







开始时间:2022-09-11
课程链接:尚硅谷2022版JUC并发编程
JavaGuide
Java内存模型
Java 内存模型抽象了线程和主内存之间的关系,就比如说线程之间的共享变量必须存储在主内存中。Java 内存模型主要目的是为了屏蔽系统和硬件的差异,避免一套代码在不同的平台下产生的效果不一致。
注意辨析Java内存模型和Java内存模型不一样的
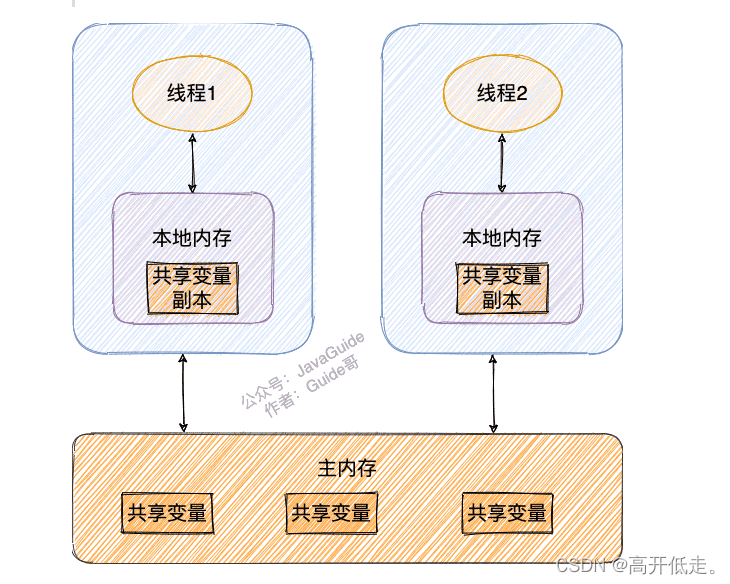
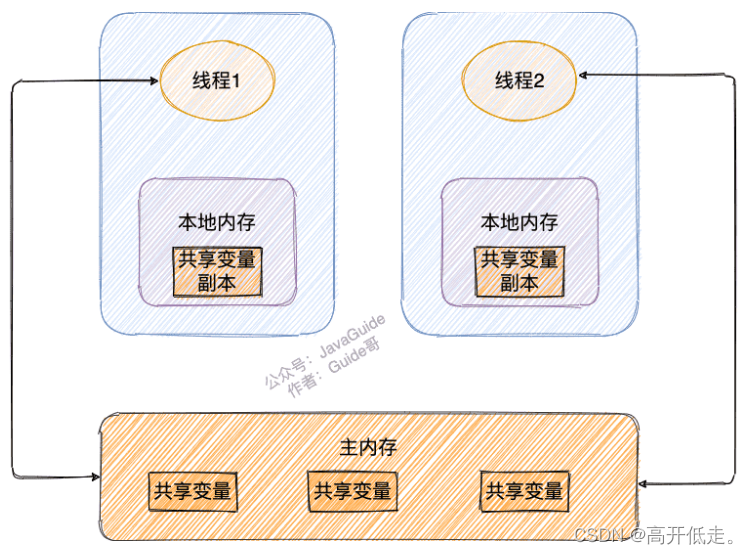
上面两个都是Java 内存模型
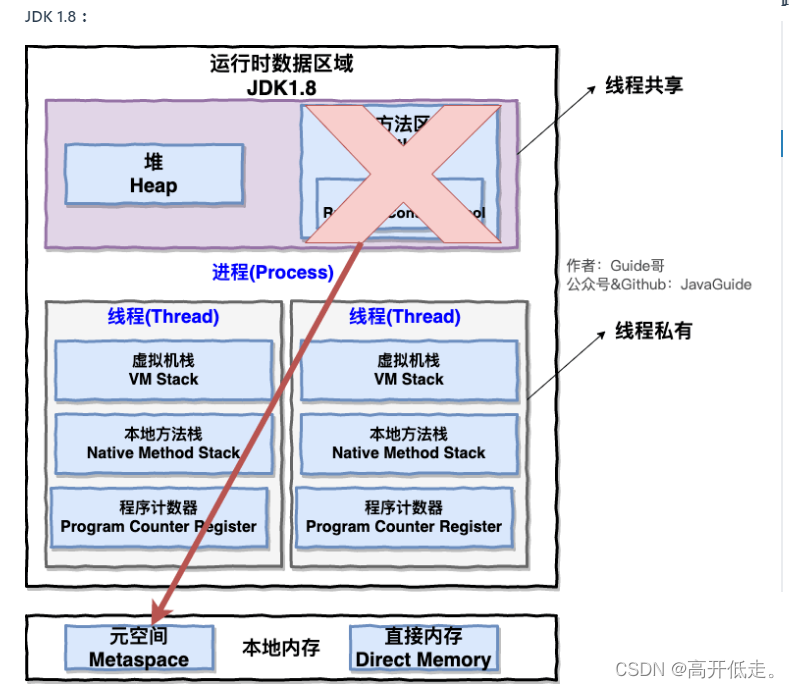
线程进程那个模型
JMM主要考虑的就是多线程三大特性:原子性,有序性,可见性
- 原子性 : 一次操作或者多次操作,要么所有的操作全部都得到执行并且不会受到任何因素的干扰而中断,要么都不执行。synchronized 可以保证代码片段的原子性。
- 可见性 :当一个线程对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。volatile 关键字可以保证共享变量的可见性。(有点像git)线程间变量值的传递均通过主内存
- 有序性 :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。volatile 关键字可以禁止指令进行重排序优化。
系统主内存共享变量数据修改被写入的时机是不确定的,多线程并发下很可能出现"“脏读”,所以每个线程都有自己的工作内存.
