






JAVA集合
文章目录
- JAVA集合
- 一.List
- (一)Arraylist
- **ArrayList为什么不安全?**
- **让他安全**
- **Arraylist扩容:**
- (二)Linkedlist
- (三)Vector
- (四)区别
- **Arraylist 与 LinkedList 异同:**
- **ArrayList和vertor区别:**
- 二.Map
- (一)HashMap
- **jdk1.7和1.8的区别:**
- **解决hash冲突的办法,hashmap用的哪种**
- **扩容resize:**
- **什么时候扩容**
- **hashmap put()方法:**
- **hashmap get()方法:**
- **负载因子:**
- **为什么hashmap的数组长度一定是2的次幂?**
- **重写equals方法需要同时重写hashcode方法么?**
- **为什么在解决hash冲突时不直接用红黑树,而是先用链表再转红黑树?**
- **hashmap中key的存储索引是怎么计算的**
- **一般用什么作为hashmap的key**
- **hashmap为什么线程不安全**
- **hashset和hashmap区别**
- (二)HashTable
- **hashmap和hashtable的区别:**
- **ConcurrentHashMap和HashTable哪个效率高**
- **HashTable的锁机制**
- (三)ConcurrentHashMap
- **jdk1.7和1.8区别:**
- **ConcurrentHashMap put()方法:**
- **ConcurrentHashMap get()方法:**
- **Concurrenthashmap的get为什么不加锁**
- **get方法不加锁与volatile修饰的哈希桶有关系么**
- **ConcurrentHashMap不支持key或value为空的原因**
- **ConcurrentHashMap的并发度**
- **JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock:**
- **扩容**: transfer
- **多线程下操作的操作map**
- **集合框架**
一.List
(一)Arraylist
Arraylist底层是Object数组实现的,Arraylist是一个可改变大小的数组,查询快(可以直接通过数组下标访问指定位置),增删慢,线程不安全,效率高,可以存储重复元素,允许元素为Null.
ArrayList为什么不安全?
情况一:
在调用add方法时,做了两步操作
* 1.判断列表的capacity容量是否足够,是否需要扩容
* 2.真正将元素放在列表的元素数组里面
多线程情况下
(1)列表大小为9,即size=9
(2)线程A开始进入add方法,这时它获取到size的值为9,调用ensureCapacityInternal方法进行容量判断。
(3)线程B此时也进入add方法,它获取到size的值也为9,也开始调用ensureCapacityInternal方法。
(4)线程A发现需求大小为10,而elementData的大小就为10,可以容纳。于是它不再扩容,返回。
(5)线程B也发现需求大小为10,也可以容纳,返回。
(6)线程A开始进行设置值操作, elementData[size++] = e 操作。此时size变为10。
(7)线程B也开始进行设置值操作,它尝试设置elementData[10] = e,而elementData没有进行过扩容,它的下标最大为9。于是此时会报出一个数组越界的异常ArrayIndexOutOfBoundsException.

情况二:
还有elementData[size++] = e 设置值的操作同样会导致线程不安全。这步操作也不是一个原子操作,它由如下两步操作构成:
elementData[size] = e;
size = size + 1;
在单线程执行这两条代码时没有任何问题,但是当多线程环境下执行时,可能就会发生一个线程的值覆盖另一个线程添加的值,具体:
列表大小为0,即size=0
线程A开始添加一个元素,值为A。此时它执行第一条操作,将A放在了elementData下标为0的位置上。
接着线程B刚好也要开始添加一个值为B的元素,且走到了第一步操作。此时线程B获取到size的值依然为0,于是它将B也放在了elementData下标为0的位置上。
线程A开始将size的值增加为1
线程B开始将size的值增加为2
这样线程AB执行完毕后,理想中情况为size为2,elementData下标0的位置为A,下标1的位置为B。而实际情况变成了size为2,elementData下标为0的位置变成了B,下标1的位置上什么都没有。并且后续除非使用set方法修改此位置的值,否则将一直为null,因为size为2,添加元素时会从下标为2的位置上开始。
让他安全
1.syn关键字
在方法上+:public syn void methon(){}
对象上+:new syn Arraylist()
2.使用Collections.synList()方法
生成一个静态内部类,包装list原有的方法并加锁控制
Arraylist扩容:
加入arraylist创建的时候没初始化长度,第一次调用add的时候是10
1.调用add方法添加元素
elementData=10
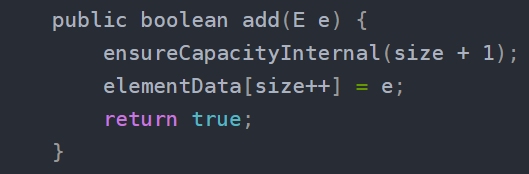
2.在ArrayList类中定义的一个空数组,当elementData的地址和这个空数组的地址相同时,说明还没开始进行扩容,这个时候会在默认容量和这次扩容最小需要的容量(minCapacity)中取出一个最大值,如果进行过扩容,那么直接返回这次扩容最小需要的容量(minCapacity)。

