







1、地址翻译概述
1. 地址翻译的流程
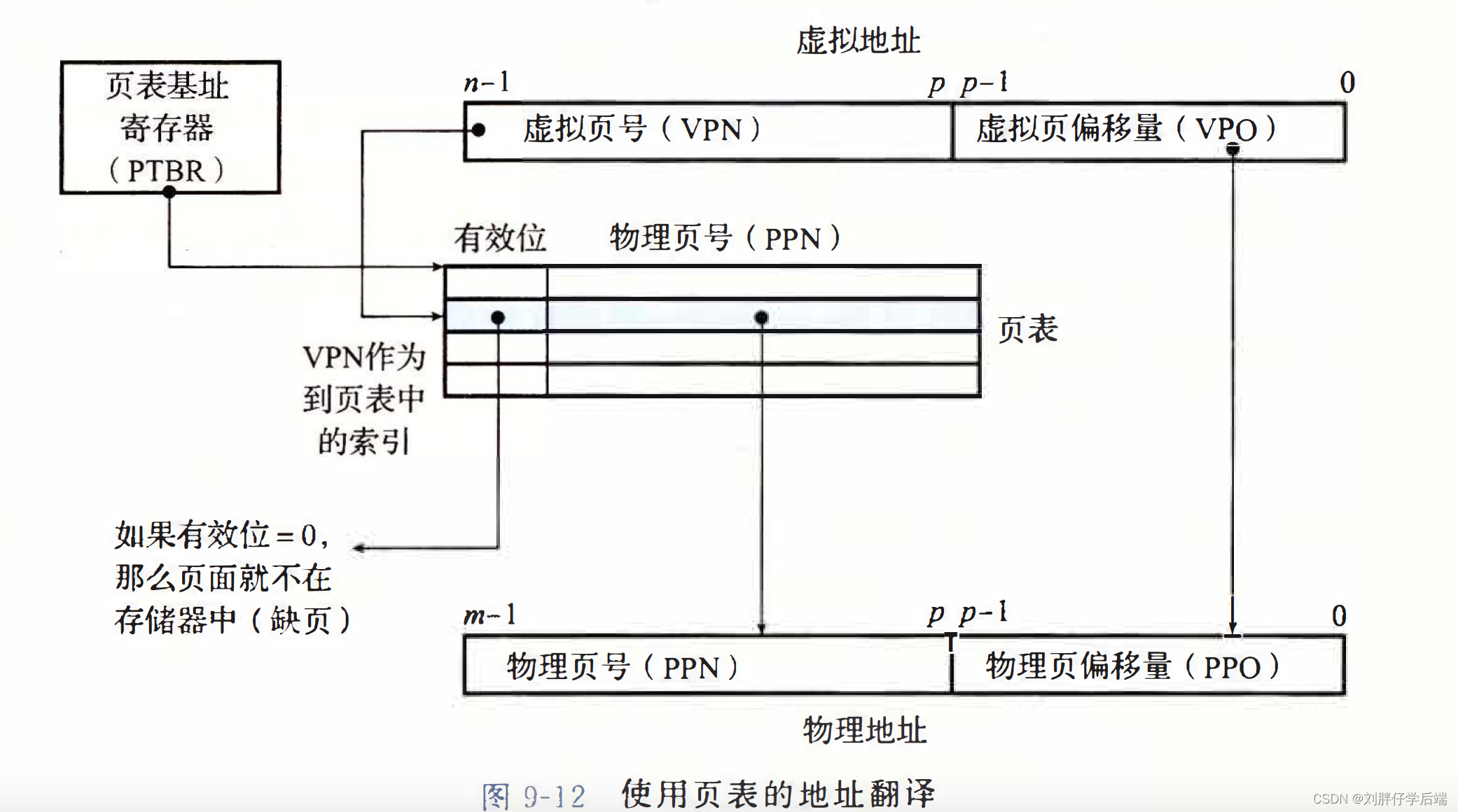
上图简述了利用页表进行地址翻译的大致过程。
首先CPU中的一个控制寄存器——页表基址寄存器(PTBR)指向当前页表。
CPU传来的n位虚拟地址被分成了两个部分,一个n-p位的虚拟页号和一个p位的虚拟页面偏移。
虚拟页号用来作为到页表中的索引,与PTBR结合可以找到具体的PTE。将PTE中存储的物理页号和虚拟地址中的虚拟页面偏移结合起来,就得到相应地物理地址。由于物理和虚拟页面的大小是相同的,所以物理页面偏移和虚拟页面偏移也是相同的。
