






A Locality Sensitive Hashing Based Approach for Federated Recommender System
摘要
推荐系统是大数据分析中的一个重要应用,给出准确的推荐和有价值的建议可以为商业公司和客户带来高利润。为了做出精确的推荐,推荐系统通常需要大量的细粒度数据进行训练。在当前的大数据时代,数据往往以孤岛的形式存在,出于隐私安全的考虑,很难对分散的数据进行集成。此外,隐私法律法规让数据共享变得更加困难。因此,设计一个隐私保护的推荐系统至关重要。现有的隐私保护推荐系统模型主要采用密码学方法来实现隐私保护。然而,加密方法在执行加密和解密操作时开销很大,并且缺乏良好的灵活性。本文提出了一种基于局部敏感哈希(LSH)的联邦推荐系统方法。我们提出的高效且可扩展的联邦推荐系统可以充分利用来自不同数据所有者的多源数据,同时保证参与方的隐私保护。在真实基准数据集上的大量实验表明,我们的方法可以在较小的隐私预算下实现高时间效率和准确性。
关键词推荐系统;位置敏感哈希;差别隐私
1 Introduction
推荐系统旨在在大量选择中为用户提供选择建议。它是一种重要而实用的数据挖掘技术,受到学术界和工业界的广泛研究,例如网飞Netflix为其用户举办了一场最佳预测电影的公开竞赛[1]。基于不同的推荐项目生成方法,已经提出了各种各样的模型[2]。在这些方法中,过滤技术起着重要的作用。根据性格过滤而言,过滤算法可以分为协作过滤、人口统计过滤、基于内容的过滤和混合过滤。详见[2]。
在当前的大数据时代,信息丰富、粒度细的数据集以孤岛的形式存在,对包括推荐系统在内的传统数据挖掘和分析领域提出了相当大的挑战[3]。为了实现准确的推荐,推荐算法通常涉及多个源数据进行训练。但是,通常情况下,不同所有者收集的多源数据存在于不同的位置。例如,在产品推荐服务中,电器产品在线经销商京东公司拥有用户购买电器产品的数据,但是用户购买日常用品的数据可以存在于其他的日常用品在线经销商中,例如淘宝和天猫。然而,由于隐私安全问题和复杂的管理程序,很难整合分散在不同公司的数据。特别是随着侵犯用户隐私事件和丑闻的增多,数据安全和隐私问题引起越来越多的关注。例如,2018 年,剑桥分析网站(Cambridge Analytica)未经Facebook用户同意,从他们的个人资料中获取了数百万用户的个人数据,并进一步被用于政治目的[4]。因此,如何设计隐私保护的推荐系统算法来利用不同的数据源是至关重要的。此外,随着时间的推移,随着不断的更新,训练数据的量经常变得越来越大。因此,可扩展性和效率对于大数据应用中推荐系统的成功至关重要。
基于上述挑战,基于隐私保护的协同过滤推荐系统是一种理想的方式,可以在高效推荐的同时实现隐私保护。基于协同过滤的方法的核心思想是根据那些与目标用户最相似的用户提供的信息对每个用户进行推荐。然而,传统的协同过滤方法如使用用户 Pearson相关系数的方法需要在原始数据层面对推荐模型进行训练,这对用户数据造成隐私威胁。现有的基于协同过滤的隐私保护推荐系统主要致力于将密码学方法与协同过滤相结合来实现隐私保护。例如,提出了一种基于隐私保护项的协同过滤方法,该方法使用非同步的安全多方计算协议,在保护用户隐私的同时实现了较高的推荐准确率[5]。然而,除了执行加密和解密操作的沉重开销之外,这些方法未能为隐私保护数据发布和挖掘应用提供良好的灵活性,因为接收者将知道关于加密数据的一切(密钥是已知的)或一无所知(密钥是未知的)。一个更好的选择是利用差分隐私来控制数据效用和隐私之间的权衡,因为差异隐私有着坚实的理论基础和强大的隐私保护能力[6]。McSherry等人在[7]中提出了一个差分隐私推荐系统框架。然而,这个框架没有显示如何处理多源数据。Qi等[8]提出了一种基于的推荐系统,在利用多源数据的同时实现快速、准确的隐私保护推荐服务,但他们没有研究其方法的隐私风险,且其方法缺乏正式的隐私保障。
