










安装配置hadoop
1.到 《官网》 下载Hadoop
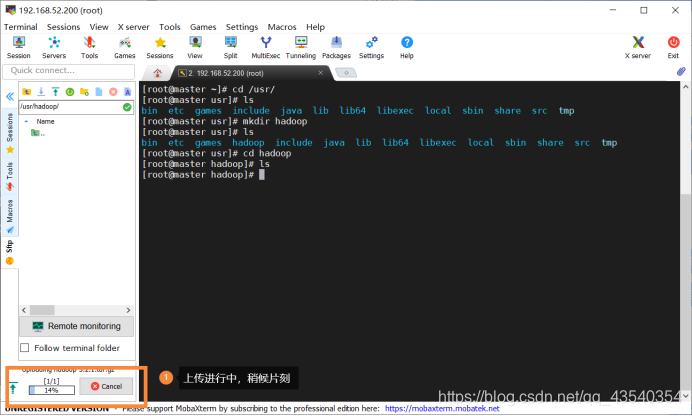
2.使用cd /usr命令,进入到usr目录下
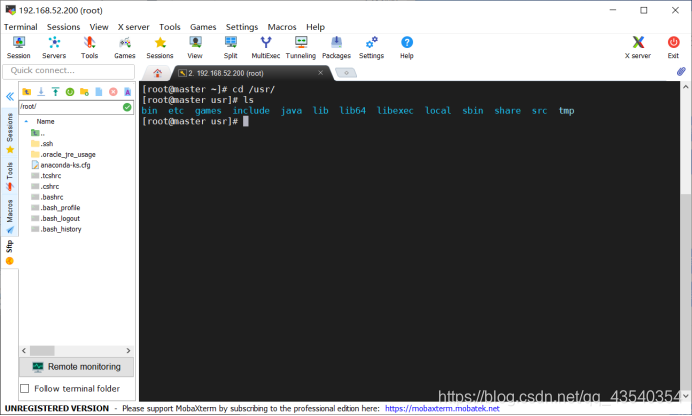
并使用mkdir hadoop命令,创建一个hadoop目录,使用ls查看是否创建成功(一般没毒的话,应该都会创建成功)
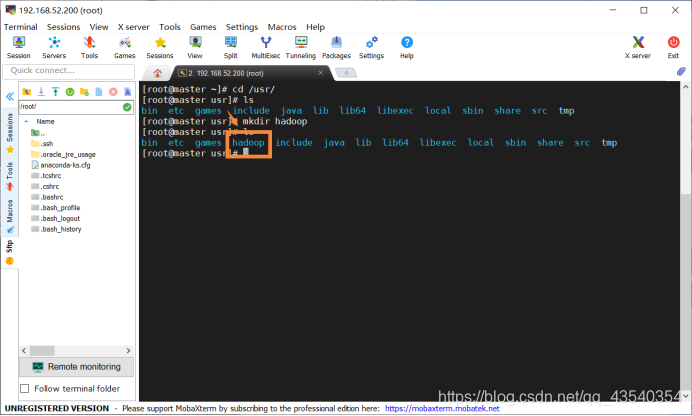
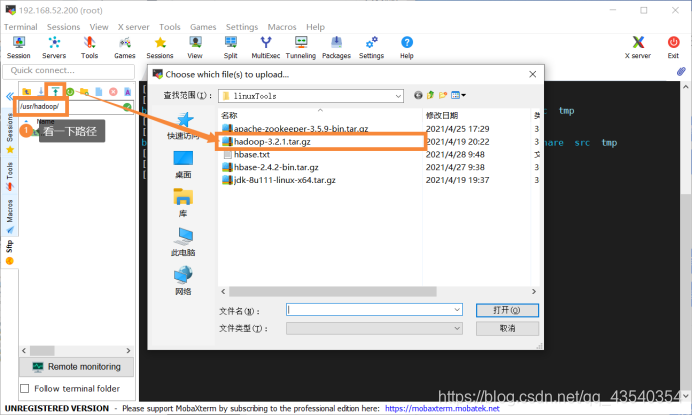
4.将下载好的文件上传到linux环境中,准确说是上一步建好的hadoop目录下,方法有三:
(1)可以使用XShell的sudo rz的命令上传,但是有的可能会出现“传输失败”,如果失败了可以换换使用sudo rz -be进行上传
(2)使用XShell配套的xftp进行上传,xftp需 额外下载
