






激活函数与梯度下降法
3.6 激活函数
-
值钱的章节一直用的sigmoid函数,但其实其他函数的性能有可能更好,sigmoid:
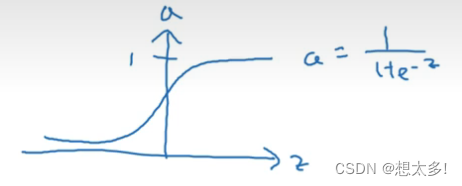
-
tan 函数几乎一直优于sigmoid函数,有数据中心化的效果:
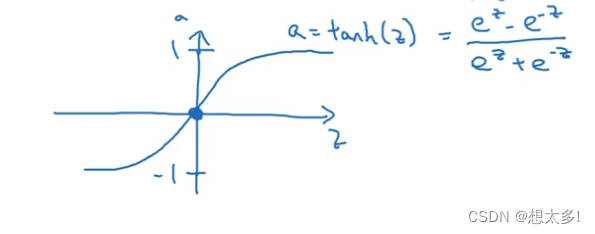
-
共有的缺点,z很大或很小的时候,函数斜率接近0
-
默认ReLU激活:z为负数=0,z为正=amax(0,z),z=0没有定义。
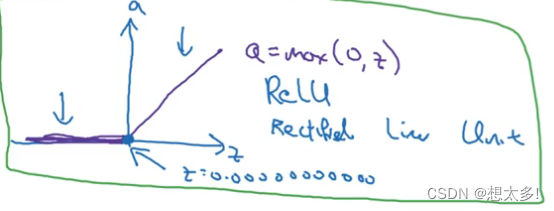
总结:
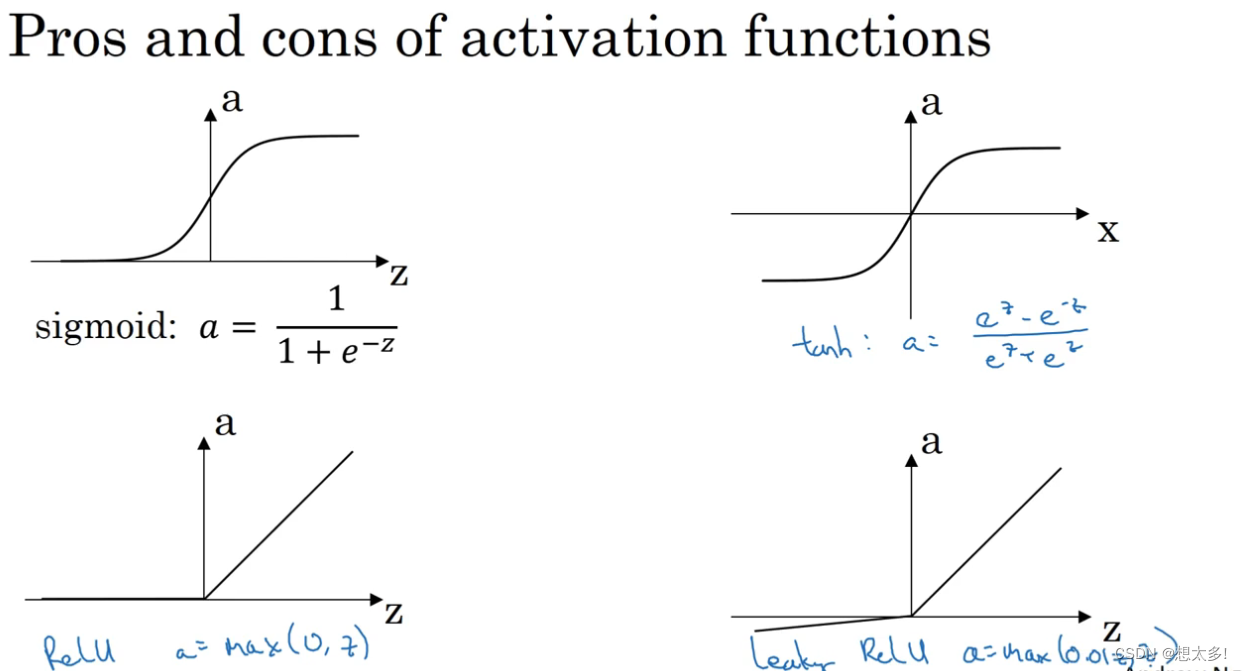
3.7 为什么需要非线性激活函数
事实证明,如果你使用线性激活函数,或者没有激活函数,那么无论你的神经网络有多少层,一直在座的只是计算线性激活函数,所以不如直接去掉全部隐藏层——线性隐层一点用都没有(在NN中)。

3.8 激活函数的导数(微积分)