在本文中,我们提出了一种基于差分隐私的LSH方法,该方法可以利用不同来源的数据进行快速准确的推荐,同时为用户提供差异隐私保障。我们提出的方法有三个主要贡献。首先,我们提出了一个通用的协同过滤框架,具有差分隐私的LSH,用于可扩展的、高效的和个性化的推荐系统。与传统的基于LSH的隐私保护推荐系统相比,该方法在提供正式的隐私保证的同时,保持了较高的推荐精度。其次,我们提出的方法可以充分利用不同的数据源,同时消除数据暴露风险。最后,综合实验验证了该方法的有效性和高效性。
本文的其余部分组织如下。第二节回顾了相关的研究工作。然后,我们给出了一个例子,并在第三部分陈述了研究问题。第四部分介绍了LSH基于用户的隐私保护推荐系统潜在的隐私风险。我们的通用框架在第五节中阐述,随后在第六节中进行理论分析。第七节介绍了对基准数据集的广泛经验评估。最后,我们对全文进行了总结,并对未来的工作进行了讨论。
2 Related Work
隐私泄露丑闻使得人们在对隐私敏感数据进行分析和挖掘时,对隐私保护的高度需求,越来越多的法律法规应运而生。例如,欧盟最近发布了《General Data Protection Regulation》(GDPR),以赋予个人对其个人数据的控制权[9]。作为机器学习的经典应用,推荐系统尽可能多的收集并使用用户数据来实现准确的推荐。然而,这显然对用户的隐私有负面影响,因为他们可能会觉得系统太了解他们的真实喜好,系统收集的数据可能会被泄露。因此,设计隐私保护的推荐系统至关重要。
Kaur等提出了一种基于多方随机屏蔽和多项式聚合技术的任意分布式数据隐私保护协同过滤方案[10]。在他们的方案中,隐私保护是通过修改协议和paillier同态加密来实现的。同样,Badsha等人提出了一种基于同态加密的隐私保护的基于用户的协同过滤技术[11]。该技术可以计算用户之间的相似性,并在不泄露任何私人信息的情况下生成推荐。Polatidis等提出了一种协作过滤系统的多级隐私保护方法,在每个评分提交给服务器之前对其进行扰动[12]。数据扰动是基于多个层次和每个层次不同范围的随机值。然而,随机扰动法缺乏明确的隐私定义,难以量化隐私水平。与加密隐私模型相比,差分隐私的计算开销较小,并且具有坚实的隐私保护理论基础。Dwork等首先介绍并定义了差分隐私[6],从此差分隐私被广泛应用于各个领域。在过去的十年里,差分隐私吸引了人们的注意,其核心概念涵盖了一系列研究领域,从隐私到机器学习、数据挖掘、统计和学习理论等数据科学领域[13]、[14]、[15]。基于差分隐私,McSherry等提出了一种通用的推荐系统方案,该方案在为用户提供差别隐私保障的同时,保持了较高的推荐性能[7]。该方案采用数据预处理,然后利用数据训练许多推荐系统算法。
作为一种有效且可扩展的相似度计算方案,局部敏感哈希(LSH)已成功地充分应用于多种应用中,如近似检测、层次聚类、全基因组关联研究、图像相似度识别等[16]。这是因为LSH有一个显著的特点,即它对于相似性计算具有线性时间复杂度,而传统的成对计算具有二次复杂度。基于这些良好的特性,梁等[17]提出了实时协同过滤推荐系统。他们使用对局部敏感哈希来构建用户或项目块,这有助于实时寻找邻居和进行推荐。Qi等[8]提出了一种基于的分布式推荐系统,以实现快速、准确、高质量的推荐服务,同时保护不同参与方的用户隐私。他们表示,通过投影,用户数据的原始形式由隐藏原始数据的索引表示。然而,他们没有讨论重建原始数据的潜在问题,缺乏理论分析。
3 Motivating Example And Problem Statement
思考Fig.1中的联邦学习例子。

