







 本文探讨了云计算中CVM的数据安全问题,特别是针对敏感数据处理的保护措施,以及CVM在大比特以太网时代面临的网络性能挑战,包括I/O数据传输效率和安全保护的CPU开销。文章还提出了性能优化的设计方案,如零拷贝加密和预接收包重组等,以提升CVM的性能和安全性。
本文探讨了云计算中CVM的数据安全问题,特别是针对敏感数据处理的保护措施,以及CVM在大比特以太网时代面临的网络性能挑战,包括I/O数据传输效率和安全保护的CPU开销。文章还提出了性能优化的设计方案,如零拷贝加密和预接收包重组等,以提升CVM的性能和安全性。
背景
云计算中数据安全很关键
- 应用在云中处理敏感数据,如key-value store,AI inference,finance service
- 被攻击的hypervisor可能窃取VM数据(hypervisor有权访问VM内存)
- 公布很多法规强制保护数据安全,例如GDPR(general data protection regulation)
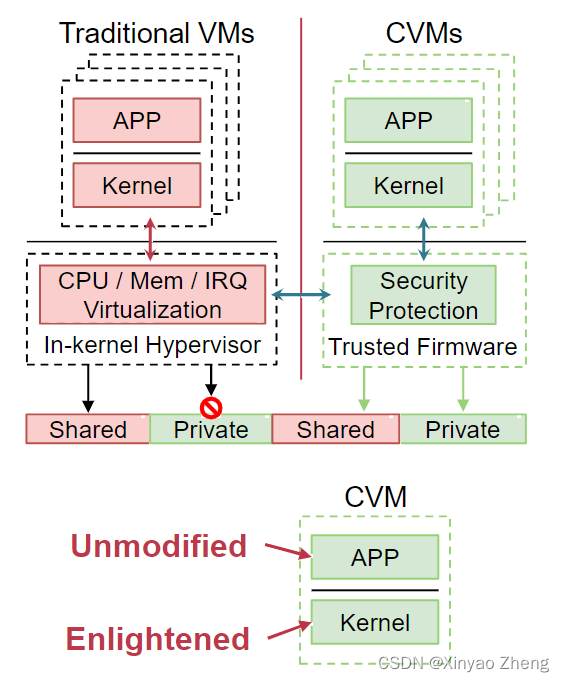
CVM适用于数据中心
- 安全性
- OS-level可信计算,每个guest OS互相隔离
- VM exits时,CPU状态受保护
- 硬件加密保护内存安全
- 兼容性
- 可以与现有IaaS集成
- 对应用透明,不需要修改应用
大比特以太网时代到来
- 现有的网络设备速度增长,比如NVIDIA ConnectX-7 400GbE SmartNIC
- CPU变成性能瓶颈,应用逻辑和IO操作都消耗大量的CPU资源
CVM中的虚拟化IO网络
-
现代云服务商的主要IO虚拟化选择,典型用法:基于轮训的用户空间IO后端以提供高性能
I/O event notification
-
Hypervisor通过vIRQ通知虚拟机,从而触发虚拟机退出
-
与传统VM相比,CVM推出具有更高的延迟

I/O data transfer
- 管理程序将IO数据拷贝to/fromVM内存
- 由于管理程序无法访问私有内存,CVM需要反弹缓冲区bounce buffer

I/O data protection
- 端到端的加密,如传输层安全( TLS )。
- 内核中的TLS支持增强的性能和扩展的功能

CVM的网络性能
Testbed configuration
- CVM: AMD SEV-ES/SNP, w/o posted IRQ
- CVM+PI: simulated Intel TDX, w/ posted IRQ
Summary: poor network performance
- CVM: 21% - 28% overhead vs. baseline
- CVM+PI: 13% - 29% overhead vs. baseline
*Posted IRQ: eliminate VM exits during vIRQ deliveries
CVM-IO Tax 影响性能
CVM-IO tax & application workloads共享有限的CPU执行时间
-
CVM-IO tax
- CPU时间花费在安全保护和固有的网络I/O程序上
- CPU花费时间越多,性能越差
-
Application workloads
- CPU时间花费在业务逻辑和有效负载处理上
- CPU花费时间越多,性能越好

CVM-IO tax consumes > 50% CPU time,Packet processing consumes a large portion of CPU time

