,9999999) from t_pricetable where ownertypeid = 1;
查询结果:
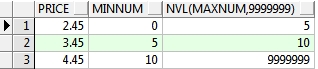
(2)空值处理函数 NVL2
用法:
NVL2(检测的值,如果不为null的值,如果为null的值);
需求:显示价格表中业主类型ID为1的价格记录,如果上限值为NULL,显示“不限”

(3)条件取值 decode
DECODE()函数:多数值判断,类似于if … else 语句,不同的是decode()判断的是数值
而不是逻辑条件
在SQL优化中,推荐DECODE(),可以减少I/O次数
语法:
decode(条件,值1,翻译值1,值2,翻译值2....,缺省值)
【功能】 根据条件返回相应值
需求:显示下列信息(不要关联查询业主类型表,直接判断1 2 3 的值)
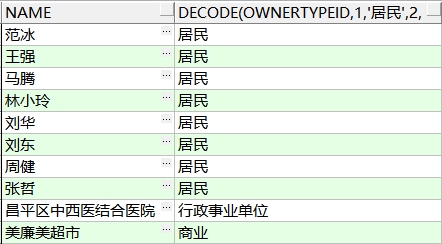
语句:
-- 显示下列信息(不要关联查询业务类型表,直接判断1 2 3的值)
select NAME,DECODE(ownertypeid,1,'居民',2,'行政事业单位',3,'商业') as "类型"
from t_owners;
上边的语句也可以用case when then 语句来实现
select name,(
case ownertypeid
when 1 then '居民'
when 2 then '行政事业单位'
when 3 then '商业'
end
) as 类型
from t_owners;
还有另外一种写法:
select name,(case
when ownertypeid = 1 then '居民'
when ownertypeid = 2 then '行政事业单位'
when ownertypeid = 3 then '商业'
else '其他'
END
) AS 类型
from t_owners;
第六章 行列转换(重点)
需求:按月份统计2012年各个地区的水费,如下图

语句:
select (select name from T_AREA where id= areaid ) 地区,
sum( case when month='01' then money else 0 end) 一月,
sum( case when month='02' then money else 0 end) 二月,
sum( case when month='03' then money else 0 end) 三月,
sum( case when month='04' then money else 0 end) 四月,
sum( case when month='05' then money else 0 end) 五月,
sum( case when month='06' then money else 0 end) 六月,
sum( case when month='07' then money else 0 end) 七月,
sum( case when month='08' then money else 0 end) 八月,
sum( case when month='09' then money else 0 end) 九月,
sum( case when month='10' then money else 0 end) 十月,
sum( case when month='11' then money else 0 end) 十一月,
sum( case when month='12' then money else 0 end) 十二月
from T_ACCOUNT where year='2012' group by areaid
需求:按照季度统计2012年各个地区的水费,如下图

语句如下:
select (select name from T_AREA where id= areaid ) 地区,
sum( case when month>='01' and month<='03' then money else 0 end) 第一季度,
sum( case when month>='04' and month<='06' then money else 0 end) 第二季度,
sum( case when month>='07' and month<='09' then money else 0 end) 第三季度,
sum( case when month>='10' and month<='12' then money else 0 end) 第四季度
from T_ACCOUNT where year='2012' group by areaid
第七章 集合运算(掌握)
1. 什么是集合运算
集合运算,集合运算就是将两个或者多个结果集组合成为一个结果集。
集合运算包括:
UNION ALL(并集),返回各个查询的所有记录,包括重复记录。
UNION(并集),返回各个查询的所有记录,不包括重复记录。
INTERSECT(交集),返回两个查询共有的记录。
MINUS(差集),返回第一个查询检索出的记录减去第二个查询检索出的记录之后剩余的记录。
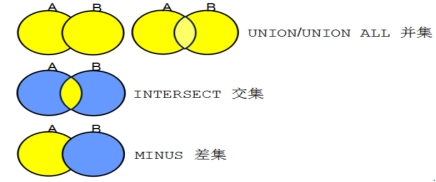
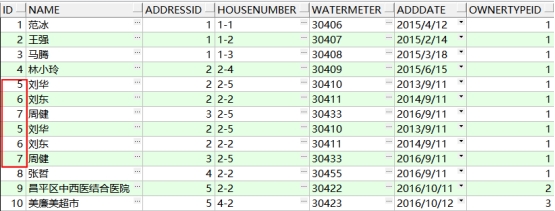
2、并集运算