让A表示IMDB公司,B表示网飞公司,这两家公司都向用户推荐电影。a1和a2是IMDB中的两部电影,b1和b2是网飞的两部电影。两个用户u1和u2分别对电影{a1,a2,b1}和{b1,b2,a2}感兴趣。现在,在利益驱动下,IMDB和网飞同意分享各自用户的电影兴趣信息,以吸引更多用户。根据传统的基于用户的协同过滤推荐方法,如果IMDB想要推荐其他电影给u2,第一步是计算u1和u2之间的相似度,即sim(u1,u2)。sim(u1,u2)的计算是基于u1和u2的电影偏好,即{a1,a2,b1}和{b1,b2,a2}。然而,由于隐私考量、法律和法规,网飞不能与IMDB共享原始数据,这使得协作过程不可行,并导致不准确的推荐结果。
上面的例子可以扩展到多个公司。联邦推荐系统的目标是在不共享原始数据的情况下,基于许多公司的信息提供高质量的推荐,同时为用户提供正式的隐私保障。为了实现这一目标,我们考虑采用LSH方法来实现数据匿名化,并结合差别隐私来提供正式的隐私保障。在下一节中,我们介绍了基于LSH用户的协同过滤推荐系统[8],该系统可以在实现数据匿名的同时,实现多个公司的协同。然后,描述了我们提出的基于联邦 LSH 用户的协同过滤推荐系统(FRecLSH ),该系统不仅可以提供数据匿名,还可以提供不同的隐私保障。
4 The Fundamentals of RecLSH
RecLSH的核心思想是使用LSH作为索引技术在提供数据匿名服务时实现快速高校的推荐。我们用Fig.2来展示RecLSH提供数据匿名化的过程。
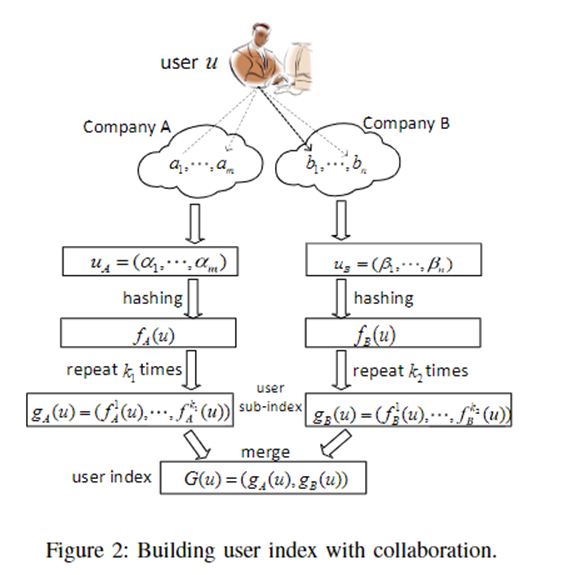
设用户u对A公司提供的
a
1
,
.
.
.
,
a
m
{a_1,...,a_m}
a1,...,am产品和B公司提供的
b
1
,
.
.
.
b
n
{b_1,...b_n}
b1,...bn产品感兴趣,A收集的偏好分数由
u
A
=
α
1
,
.
.
.
,
α
m
u_A={α_1,...,α_m}
uA=α1,...,αm记录和B收集的偏好分数由
u
B
=
β
1
,
.
.
.
,
β
m
u_B={β_1,...,β_m}
uB=β1,...,βm记录。建立用户索引的过程如下。首先,A公司和B公司都使用LSH函数对
u
A
u_A
uA和
u
B
u_B
uB进行hash操作得到
f
A
(
u
)
f_{A (u)}
fA(u)和
f
B
(
u
)
f_{B(u)}
fB(u)。然后,A使用
k
1
k_1
k1个不同的LSH函数重复
k
1
k_1
k1次哈希过程,B使用
k
2
k_2
k2个不同的LSH函数重复
k
2
k_2
k2次哈希过程。A得到用户u的子索引
g
A
(
u
)
=
(
f
A
(
u
)
1
,
…
,
f
A
(
u
)
k
1
)
g_{A (u)}=(f^1_{A (u)},…,f^{k_1}_{A (u)})
gA(u)=(fA(u)1,…,fA(u)k1),B得到用户u的子索引
g
B
(
u
)
=
(
f
B
1
(
u
)
,
…
,
f
B
(
u
)
k
2
)
g_{B(u)}=(f^1_B (u),…,f^{k_2}_{B (u)})
gB(u)=(fB1(u),…,fB(u)k2)。
g
A
(
u
)
g_{A(u)}
gA(u)和
g
B
(
u
)
g_{B(u)}
gB(u)双方都可以共享,因此,A公司和B公司可以合并用户u的子索引得到用户u的完整索引。RecLSH就基于这样一个用户索引。对于RecLSH的详细描述见[8]。
数据匿名化是指隐藏身份和/或屏蔽隐私保护数据,以保护个人隐私。由于
u
A
u_A
uA和
u
B
u_B
uB是由其索引表示的,A公司和B公司无法知道
u
A
u_A
uA和