此时minCapacity=11
3.如果这次扩容最小需要的容量比elementData的内存空间要大,进行扩容,调用grow方法

4.
(1)获取原集合长度
(2)集合长度扩容为原长度的1.5倍
(3)if判断,如果扩容后的容量(new capacity)小于扩容最小需要的容量(min capacity),那么 new capacity=min capacity
比如扩容后是15,但是扩容最小需要的容量是16,那就让把16赋值给15
(4)if判断,如果扩容后的容量大于默认的最大值,就需要检查是否溢出,防止OOM。
(5)调用Arrays.copyOf方法将elementData数组指向扩容后的newCapacity的内存空间。

min capacity 这次扩容最小需要的容量
old capacity 扩容前原始数组容量
newCapacity = oldCapacity + (oldCapacity >> 1) 是预计要扩容到的容量
(二)Linkedlist
Linkedlist底层使用双向链表实现的 (JDK1.6之前为双向循环链表,JDK1.7取消了循环 ,这样做的优点就是:1.first / last有更清晰的链头、链尾概念,代码看起来更容易明白。2、 first / last方式能节省new一个headerEntry。3、 在链头/尾进行插入/删除操作,first /last方式更加快捷。), 查询慢,增删快(可以通过修改链表的指针来增删,其实是Node节点),线程不安全,效率高,可以存储重复数据,允许元素为Null.
实现了Cloneable 接口,可以调用Object.clone()方法,如果没有实现Cloneable接口的实例上调用Obejct.clone()方法,会抛出CloneNotSupportException异常。
实现jSerializable接口,所以LinkedList支持序列化,能通过序列化去传输。
(三)Vector
Vector底层使用Object数组实现的,Vector是线程安全的(加入了syn同步锁),查询快(数组下标),增删慢,效率低(因为用到了syn,一个线程工作,其他线程就要等待锁释放,所以效率低),可以存储重复元素,允许值为Null。
Vector扩容:
为什么要成倍的扩容而不是一次增加一个固定大小的容量呢?
采用成倍方式扩容,可以保证常数的时间复杂度,而增加指定大小的容量只能达到O(n)的时间复杂度,因此,使用成倍的方式扩容。
为什么是以两倍的方式扩容而不是三倍四倍,或者其他方式呢?
为了防止申请内存的浪费,更好的实现对内存的重复利用。
(四)区别
Arraylist 与 LinkedList 异同:
相同点:
- ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
2.LinkedeList和ArrayList都实现了List接口(Linkedlist还实现了Queue接口)
不同点:
1. 底层数据结构:
Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构
2. 插入和删除是否受元素位置的影响:
① ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 (比如:执行 add(E e) 方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话( add(int index, E element) )时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 )
② LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)。
3. 是否支持快速随机访问:
LinkedList 不支持高效的随机元素访问,而 ArrayList 支持,因为ArrayList实现了RandomAccess接口。快速随机访问就是通过元素的序号快速获取元素对象(对应于 get(int index) 方法)
4. 内存空间占用:
ArrayList的空间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
ArrayList和vertor区别:

二.Map
(一)HashMap
hashmap是线程不安全的,可以存储空的key和value,在排序上是无序的,在构造hash表时,如果不指明初始化大小,默认就是16
jdk1.7和1.8的区别:
jdk1.7中,hashmap是由数组+链表组成,数组是hashmap的主体,链表主要是为了解决哈希冲突的。
jdk1.8中,hashmap是由数组+链表+红黑树组成的,当链表过长,会严重影响hashmap的性能,红黑树搜索的时间复杂度是O(logn),链表是O(N),当链表长度>8且数据总量超过64才会转成红黑树,jdk1.7 用的是头插法,jdk1.8 用的是尾插法,当采用头插法时会容易出现逆序,环形链表死循环的情况,1.8的尾插法避免了这种情况;
解决hash冲突的办法,hashmap用的哪种

