







 本文详细介绍了Pandas DataFrame的基础操作,包括创建、增加、删除、修改和查询数据,以及形状查看、排序、统计计算等功能。此外,还讲解了如何读取和保存CSV文件,以及如何利用apply函数进行数据处理。
本文详细介绍了Pandas DataFrame的基础操作,包括创建、增加、删除、修改和查询数据,以及形状查看、排序、统计计算等功能。此外,还讲解了如何读取和保存CSV文件,以及如何利用apply函数进行数据处理。
基本的操作
Dataframe介绍:
DataFrame是一种数据结构,它类似于一个二维数组,它与二维数组的不同在于它的内部数据不仅限于数值,还可以是其他的数据类型(布尔型,字符串等),它还在二维数组的基础上增加了行索引和列索引。pandas中的Dataframe对象的基本操作有很多,我这里只总结了一些常用的。
创建方式
创建方式常用的有两种,用多维数组和字典,用数组创建的时候要给出列索引属性(columns)和行索引属性(index)的值,如果不给出默认索引以0开始依次递增,字典创建的时候,字典的键是列索引属性值,行索引属性值若不给出也是默认的以0递增。具体的见下面代码。
import pandas as pd
import numpy as np
arr1 = np.array([[1,2,3],[4,5,6]])
pd1 = pd.DataFrame(arr1)
pd2 = pd.DataFrame(arr1,index=['a','b'],columns=['A','B','C']) #以列表创建
dict1 = {'A':[1,4],'B':[2,5],'C':[3,6]}#以字典形式创建
pd3 = pd.DataFrame(dict1,index=['a','b'])
print('pd1=\n',pd1)
print('pd2=\n',pd2)
print('pd3=\n',pd3)
DataFrame对应的基本操作
一种数据结构的基本操作一般包括增删改查和一些特定功能的函数(求和,排序等)。
增加:
这里增加数据的时候要注意DataFrame对象的形状,比如二行三列的数据,增加行数据的时候,数据列表长度应该是3,不然会报错。
arr1 = np.array([[1,2,3],[4,5,6]])
pd2 = pd.DataFrame(arr1,index=['a','b'],columns=['A','B','C']) #以列表创建
#增加行数据
pd2.loc['c'] = [7,8,9]
#增加列数据
pd2['D'] = [10,11,12]
删除:
用drop()这个函数,函数第一个参数是你要删除的行名或者列名,可以是单列或单行,也可以是多列或多行(可以用列表给出),第二个参数axis=1代表前面的索引为列索引,axis=0表示前面的索引为行索引,inplace=True表示在原Dataframe对象的视图上修改,这个参数默认是False,就是需要哪一个变量来接收原Dataframe对象删除某些行或列的结果,但是原Dataframe对象并没有改变。见代码例子:
pd2.drop('c',axis=0,inplace=True) #删除索引为'c'的一行
pd2.drop('A',axis=1,inplace=True) #删除索引为'A'的一列
pd2.drop(['C','B'],axis=1,inplace=True) #删除索引为'B'和'C'的两列
修改:
在修改之前,pd2对象的数据只这样的

