







一、维度的基本概念
1. 维度表
定义:
维度表是维度建模的两大核心之一(另一个是事实表)。它包含了描述业务过程的环境、上下文和背景的描述性信息。可以把它想象成回答 “谁、什么、何处、何时、为何” 等问题的表。
核心特征:
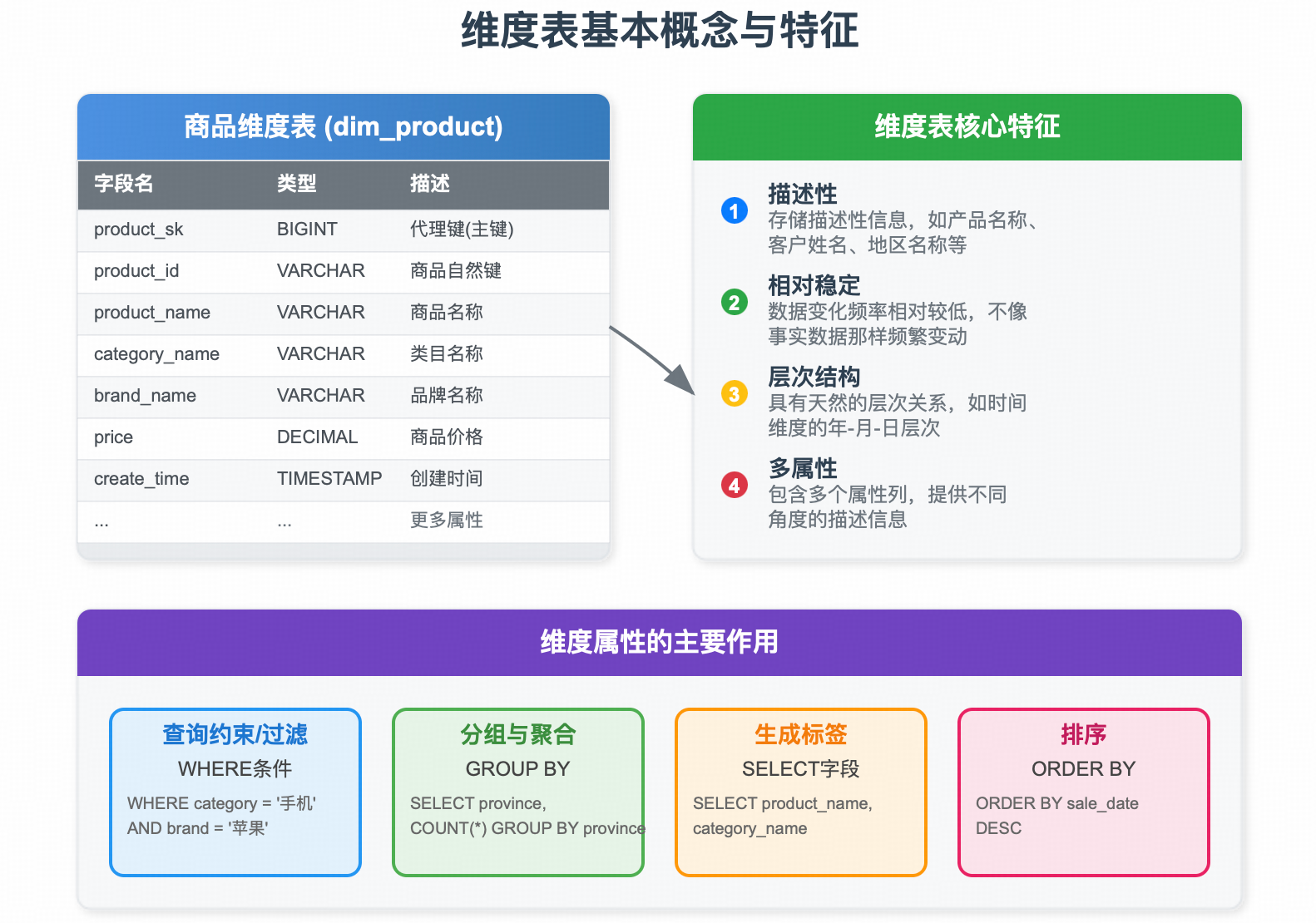
- 描述性:包含的是文本性的、离散的描述信息(如名称、状态、分类),而非可计算的连续数值
- 宽表:通常包含大量的列(属性),有时甚至会有几十到上百列,以便从各个角度描述业务
- 相对较少的数据行:与事实表相比,行数要少得多。例如,一个商品维度表可能有几百万行,而记录每天销售交易的事实表可能有几十亿行
- 查询的入口:用户的分析查询(过滤、分组、标记)绝大多数都是基于维度表的属性进行的
例子:
- 商品维度表 (dim_product)
- 主键:
product_sk(代理键) - 属性:
product_id(自然键),product_name,category_l1_name,category_l2_name,brand_name,price,color,size,is_available,seller_id, …
- 主键:
- 客户维度表 (dim_customer)
- 主键:
customer_sk - 属性:
customer_id,customer_name,gender,age_range,city,province,membership_level, …
- 主键:
2. 维度属性
定义:
维度属性是维度表中的列。它们是维度表的具体构成要素,是业务用户能够看到并直接用于分析的文本、标识或描述性数值。
作用:
维度属性是数据易用性和强大分析能力的基石。它们主要用于:
- 查询约束/过滤 (WHERE):
WHERE category = '手机' AND brand = '苹果' - 分组与聚合 (GROUP BY):
SELECT province, COUNT(*) FROM ... GROUP BY province - 生成标签/报表头 (SELECT):在报表中直接显示
product_name,category_name等 - 排序 (ORDER BY):
ORDER BY sale_date DESC
例子:
在 dim_product表中,几乎所有列都是维度属性:
product_name:用于标识和过滤特定商品category_l1_name:用于将销售数据按一级类目(如"电子设备"、“服装”)进行汇总分析brand_name:用于对比不同品牌的业绩price:虽然是一个数值,但在此处它通常用于分类(如定义价格区间)或过滤,而不是直接求和(求和是在事实表中对销售额字段进行的)
3. 如何获取维度或维度属性?