2. 从硬件角度看地址翻译
1. 页面命中
- CPU向MMU发送一个虚拟地址
- MMU生成PTEA,也就是所需PTE的地址,并向内存请求PTE
- 内存向MMU返回PTE
- MMU组装物理内存地址,向内存请求数据
- 页面命中,内存返回所请求的数据
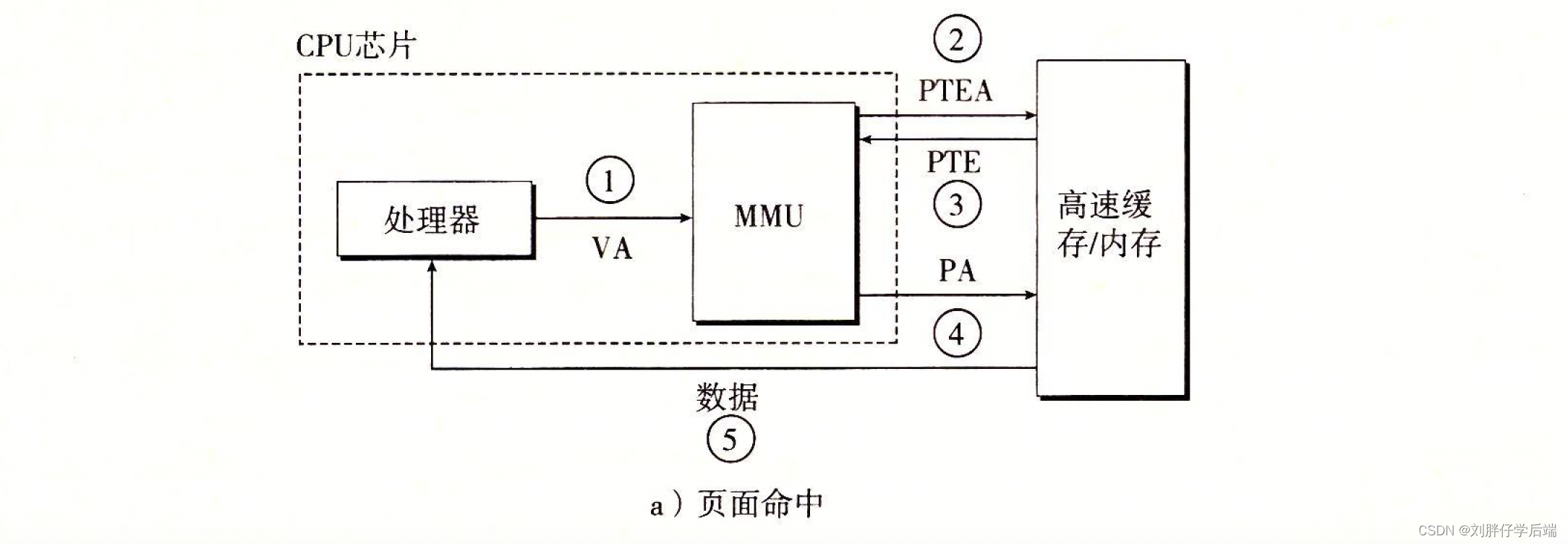
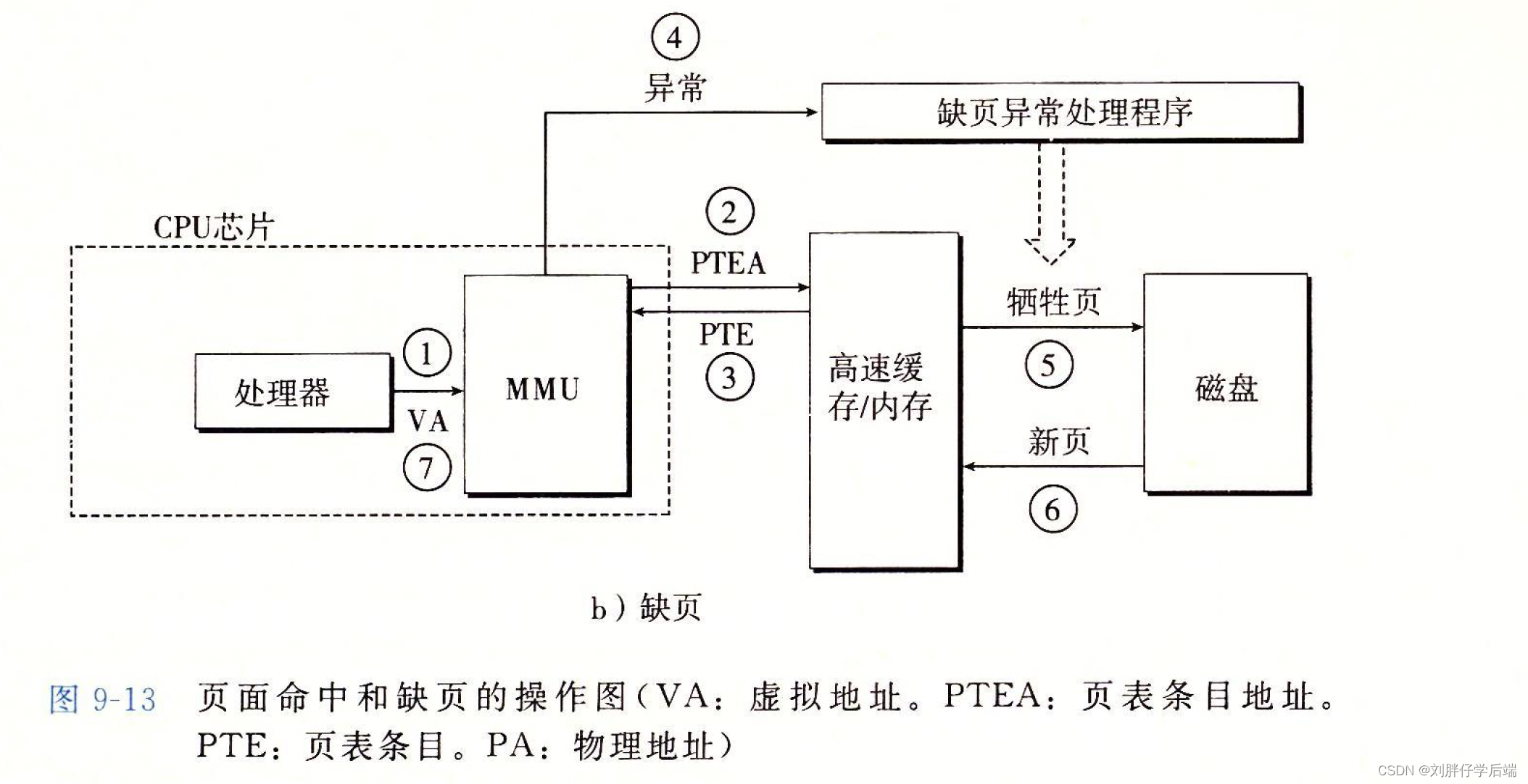
2. 缺页
- CPU向MMU发送一个虚拟地址
- MMU生成PTEA,也就是所需PTE的地址,并向内存请求PTE
- 内存向MMU返回PTE