(3)直接使用MobaXterm,自带上传,无需额外下载其他软件
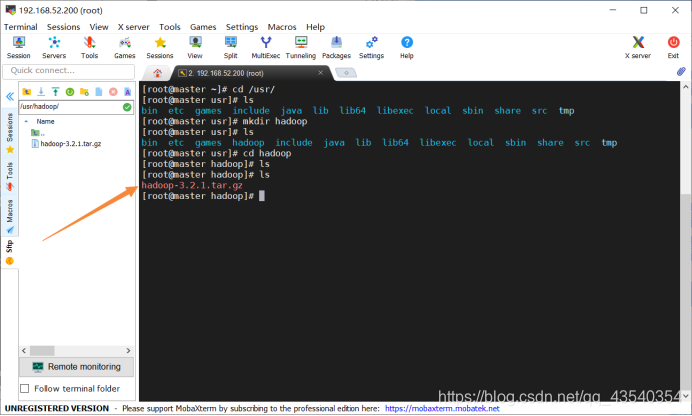
4.上传完成后,使用ls命令,查看上传是否成功
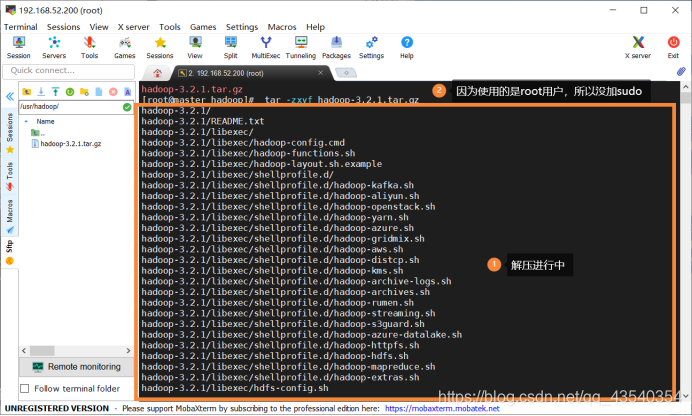
5.执行sudo tar -zxvf hadoop-3.2.1.tar.gz命令,将tar包解压到当前文件夹中
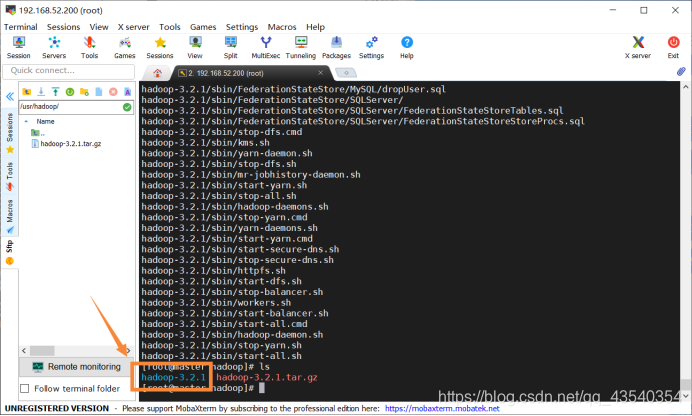
使用ls命令,查看解压后的文件夹
6.执行vi /etc/profile(因为是使用的root用户,所以没加sudo),准备修改/etc/profile配置文件,打开文件到最后一行(可以使用“shift键 + G”直接到最后一行)
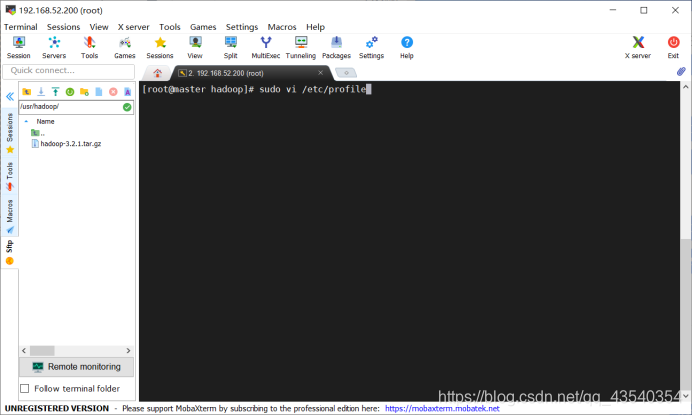
修改前截图为:
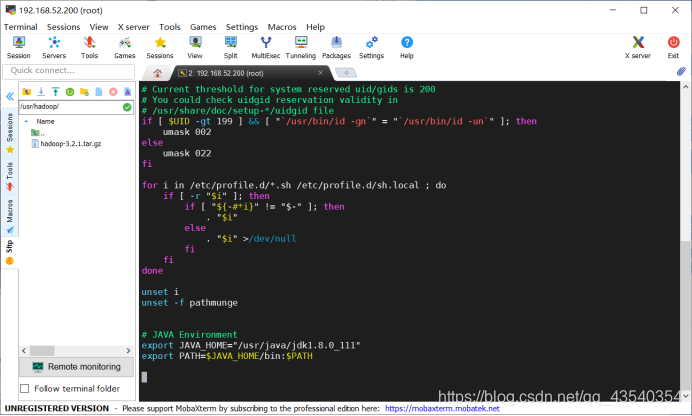