获取维度及其属性的过程是一个深度理解业务的过程,而不是一个纯粹的技术活动。
方法一:与业务人员访谈和沟通(最重要、最直接的方法)
这是发现维度的最佳途径。在与业务方(如产品经理、运营、市场人员)交谈时,要特别留意他们语言中的"按照…(by)"语句。
-
典型问题:
- “你们通常希望从哪些角度来分析销售额/用户数/订单量?”
- “在看这份报表时,你们会想要’按照’什么来拆分数据?”
- “这个指标,你们需要从时间、地区、产品类型等角度看看吗?”
-
对话示例:
- 业务人员说:“我想按照月份和产品线看看销售趋势。” → 这意味着你需要
时间维度(月)和产品维度(产品线属性) - 业务人员说:“我想对比一下不同城市、不同客户等级的购买力。” → 这意味着你需要
客户维度(城市、等级属性)和地理维度
- 业务人员说:“我想按照月份和产品线看看销售趋势。” → 这意味着你需要
方法二:从现有报表、查询和接口中逆向工程
分析现有的业务报表、应用程序中的查询语句或API接口返回的数据结构。
- 查看报表的列和筛选器:报表的列标题、分组栏、下拉筛选框,几乎直接对应了维度属性
- 分析SQL查询:查看现有应用或临时查询中的
GROUP BY,WHERE,ORDER BY子句,里面的字段极有可能就是需要的维度属性
方法三:思考业务过程的基本问题
对任何业务过程,都可以套用一些通用的问题模板来发现维度:
- 何时发生的? → 时间维度
- 在何处发生的? → 地理/位置维度
- 谁/什么参与的? → 参与者维度(用户、客户、卖家、产品、员工)
- 如何组织的? → 组织结构维度
- 为何会发生? → 促销维度、活动维度
最佳实践
-
使用代理键:
- 在数据仓库的维度表中,强烈建议使用无业务含义的代理键(如自增ID)作为主键,而不是使用源系统的自然键(如
user_id) - 好处:
- 处理缓慢变化维:当用户信息变化时(如改变地址),你可以保留历史记录而不影响现有的事实表关联
- 集成多源数据:不同源系统可能有不同的自然键,代理键可以统一管理
- 性能:通常比自然键(可能是字符串)更小,索引更快
- 在数据仓库的维度表中,强烈建议使用无业务含义的代理键(如自增ID)作为主键,而不是使用源系统的自然键(如
-
维度属性应尽可能丰富:
- “越宽越好”。尽可能多地加入有分析价值的描述性属性,为用户提供"无所不包"的分析能力
- 例如,在用户维度表中,除了基本信息,还可以加入通过计算得到的标签,如"高价值用户"、"新用户"等
-
使用一致的维度(一致性维度):
- 在不同的事实表和数据集市中,相同的维度(如时间、产品)应该使用相同的结构和属性
- 这是构建企业级数据仓库总线架构的基础,确保了数据的可集成性和一致性
-
对属性进行适当的反规范化:
- 为了提高查询性能,通常会将相关的层次结构反规范化到一张维度表中
- 例如,在商品维度表中,直接存储
一级类目名称、二级类目名称,而不是让用户每次都需要去关联一个规范化的类目表 - 这牺牲了部分存储空间,但换来了极大的查询便捷性和性能
-
使用明确的列名:
- 避免使用晦涩的缩写。列名应清晰、具有业务可读性,如
product_name而不是prod_nm
- 避免使用晦涩的缩写。列名应清晰、具有业务可读性,如