扩容resize:
1.7
当put元素的时候,发现当前元素个数大于等于阈值,并且要存放值的位置已经有元素了,执行resize()
//传入新的容量
//引用扩容前的Entry数组
//如果扩容前的数组大小>=默认最大值,直接返回扩容前的数组大小
//初始化一个新的Entry数组
//将数据转移到新的Entry数组里
//修改阈值
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
//遍历旧的Entry数组
//取得旧Entry数组的每个元素
//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
//1.7重新计算每个元素在数组中的位置
//把元素放到对应的位置
1.8
获取原哈希表容量 如果哈希表为空则容量为0 ,否则为原哈希表长度
如果原容量大于 0
判断原容量是否大于等于HashMap允许的容量最大值
如果原容量已经大于等于了允许的最大容量,
那就把当前HashMap的阈值设置为Integer允许的最大值
然后将容量扩大为原来的2倍,阈值也变为2倍
如果 原数组容量小于等于零
* 并且 阈值大于0 则
* 新数组容量为原数组的阈值
如果原数组容量小于等于0
* 并且阈值也小于等于0
* 新数组容量为默认初始化容量16,阈值12
如果老的哈希表不为空
(后面还有,后续补上)
什么时候扩容
(1)当hashmap中的元素个数>数组大小×负载因子并且存放新值发生hash碰撞的时候就要扩容
(2)当某个桶中的链表长度达到8进行链表扭转为红黑树的时候,会检查总桶数是否小于64,如果总桶数小于64也会进行扩容;
(3)当new完HashMap之后,第一次往HashMap进行put操作的时候,首先会进行扩容。
hashmap put()方法:
(1)根据key计算hash值,找到该元素在数组中存储的下标
(2)如果数组是空的,就调用resize()进行初始化 16
(3)如果没有hash冲突,直接放在对应的数组下标的位置
(4)如果这个索引位置处对应的元素不为空,就判断这两个元素是否相等(equals和hashcode),相同的话就直接覆盖
(5)不同的话说明发生了hash冲突,如果冲突后是链表,判断链表长度是否>8,如果>8并且数组容量<64,就进行扩容;如果>8并且数组容量>64,转成红黑树;如果链表<8,直接插入。
hashmap get()方法:
先求出这个key的hash值
然后求出这个key对应的桶号 hash%length
确定了在哪个桶之后,如果桶容量为0或者该桶内没有元素,直接返回空
如果桶内有元素的话就判断桶中的第一个元素和要取的key是否相等
相等的话就取出
不相等的话就判断该节点是否为树节点,是的话就遍历整个树,不是的话就说明是链表,遍历整个链表
负载因子:
负载因子就是表示Hash表中元素的填满程度。
0.75是对空间和时间效率的一个平衡的选择,除非在时间和空间比较特殊的情况下:
如果内存空间很多并且对时间效率要求很高,可以降低负载因子的值
如果内存空间不足,对时间效率要求的不高,可以增加负载因子的值
当他是0.75的时候对时间和空间的成本提供了一个相对折中的效果,较高会降低空间开销,但提高查找成本(体现在get put的时候)
为什么hashmap的数组长度一定是2的次幂?
只有hashmap的数组长度是2的次幂时,hash%length和hash&length-1的值才相等,为了提高运行效率所以用&运算
重写equals方法需要同时重写hashcode方法么?
需要,如果两个对象的 hashCode()相同, 但equals()不一定相同。
hashCode()返回该对象的哈希码值;equals()返回两个对象是否相等。
如果两个对象equals()相等,那么两个对象的hashCode()方法返回的结果也必然相等。如果重写equals()方法,必须重写hashCode()方法,以保证equals方法相等时两个对象hashcode返回相同的值。
为什么在解决hash冲突时不直接用红黑树,而是先用链表再转红黑树?
红黑树需要左旋,右旋,变色这些操作来保持平衡,而单链表不需要。当元素小于8个的时候,此时做查询操作,链表结果就已经可以保证查询的性能了,当元素>8个的时候,红黑树搜索的时间复杂度是O(logN),链表是O(n),此时需要红黑树来加快查询速度,但是新增节点的速度就会变慢(logN,链表是1),如果一开始就用红黑树,元素少,新增效率还慢,浪费性能。
hashmap中key的存储索引是怎么计算的
(1)取key的hashcode值
h=key.hashcode()
(2)根据hashcode计算出hash值
hash=h^(h>>>16) 高位运算
(3)通过取模计算下标
(n-1)&hash n为长度
一般用什么作为hashmap的key
一般用Integer String这种不可变的类当hashmap的key,String比较常用
(1)字符串是不可变的,在创建的时候hashcode就被缓存了,不需要重新计算
(2)get元素的时候经常要用到hashcode和equals方法,需要正确的重写这两个方法
hashmap为什么线程不安全
1.jdk1.7头插法,多线程情况下导致死循环
2.多线程同时执行 put 操作,如果计算出来的索引位置是相同的,线程A,B都会在这个位置进行put,具体逻辑是通过hash值计算元素在hash表中的位置,并将这个位置上的元素赋值个p,如果是空的,则new一个新的node放在这个位置上,线程A判断如果是空的做了一次赋值操作,线程B也判断是空的,也做了一次赋值操作,就会导致前一个key被后一个key覆盖,从而导致元素的丢失。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
3.put和get并发操时,可能导致get为null
当线程1put元素的时候,发现超过阈值了,需要进行resize操作
resize的过程有一步操作是:用新计算的容量new了一个新的hash表,然后将新创建的空hash表赋值给实例变量table。(后面就是rehash的过程了)
这个时候线程2执行get操作,就会出现get为null的情况
hashset和hashmap区别