UNION ALL 不去掉重复记录

结果如下:
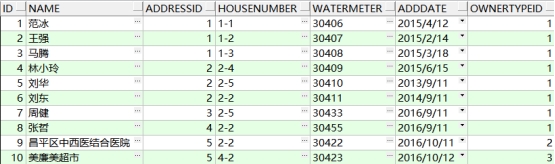
UNION 去掉重复记录

3. 交集运算

结果:

4. 差集运算

结果:

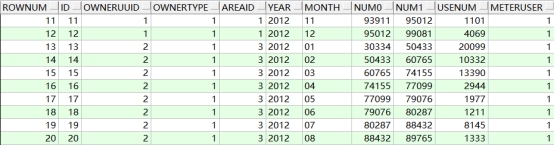
如果我们用minus运算符来实现分页,语句如下:

结果:
第八章 综合案例
为《自来水收费系统》开发统计模块相关的功能
1.收费日报单(总)
统计某日的收费,按区域分组汇总,效果如下:

语句:
select (select name from T_AREA where id= areaid ) 区域,
sum(usenum)/1000 "用水量(吨)" ,sum(money) 金额
from T_ACCOUNT
where to_char(feedate,'yyyy-mm-dd')='2012-05-14'
group by areaid
2.收费日报单(收费员)
统计某收费员某日的收费,按区域分组汇总,效果如下:

语句:
select (select name from T_AREA where id= areaid ) 区域,
sum(usenum)/1000 "用水量(吨)" ,sum(money) 金额
from T_ACCOUNT
where to_char(feedate,'yyyy-mm-dd')='2012-05-14'
and feeuser=2
group by areaid
3.收费月报表(总)
统计某年某月的收费记录,按区域分组汇总

语句:
select (select name from T_AREA where id= areaid ) 区域,
sum(usenum)/1000 "用水量(吨)" ,sum(money) 金额
from T_ACCOUNT
where to_char(feedate,'yyyy-mm')='2012-05'
group by areaid
*4.收费月报表(收费员)*
统计某收费员某年某月的收费记录,按区域分组汇总
语句:
select (select name from T_AREA where id= areaid ) 区域,
sum(usenum)/1000 "用水量(吨)" ,sum(money) 金额
from T_ACCOUNT
where to_char(feedate,'yyyy-mm')='2012-05' and feeuser=2
group by areaid
*5.收费年报表(分区域统计)*
统计某年收费情况,按区域分组汇总,效果如下:

语句:
select (select name from T_AREA where id= areaid ) 区域,
sum(usenum)/1000 "用水量(吨)" ,sum(money) 金额
from T_ACCOUNT
where to_char(feedate,'yyyy')='2012'
group by areaid
*6.收费年报表(分月份统计)*
统计某年收费情况,按月份分组汇总,效果如下
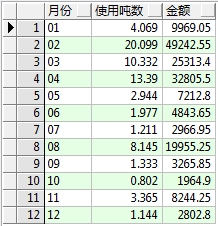
语句:
select to_char(feedate,'mm') 月份,sum(usenum)/1000 使用吨数,sum(money) 金额
from T_ACCOUNT
where to_char(feedate,'yyyy')='2013'
GROUP BY to_char(feedate,'mm')
ORDER BY to_char(feedate,'mm')
*7.收费年报表(分月份统计)*
统计某年收费情况,按月份分组汇总,效果如下