- MMU发现,发过来的PTE的有效位是0,立即触发缺页异常。将CPU的控制传递给内核的缺页处理程序
- 缺页处理程序选出合适的牺牲页,如果他被修改过,则将其存入磁盘。
- 缺页处理程序将新页从磁盘中换进内存中,并更换PTE的条目。
- 缺页处理程序返回到原来的进程,再次执行导致缺页的指令,这次就会正常的获得数据了。
2、结合高速缓存和虚拟内存
其核心在于,到底是使用物理地址寻址高速缓存还是使用虚拟地址寻址高速缓存。大多数系统使用的是物理地址。其优势在于:
- 使用物理寻址,多个进程同时在高速缓存中有存储块和共享来自相同虚拟页面的块成为很简单的事情
- 高速缓存无需处理保护问题, 因为访问权限的检查是地址翻译过程的一部分
最终的方案会如图所示,虚拟地址的翻译会在查找高速缓存之前进行。
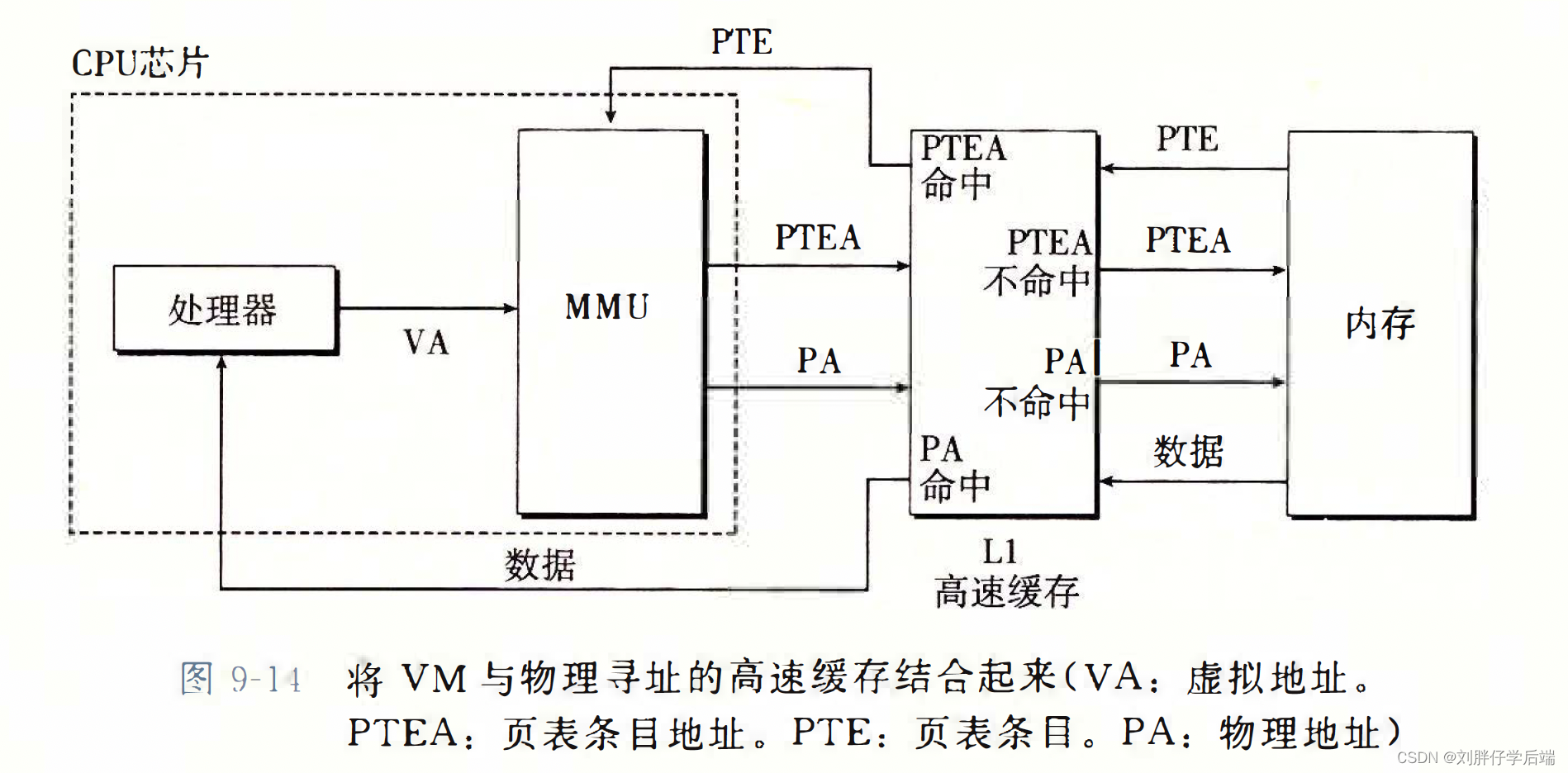
处理器将虚拟地址发送到MMU,MMU获得PTEA之后向L1缓存请求该地址PTE,如果没有命中,就会从内存中获取。如果命中了就直接返回。后面的事情跟前面类似。
3、利用TLB加速地址翻译
我们看到每次进行地址翻译的时候,MMU总是要向不管是L1缓存还是内存查询PTE。许多系统试图消除掉这样的开销。在MMU中包括了一个关于PTE的小的缓存,称为翻译后备缓冲器(Translation Lookside Buffer,TLB)