总结
- 维度表是数据仓库的"灵魂"。它提供了分析数据的背景和环境,是用户理解和探索数据的窗口。它宽而浅,充满了描述性信息
- 维度属性是维度表的"血液"。它们是具体的列,是用户与数据交互的直接手段,用于过滤、分组、标记和排序,是产生所有洞察的基础
- 获取维度是一个业务驱动的过程。需要通过与业务人员沟通(捕捉"按照…"语句)、分析现有报表等方式,深度理解业务分析需求,才能设计出真正有用的维度和属性
- 最佳实践的核心是易用性和性能。使用代理键、创建丰富的反规范化属性、保持维度一致性,都是为了确保数据仓库能够高效、准确、灵活地支持业务决策
本质上,维度建模就是一种业务用户看得懂、能直接使用的数据组织方式,而维度表及其属性是这种方式最直接的体现。
二、维度的基本设计方法
维度的设计过程就是确定维度属性的过程,如何生成维度属性,以及所生成的维度属性的优劣,决定了维度使用的方便性,成为数据仓库易用性的关键。正如 Kimball 所说,数据仓库的能力直接与维度属性的质量和深度成正比。
三、维度表设计步骤
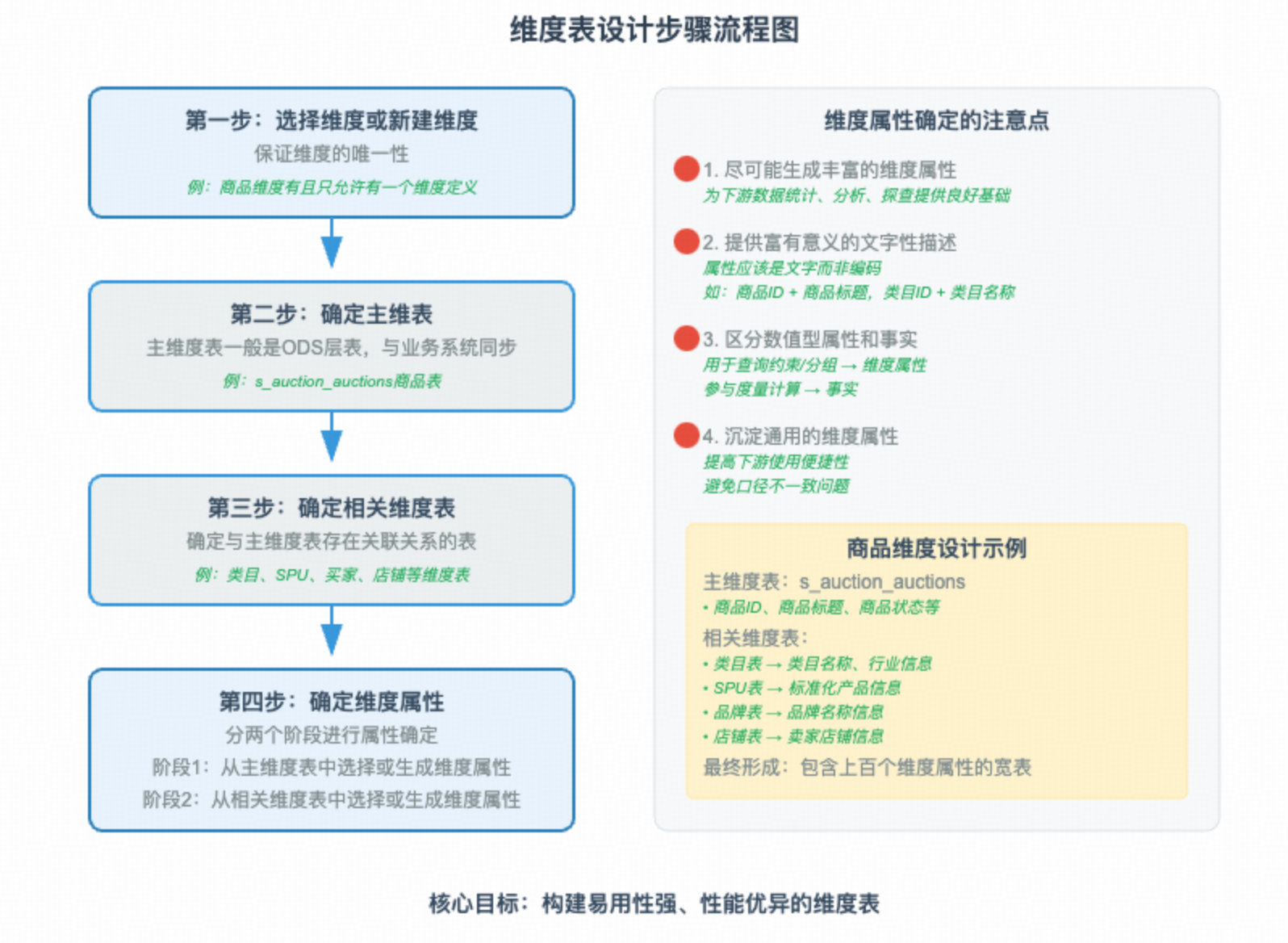
第一步:选择维度或者新建维度
作为维度建模的核心,在企业级数据仓库中必须保证维度的唯一性。以商品维度为例,有且只允许有一个维度定义。
第二步:确定主维表
主维度表一般是 ODS 层表,直接与业务系统同步。以商品维度为例:s_auction_auctions 是与前台商品中心系统同步的商品表,此表即为主维度表。
第三步:确定相关维度表
数据仓库是业务源系统的数据整合,不同业务系统或者同一业务系统的表之间存在关联性。根据业务的梳理,确定哪些表和主维度表存在关联关系。并选择其中的某些表用于生产维度属性。以商品维度为例,根据对业务逻辑的梳理,可以得到商品与类目、SPU、买家、店铺等维度存在的关联关系。
第四步:确定维度属性
主要包括两个阶段:
- 第一个阶段是从主维度表中选择维度属性或者生成新的维度属性
- 第二阶段是从相关维度表中选择维度属性和生成新的维度属性
以商品维度为例,从主维度表和类目、SPU、卖家、店铺等相关维表中选择维度属性或生成新的维度属性。
确定维度属性的注意点
1. 尽可能生成丰富的维度属性
比如商品维度有上百个维度属性,为下游数据统计、分析、探查提供了良好的基础。
2. 尽可能多地给出包括一些富有意义的文字性描述
属性不应该是编码,而应该是真正的文字。在维度建模中,一般是编码和文字同时存在,比如商品维度中的商品 ID 和商品标题、类目 ID 和类目名称等。ID 一般用于不同表之间的关联,而名称一般用于报表标签。
3. 区分数值型属性和事实
数值型字段作为事实还是维度属性,可以参考字段的一般用途。如果通常用于查询约束条件或者分组统计,则是作为维度属性;如果通常参与度量的计算,则是作为事实。
比如商品价格,可以用于查询约束条件或者统计价格区间的商品数量,此时是作为维度属性使用的。也可以用于统计某类目下商品的平均价格,此时是作为事实使用的。
另外,如果数值型字段是离散值,则作为维度属性存在的可能性较大。如果数值型字段是连续值,则作为度量存在的可能性较大,但并不绝对,需要同时参考字段的具体用途。
4. 尽量沉淀出通用的维度属性