u
B
u_B
uB的原始值,因此,RecLSH为A公司和B公司提供数据匿名。但是,数据匿名技术通常会遇到去匿名问题。例如,Narayanan 和Shmatikov通过将数据与互联网电影数据库中的电影分级进行匹配,成功地从网飞提供的匿名数据集中重新识别了个人信息[18]。作为一种数据匿名技术,RecLSH也存在隐私风险。一个直观的潜在隐私风险是恶意攻击者可以使用共享子索引
g
A
(
u
)
g_A (u)
gA(u)和
g
B
(
u
)
g_B (u)
gB(u)重建
u
A
u_A
uA或
u
B
u_B
uB。用户u的敏感信息可以通过重构结果暴露出来。除此之外,RecLSH不提供正规的隐私保护,很难量化隐私等级。基于以上的挑战,我们提出了FRecLSH在为用户提供差分隐私的同时,保留数据匿名化。
5 The Fundamentals of FRecLSH
FRecLSH以RecLSH为基础。然而,FRecLSH的挑战是证明FRecLSH能保证特定级别的隐私保护。FRecLSH的目标是建立一个差分隐私的LSH索引。我们提出了一种差分隐私LSH (DPLSH)方法来构建差分隐私LSH索引。DPLSH的核心思想是在建立hash索引的过程中添加扰动。我们引入了本地差分隐私并且展示DPLSH是怎么运行的。
Definition 1(差分隐私):
已知用户数据u,公司创建用户u的差分隐私LSH索引,并与其他公司分享。用户数据u的差分隐私LSH索引是一种嘈杂的表示。u的嘈杂LSH索引以这样的方式建立为了只泄露有限的信息,从而限制攻击者了解u的能力。为了提供强大的隐私保护,差分隐私LSH索引的构建过程就是在基于随机响应思想的防御机制实现的,隐私保护的水平是可控的。
DPLSH算法以用户数据u和参数k、p作为输入,在公司本地按照下列三步进行执行:
Step1:Hashing. 使用k个局部敏感哈希函数对u进行哈希得到哈希签名S。
Step2:Perturbation. 对于每个用户数据u和bits
i
,
0
≤
i
<
k
i
n
S
i,0≤i<k in S
i,0≤i<kinS,创建差分隐私哈希签名值KaTeX parse error: Expected group after '^' at position 2: S^̲',依照下式计算对应的值
S
i
S_i
Si。

其中p是控制隐私保护等级的可调参数。
Step3:Report. 将生成的哈希签名
S
′
S^{'}
S′发送给其他公司。

DPLSH索引的生成过程非常直观,易于理解。第二步的扰动过程将真实的本地敏感哈希值S替换为带有噪声的版本
S
′
S^{'}
S′。发送的哈希签名
S
′
S^{'}
S′可能也包含也可能不包含用户数据u的真实局部敏感哈希值,这取决于来自S的哈希值是否被随机的1/0替换,替换概率为1-p。隐私保护由步骤二保证,恶意攻击者区分真假哈希签名的能力是有限的。一次,恶意攻击者无法区分推断出的私人信息是否真实。
6 Differential privacy of DPLSH
在这一部分,我们给出了DPLSH满足ε差分隐私的证明并且给出如何选择DPLSH的参数。
A.差分隐私证明
我们通过Observation 1 来证明DPLSH满足差分隐私。
Observation 1.[19]对于
a
,
b
>
0
a,b>0
a,b>0 和
c
,
d
>
0
c,d>0
c,d>0,我们有
(
a
+
b
)
/
(
c
+
d
)
≤
m
a
x
(
a
/
c
,
b
/
d
)
(a+b)/(c+d)≤max(a/c,b/d)
(a+b)/(c+d)≤max(a/c,b/d)
Proof. 假设
a
/
c
≥
b
/
d
a/c≥b/d
a/c≥b/d,反证法令该式子为假,eg.