高速缓存介绍

TLB是一个小的、虚拟寻址的缓存中每一行都保存着一个由单个PTE 组成的块。
用于组选择和行匹配的索引和标记字段是从虚拟页号中提取的。如果TLB有T=
2
t
2^t
2t个组,那么TLB索引(TLBI)是由VPN的t个最低位组成的,而TLB标记(TLBT)是由VPN中剩余的位组成的。
那么翻译的过程就会如下
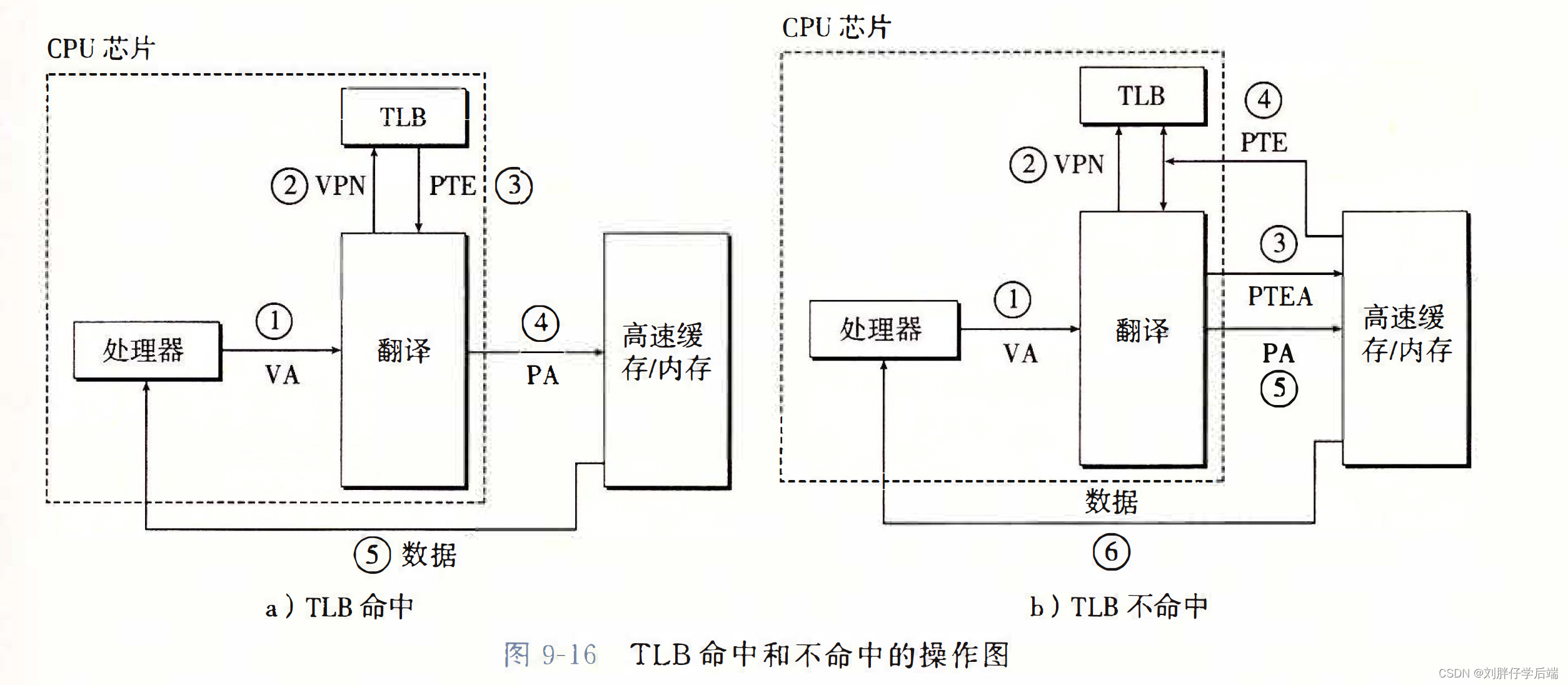
对于CPU传来的VA,MMU从TLB中得到PTE,直接组装成PA,获取数据。如果TLB不命中,则从高速缓存或者内存中获得PTE,同时覆盖一个已有的条目。从而可以继续下去。