有些维度属性获取需要进行比较复杂的逻辑处理,有些需要通过多表关联得到,或者通过单表的不同字段混合处理得到,或者通过对单表的某个字段进行解析得到。
此时,需要将尽可能多的通用的维度属性进行沉淀。一方面,可以提高下游使用的方便性,减少复杂度;另一方面,可以避免下游使用解析时由于各自逻辑不同而导致口径不一致。
例子:
-
淘宝商品的 property 字段,使用 key:value 方式存储多个商品属性。商品品牌就存储在此字段中,而商品品牌是重要的分组统计和查询约束的条件,所以需要将品牌解析出来,作为品牌属性存在
-
商品是否在线,即在淘宝网站是否可以查看到此商品,是重要的查询约束的条件,但是无法直接获取,需要进行加工。加工逻辑是:商品状态为0和1且商品上架时间小于或等于当前时间,则是在线商品;否则是非在线商品。所以需要封装商品是否在线的逻辑作为一个单独的属性字段
四、维度的层次结构
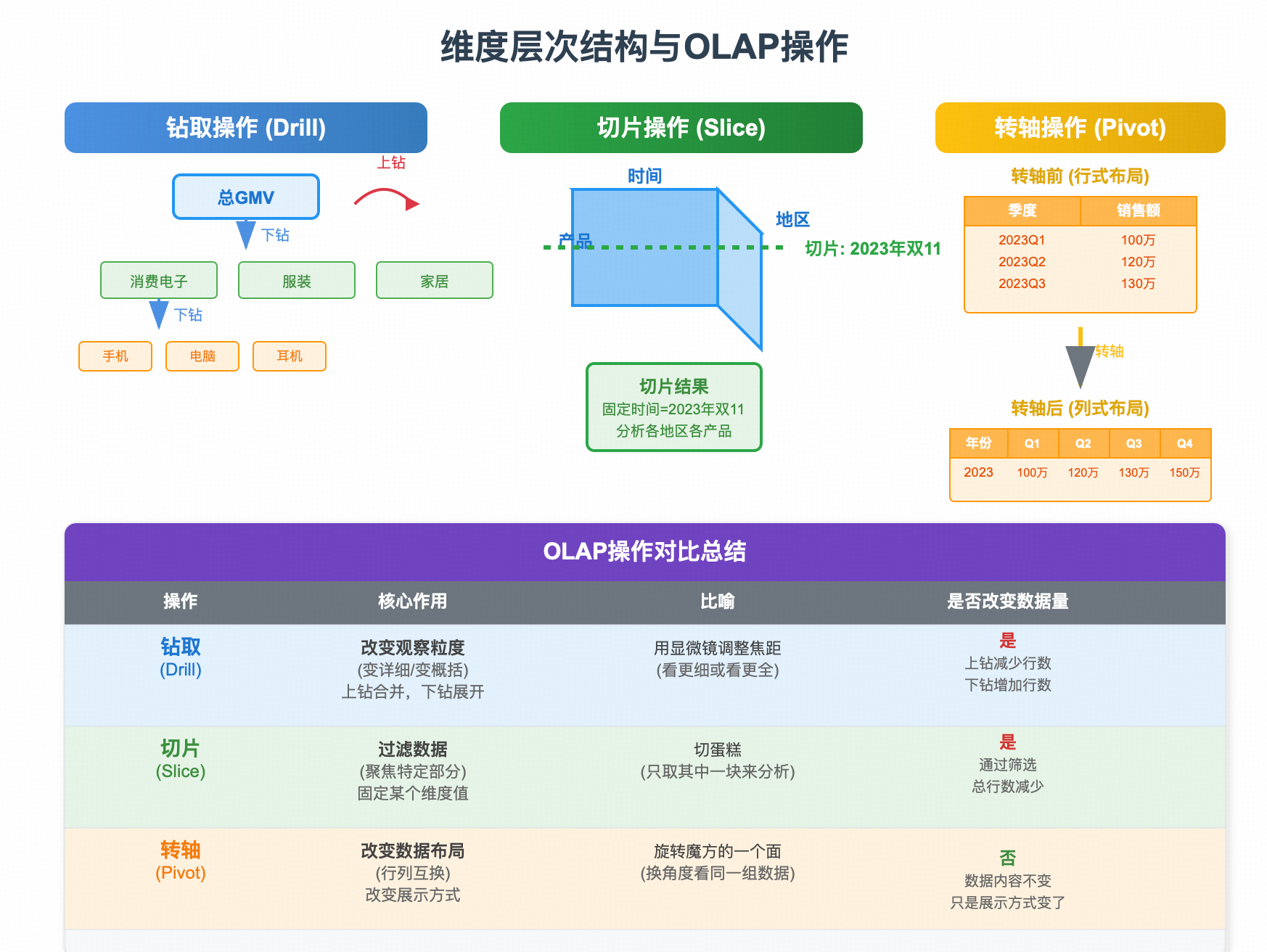
1. 维度钻取
定义:
钻取是改变数据观察粒度(详细程度)的操作。它沿着维度定义的属性层次结构向上或向下移动,从而看到更汇总或更详细的数据。
-
上钻:沿着层次结构向上,从更详细的数据到更汇总的数据。这是一种"归总"或"收敛"的过程
- 例子:从查看各个品牌(如苹果、华为、小米)的销售额,上钻到查看这些品牌所属的一级类目(如"手机")的销售额总和
-
下钻:沿着层次结构向下,从汇总数据到更详细的数据。这是一种"展开"或"细分"的过程
- 例子:在看到**“华东地区”** 总销售额表现不佳后,下钻查看该地区下各个省份(上海、江苏、浙江等)的销售额,以定位问题具体出在哪个省
钻取案例:
- 初始:2019年双11总GMV → (1行记录)
- 第一次下钻(添加
行业维度):得到每个行业的GMV → (如"消费电子"、“服装”、"家居"等,记录数等于行业个数) - 第二次下钻(在"消费电子"行业下添加
一级类目维度):得到"消费电子"行业下每个一级类目(如"手机"、“电脑”、“耳机”)的GMV → (记录数等于一级类目个数) - 还可以继续下钻到二级类目、三级类目,甚至具体商品
最佳实践:
- 设计良好的维度模型:这是钻取的前提。维度表必须包含清晰、完整的属性层次结构(如:国家-省-市、年-季度-月-日、类目层级)
- 用户界面直观:在BI工具(如Tableau, Power BI, FineBI)中,通常通过点击数据点旁的 “+” 或 “-” 号,或直接在图表上双击来实现钻取,交互必须流畅自然
- 性能优化:下钻到底层时,数据量会急剧增加。需要对底层数据表建立有效的索引和聚合表,以保证查询速度
2. 切片
定义:
切片是固定某个维度的成员值,从而过滤数据,专注于分析一个特定的"切片"。它相当于在多维数据立方体上切一刀,取出一个二维平面(或子立方体)来进行观察。
-
关键点:切片是减少分析的维度数,而不是改变现有维度的粒度。它通过筛选器(Filter)来实现
-
例子:
- 在一个包含时间、地区、产品等多维度的数据集中,固定"时间=2023年10月",然后分析各个地区和各种产品在2023年10月的销售情况。这就是一个时间切片
- 固定"产品=iPhone 14",分析这款手机在各个时间、各个地区的销售情况。这是一个产品切片
