







 本文通过一个简单的WordCount程序,展示了Flink 1.12.0中批流一体的功能。在不设置RuntimeExecutionMode时,批数据被当作流数据处理。当设置为Batch模式时,发现存在bug导致结果错误。升级到Flink 1.12.1及以上版本后,问题得到解决,得到了正确的批处理结果。
本文通过一个简单的WordCount程序,展示了Flink 1.12.0中批流一体的功能。在不设置RuntimeExecutionMode时,批数据被当作流数据处理。当设置为Batch模式时,发现存在bug导致结果错误。升级到Flink 1.12.1及以上版本后,问题得到解决,得到了正确的批处理结果。
一、问题
在Flink1.12.0有个重要的功能,批流一体,就是可以用之前流处理的API处理批数据。
只需要调用setRuntimeMode(RuntimeExecutionMode executionMode)。
RuntimeExecutionMode 就是一个枚举,有流、批和自动。
@PublicEvolving
public enum RuntimeExecutionMode {
STREAMING,
BATCH,
AUTOMATIC;
private RuntimeExecutionMode() {
}
}
下面用最最简单的WordCount程序演示。
1. 待测试的文本txt
apple flink flink
hello es flink
study flink
2. WordCount,不设置setRuntimeMode
public class Test01_WordCount_Tuple {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.readTextFile(BaseConstant.WORD_COUNT_TEST);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = source
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(" ");
if (split != null && split.length > 0) {
Stream<String> stream = Arrays.stream(split);
stream.forEach(word -> out.collect(Tuple2.of(word, 1)));
}
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = wordAndOne
.keyBy(f -> f.f0)
.sum(1);
sum.print();
env.execute();
}
}
运行结果:可见是按照流处理的方式处理了批数据,这不是我们想要的
5> (study,1)
7> (flink,1)
6> (es,1)
7> (flink,2)
7> (apple,1)
7> (flink,3)
7> (flink,4)
3> (hello,1)
3. WordCount,且setRuntimeMode(RuntimeExecutionMode.BATCH)
只需要设置env.setRuntimeMode(RuntimeExecutionMode.BATCH),依旧用流处理的keyBy方法。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
和之前唯一不同的是添加了这行,设置为批处理
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
DataStreamSource<String> source = env.readTextFile(BaseConstant.WORD_COUNT_TEST);
运行结果
7> (flink,4)
这个时候发现只有flink这个单词有输出,显然这是不对的。
4. 解决问题
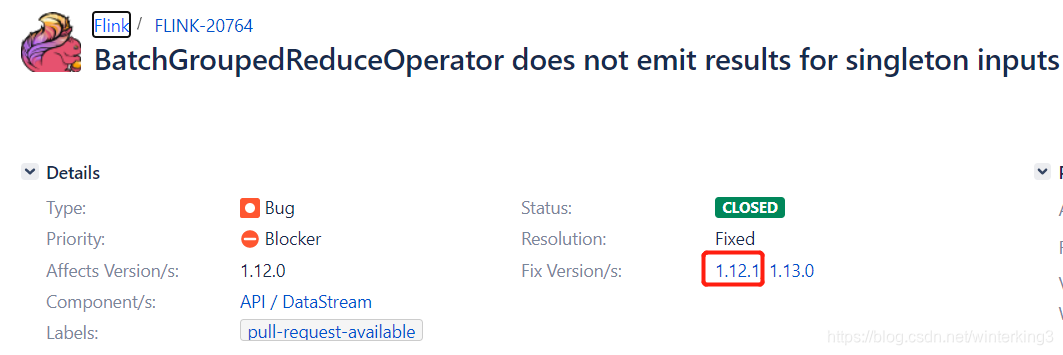
通过百度发现该bug已经在Flink1.12.1修复了,bug是因为在批处理reduce里对单个值的累加器有问题。
升级到Flink1.12.1及以上(写博客时,最新是1.12.2)。发现可以解决问题。
升级Flink后运行结果如下:这个我们想要的批处理结果。
5> (study,1)
6> (es,1)
7> (apple,1)
3> (hello,1)
7> (flink,4)


















 1760
1760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