(二)HashTable
底层数据结构是数组+链表,hashtable是线程安全的,因为加入了syn关键字,保证了线程的安全,hashtable是不可以放入空值的。hashtable的默认容量是11,负载因子是0.75
hashmap和hashtable的区别:
hashmap不是线程安全的,但是他的效率比hashtable高,因为hashtable用到了syn关键字实现线程安全,hashmap是可以存放空值的,但hashtable不可以存放空值,hashtable的映射不是有序的,hashmap的默认容量是16,hashtable默认容量是11,hashtable直接使用对象的hashcode,hashmap需要重新计算hash值。
扩容:
扩容为原来长度的2倍+1
ConcurrentHashMap和HashTable哪个效率高

HashTable的锁机制

(三)ConcurrentHashMap
主要是为了解决hashmap线程不安全的问题,不允许存储空值的,否则会抛出异常。默认容量是16
jdk1.7中的ConcurrentHashMap是由segment数组和链表(hashentry)组成的,把哈希桶分成了小数组,每个小数组下又有很多个链表组成,segment继承了ReentrantLock,所以segment可以当做锁,链表用来存储键值对。1.7是将数据分为一段一段的存储,然后给每段数据配把锁,当一个线程占用锁访问其中一段数据的时候,其他段的数据也能被其他线程访问
jdk1.8中的ConcurrentHashMap是由数组+链表+红黑树组成的,链表长度>8转红黑树,在锁的实现上,采用CAS+syn来加锁,降低了锁的粒度,只需要锁住这个链表的头节点(红黑树的头节点),不会影响其他哈希桶的读写,提高并发度。
jdk1.7和1.8区别:

ConcurrentHashMap put()方法:
(1)先判断key value 是否为null,为null就直接返回,因为con不允许存空值
(2)得到hash值
int hash = spread(key.hashCode());
(3)if判断,如果桶为空,或者长度为0,进行初始化
(4)else if 不为空进入自旋,计算元素的索引位置
(5)如果该位置没有元素,通过CAS把元素插入
(6)如果为moved,就是协助扩容
(7)如果以上条件都不满足,说明存在hash冲突,那就要进行加锁操作,锁住链表头结点
(8)然后遍历链表,元素相等就覆盖,不等就插入到链表尾部
如果链表长度>8就转成红黑树
ConcurrentHashMap get()方法:
1.计算hash值,定位到该索引位置,如果是首节点符合就直接返回
2.如果不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
Concurrenthashmap的get为什么不加锁
get方法不需要加锁,因为Node的元素val和指针next是用volatile修饰的,多线程情况下,线程A修改节点的值或者新增节点的时候,对线程B是可见的

get方法不加锁与volatile修饰的哈希桶有关系么

ConcurrentHashMap不支持key或value为空的原因
ConcurrentHashMap是用于多线程的,如果map.get(key)=null,没办法判断是value映射的是null,还是没有找到对应的key而返回null。
用于单线程的hashmap可以用containsKey(key)方法来判断是否包含了这个null,包含true 不包含false。
假设ConcurrentHashMap允许存空的key value,线程A调用map.get(key)=null,没办法判断是value映射的是null,还是没有找到对应的key而返回null,假设我知道返回null的原因是没找到对应的key,然后用containsKey(key)方法验证,期望的结果应该是false,但是在调用containsKey(key)之前,线程B做了一个put操作,在验证的时候返回的结果就是true了
ConcurrentHashMap的并发度

JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock:
1.因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
2.JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
3.在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
ConcurrentHashMap 主要使用的是 CAS+自旋+synchronized+多重check 来保证在初始化,新增,和扩容的时候线程安全,读取数据的时候则使用了 volatitle 让元素节点 在多线程之间 可见,从而达到获取最新的值!
扩容: transfer
在新增原数后 判断是否达到临界值 如果达到 就进行扩容 都是2倍的扩容原大小
1.首先从原数组的队尾开始进行拷贝
2.拷贝数组的时候 会把原数组的槽点的锁住使用的是synchronized,这样 原数组里面的数据就没法被修改,保证了线程安全,成功拷贝到新数组后,把原数组的槽点设置为转移节点move。
3.如果这个时候有数据的put 当前槽点状态是转移节点也就是move,就会一直等待
4.直到原数组所有的节点被复制到新数组里面,然后再把新数组赋值给数组容器,完成拷贝
总结一下,在数组扩容的时候,主要是利用Synchronized锁去锁住槽点,不让别的线程去操作,槽点复制成功后,会标识为转移节点,这样新的put操作过来,看的槽点状态是move,就会一直等待扩容完成后才会再进行put操作。
多线程下操作的操作map


集合框架


















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