- 如果固定"活动=双11",那么后续所有的钻取操作(看行业、看类目)都是在"双11"这个切片上进行的
最佳实践:
- 提供灵活的筛选器:允许用户轻松地选择不同的维度值进行切片分析,例如使用下拉列表、搜索框、日期选择器等
- 多切片组合:通常需要同时进行多个切片,例如"时间=2023年10月"且"地区=华东",再对此切片下的数据进行钻取分析。BI工具应支持多条件筛选
3. 转轴
定义:
转轴,也称为旋转,是改变报表或视图的布局的操作。它将数据行转换为数据列,或者将数据列转换为数据行,从而改变数据的呈现方式,以提供不同的视角来分析数据。
-
核心:行列转换。它不改变数据本身的总量或粒度,只是改变了数据的排列方式
-
例子:
-
转轴前(行式布局):
年份 季度 销售额 2023 Q1 100万 2023 Q2 120万 2023 Q3 130万 2023 Q4 150万 -
转轴后(列式布局):
年份 Q1销售额 Q2销售额 Q3销售额 Q4销售额 2023 100万 120万 130万 150万 这个操作将"季度"这个维度的值从行区域移动到了列区域。
-
最佳实践:
- 交叉表:转轴最常见的应用就是创建交叉表(数据透视表),行和列上都可以放置多个维度,交叉点显示度量值(如销售额、数量),非常适合进行多维度对比分析
- 用户自助服务:现代BI工具都提供拖拽式转轴功能,用户可以将字段从"行"拖到"列",或者从"列"拖到"行",极大地增强了探索数据的灵活性
总结与关系
| 操作 | 核心作用 | 比喻 | 是否改变数据量 |
|---|---|---|---|
| 钻取 | 改变观察粒度(变详细/变概括) | 用显微镜调整焦距(看更细或看更全) | 是。上钻合并数据,行数减少;下钻展开数据,行数增加。 |
| 切片 | 过滤数据(聚焦特定部分) | 切蛋糕(只取其中一块来分析) | 是。通过筛选,只显示部分数据,总行数减少。 |
| 转轴 | 改变数据布局(行列互换) | 旋转魔方的一个面(换一个角度看同一组数据) | 否。数据内容不变,只是展示方式变了。 |
协同工作:
在实际分析中,这三个操作总是协同使用的:
- 首先,通过切片锁定你要分析的范围(例如:只看2023年双11的数据)
- 然后,对这个数据切片进行钻取,从年份下钻到季度,再下钻到月份,查看趋势细节
- 最后,你可以通过转轴,将"月份"作为列,"产品类别"作为行,形成一个清晰的交叉表,对比各个品类在各个月份的表现
最终总结:
钻取、切片和转轴是数据探索的三大基本操作。它们赋予了分析师从"宏观"到"微观"、从"全面"到"聚焦"、从"一个视角"到"另一个视角"自由切换的能力,是构建交互式、自助式分析系统的基石。理解并熟练运用这些操作,是有效进行数据分析和洞察的关键。
五、规范化和反规范化
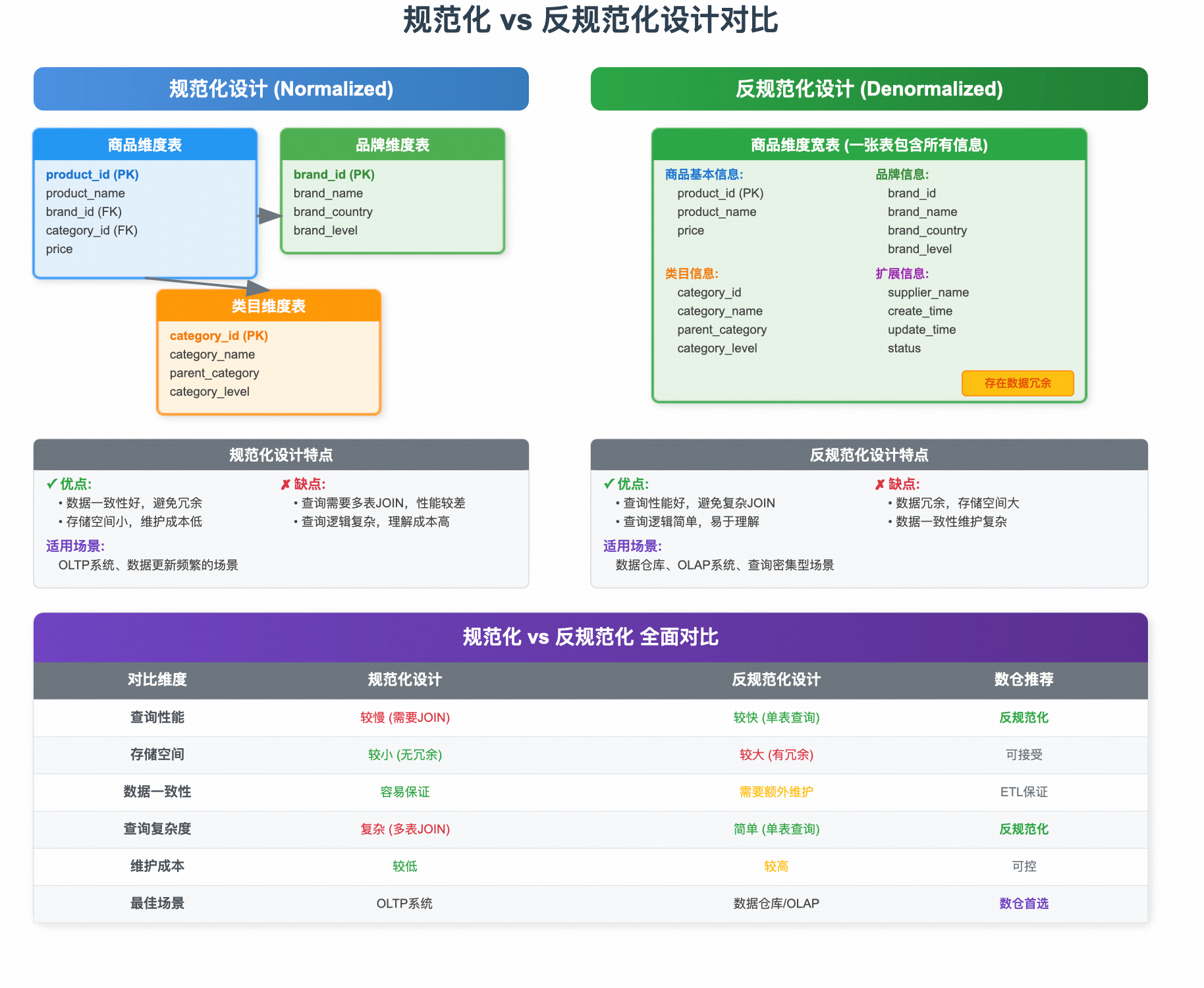
核心概念对比
| 特性 | 规范化 (雪花模式) | 反规范化 (扁平维度) |
|---|---|---|
| 设计目标 | 减少数据冗余,保证数据一致性,优化事务处理(OLTP)。 | 优化查询性能,简化数据模型,方便数据分析(OLAP)。 |