线程脏读
主内存中有变量x初始值为0
线程A要将x加1,先将x=0拷贝到自己的私有内存中,然后更新x的值线程A将更新后的×值回刷到主内存的时间是不固定的
刚好在线程A没有回刷x到主内存时,线程B同样从主内存中读取x,此时为0,和线程A一样的操作
最后期盼的x=2就会变成x=1
- 我们定义的所有共享变量都储存在物理主内存中
- 每个线程都有自己独立的工作内存,里面保存该线程使用到的变量的副本(主内存中该变量的一份拷贝)
- 线程对共享变量所有的操作都必须先在线程自己的工作内存中进行后写回主内存,不能直接从主内存中读写(不能越级)
- 不同线程之间也无法直接访问其他线程的工作内存中的变量,线程间变量值的传递需要通过主内存来进行(同级不能相互访问)
Happens-before
我们没有时时、处处、次次,添加volatile和synchronized来完成程序,这是因为Java语言中JMM原则下有一个“先行发生”(Happens-Before)的原则限制和规矩,给你立好了规矩!
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
- 一个unLock操作先行发生于后面((这里的“后面”是指时间上的先后))对同一个锁的lock操作;也就是说,之前用了这把锁,你后面要再获得,获得之前一定要先unlock
- 对一个volatile变量的写操作先行发生于后面对这个变量的读操作,前面的写对后面的读是可见的,这里的“后面同样是指时间上的先后
- 如果操作A先行发生于操作B,而操作B又先行发生于操作c,则可以得出操作A先行发生于操作C;
- Thread对象的start()方法先行发生于此线程的每一个动作
- 对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;可以通过Thread.interrupted()检测到是否发生中断,也就是说你要先调用interrupt()方法设置过中断标志位,我才能检测到中断发送
- 线程中的所有操作都先行发生于对此线程的终止检测,我们可以通过isAlive()等手段检测线程是否已经终止执行
- 对象没有完成初始化之前,是不能调用finalized()方法的
volatile
- 当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值立即刷新回主内存中。
- 当读一个volatile变量时,JMM会把该线程对应的本地内存设置为无效,重新回到主内存中读取最新共享变量,所以volatile的写内存语义是直接刷新到主内存中,读的内存语义是直接从主内存中读取。
内存屏障
内存屏障(也称内存栅栏,屏障指令等,是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作),避免代码重排疗。
内存屏障其实就是一种JVM指令,Java内存模型的重排规则会要求Java编译器在生成JVM指令时插入特定的芮存屏障指令,通过这些内存屏障指令,volatile实现了Java内存模型中的可见性和有序性(禁重排),但volatile无法保证原子性。
- 内存屏障之前的所有写操作都要回写到主内存,
- 内存屏障之后的所有读操都能获得内存屏障之前的所有写操作的最新结果(实现了可见性)。
读屏障:在读指令之前插入读屏障,让工作内存或CPU高速缓存当中的缓存数据失效,重新回到主内存中获取最新数据
写屏障:在写指令之后插入写屏障,强制把写缓冲区的数据刷回到主内存中
测试一下volatile的可见性
package com.bupt.volatileDemo;
public class VolatileSeeDemo {
static volatile boolean flag = true;
public static void main(String[] args) {
new Thread(() -> {
System.out.println("进入到" + Thread.currentThread().getName());
while (flag) {
}
System.out.println("成功证明了volatile后才有flag的可见性");
}, "A").start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = false;
System.out.println("修改了flag的值"+flag);
}
}
我们如果不加volatile
会一直卡着,即使修改了flag,还是不会退出来
加了volatile后,修改了flag,马上就出来了
不过当我在while里面加了sleep和sout,加不加volatile都能读出来了
弹幕老哥说如果在循环体打印sout的话,就用到了sync,会从主程序重新加载
为什么看不到,可能有两个原因
1.主线程修改了flag之后没有将其刷新到主内存,所以t1线程看不到。
⒉主线程将flag刷新到了主内存,但是t1一直读取的是自己工作内存中flag的值,没有去主内存中更新获取flag最新的值。
那我们要排查一下
我们的诉求:
1.线程中修改了自己工作内存中的副本之后,立即将其刷新到主内存;