问题和设计方案
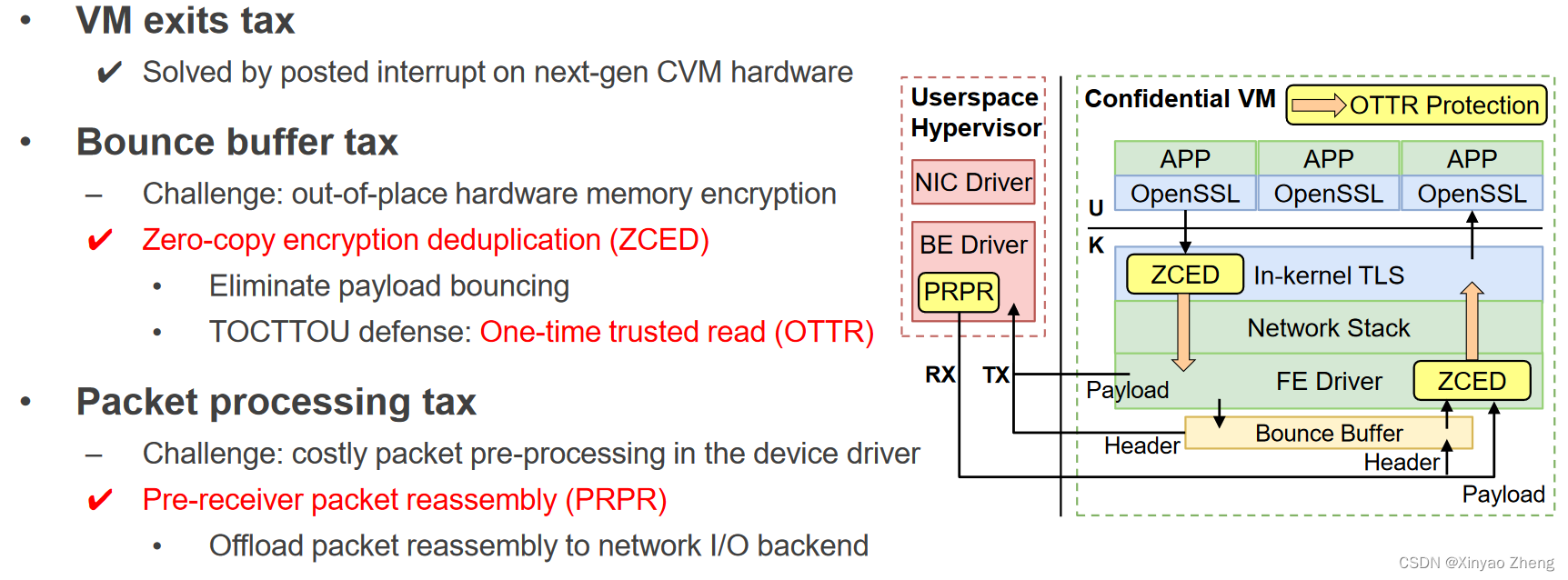
Lengthy VM Exits
- CVM引入了对CPU状态的保护,例如,当VM退出时,可信的固件可以保存和清除寄存器
- 该保护为guest-host世界交换机增加了大量的CPU周期,CVM consumes 5,833 cycles more than its baseline
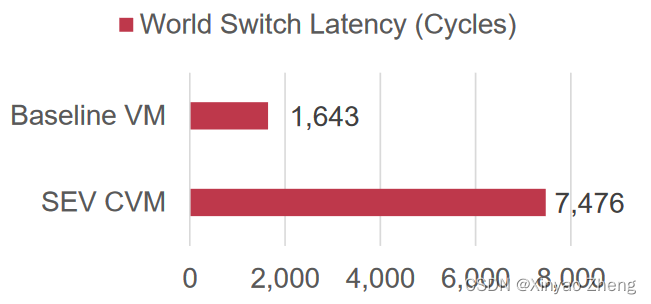
- VM exits占据CVM的大量CPU时间
- 高达20%->严重的性能影响
- 增加的延时和高频率->和baseline VM相比开销大
- posted IRQ最小化了VM推出的性能影响
- CVM+PI有最多1%的CPU周期数
- 可以在下一代的CVM硬件平台中迅速支持
Bounce Buffer
- 传统的VM内存是与管理程序共享的,只需要一次copy

- CVM内存默认设置为私有,hypervisor不可以直接访问私有内存的packets,需要多一次copy

-
多一次copy,更大的IO数据传输会导致更多的CPU时间占用
-
bounce buffer 消耗CVM的大量CPU时间
- CVM+PI有高达20%的CPU周期->严重的性能影响
- 拷贝IO数据和维护元数据都很昂贵
- 更大的数据->开销大
-
对于性能而言,有必要避免bouncing更大的IO数据
设计
设计目标
- 性能
- Bounce buffer tax: avoid bouncing large-size I/O data
- Packet processing tax: reduce the number of packets to be processed
- 安全
- Maintain the same level of security guarantees as existing CVMs
- 通用
- Applicable to diverse platforms (e.g., x86, ARM), guest/host OSes (e.g., Linux, FreeBSD)
- 实用
- Transparent to applications & Non-intrusive and minor modifications
挑战
C1:异地硬件存储器加密和解密