语句:
select '用水量(吨)' 统计项,
sum (case when to_char(feedate,'mm')='01' then usenum else 0 end )/1000 一月,
sum (case when to_char(feedate,'mm')='02' then usenum else 0 end )/1000 二月,
sum (case when to_char(feedate,'mm')='03' then usenum else 0 end )/1000 三月,
sum (case when to_char(feedate,'mm')='04' then usenum else 0 end )/1000 四月,
sum (case when to_char(feedate,'mm')='05' then usenum else 0 end )/1000 五月,
sum (case when to_char(feedate,'mm')='06' then usenum else 0 end )/1000 六月,
sum (case when to_char(feedate,'mm')='07' then usenum else 0 end )/1000 七月,
sum (case when to_char(feedate,'mm')='08' then usenum else 0 end )/1000 八月,
sum (case when to_char(feedate,'mm')='09' then usenum else 0 end )/1000 九月,
sum (case when to_char(feedate,'mm')='10' then usenum else 0 end )/1000 十月,
sum (case when to_char(feedate,'mm')='11' then usenum else 0 end )/1000 十一月,
sum (case when to_char(feedate,'mm')='12' then usenum else 0 end )/1000 十二月
from T_ACCOUNT
where to_char(feedate,'yyyy')='2013'
UNION ALL
select '金额(元)' 统计项,
sum (case when to_char(feedate,'mm')='01' then money else 0 end ) 一月,
sum (case when to_char(feedate,'mm')='02' then money else 0 end ) 二月,
sum (case when to_char(feedate,'mm')='03' then money else 0 end ) 三月,
sum (case when to_char(feedate,'mm')='04' then money else 0 end ) 四月,
sum (case when to_char(feedate,'mm')='05' then money else 0 end ) 五月,
sum (case when to_char(feedate,'mm')='06' then money else 0 end ) 六月,
sum (case when to_char(feedate,'mm')='07' then money else 0 end ) 七月,
sum (case when to_char(feedate,'mm')='08' then money else 0 end ) 八月,
sum (case when to_char(feedate,'mm')='09' then money else 0 end ) 九月,
sum (case when to_char(feedate,'mm')='10' then money else 0 end ) 十月,
sum (case when to_char(feedate,'mm')='11' then money else 0 end ) 十一月,
sum (case when to_char(feedate,'mm')='12' then money else 0 end ) 十二月
from T_ACCOUNT
where to_char(feedate,'yyyy')='2013'
*8.统计用水量,收费金额(分类型统计)*
根据业主类型分别统计每种居民的用水量(整数,四舍五入)及收费金额 ,如果该类型在台账表中无数据也需要列出值为0的记录 , 效果如下:
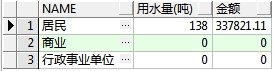
语句:
select ow.name,
nvl(round(sum(usenum)/1000),0) "用水量(吨)",nvl(sum(money),0) 金额
from T_OWNERTYPE ow,T_ACCOUNT ac
where ow.id = ac.ownertype(+)
group by ow.name
分析:这里所用到的知识点包括左外连接、sum()、分组group by 、round() 和nvl()
9、统计每个区域的业主户数,并列出合计