(
a
+
b
)
/
(
c
+
d
)
>
a
/
c
(a+b)/(c+d)>a/c
(a+b)/(c+d)>a/c,则有
a
c
+
b
c
>
a
c
+
a
d
或者
b
c
>
a
d
ac+bc>ac+ad 或者 bc>ad
ac+bc>ac+ad或者bc>ad,与假设冲突。
Theorem 1 : DPLSH的第二步扰动满足ε-差分隐私要求,其中
ε
=
k
l
n
(
p
/
(
1
−
p
)
)
ε=kln(p/(1-p))
ε=kln(p/(1−p))
Proof:令
S
′
=
s
1
′
,
…
,
s
m
′
S^{'}=s^{'}_1,…,s^{'}_m
S′=s1′,…,sm′是公司随机生成的哈希签名。通过观察任何共享的哈希值
s
′
s^{'}
s′可以观察到真正用户数据u的概率为:
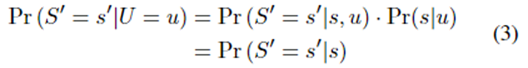
为了不失一般性,令1,…,i个哈希值被设置,eg.
s
=
h
1
=
1
,
…
,
h
i
=
1
,
h
(
i
+
1
)
=
0
,
…
h
k
=
0
s={h_1=1,…,h_i=1,h_{(i+1)}=0,…h_k=0}
s=h1=1,…,hi=1,h(i+1)=0,…hk=0。
然后,

令
S
∗
S^*
S∗为所有可能的差分隐私哈希签名的集合。令∅为具有不同S,s1,s2值的两个条件概率的比率。为了满足差分隐私要求,∅应该以exp(ε)为界限。
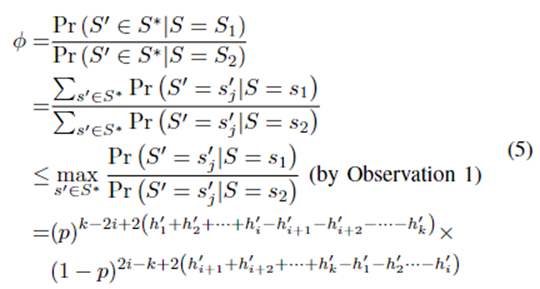
当
h
1
′
=
h
2
′
=
⋯
=
h
k
′
=
1
和
h
(
i
+
1
)
′
=
h
(
i
+
2
)
′
=
⋯
=
h
k
′
=
0
h_1^{'}=h_2^{'}=⋯=h_k^{'}=1和h_(i+1)^{'}=h_(i+2)^{'}=⋯=h_k^{'}=0
h1′=h2′=⋯=hk′=1和h(i+1)′=h(i+2)′=⋯=hk′=0时,敏感性最大化,此时
∅
=
p
k
/
(
1
−
p
)
,
ε
=
k
l
n
(
p
/
(
1
−
p
)
)
∅={p^k/(1-p)} , ε=kln(p/(1-p))
∅=pk/(1−p),ε=kln(p/(1−p))。
B.参数选择
使用LSH进行相似性搜索的成功之处在于它只有线性的时间复杂度,而传统的pair-wise计算需要二次时间复杂度。在原始LSH中,散列函数的数量k控制着相似性搜索的时间和准确性之间的权衡。小k可以保证精度,但搜索时间长。较大的k会减少时间,但是,搜索精度也会降低。一个合适的k值应该要平衡搜索时间和准确性。在我们提出的DPLSH算法中,k也控制相似性搜索时间和准确性之间的权衡。此外,p会影响准确性,因为p控制着扰动(步骤 2)过程。要实现DPLSH算法,需要调整相关参数。我们进行了许多实验(平均超过10次重复)来研究参数如何影响相似性搜索的结果。我们进行了两种类型的实验来评估p和k如何影响DPLSH的相似性搜索能力,并与传统的LSH比较相似性搜索能力。我们使用召回率来衡量相似性搜索能力。召回率是通过特点相似性搜索方法检索到的M个物品中,真正是最近邻物品的比例。我们在我们的实验中设M=100。我们使用MNIST数据库进行实验是为了方便,且在预处理和格式化方面花费时间最少。MNIST数据集具有60000个手写数字的训练集和包含10000个例子的测试集。每个图片都被转化为28*28的向量。

第一种实验研究如何选择散列函数的数量,评估散列函数k的数量如何影响召回率和运行时间。在Fig 4a中,左纵轴表示相似性搜索的召回率,右纵轴表示相似性搜索的运行时间。从Fig 4a可以看出,当k=4时,LSH的召回率为0.90(远高于k = 5),运行时间为230秒(远小于k = 3)。因此,我们建议选择k=4以实现快速相似性搜索,同时保证一定程度的相似性搜索精度。