C2:设备驱动中昂贵的包预操作

观察
O1:端到端的加密 or 私有内存都足以保证数据的安全性

O2:端到端加密存在有效载荷位置移动的副作用

O3:I / O后端通常有大量的剩余CPU资源可用

设计
bounce buffer tax
-
D1:Zero-copy encryption deduplication (ZCED)
- 利用O1和O2消除负载的bouncing tax,进行加密后,从private memory放到share memory,只需要一次copy
- 尽量减少对CVM分配器的修改和重用,专用NUMA节点(称为ZCED NUMA)

D2. One-time trusted read (OTTR)
-
防御TOCTTOU对ZCED NUMA的攻击
-
原则:只信任从共享内存中的第一次读取,在TX和RX两个方向上实施保护
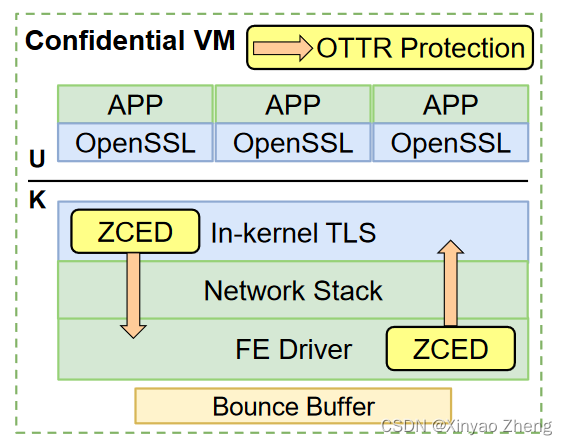
D3:预接收包重组( PRPR )
- 利用O3减少packet 预处理tax
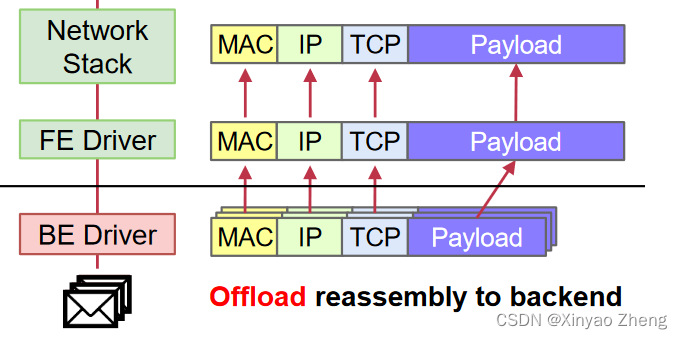
packet receive
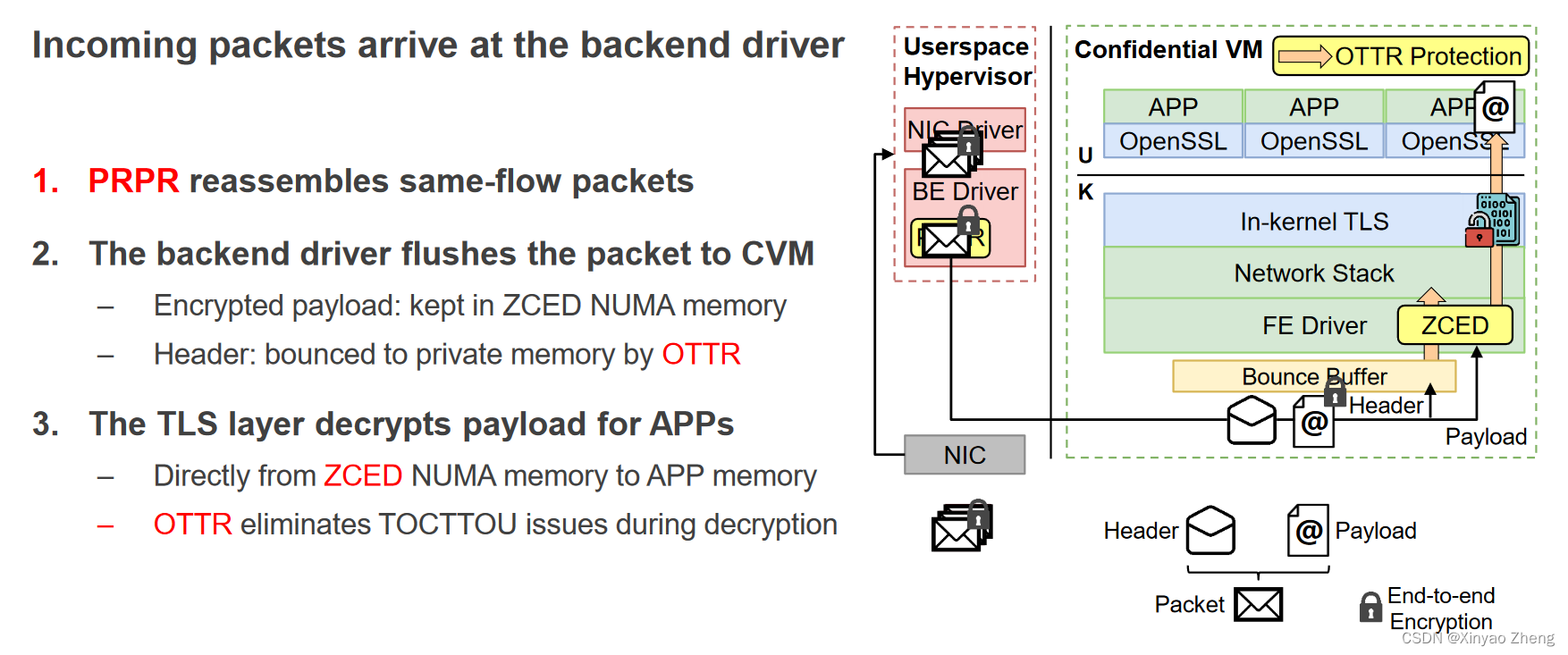
Packet Sending
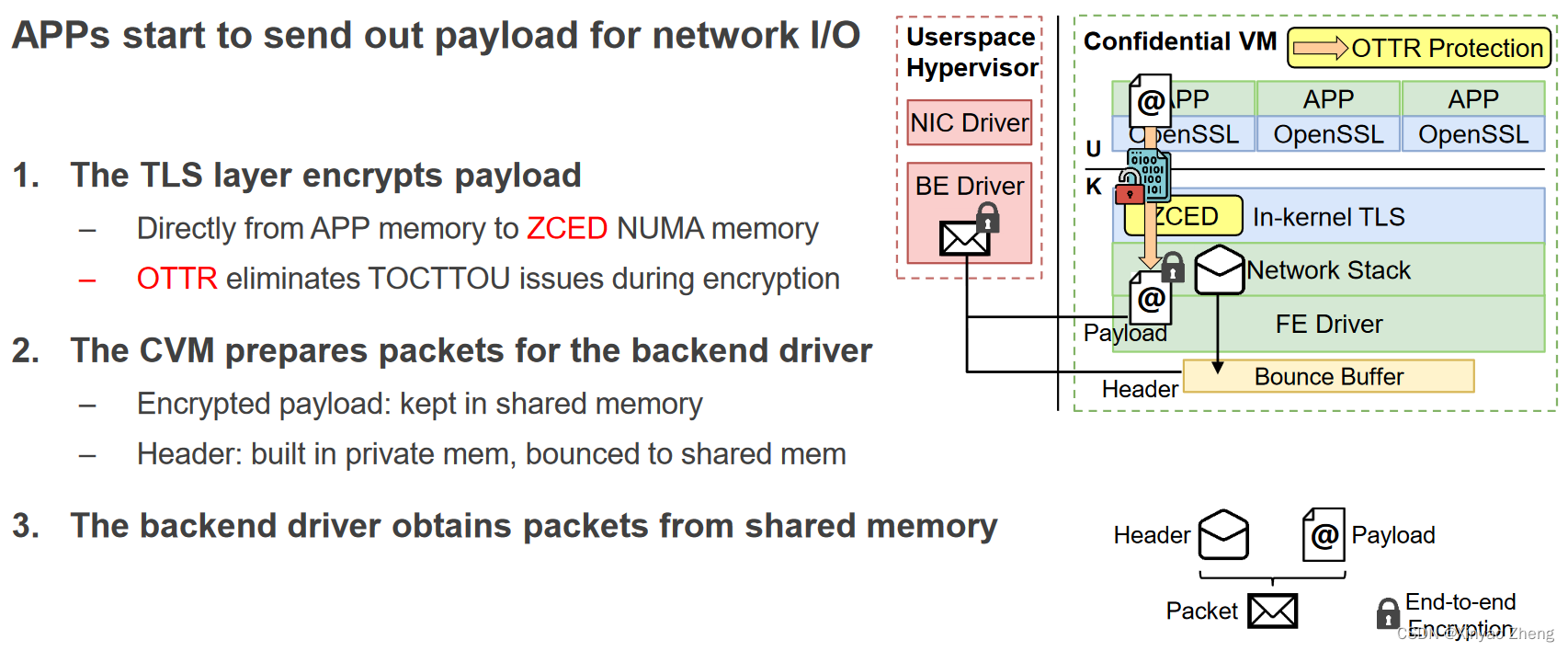
总结















 7751
7751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









