






pocketsphinx-中文
上一篇使用的英文语音包,本篇使用中文识别,分为现有的语音包和自定义语音包两种途径
一: 现有的中文包使用
1. 获取语音包:
pocketsphinx-hmm-zh-tdt_0.8-5_all;下载这个包
pocketsphinx-lm-zh-hans-gigatdt_0.8-5_all;下载这个包
提取data.tar.xz得到usr文件夹,按照路径usr/share/pocketsphinx/model寻找,两个语音包里面分别有一个hmm和lm文件夹,复制到先前创立在pocketsphinx下的model文件夹里面。

2. 修改recognizer.py
按照前一篇的格式修改路径即可(如下图)

3. 效果(此时手机一直播放语音“看这里”)

可见,效果非常不好
二:自定义语音
<1>准备工作
由于是自定义的关键字,用不到语言包,所以在pocketsphonx下创建的model文件夹(存放语言包的)就用不到了,直接在/demo文件夹下进行操作,但是语言包里hmm文件下的tdt_sc_8k文件夹和lm文件夹下的.dic文件(定义关键字的文件)需要保留在/demo文件夹下
<2>编辑自定义的关键字文档
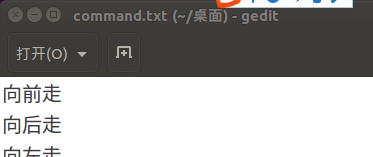
<3>在线编译
到这里编译链接上传自己的文档,编译后下载,得到几个文件,主要用到.dic和.lm(这里重命名为dog.dic和dog.lm),并把他们也放到/demo文件夹下
<4>对照语言包的.dic搜索相同关键字修改dog.dic

<5>修改recognizer.py的三处与lm,dic,hmm定义及配置相关的代码
首先,用不到代码包了,把路径代码注释掉
 第一处:
第一处:
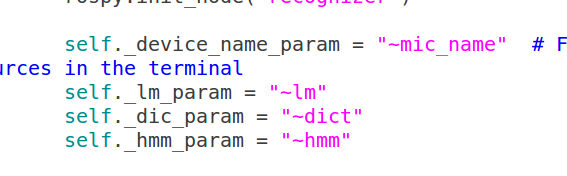
第二处:
 第三处:
第三处:
 从github上扒下来的原装代码在这三处好像只是没有与hmm相关的代码,比葫芦画瓢添上去了
从github上扒下来的原装代码在这三处好像只是没有与hmm相关的代码,比葫芦画瓢添上去了
<6>写dog_voice_cmd.launch如下
<launch>
<node name="recognizer" pkg="pocketsphinx" type="recognizer.py" output="screen">
<param name="lm" value="$(find pocketsphinx)/demo/dog.lm"/>
<param name="dict" value="$(find pocketsphinx)/demo/dog.dic"/>
<param name="hmm" value="$(find pocketsphinx)/demo/tdt_sc_8k"/>
</node>
</launch>
<7>完成,此时文件结构如下(包含pocketphinx下载自带的文件):

<8>启动+效果

有几种结果:没结果,对了,错了,多了。可能是因为用文字转语音软件播放的语音的缘故,反正这效果肯定是不行的
总结
原装的中文包不行,效果太差。自定义关键字后可能是因为减少了相似音调的词语的缘故,识别率有明显提高,但是依旧不好,不能用。pocketsphinx的学习之路(英文包+中文包+自定义中文)到此结束















 2701
2701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