第二种实验评估在固定的k的情况下隐私预算ε如何影响召回率。根据第一类实验,我们将k固定为 4,并将p的值设置在[0, 1)范围内。Fig 4b显示了关于不同值的召回。从Fig 4b可以看出,当隐私预算大于10时,DPLSH的相似性搜索能力与LSH几乎相同。当ε=10且k=4时,对应的p约为0.90。因此,我们建议选择k=4和p=0.90以在隐私级别和相似性搜索能力之间取得良好的平衡。
7 Experimental Evaluation
A.实验设置
为了评估FRecLsh的有效性,我们将其与RecLSH和一个典型的无隐私保护算法UPCC作对比。使用下列三个指标来衡量和比较。
- 推荐时间:生成推荐结果所消耗的时间,通过它我们可以测试推荐的效率和可扩展性。
- 平均绝对误差(MAE):推荐的预测质量和真实质量之间的平均差异,通过它我们可以测试推荐的准确性。
- 均方根误差(RMSE):预测质量与实际推荐质量之间的平方差的平均值的平方根,通过它我们可以测试推荐的准确性。
RecLSH为每个用户提供了数据匿名化保护,而FRecLsh不仅提供了数据匿名化保护,还实现了差分隐私保护。UPCC是一种基于原始数据访问的non-private协同过滤推荐方法。UPCC的MAE和RMSE是一个黄金标准,因为RecLSH和FRecLsh基于隐私数据运算。RecLSH和FRecLsh的MAE和RMSE应该比UPCC的大。我们使用一个经典的推荐数据集,即来自https://grouplens.org/datasets/jester/ 的Jester 数据集来进行推荐系统实验。Jester数据集包含来自73496个用户的100个笑话的 410万个连续评分(-10.00, 10.00)。我们根据示例的百分比将Jester数据集划分为测试数据集和训练数据集。我们将测试数据集的百分比设置为0.1,将训练数据集的百分比设置为0.9。实验在DELL OptiPlex 7050计算机上进行,该计算机具有3.60 GHz处理器和16.0 GB RAM,在Windows 10、Python 3.7上运行。
B.结果和分析
准确性比较:Fig 5a分别显示了FRecLSH、RecLSH和UPCC方法的MAE和RMSE。在Fig 5a 中,左纵轴为MAE值,右纵轴为RMSE值。如图5a所示,与FRecLSH和RecLSH相比,UPCC方法具有最小的MAE和RMSE。这是因为UPCC方法是一种非隐私保护方法,它是在原始数据上实现的。FRecLSH方法具有最大的MAE和RMSE。但是,当隐私预算增加时,FRecLSH方法的MAE和RMSE越来越小,在ε=10时略大于传统的RecLSH方法。这表明FRecLSH方法的推荐准确率具有可比性使用RecLSH方法,同时提供不同的隐私保证。
效率比较:Fig 5b分别显示了FRecLSH、RecLSH和UPCC方法的推荐时间。如Fig 5b所示,FRecLSH和RecLSH的时间成本都远小于UPCC的时间成本。这是因为基于LSH的方法对于相似度计算具有线性时间复杂度,而UPCC具有二次复杂度。RecLSH的时间成本约为UPCC的时间成本的1/5。此外,当隐私预算增加时,FRecLSH的时间成本会降低。与传统 LSH 相比,DPLSH的扰动(步骤 2)仅略微增加了处理时间。

8 Conclusions And Future Work
本文,我们提出了一个联邦推荐系统的局部敏感哈希算法。具体来说,我们将差分隐私和LSH结合起来,提出差分隐私LSH以消除潜在的数据暴露问题。实验表明,我们的差分隐私LSH可以在很小的差分隐私预算下达到与传统LSH非常接近的推荐质量。此外,与传统LSH相比,我们提出的方法在处理时间略有增加的情况下保持了效率。为给定的计算任务设计高效且有效的差分隐私算法是一个具有挑战性的问题。基于这些贡献,我们计划整合不同的LSH类型,以实现可扩展的隐私保护推荐系统。















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