4、多级页表
1. 多级页表的组织
对于一个有着32位地址空间、4KB的页面和一个4字节的PTE来说,即使应用程序引用的只是虚拟地址空间的很小一部分地址,也总是要在内存中存储一个4M的页表。压缩页表的常用方式就是使用多级页表。
对于一个如下图所示的虚拟内存,我们按照两级的页表结构可以这样组织。
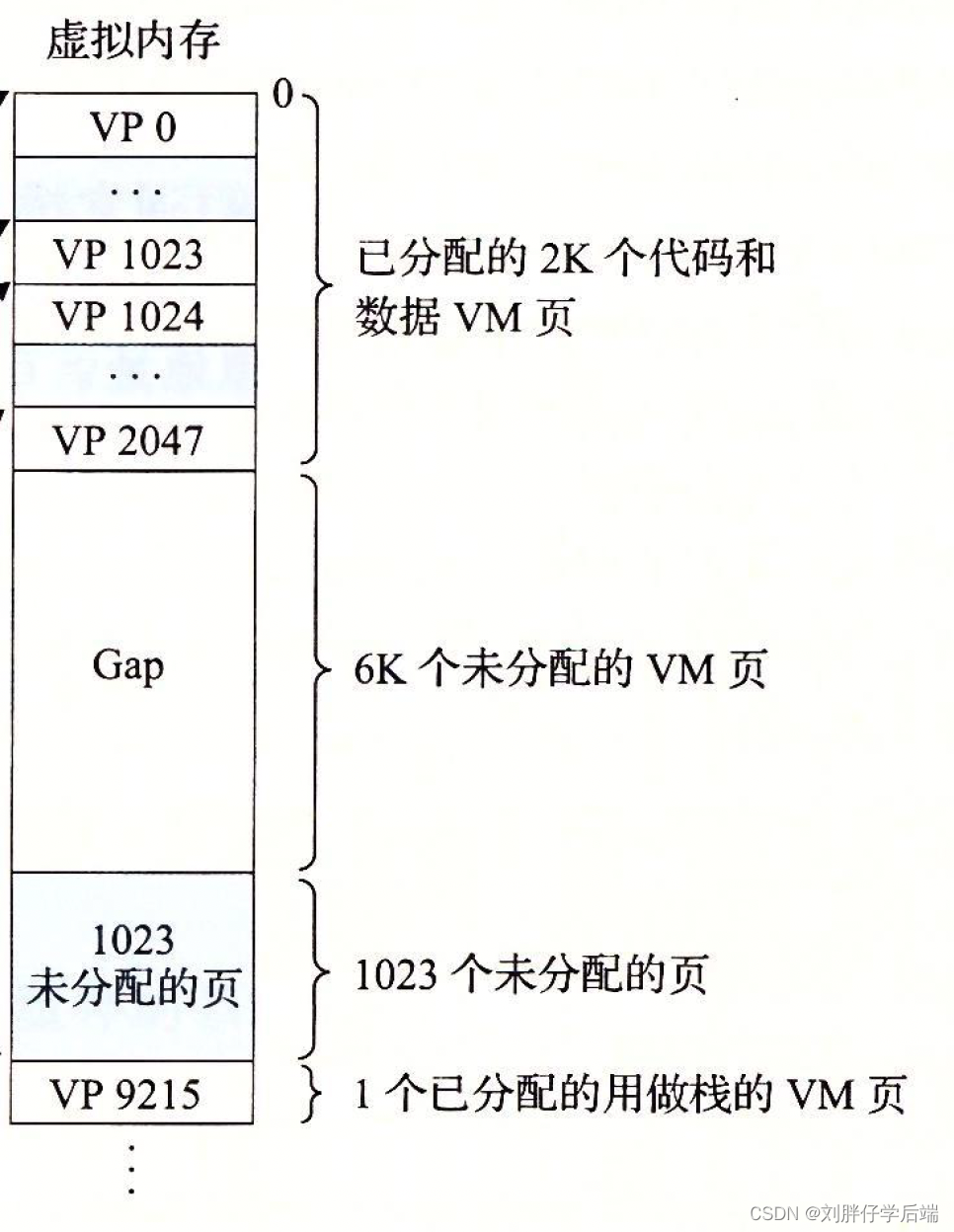
一级页表中的每个PTE指向一个包含1K个PTE的二级页表(一个二级页表也是4K大小),而每个二级页表的PTE跟我们原来谈论的页表一样,表示一个虚拟地址和其物理地址之间的关系。
