






SST:用于多标签图像识别的空间和语义变压器
SST:用于多标签图像识别的空间和语义变压器
Index Terms—Multi-label image recognition, transformer, label correlation.
I. INTRODUCTION
普通的ResNet-101方法的激活往往是不完整的,置信度较低。

总之,我们的贡献有三方面:
- 我们提出了一个即插即用的模块,即SST模块,用于在多标签图像识别任务中同时建模空间和语义标签相关性。
- 我们探索了空间和语义相关的工作机制,我们的SST改进了长期空间相关建模,并消除了捕获语义相关的复杂人工设计。
- 我们提出的方法在四个流行的多标签基准数据集上取得了优秀的结果。
II. RELATED WORK
A. Multi-Label Image Recognition
一般说来,多标签图像的代表性方法可以分为三种,即相关性不可知法、语义相关法和空间相关法。 这是首次同时捕获语义和空间相关性的工作,证明了这些相关性在多标记图像识别中是相辅相成的,值得同等重视。
B. Transformer in Computer Vision
Transformer具有捕捉远程依赖关系的能力,在自然语言处理(NLP)中取得了巨大的成功 。
在本工作中,我们探索如何将变压器集成到流行的多标签图像识别方法中。 考虑到Transformer在捕获长程关联方面的突出能力,我们主要关注利用Transformer捕获空间和语义关联。
III. APPROACH