| 结构特点 | 将维度属性层次拆分成多个关联的表,形成树状或雪花状结构。 | 将维度属性层次合并到单个维度表中,形成宽表。 |
| 数据冗余 | 低。相同数据(如类目名称)只存储一次。 | 高。相同数据(如类目名称)在多个商品记录中重复存储。 |
| 查询性能 | 差。需要大量的表关联(JOIN)操作,非常消耗资源。 | 优。查询通常只需扫描单表或减少关联,速度极快。 |
| 模型复杂度 | 高。对用户不友好,需要了解复杂的表间关系才能正确查询。 | 低。对用户非常友好,易于理解和使用。 |
| 适用场景 | 联机事务处理系统(OLTP),如业务后台系统、ERP、CRM。 | 联机分析处理系统(OLAP),如数据仓库、数据集市、BI平台。 |
雪花模式示例
在雪花模式下,"商品"维度会被拆分成多个关联的表:
-
核心表 (被事实表关联的表):
商品表。它包含了最核心的信息,如商品ID(主键)、商品标题,并通过外键(类目ID,品牌ID,SPU_ID)关联到其他维度表 -
关联的维度表:
类目表:提供商品的分类信息品牌表:提供商品的品牌信息SPU表:提供标准化产品单元的信息- 值得注意的是,
类目表本身还包含了行业ID和行业名称,这意味着行业信息并没有被进一步规范化到单独的表中,而是被"反规范化"到了类目表里。这其实是一个混合模式,体现了设计上的权衡
在这种雪花模型下,一个简单的查询会变得复杂:
查询: “列出所有’电子产品’行业下的’苹果’品牌商品的名称”
SQL可能如下(需要多次JOIN):
SELECT p.商品标题
FROM 商品 p
JOIN 类目 c ON p.类目ID = c.类目ID -- 第一次JOIN,为了拿到行业
JOIN 品牌 b ON p.品牌ID = b.品牌ID -- 第二次JOIN,为了拿到品牌名称
WHERE c.行业名称 = '电子产品'
AND b.品牌名称 = '苹果';
反规范化设计示意图
如果采用反规范化设计,商品维度表(dim_product) 将合并所有属性,形成一个宽表,其结构将如下所示:
| 列名 | 示例值 | 来源 |
|---|---|---|
| product_sk (代理键) | 10086 | ETL生成 |
| product_id (自然键) | 123456789 | 商品表 |
| product_title | iPhone 15 Pro Max | 商品表 |
| category_id | 50012026 | 商品表 → 类目表 |
| category_name | 手机 | 类目表 |
| industry_id | 4 | 类目表 |
| industry_name | 消费电子 | 类目表 |
| brand_id | 100 | 商品表 → 品牌表 |
| brand_name | 苹果 | 品牌表 |
| spu_id | ABC123 | 商品表 → SPU表 |
| spu_name | iPhone 15 系列 | SPU表 |
| … (其他属性) | … | … |
同样的查询,在反规范化后变得极其简单:
查询: “列出所有’电子产品’行业下的’苹果’品牌商品的名称”
SQL变得非常简单:
SELECT product_title
FROM dim_product -- 只需要一张表!