2.工作内存中每次读取共享变量时,都去主内存中重新读取,然后拷贝到工作内存。
通过内存屏障来实现
写数据时加入屏障,强制将线程私有工作内存的数据刷回主物理内存
读数据时加入屏障,线程私有工作内存的数据失效,重新到主物理内存中获取最新值
volatile写之前的工作,都禁止重排序到volatile后(写在前)
volatile读之后的工作,都禁止重排序到volatile前(读在后)
volatile无原子性
volatile只保证读取时读取的是最新的; 但是可能其他线程已经读取过了还是拿旧的计算了
我们首先看看synchronized保证原子性
package com.bupt.volatileDemo;
public class VolatileNoAtomicDemo {
public static void main(String[] args) {
MyNumber myNumber = new MyNumber();
for (int i = 1; i <= 10; i++) {
new Thread(() -> {
for (int j = 1; j <= 1000; j++) {
myNumber.addPlusPlus();
}
}, String.valueOf(i)).start();
}
try {
Thread.sleep(120);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(myNumber.number);
}
}
class MyNumber {
int number;
public synchronized void addPlusPlus() {
number++;
}
}
输出稳稳当当10000
如果不保留synchronize,那么基本每次都是小于10000的
即使改为
volatile int number
也无济于事
那么可以证明volatile不保证原子性
对于volatile变量具备可见性,JVM只是保证从主内存加载到线程工作内存的值是最新的,也仅是数据加载时是最新的。但是多线程环境下,“数据计算"和”"数据赋值"操作可能多次出现,若数据在加载之后,若主内存volatile修饰变量发生修改之后, 线程工作内存中的操作将会作废去读主内存最新值,操作出现写丢失问题。即各线程私有内存和主内存公共内存中变量不同步,进而导致数据不一致。由此可见volatile解决的是变量读时的可见性问题,但无法保证原子性,对于多线程修改主内存共享变量的场景必须使用加锁同步。
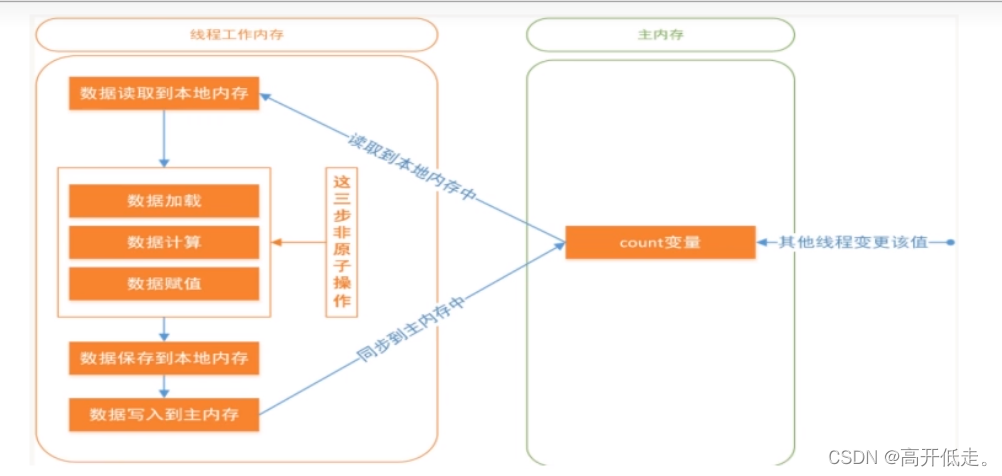
修改值的时候,发来了最新数据,此时会放弃修改,变为读操作,读到的是最新值,但是自己写的这个操作就作废了。
假设某一时刻i=10,线程A读取10到自己的工作内存,A对该值进行加一操作,但正准备将11赋给i时,由于此时i的值并未改变,B读取了主存的值仍为10到自己的工作内存,并执行了加一操作,正准备将11赋给i时,A将11赋给了i,由于volatile的影响,立即同步到主存,主存中的值为11,并使得B工作内存中的i失效,B执行第三步,虽然此时B工作内存中的i失效了,但是第三步是将11赋给i,对B来说,我只是赋值操作,并没有使用i这个动作,所以这一步并不会去刷新主存,B将11赋值给i,并立即同步到主存,主存中的值仍为11。虽然A/B都执行了加一操作,但主存却为11,这就是最终结果不是10000的原因。
因为i++这个动作是分为几个步骤的
getfield
iconst_1
iadd
putfield
B的iconst_1和iadd没执行,但putfield执行了
作者:xialedoucaicai
链接:https://www.jianshu.com/p/eabdb2ba2e56
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
volatile适用场景
- 读远多于写(boolean flag)
此时用volatile可以减轻锁开销

- 双重校验锁
package com.bupt.volatileDemo;
public class Single {
private static volatile Single instance;
private Single() {
}
public static Single getInstance() {
if (instance == null) {
//多线程并发创建对象时,会通过加锁保证只有一个线程能创建对象
synchronized (Single.class) {
if (instance == null) {
//隐患:多线程环境下,由于重排序,该对象可能还未完成初始化就被其他线程读取
//因此必须加上volatile
instance = new Single();
}
}
}
return instance;
}
}
正常顺序是
分配对象内存空间->初始化对象->设置instance指向刚分配的内存地址
没有volatile这上面三个可能不按顺序执行
CAS