追加如下配置,截图如下(如果使用的是MobaXterm可以使用“shift键 + insert键”进行粘贴,XShell好像也可以):
# Hadoop Environment
export HADOOP_HOME="/usr/hadoop/hadoop-3.2.1"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
追加后截图为:
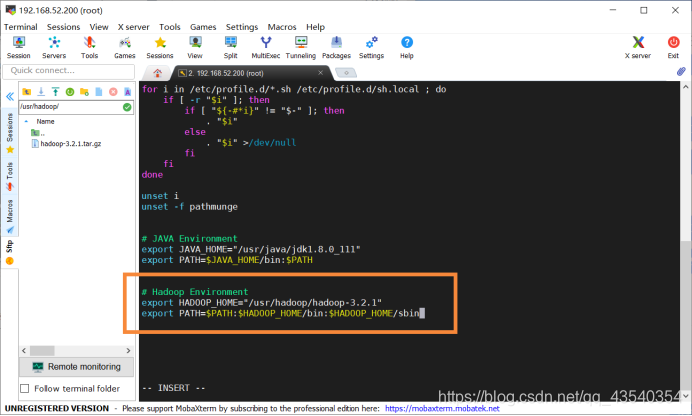
按esc(视频退出全屏➹),输入:wq保存并退出
7.执行source /etc/profile命令,使配置生效
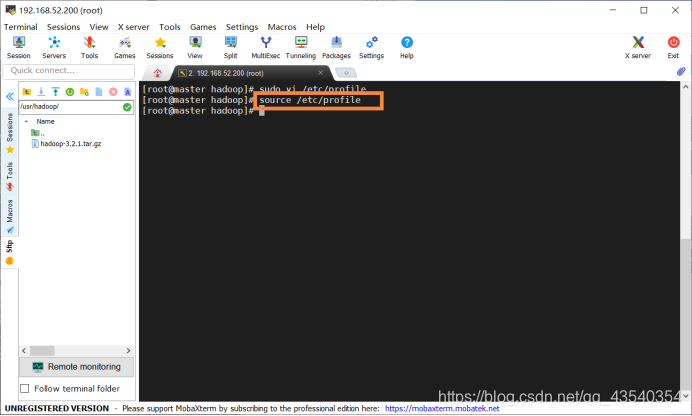
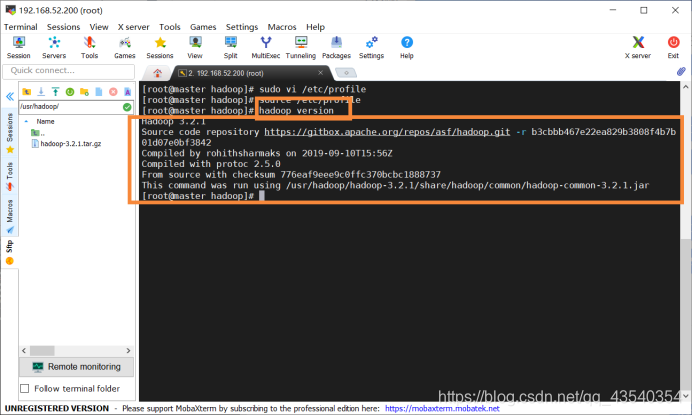
8.使用hadoop version命令,查看hadoop 版本号,顺带检验hadoop 是否安装成功,安装成功,截图如下:
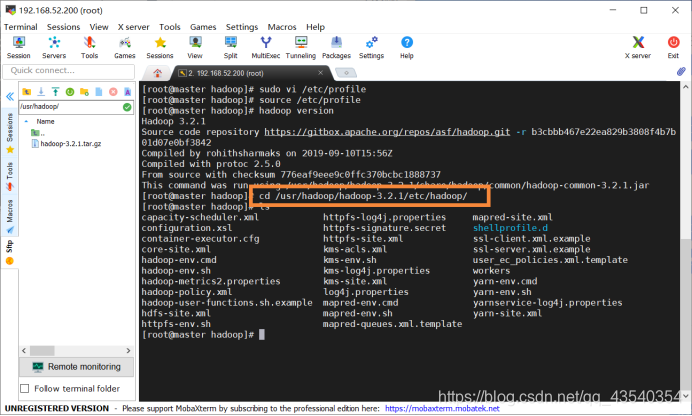