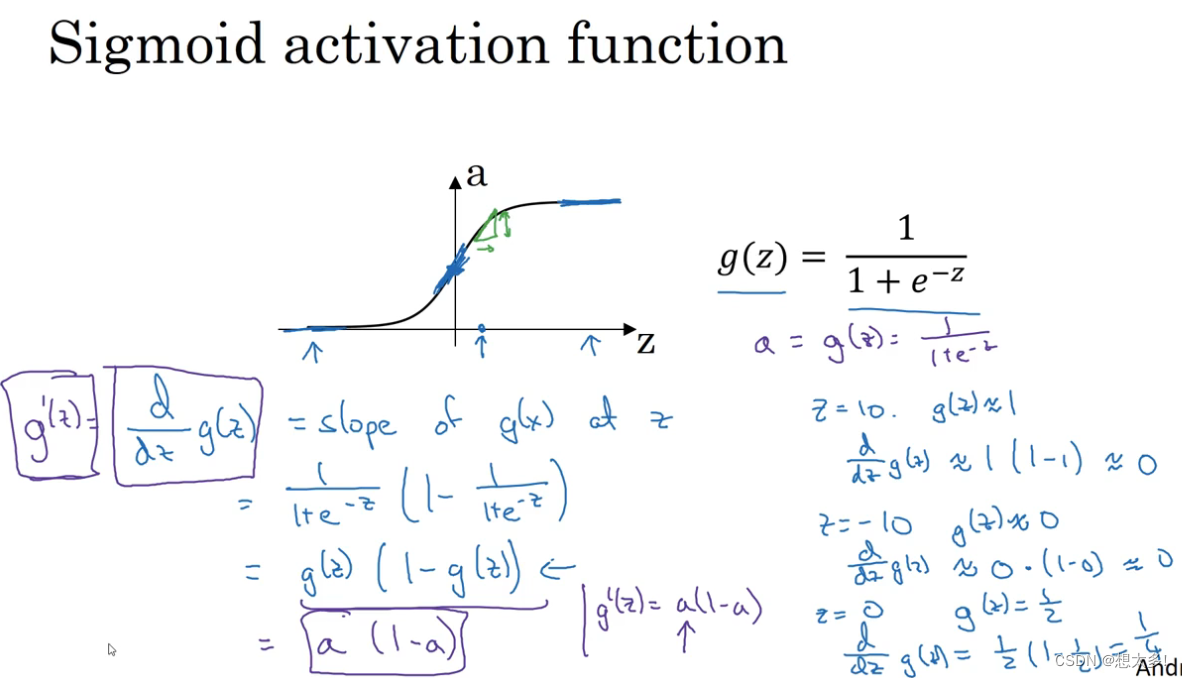
sigmoid函数:
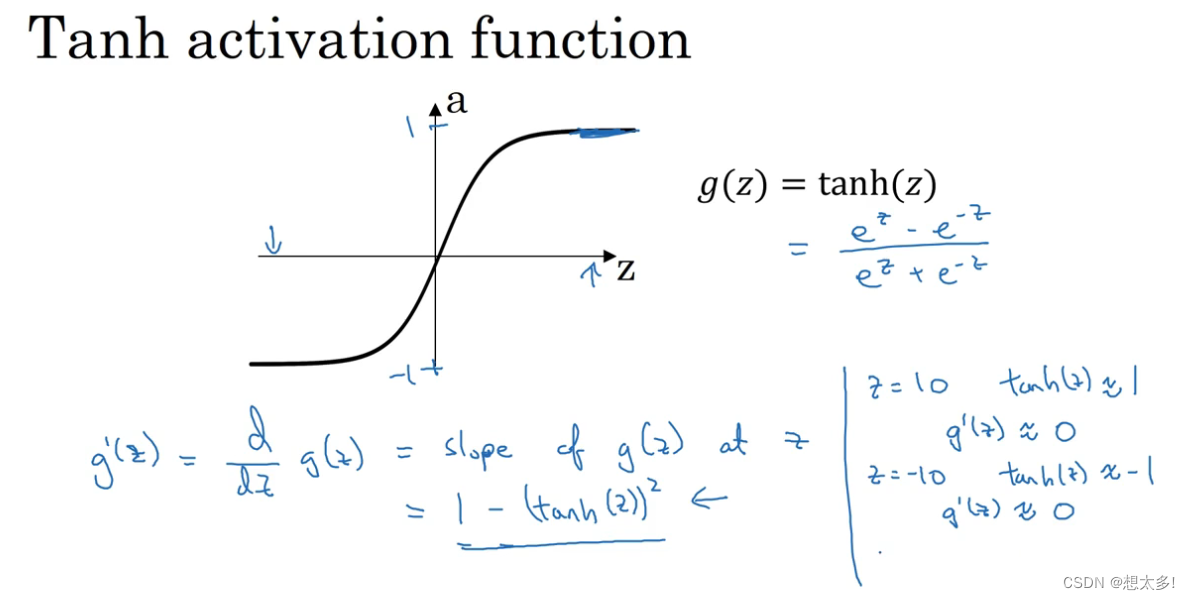
Tanh函数:
ReLU 和 Leaky ReLU:
在0本身无定义,但可以用代码去定义0点的值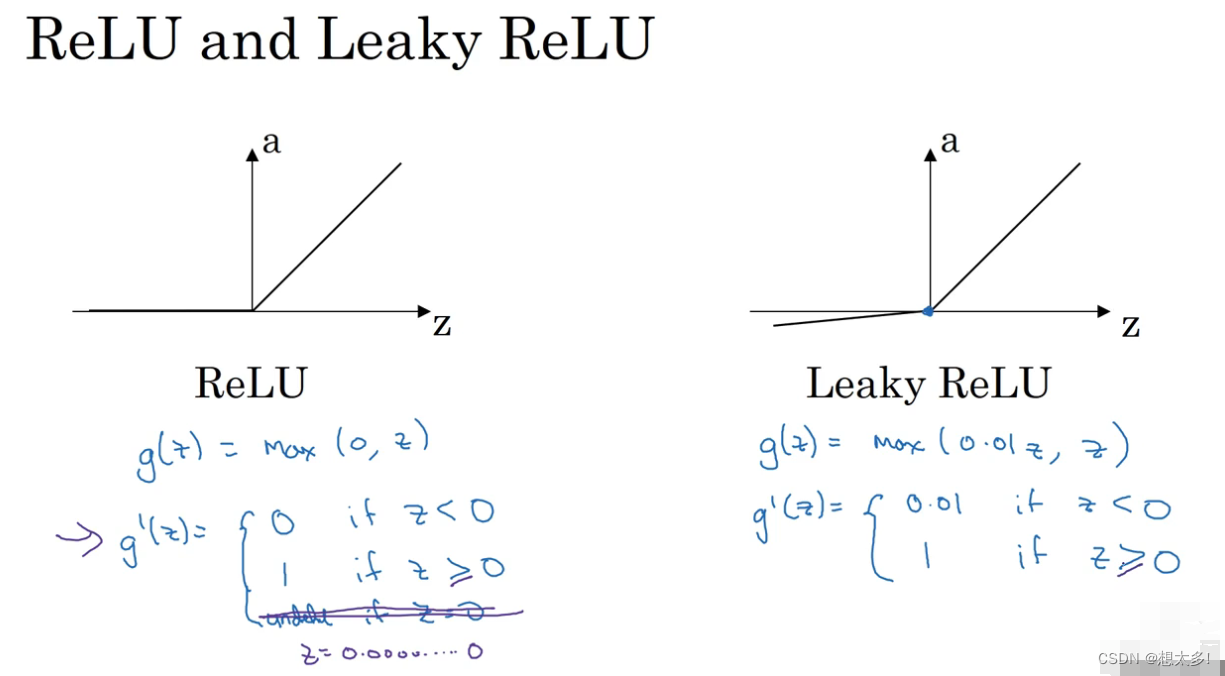
3.9 NN的梯度下降法
3.9.1 Gradient descent for neural networks
