







2023/12/15 菜鸟记录.
场景:Minio上存储了txt文件,需要Flink读取解析,写入Doris表。
背景:Flink版本 1.14.4
Doris版本 1.1.5
采坑1:使用自定义SourceFunction读取Minio数据,使用Flink-Doris-Connector写入Doris。
结果1:写入失败,不报错。因为无界流写入Doris必须开启Batch模式。

但是坑来了,SourceFunction的有界性是写死的,值为无界。所以设置批处理模式后会运行报错:Detected an UNBOUNDED source with the 'execution.runtime-mode' set to 'BATCH.

采坑2:使用自定义SourceFunction读取Minio数据,使用Flink-Mysql-Connector写入Doris。
结果2:写入成功,但是速度太慢。3并行度每秒才写入几十条,设置了批写入提升效果不明显。
采坑3:使用Doris自带的Broker Load导入。
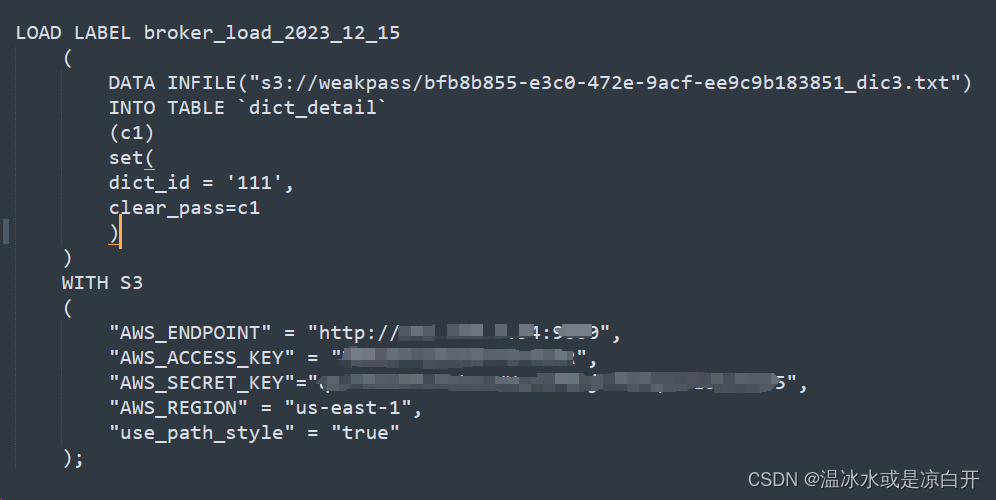
结果3:BrokerLoad功能有限,只能将映射文件中的字段c1到表中的clear_pass,但是不能指定dict_id为定值‘111’.
最终实现:使用Flink-S3-Connector读取Minio数据,使用Flink-Doris-Connector写入Doris。
把Flink官网仔细通读了一遍,发现Flink兼容Minio这样的S3对象存储服务。详见:Amazon S3 | Apache Flink
步骤 1:在flink-conf.yaml配置中添加:(切记s3.endpoint要加http://, 踩过坑。)
s3.access-key: XXXXXXX
s3.secret-key: XXXXXXX
s3.endpoint: http://XXXXXXXXX:XXXX/
s3.path.style.access: true
fs.allowed-fallback-filesystems: s3
步骤 2:下载S3插件,flink-s3-fs-hadoop-(flink版本号).jar
https://mvnrepository.com/artifact/org.apache.flink/flink-s3-fs-hadoop
步骤 3:在服务器的 (Flink目录)/plugins/目录下创建目录flink-s3-fs-hadoop,把jar包放进来。不用在pom里引依赖,Flink会默认在plugins/下面找。
步骤 4:重启Flink服务。配置生效,flink-s3-fs-hadoop插件自动载入。
步骤 5:Coding!直接用!

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