9.执行cd /usr/hadoop/hadoop-3.2.1/etc/hadoop/进入hadoop目录,并使用ls查看配置文件,截图如下:
10.执行sudo vi hadoop-env.sh命令,添加配置运行环境变量
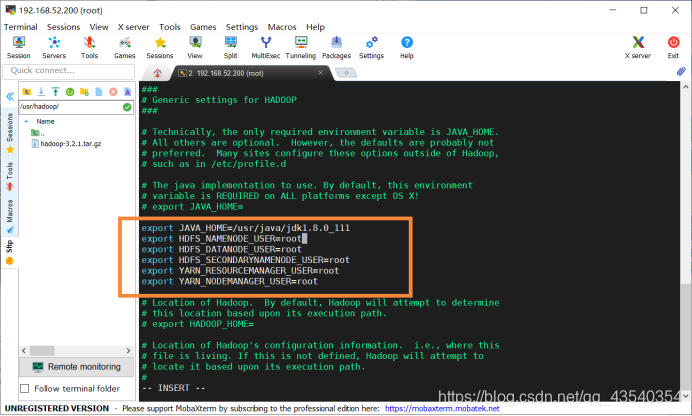
增加如下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_111
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
按esc(视频退出全屏➹),输入:wq保存并退出
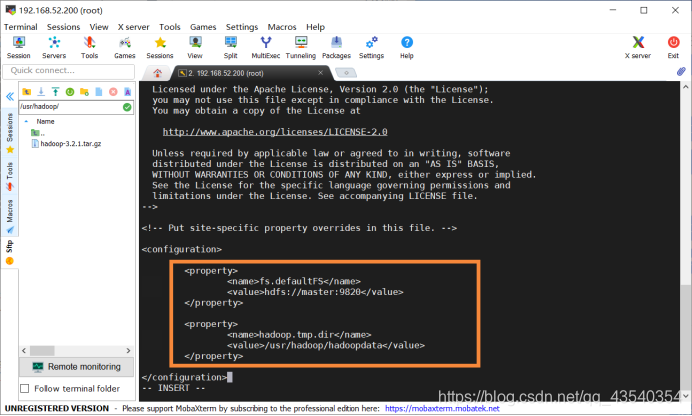
11.执行sudo vi core-site.xml命令,修改core-site.xml文件,在configuration中添加如下配置
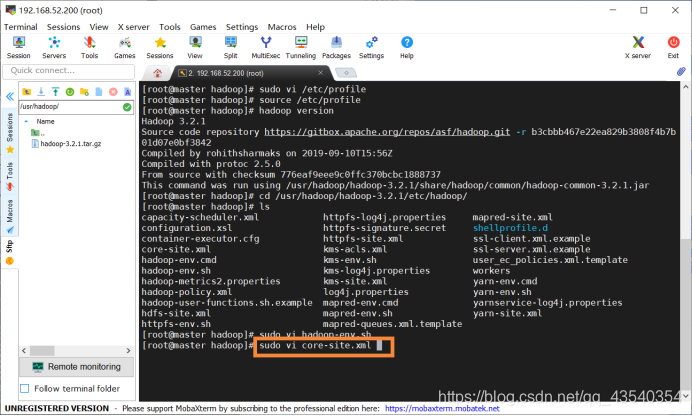