WHERE industry_name = '消费电子'
AND brand_name = '苹果';
最佳实践与总结
-
OLAP系统首选反规范化:
- 数据仓库和BI系统的核心目标是快速查询和分析,而不是频繁的事务更新
- 数据一旦导入,通常非常稳定(只读或少量更新)
- 因此,牺牲存储空间来换取极致的查询性能和易用性是绝对值得的
-
存储成本与性能成本的权衡:
- 存储成本非常低廉,而计算资源(CPU)和工程师的时间成本非常高昂
- 让昂贵的计算资源在每次查询时都去执行复杂的JOIN操作,是一种巨大的浪费
- 预先通过ETL过程完成JOIN,将结果扁平化存储,是更经济的选择
-
简化模型,赋能业务用户:
- 一个扁平的、包含所有常用属性的维度表,使得业务人员(如数据分析师、运营)可以直接使用像Tableau、FineBI这样的工具进行拖拽分析
- 无需深入理解底层复杂的数据库关系,极大地降低了使用门槛,提升了数据驱动的效率
-
并非绝对禁止雪花模式:
- 在某些极端情况下,如果某个维度属性非常庞大且很少被查询,可以考虑将其单独存放以避免主维度表变得过于臃肿
- 但这属于特例优化,而非通用原则
最终总结:
在数据仓库的维度建模中,几乎总是应该选择反规范化的扁平维度设计。
- 雪花模式是OLTP系统的设计哲学,旨在保证数据的一致性和更新效率
- 反规范化是OLAP系统的设计哲学,旨在追求数据的查询性能和使用易用性
数据仓库的ETL流程的核心任务之一,就是将OLTP源系统的雪花模式通过预先的关联和计算,整合成反规范化的扁平维度表,从而为上层分析应用提供强大、高效、易用的数据服务。
六、一致性维度和交叉探查
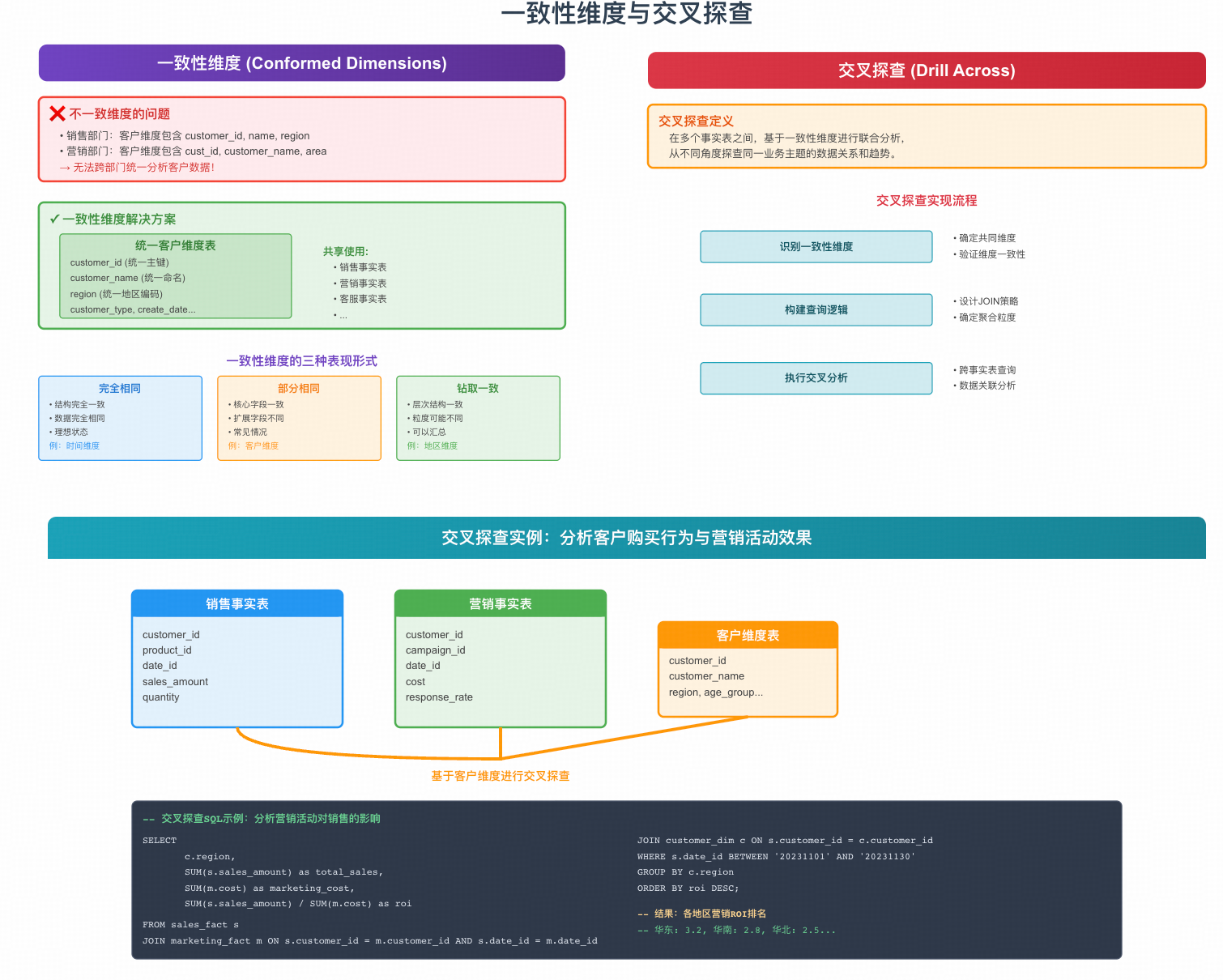
1. 一致性维度
定义:
一致性维度是指在不同数据集市或事实表中,具有相同含义、相同结构、相同内容的维度。简单来说,就是"在整个企业数据仓库中,对同一个业务对象,有且只有一个统一的定义"。
核心目标:
消除"信息孤岛",确保不同业务团队、不同数据域的分析结果可以无缝地整合和对比,保证数据的唯一可信性。
三种表现形式及其例子:
-
共享维度表(最高形式)
- 定义:物理上就是同一张维度表,被所有事实表共享
- 例子:在阿里巴巴的数据仓库中,
dim_product(商品维度表)有且只有一个。无论是分析交易事实表(如订单)、日志事实表(如点击流)、还是库存事实表,它们都关联到这张唯一的商品维度表。这意味着所有业务中对"商品"的定义(如品牌、类目、状态等)是完全一致的
-
一致性上卷
- 定义:其中一个维度是另一个维度的子集。子集维度的所有属性都来自父维度,且名称、数据类型、值域完全一致
- 例子:
dim_category(类目维度)和dim_product(商品维度)。dim_category中的属性(如类目ID,类目名称,行业ID,行业名称)也同时存在于dim_product中,并且含义和值完全相同。因此,基于"类目"进行跨业务过程的交叉分析不会有任何问题
-
交叉属性
- 定义:两个不同的维度拥有部分相同的属性。这些公共属性在两个维度中必须保持一致
- 例子:
dim_product(商品维度)中有category_id和category_name,dim_seller(卖家维度)中有main_category_id和main_category_name(卖家主营类目)。虽然两个维度不同,但它们都包含了"类目"这个属性。只要这两个类目属性来自同一个主数据源,定义一致,我们就可以分析"某个类目下的商品交易额"与"主营该类目的卖家数量"之间的关系
不一致性的严重后果(反面教材):
- 属性缺失:日志域用
商品维度1(有BC类型),交易域用商品维度2(无BC类型)。导致无法分析"天猫商品和集市商品的转化率差异" - 格式不一致:
商品维度1的上架时间是yyyy-MM-dd,商品维度2是时间戳。需要复杂的转换才能按上架日期分析,极易出错 - 内容不一致:
商品维度1不包含旅行商品,商品维度2包含。导致分析整体转化率时,日志域的PV基数偏小,计算结果完全错误
2. 交叉探查
定义:
交叉探查是指将来自不同业务过程或不同数据域的事实数据,在一致的维度基础上,进行关联、对比、计算的分析过程。
