







数据爬取常用方法_01 利用pandas库中的read_html抓取网页中的表格信息
01 爬取对象
我们经常会需要爬取网页中的表格数据来进行进一步的分析,通过“右键-检查”这些表格对象后会发现他们都是table类型的表格数据。
针对这类< table >表格数据,pandas库为我们提供了一种简便准确的爬取工具——read_html方法
爬取条件:
①网页是静态网站
②是table表格数据
02 爬取过程
下面用2021福布斯全球富豪榜为例,感受该方法的便利:
#2021福布斯全球富豪榜数据:https://www.forbeschina.com/lists/1757
import pandas as pd
url = 'https://www.forbeschina.com/lists/1757'
tb = pd.read_html(url)
tb

该函数直接将table以list的形式返回。
03 read_html() 详解
先参考api文档
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, tupleize_cols=None, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
其中:
io:str, path object or file-like object;
match:str或正则表达式,匹配模式
flavor:解析器
header:标题行
attrs:属性,This is a dictionary of attributes that you can pass to use to identify the table in the HTML. 如:attrs = {‘id’: ‘table’} is a valid attribute dictionary because the ‘id’ HTML tag attribute is a valid HTML attribute for any HTML tag as per this document.
Returns: list of DataFrames
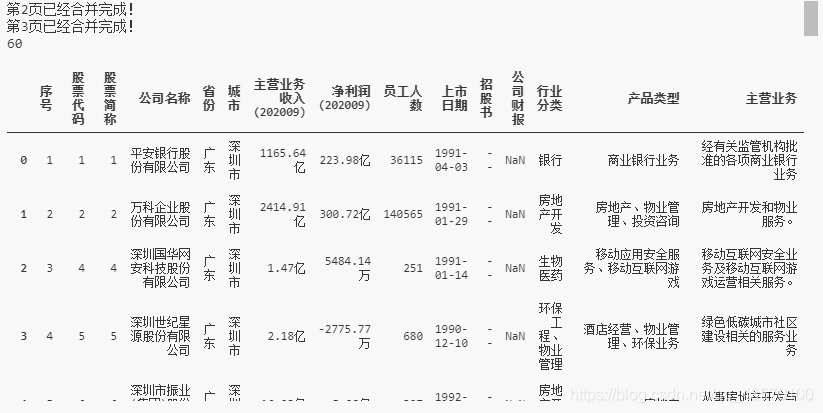
04 爬取多页数据
# 爬取A股市场的多页数据 https://s.askci.com/stock/a
import pandas as pd
url = 'https://s.askci.com/stock/a/0-0?reportTime=2020-09-30&pageNum=1'
tb = pd.read_html(url)[3]
for i in range(2,4):
url='https://s.askci.com/stock/a/0-0?reportTime=2020-09-30&pageNum=%s' % (str(i))
tb = pd.concat([tb,pd.read_html(url)[3]]) #将爬取到的三个表合并为一个表
print("第"+str(i)+"已经合并完成!")
tb = tb.reset_index(drop=True) #重设index
print(len(tb))
tb
输出:














 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