增加如下配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoopdata</value>
</property>
按esc(视频退出全屏➹),输入:wq保存并退出
12.执行sudo vi hdfs-site.xml命令,修改hdfs-site.xml配置文件
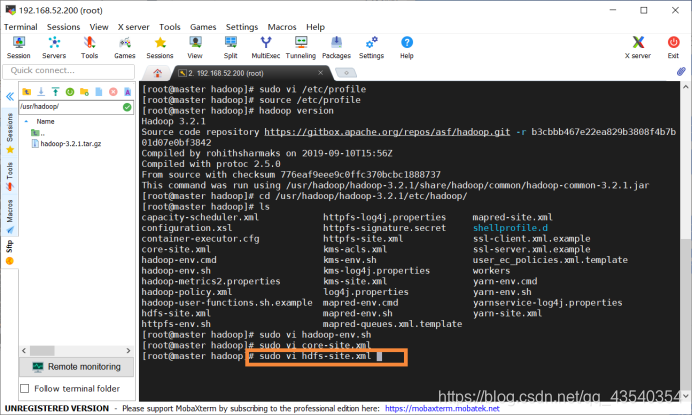
添加如下配置:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
截图如下:

按esc(视频退出全屏➹),输入:wq保存并退出
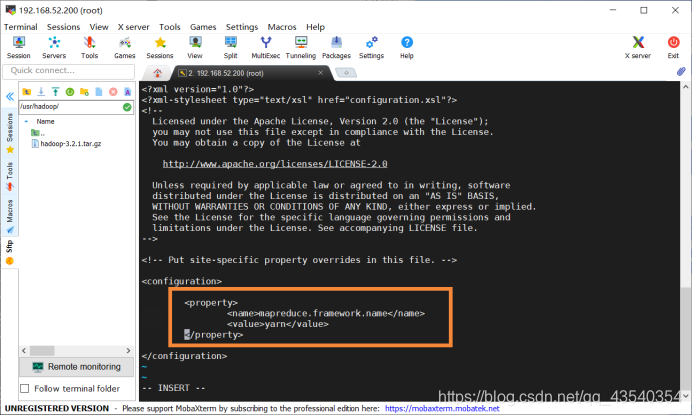
13.执行sudo vi mapred-site.xml命令,修改mapred-site.xml配置文件
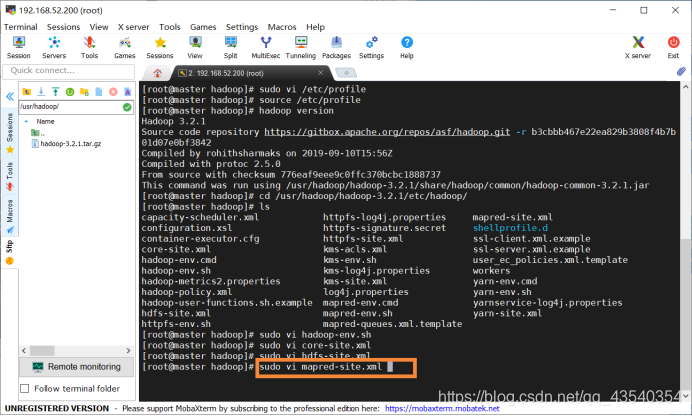