这样一来,每个一级页表就指向了一个1k * 4K = 4M大小的片,那么只需要1k个PTE就可以指向整个地址空间。
如下图所示。
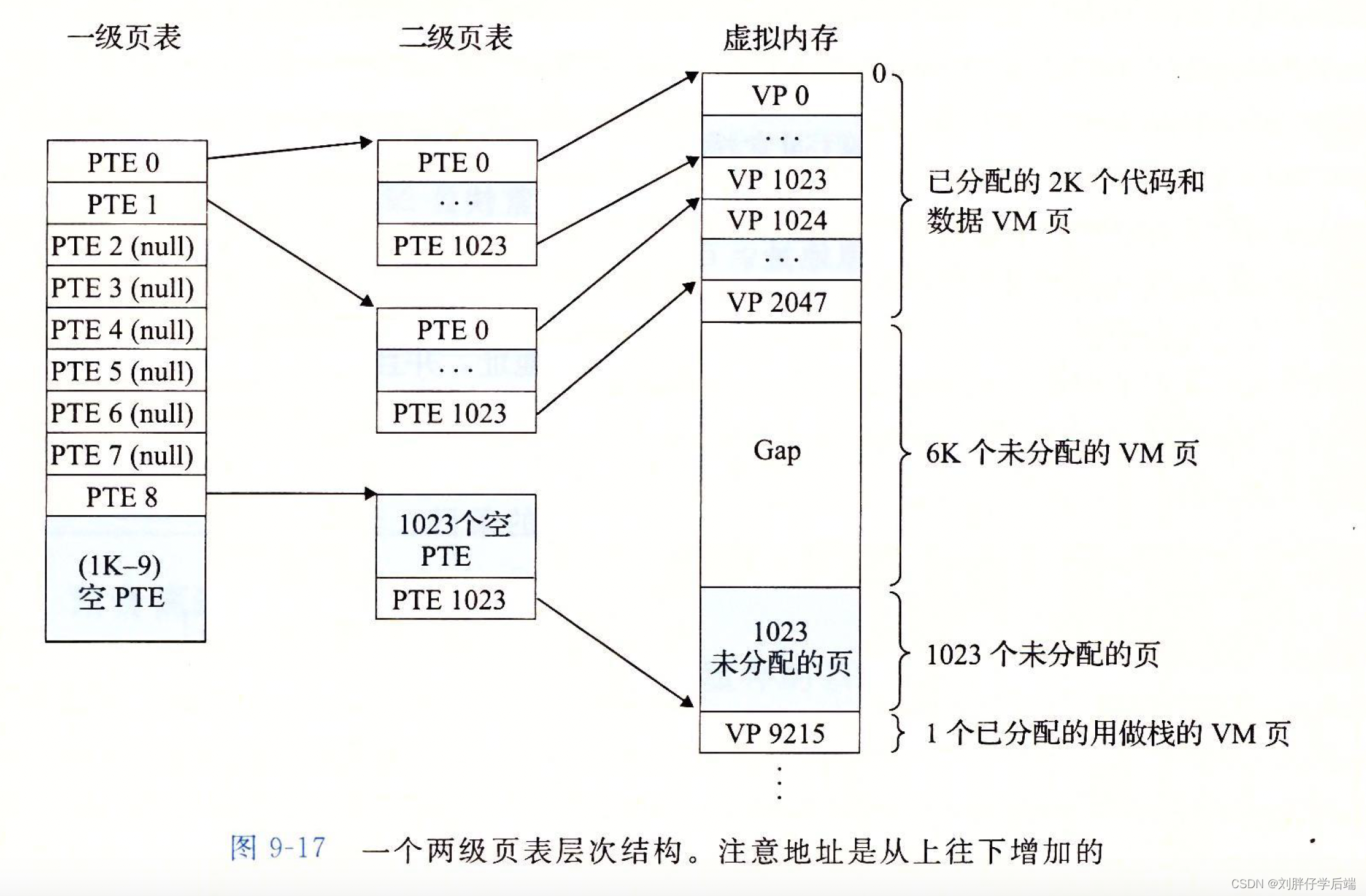
如果片1中的每个页面都未被分配, 那么一级PTEi就为空。
2. 使用多级页表的内存优势
- 如果PTEi是空的,那么相应的二级页表就无需存在。因为对于一个进程和4G的虚拟地址空间来说,可能大部分情况下大部分的虚拟页面都是未分配的。
- 只有一级页表才是需要常驻内存中的,其余的页表可以跟普通的页面一样在需要时创建、调入内存。这就减小了主存的压力。