核心前提:一致性维度。没有一致性维度,交叉探查就是无源之水,无本之木。
过程:
- 在不同的数据域中,业务过程被建模为不同的事实表(如
fact_log_daily日志日快照表,fact_trade_daily交易日快照表) - 这些事实表通过一致性维度(如商品维度、时间维度)关联在一起
- 分析师可以轻松地将这些事实进行组合计算,产生新的、综合性的指标
交叉探查案例详解:
- 业务过程1:用户浏览商品 → 记录到日志域,生成事实表
fact_page_view,度量:PV、UV - 业务过程2:用户下单购买 → 记录到交易域,生成事实表
fact_order,度量:GMV - 交叉探查:计算"商品转化率" =
GMV / UV - 如何实现:
- 首先,必须存在一张一致性商品维度表
dim_product,被fact_page_view和fact_order共同使用 - 然后,通过ETL过程,分别聚合出每个商品的每日UV和每日GMV
- 最后,基于
商品ID和日期,将两个事实的聚合结果关联起来,即可轻松计算转化率
- 首先,必须存在一张一致性商品维度表
SQL示例:
SELECT
p.product_name,
p.category_name,
log.uv,
trade.gmv,
trade.gmv / log.uv as conversion_rate -- 交叉探查计算转化率
FROM dim_product p
JOIN (
SELECT product_sk, date_sk, COUNT(DISTINCT user_id) as uv
FROM fact_page_view
GROUP BY product_sk, date_sk
) log ON p.product_sk = log.product_sk
JOIN (
SELECT product_sk, date_sk, SUM(gmv) as gmv
FROM fact_order
GROUP BY product_sk, date_sk
) trade ON p.product_sk = trade.product_sk AND log.date_sk = trade.date_sk
WHERE log.date_sk = 20230810;
最佳实践
-
建立企业数据仓库总线架构:
- 在项目规划初期,就定义好企业级的一致性维度和标准事实的矩阵清单
- 这是数据仓库的"蓝图"和"合同",所有团队都必须遵守
-
中心化的维度管理:
- 设立专门的团队或流程来管理和发布核心一致性维度(如商品、用户、时间)
- 其他团队不能自行创建这些维度的副本,必须从中央仓库获取
-
使用代理键:
- 在一致性维度表中使用代理键,而不是自然键
- 这可以有效处理不同源系统间自然键冲突、变化等问题,是维护维度一致性的技术保障
-
在ETL过程中实现一致性:
- 构建强大的ETL流程,确保所有下游事实表所使用的维度数据都来自同一个权威的、经过清洗和转换的维度表源头
- 确保属性的格式、内容、粒度都符合总线架构的定义
-
增量迭代开发:
- 按照数据总线架构的规划,一次只实施矩阵中的一行(即一个业务过程)
- 每次迭代都确保新加入的事实表与已有的事实表共享一致性维度
- 这样既能快速交付价值,又能保证最终的整体一致性
总结
-
一致性维度是方法和基础。它是Kimball数据仓库总线架构的灵魂,通过在企业内强制实行维度的统一定义,为数据的集成和一致性提供了保障。它就像城市的"标准轨距",确保所有"列车"(数据)都能在"轨道系统"(数据仓库)上无缝运行
-
交叉探查是目的和价值。它是数据仓库最终要支持的高级分析能力,允许用户打破业务过程的界限,从全局视角分析问题,从而发现更深层次的洞察(如转化率、漏斗分析、全局运营效率等)
二者关系:一致性维度是实现有效交叉探查的前提,交叉探查是体现一致性维度价值的核心场景。
遵循"总线架构"和"一致性维度"的理念构建数据仓库,可以从一开始就避免形成孤立的、不一致的数据集市,从而建成一个真正为企业服务的、灵活的、可扩展的企业级数据仓库。


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