compare and swap的缩写,中文翻译成比较并交换,实现并发算法时常用到的一种技术。它包含三个操作数——内存位置、预期原值及更新值
执行CAS操作的时候,将内存位置的值与预期原值比较;如果相匹配,那么处理器会自动将该位置值更新为新值,
如果不匹配,处理器不做任何操作,多个线程同时执行CAS操作只有一个会成功。
CAS请求参数有V内存地址,A旧的预期值,B新值
当V中值和A相等,用B的值更新V的值
否则不更新或重来
重来的行为成为自旋(针对CAS失败的一种策略)(do… while…)
共享变量5,本地内存读到5,加1,CAS的旧值是5,新值设置为6
CAS后共享变量就是6了
那如果共享变量是5,本地内存读到5,其他线程给共享变量改为6了,那么就CAS重来
再去读,此时独到共享变量为6,本地内存读到6,加1,CAS旧值是6,新值设置为7,再写回共享内存
写个Demo看看
单线程
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(5);
System.out.println(atomicInteger.compareAndSet(5, 2022) + " " + atomicInteger.get());
System.out.println(atomicInteger.compareAndSet(5, 2023) + " " + atomicInteger.get());
}
原子类下面有一个Unsafe类
由于Java方法无法直接访问底层系统,需要通过本地(native)方法来访问,Unsafe可以像C的指针一样直接操作内存
Unsafe类的所有方法都是native修饰的,也就是说Unsafe类中的方法都直接调用操作系统底层资源执行相应任务。
没有CAS我们怎么保证原子性的呢?
public class AtomicDemo01 {
volatile int number = 0;
public int getNumber() {
return number;
}
public synchronized void setNumber() {
number++;
}
}
但是synchronized毕竟重量级锁,如何优化呢?
AtomicInteger atomicInteger = new AtomicInteger();
public int getAtomicInteger(){
return atomicInteger.get();
}
public void setAtomicInteger(){
atomicInteger.getAndIncrement();
}
原子类利用CAS+Volatile和native方法来安保证原子操作
手写自旋锁
自旋锁指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,当线程发现锁被占用时,会不断循环判断锁的状态,直到获取。这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU
底层本质就是 while 循环
我们自己来实现一下
public class SpinLockDemo {
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void lock() {
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + " " + "--come in");
while (!atomicReference.compareAndSet(null, thread)) {
}
}
public void unLock() {
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread, null);
System.out.println(Thread.currentThread().getName() + " " + "task over");
}
public static void main(String[] args) {
SpinLockDemo spinLockDemo = new SpinLockDemo();
new Thread(()->{
spinLockDemo.lock();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
spinLockDemo.unLock();
},"A").start();
new Thread(()->{
spinLockDemo.lock();
spinLockDemo.unLock();
},"B").start();
}
}
A先执行,执行之后B再执行
但是B没办法结束,必须等到A结束才能结束
A --come in
B --come in
A task over
B task over
CAS缺点
- 循环时间长(消耗多)
- ABA问题(时间戳+版本号)
结束时间:2022-09-13















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