具体的模型内容移步原文,emm这篇是为了多了解一下transformer,dddd
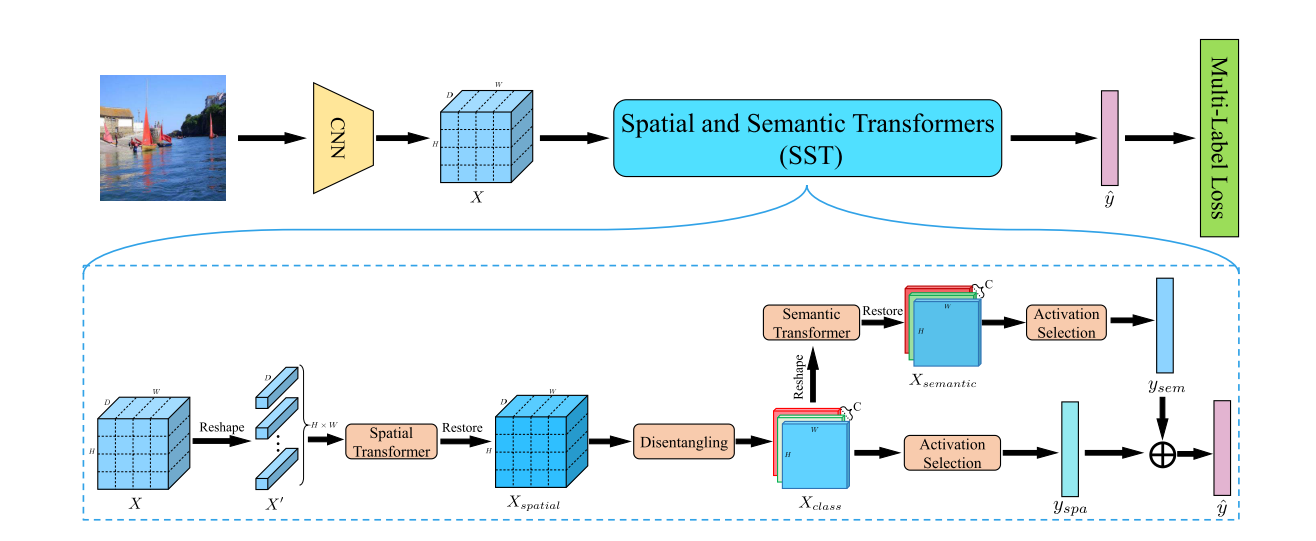
A. Motivation
B. Recap of Transformer
C. Modeling Spatial Label Correlations
D. Modeling Semantic Label Relationship
E. Shared Transformer Encoder
我们提出的方法的训练方案

F. Network Architecture
线性聚合两种变换的预测有两个优点:
- 首先,多标记图像识别(二值交叉)损失可以直接应用于类别感知特征映射,极大地有利于分类特征的分离。
- 其次,它更有利于梯度的反向传播,有利于空间和语义相关性的整合。
IV. EXPERIMENTS
A. Evaluation Metrics
Specifically, we compute the average per-class precision (CP), recall (CR), F1 (CF1) and the average overall precision (OP), recall (OR), F1 (OF1) in Eq,即均每类精度(CP)、查全率(CR)、F1(CF1)和平均总体精度(OP)、查全率(OR)、F1(OF1)
上述评价指标的计算公式如下:
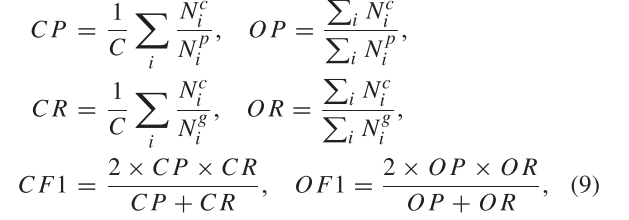
B. Implementation Details