添加如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
截图如下:
按esc(视频退出全屏➹),输入:wq保存并退出
14.执行sudo vi yarn-site.xml命令,修改yarn-site.xml配置文件
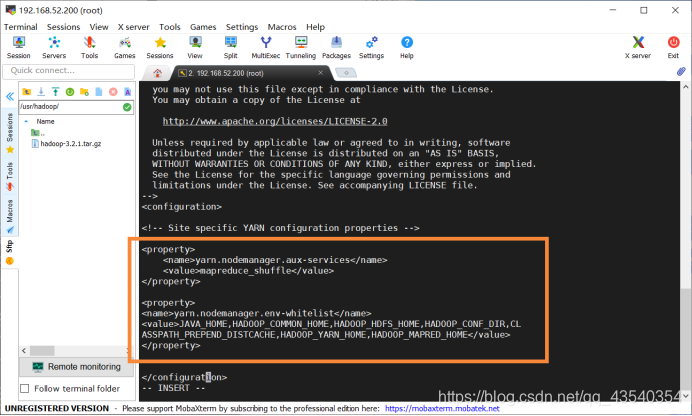
添加如下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CL
ASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
截图如下:
按esc(视频退出全屏➹),输入:wq保存并退出
15.执行sudo chmod -R 777 /usr/hadoop命令,将/usr/hadoop目录赋予777权限,否则后面格式化HDFS会报错
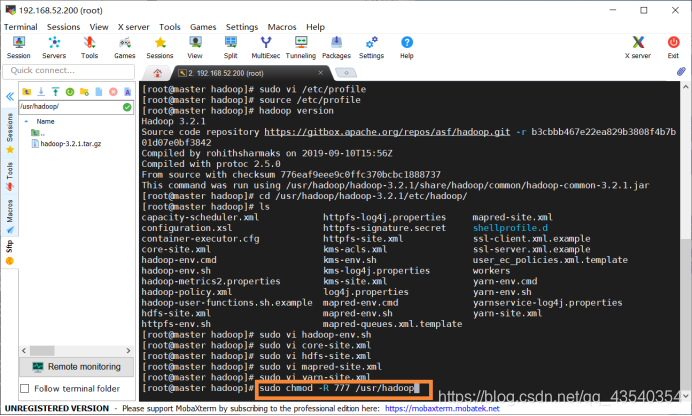
执行cd /usr/hadoop/hadoop-3.2.1命令,进入hadoop-3.2.1目录下