对单个元素修改
pd2.loc['a']['B'] = 6 #把a行B列的那个元素改为6
对单列或单行修改,这里也一定要注意列和行的长度
pd2['D'] = [15,16,17] #把D列的元素改为[15,16,17]
pd2.loc['c'] = [15,16,17,18]#把c行的元素改为[15,16,17,18]
修改完之后的数据结构是这样的,可以看出,数据确实被修改了。
查询:查询包括索引和切片
简单的查询:
print(pd2.loc['a']['B']) ##查看a行B列元素的值
print(pd2['B']) #查看B列元素的值
print(pd2.loc['a'])#查看a行元素的值
切片:
学过python的应该对切片都不陌生,切片就是把数据按照自己的要求截取下来,列表元组这些是在一维数据上切片,也就是在一条线上切,而Dataframe就是在二维数据上进行切片,也就是在一个面上进行切。形式是Dataframe.loc[:,:]或Dataframe.iloc[:,:],用逗号把行和列隔开,逗号左侧是对行切片,右侧是对列切片。这里解释一下iloc和loc,iloc就是隐式标签,loc是显示的,就拿我们的例子来讲,pd2是一个列索引为[‘A’,‘B’,‘C’,‘D’],行索引为[‘a’,‘b’,‘c’]的3行4列数据。如果我们想要pd2对象前2行3列的数据,下面这两种方法是等价的,但是都没有对pd2本身改变,只是又拿一个Dataframe对象接收切片后的数据。切片前pd2数据元素与上面修改后的数据一样。
切片取前2行3列:
pd3 = pd2.iloc[:2, :3]
pd4 = pd2.loc[:'b',:'C']
pd3和pd4都是这个:
Dataframe对象的其他操作
查看形状和索引
import numpy as np
import pandas as pd
arr1 = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
pd2 = pd.DataFrame(arr1,index=['a','b','c'],columns=['A','B','C','D']) #以列表创建
print(pd2)
print(pd2.shape) #查看形状
print(pd2.index) #查看行索引
print(pd2.columns) #查看列索引
关于排序
pd2.sort_values("A",inplace=False,ascending=True)
#参数inplace指定是否对原dataframe对象试图上操作,默认为False,如果该值为False,那么原来的顺序没变,只是返回的是排序的,如果为True原来的对象也将改变,其他列也按照排序的顺序改变。
#参数ascending是指定升序排列还是降序排列,默认为True,按照升序排序,为False时,按照降序排序。
对单列或者单行进行操作
print(pd2['A'].mean()) #A列求平均值
print(pd2['A'].std()) #A列求标准差
print(pd2['A'].var()) #A列求方差
print(pd2['A'].max()) #A列求最大值
print(pd2['A'].min()) #A列求最小值
#对行操作只需注意不要忘记loc和对应的行索引名就行了,其他的与列相似
print(pd2.loc['a'].sum()) #a行求和
print(pd2.loc['a'].var()) #a行求方差
对多列和多行操作,假如这里有个问题:让你把某几列的数据每一行求平均值,把结果放到最后一列(包括对行类似的操作)代码如何写呢。
l = ['A','B','C']#指定要操作的列名
l1 = ['a','b','c'] # 指定要操作的行名
pd2['E'] = pd2[l].mean(axis=1)#求指定列的平均值加到最后一列
pd2.loc['d'] = pd2.loc[l1].mean(axis=0)#求指定行的平均值加到最后一行
print(pd2)
与apply()函数结合,假如这里有个任务:让你把某列或者某行的数据都加上2。该如何操作呢?
pd2['F']=pd2['A'].apply(lambda x:x+2) #对A列的数据每个元素都加2,把数据加到F列
pd2.loc['e']=pd2.loc['a'].apply(lambda x:x+2) #对A行的数据每个元素都加2,把数据加到e行
print(pd2)
这里面都要注意,上面的这些Dataframe对象的其他操作都是拿该对象的数据过来用,除了增加列和行以外,原对象本身并没有改变,增加列和行也是为了更加清晰的观看效果,可以复制代码运行观看结果。
文件数据的的载入与存储
Dataframe对象之所以强大是因为它能够与文件交互,能根据你的需求把对文件里的数据进行操作。你对文件的操作一定要知道如何读文件和如何写文件,这里就详细介绍read_csv和to_csv两个函数。
read_csv()函数功能是从文件(.csv,txt类型)读取数据,返回一个Dataframe对象。下面是官网定义的read_csv,参数有很多,这里解释一下几个常用的。
filepath_or_buffer
文件的路径,可以是绝对路径和相对路径
sep=","
读取csv文件时指定的分隔符,默认是逗号,这里要注意,如果你要读取的文件是以空格分隔的,你就要加上这个参数值为空格的字符串(sep= " "),不然文件读取返回的对象后面的几列都是空值。
delimiter=None
分隔符的另一个名字,与 sep 功能相似。
header=“infer”,
names=None,
这两个是设置导入 DataFrame 的列名称
index_col=None,
我们在读取文件之后,若这个为默认参数,生成的DataFrame的索引默认是0 1 2 3…,我们想设置索引,就把这个参数改为自己想要的索引名就行了。
具体的参数解释可以参看一下这个博客,博主写的很详细。read_csv函数详解
介绍完read_csv,在介绍to_csv,这两个函数功能相对,参数其实也差不多,具体的参看下面这个博客。to_csv参数详解
这里有一个四位同学的语数英三科成绩的文件,读取这该文件,把每位同学的三科总分和三科平均值计算出来也保存到另一个文件中。操作前文件的文件,行代表四名同学,三列为语数英三科的成绩。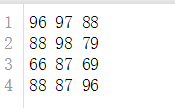
import pandas as pd
name = ['张三','李四','王二','麻子']
chengji = pd.read_csv('test.txt',sep=' ',names = ['数学','语文','英语'])
chengji.index = name
print(chengji)
chengji['总分'] = chengji[['数学','语文','英语']].sum(axis = 1)
chengji['三科平均分'] = chengji[['数学','语文','英语']].mean(axis = 1)
print(chengji)
chengji.to_csv('test1.csv',sep=' ')
操作之后test1文件内容是这样的


















 2427
2427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