在我们的实验中,输入的图像被随机裁剪成448×448的分辨率,并通过随机的水平翻转进行数据增强。在[1]-[3]之后,选择ResNet-101 作为我们提出的模型的主干,该模型在ImageNet 上进行预训练,以进行模型参数初始化。
C. Datasets
- MS-COCO 2014 Dataset
- NUS-WIDE Dataset
- Pascal VOC 2007 & 2012 Dataset
D. Comparisons With State-of-the-Art Methods
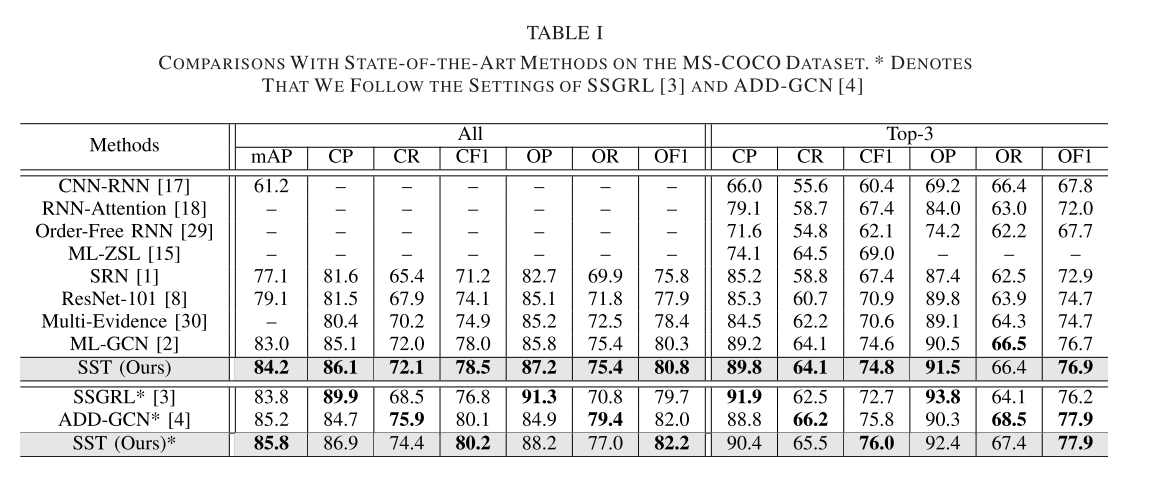
1) Performance on the MS-COCO 2014 Dataset:
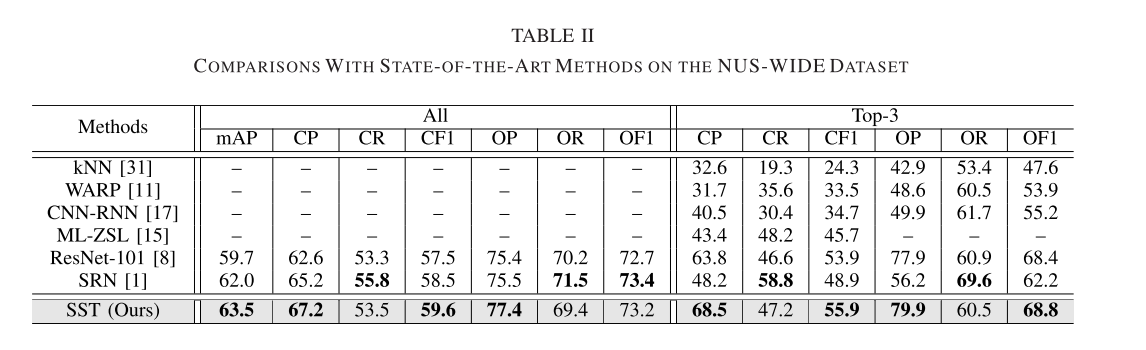
2) Performance on the NUS-WIDE Dataset:
3) Performance on the VOC Dataset:
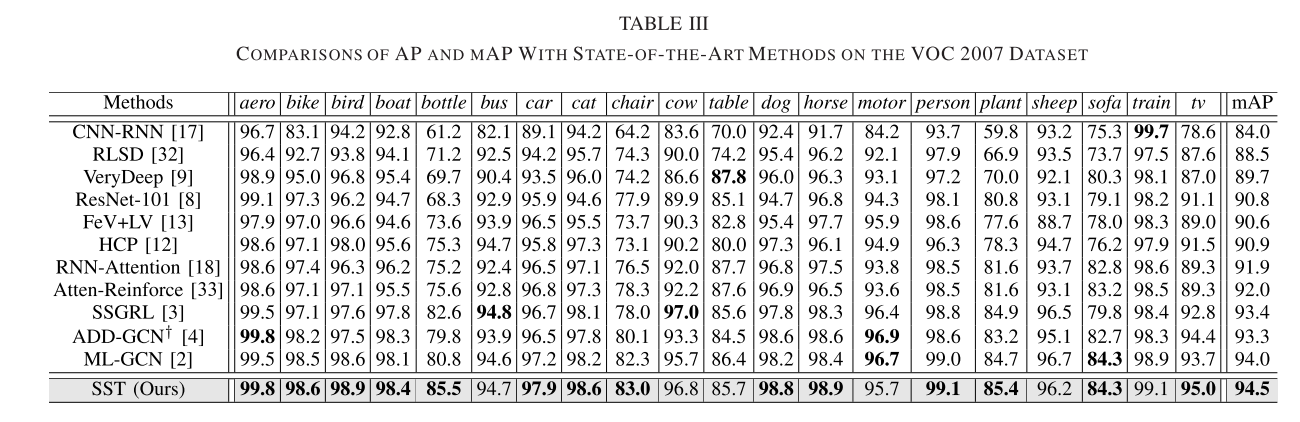
从上面这三张表已经能很明显的看出来本文所述方法在各项指标上的优越性,证明了研究价值。
E. Ablation Studies
1) Spatial Transformer:
我们提供了仅用空间变压器捕获的注意力的可视化。这个图中的注意图说明了物体可以被精确地定位并被强烈地激活。然而,小物体往往只被忽略了空间相关性
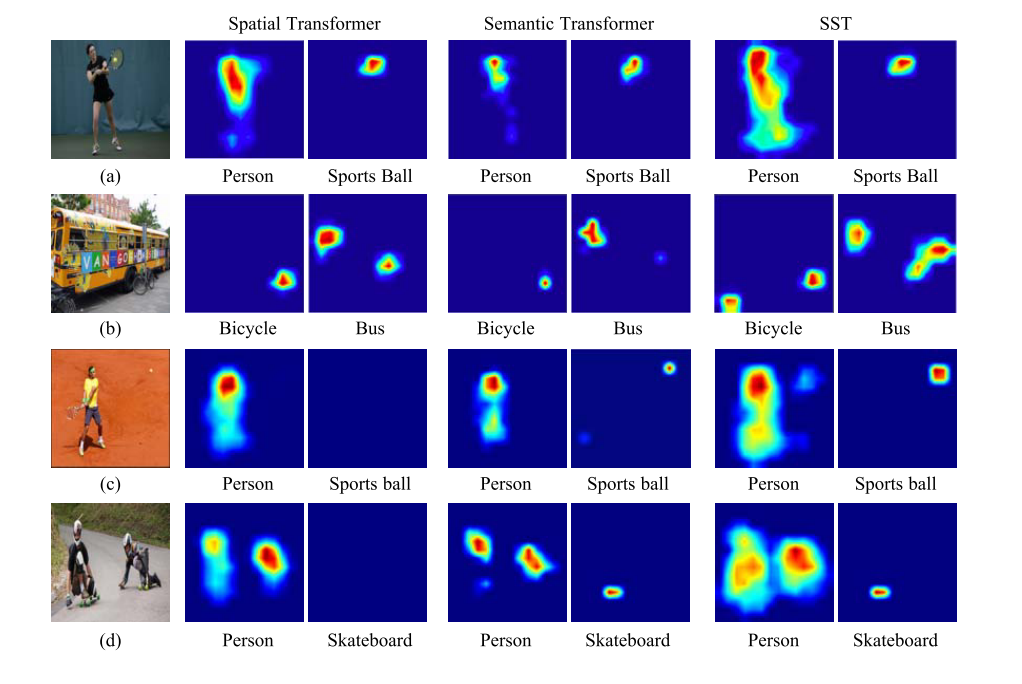