语句:
select ar.name 区域,count(ow.id) 业主户数
from T_AREA ar,T_OWNERS ow,T_ADDRESS ad
where ad.id=ow.addressid and ad.areaid=ar.id
group by ar.name
union all
select '合计',count(1) from T_OWNERS
10.统计每个区域的业主户数,如果该区域没有业主也要列出0
如图:
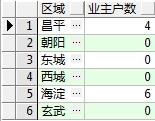
语句:
select ar.name 区域,count(owad.id) 业主户数
from T_AREA ar ,
(
select ow.id,ow.name,ad.areaid from T_OWNERS ow,T_ADDRESS ad where ow.addressid=ad.id
)
owad
where ar.id=owad.areaid(+)
group by ar.name
第九章 总结
1. 知识点总结
2. 上机任务
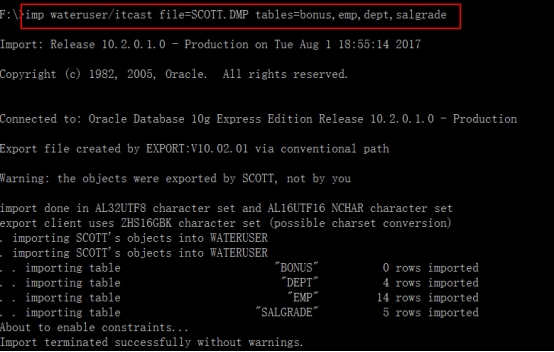
*1.表结构分析*
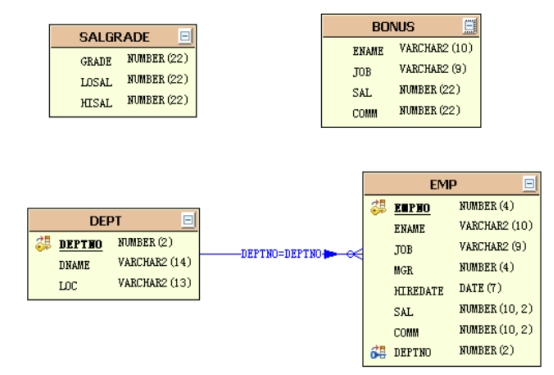
*Scott********用户案例下表分析*
雇员表:EMP
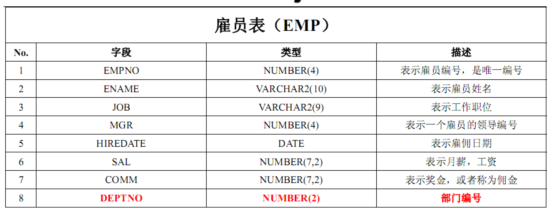
部门表:Dept
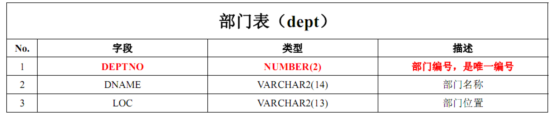
工资等级表:Salgrade
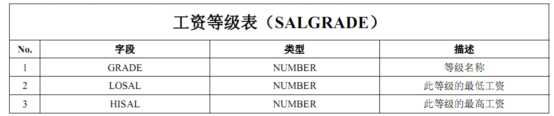
奖金表:Bonus
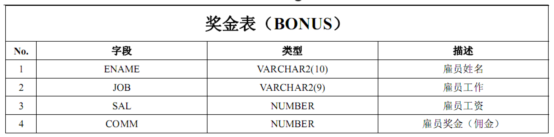
****2.练习题
- List item
****
1.请从表EMP中查找工种是职员CLERK或经理MANAGER的雇员姓名、工资。
2.请在EMP表中查找部门号在10-30之间的雇员的姓名、部门号、工资、工作。
3.请从表EMP中查找姓名以J开头所有雇员的姓名、工资、职位。
4.请从表EMP中查找工资低于2000的雇员的姓名、工作、工资,并按工资降序排列。
5.请从表中查询工作是CLERK的所有人的姓名、工资、部门号、部门名称以及部门地址的信息。
6.在表EMP中查询所有工资高于JONES的所有雇员姓名、工作和工资。
7.列出没有对应部门表信息的所有雇员的姓名、工作以及部门号。
8.查找工资在1000~3000之间的雇员所在部门的所有人员信息
9.雇员中谁的工资最高。
10.查询所有雇员的姓名、SAL与COMM之和。
11.查询所有1981年7月1日以前来的员工姓名、工资、所属部门的名字
12.查询各部门中1981年1月1日以后来的员工数
13.查询所有在CHICAGO工作的经理MANAGER和销售员SALESMAN的姓名、工资
14.查询列出来公司就职时间超过24年的员工名单
15.查询于1981年来公司所有员工的总收入(SAL和COMM)
16.查询显示每个雇员加入公司的准确时间,按××××年××月××日 时分秒显示。
17.查询公司中按年份月份统计各地的录用职工数量
18.查询列出各部门的部门名和部门经理名字
19.查询部门平均工资最高的部门名称和最低的部门名称
20.查询与雇员号为7521员工的最接近的在其后进入公司的员工姓名及其所在部门名
第十章 相关问题汇总及解答
1、在执行select trunc(sysdate,‘ss’) from dual语句时,发生以下错误
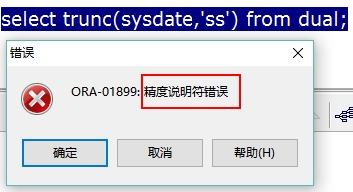
解答:ORACLE中的sysdate是获取当前系统的年月日时分秒(仅精确到秒)。
2、全字段扫描查询和指定字段扫描查询的区别?