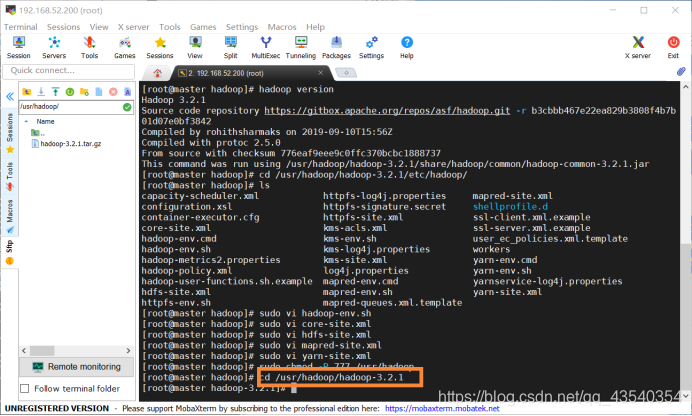
执行bin/hdfs namenode -format命令,格式化HDFS文件系统
注意:只需要格式化一次即可,如果多次格式化到后面可能会出现问题,到那时删除/usr/hadoop/hadoopdata目录后再重新格式化
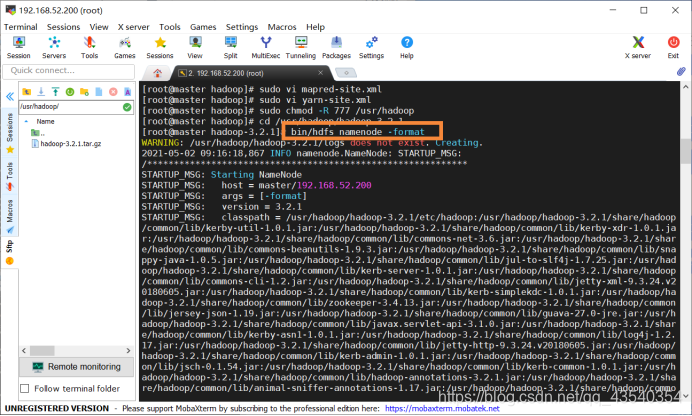
16.执行sbin/start-all.sh命令,启动hadoop所有进程,截图如下:
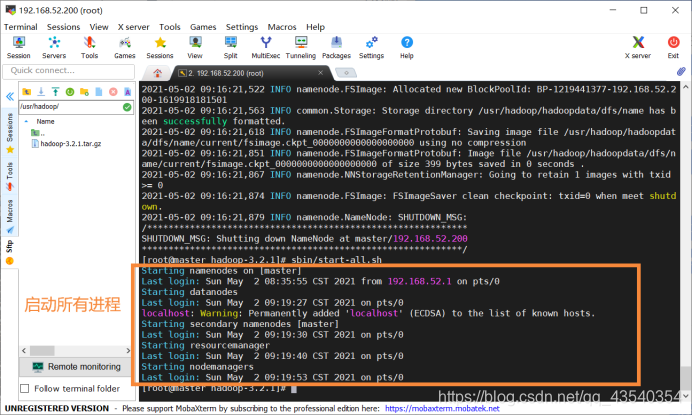
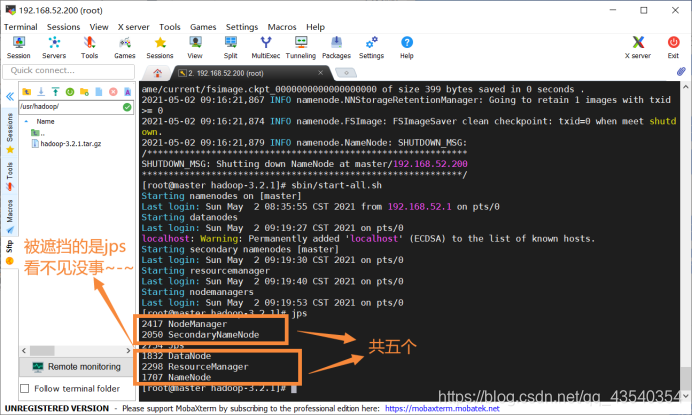
启动完成后,执行jps命令(以后经常用),查看已经启动的进程:
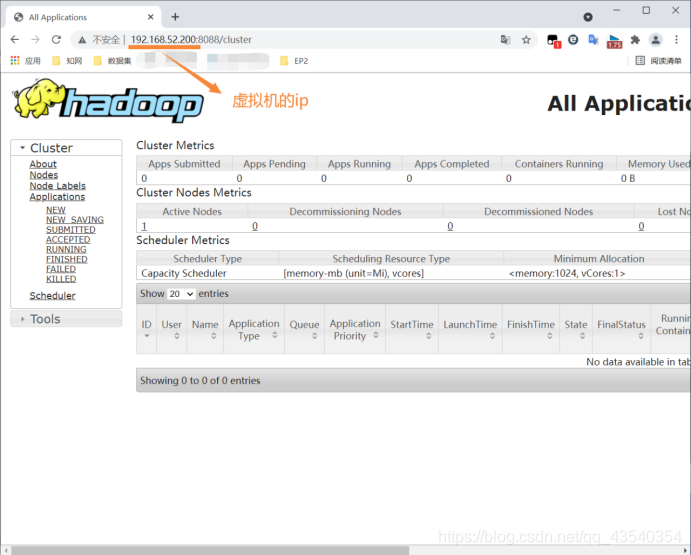
在window浏览器中输入:http://192.168.52.200:8088/cluster(虚拟机ip地址)即可查看ResourceManager界面