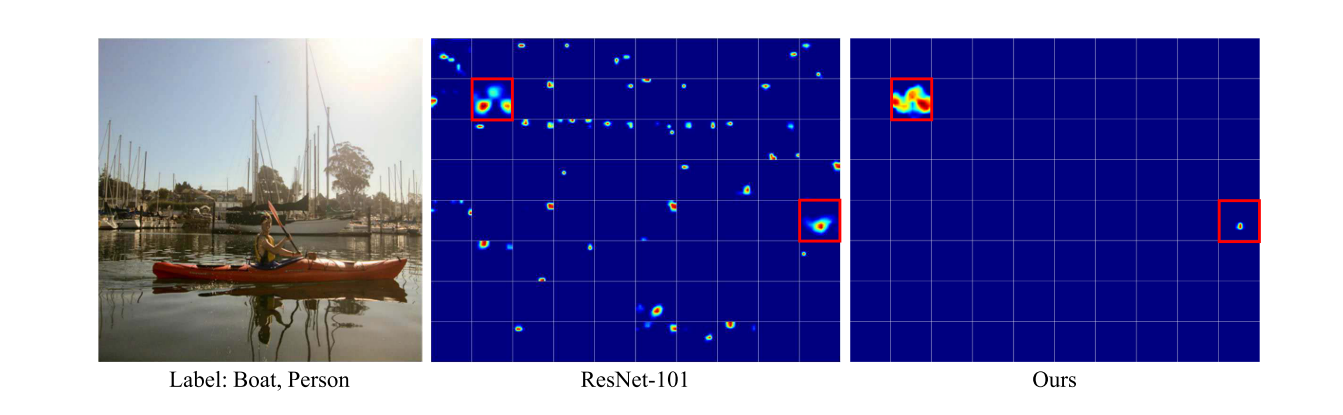
8) Uncorrelated Labels:
在所有类别上的注意力地图的说明。与基线方法相比,我们的方法可以产生了干净和强激活的注意图。地面真相类别用红色矩形标记。
V. CONCLUSION
-
在这项工作中,我们提出了空间和语义变压器(SST)模块,这是一个即插即用的模块,用于同时捕获多标签图像中的空间和语义相关性。我们的方案主要由两个独立的转换器组成,即空间转换器和语义转换器。
-
空间转换器被指定用于从所有空间位置捕获特征之间的空间相关性,而语义转换器被设计用于捕获没有手动定义规则的标签共存。
-
此外,同样重要的是,我们证明空间和语义相关性是互补的。换句话说,同时建模两种类型的标签相关性被证明对多标签图像识别非常有益。在MS-COCO、NUS-CODE和VOC2007这三个流行的多标签图像分类数据集上的最新结果证明了我们所提出的方法的有效性。
-
此外,定量和定性的消融研究和可视化也有力地支持了我们的方法中的基本成分。由于这项工作仍然依赖于cnn来提取整体的深度特征,我们希望探索纯粹的基于变压器的网络,例如,设计一个基于变压器的主干来提取整体的深度特征。
-
此外,我们还想探讨如何通过设计变压器中的一种新的前馈网络块来减少额外的计算成本,例如,瓶颈架构和分组全连接层。此外,我们还将进一步探讨不同标签分布中空间和语义相关的趋势。















 4224
4224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