3. k级页表层次结构
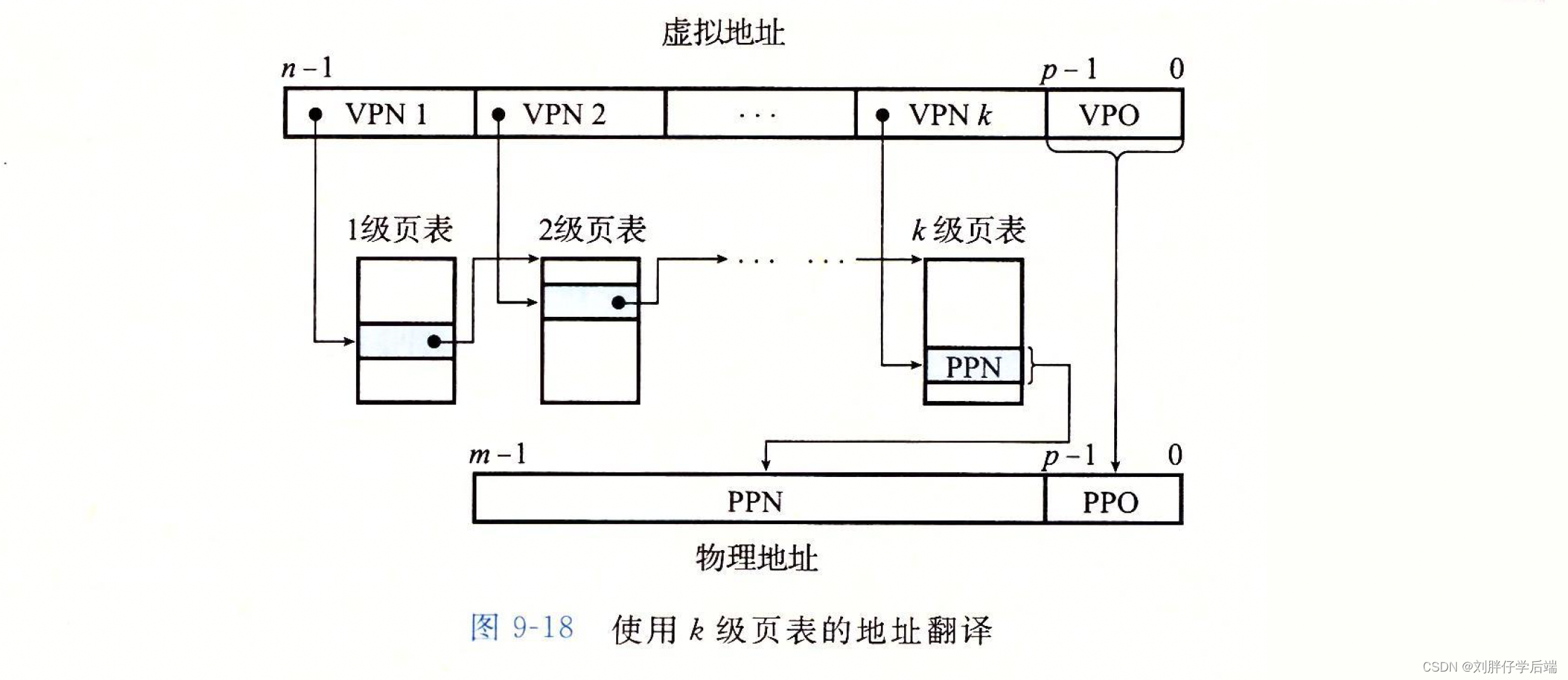
我们看到VPN被分割成了k部分,每个VPNi都是在第i级页表的索引,第i级页表的PTE存储的是第i+1级某个页表的基址。第k级页表的PTE包含某个物理页面的PPN或者指向一个磁盘块的地址。
而在访问得到PPN之前,MMU需要得到k次PTE,此时就看出TLB的巨大作用了。

















 1130
1130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