解答:在执行以上SQL查询语句时,会先去数据库中找到t_owners表,在数据表确定后,语句中"*"表示是所有字段,此时会去扫描t_owners表所有的字段。
在扫描所有字段后,会把全部字段代替"*",继续执行查询
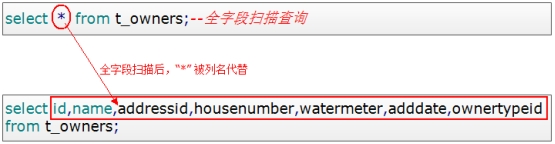
而指定字段查询,省去了扫描数据表中所有字段这一步骤,效率上有所提升。
3、关于translate函数
select translate(‘zha12#3sa4’, ‘#1234’, ‘@’) from dual;
– 对比replace
– replace 字符串级别的替换
select replace(‘accd’,‘cd’,‘ef’) from dual; --结果为: acef
– translate 字符级别的替换
select translate(‘acdd’,‘cd’,‘ef’) from dual; --结果为:aeff
–语法:translate(expr,from_string,to_string)
–示例1:将数字全部转换为 9,其他的大写字母转换为 #
select translate(‘123ITCAST789’,
‘0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ’,
‘9999999999##########################’)
from dual;
–示例2:只保留数字,其它字母移除。
select translate(‘123ITCAST789’,
‘0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ’,
‘0123456789’)
from dual;
–示例3:把中文替换为英文(是按字符处理。当from_string比to_string字符少时,不会异常。在to_string中多余的字符不处理)
select translate(‘我是中国人,我爱中国’, ‘中国人’, ‘China’) from dual;
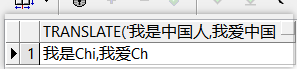
–示例4:把英文替换为中文(按字符处理。当from_string比to_string字符多时,from_string中多余的字符被移除)
select translate(‘I am Chinese, I love China’, ‘China’, ‘中国’) from dual;

–示例5:
select translate(‘中国人’, substr(‘中国人’,1,length(‘中国人’) - 1), rpad(’’,length(‘中国人’),’’)) from dual;

rpad(‘tech’, 7); 将返回’tech ’
rpad(‘tech’, 2); 将返回’te’
rpad(‘tech’, 8, ‘0’); 将返回’tech0000’
第十一章 面试题
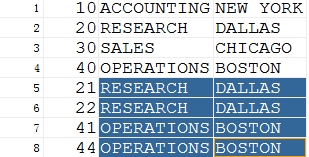
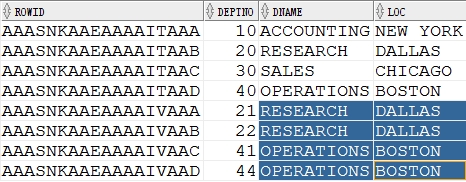
**面试****题:**请删除MYDEPT表中的重复记录 (利用ROWID)
在开发过程中,由于开发人员更换,会造数据存在大量的测试数据,测试数据会存在重复的问题
[分析:
发现数据行号不同,早期插入的数据比较小
发现数据存在重复
]
delete from dept where not rowid in(
select min(rowid) from dept group by dname,loc);
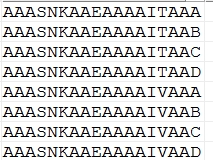















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