首先要随机初始化,3.11会讨论,如何求解偏导数在3.10

3.9.2 Formulas for computing derivatives
首总结一下正向与反向传播的方程Z,A

3.10 (选修)直观理解反向传播
3.10.1 流程图推导,逻辑回归:

神经网络梯度:要实现维度的匹配
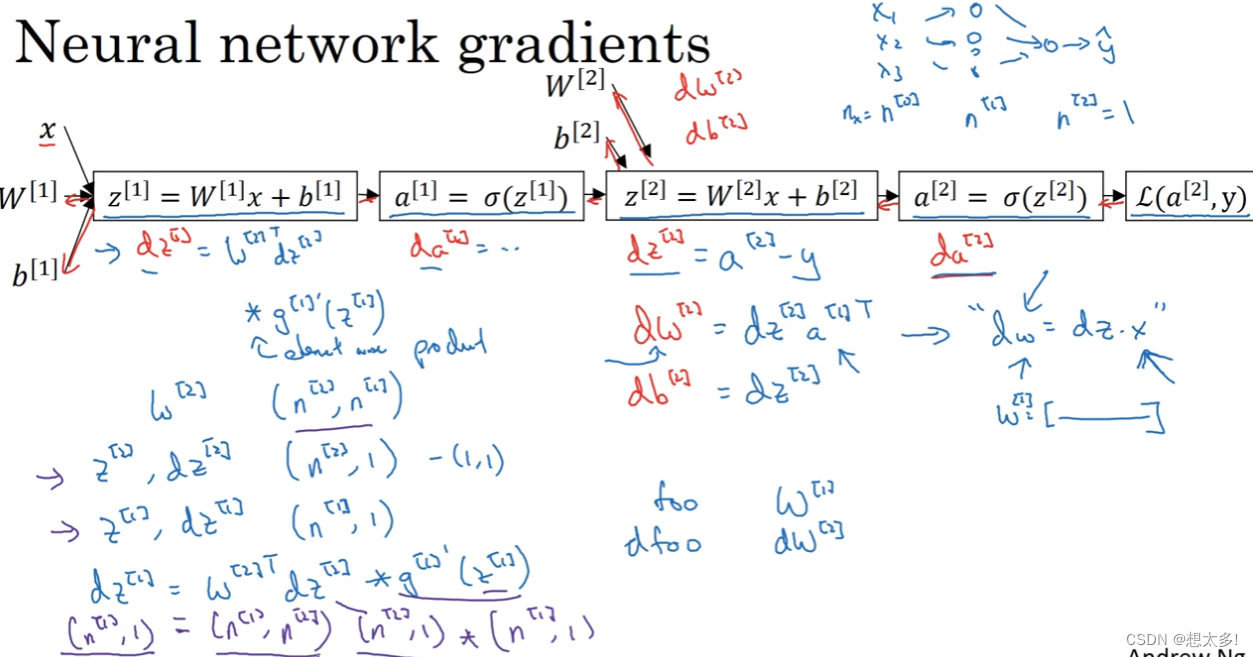
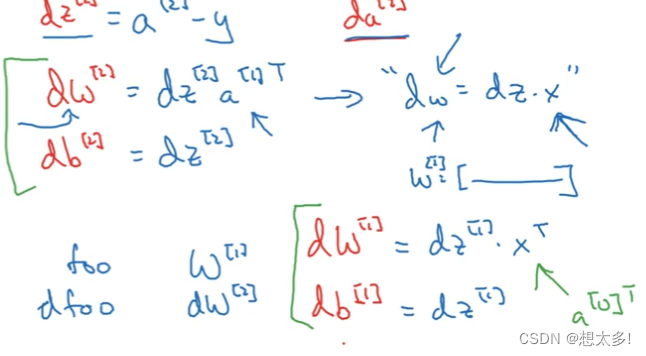
3.10.2 总共六个方程,把所有训练样本向量化:

- 反向传播:

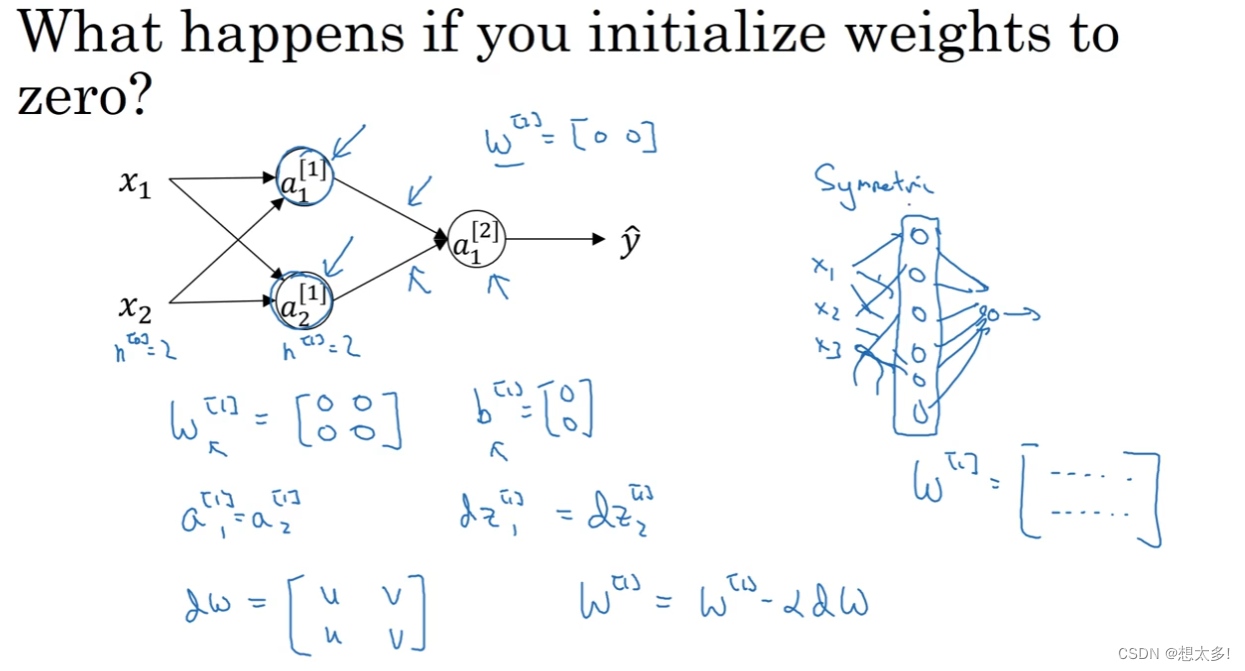
3.11 随机初始化
权重全为0的问题,多个隐藏单元一模一样,就失去了意义:
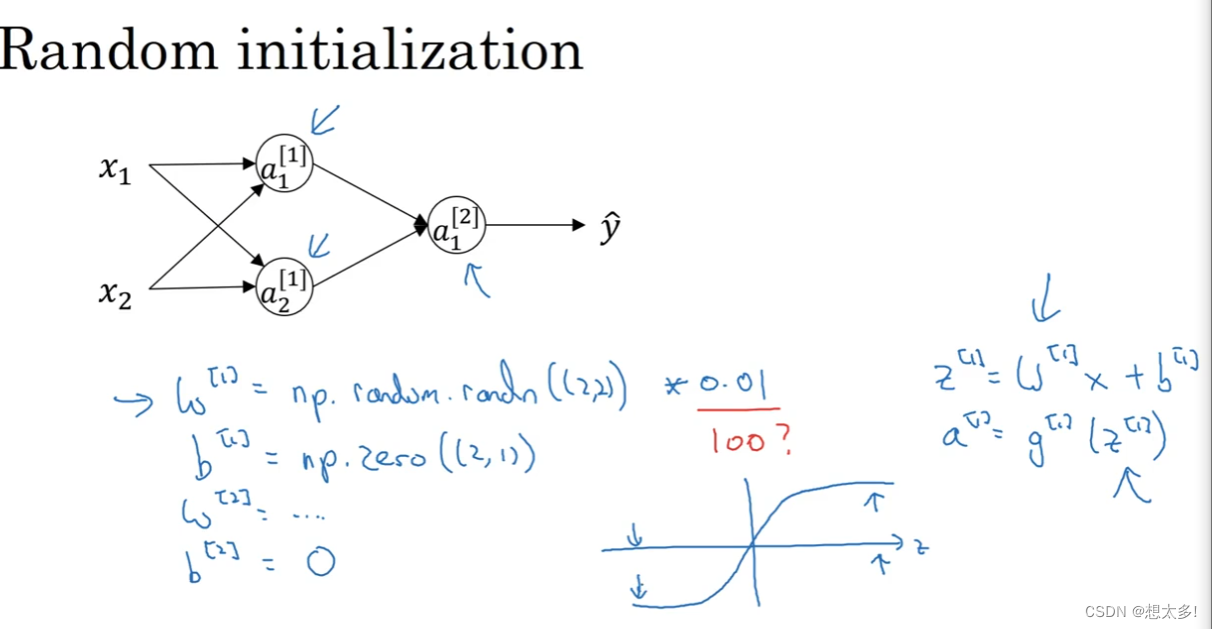
解决办法:随机初始化,初始化参数一般都很小















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