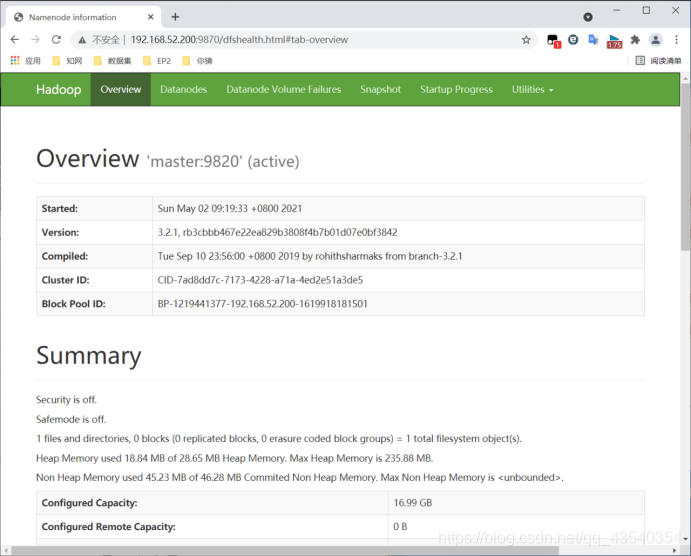
输入http://192.168.52.200:9870/,查看namenode
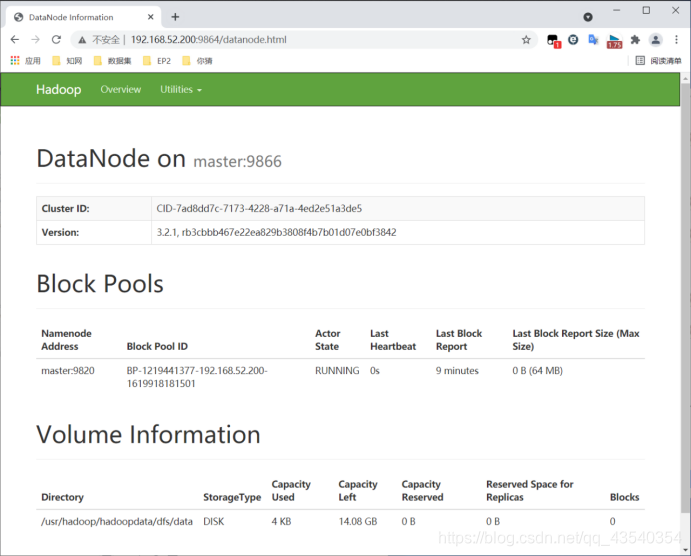
输入http://192.168.52.200:9864,查看datanode
注:执行“stop-all.sh”停止hadoop,以后启动、停止hadoop因为加入到环境变量中,所以不用在进入固定文件夹中启动了。
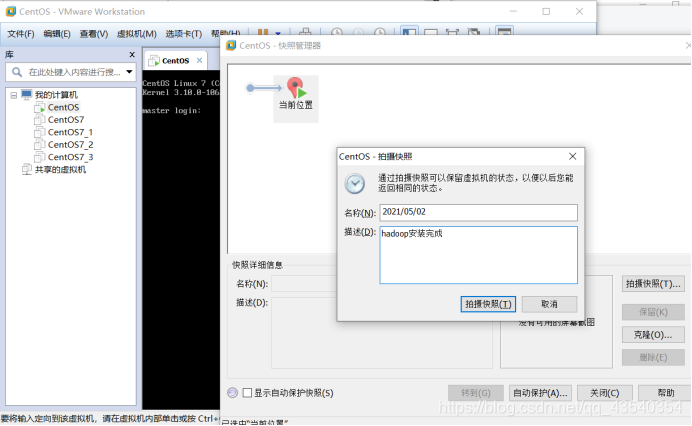
如果是虚拟机,记得做做快照(至于啥时候做快照,每个重要时间节点做一下就行,至于什么是重要时间姐姐,就看自己了(๑→ܫ←))














 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









