







tokens的编译
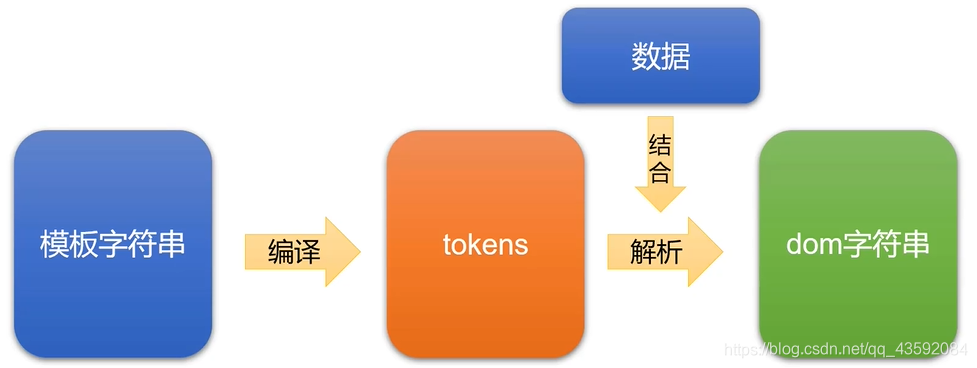
在mustache模板引擎,最为重要的就是tokens了,tokens还是“抽象语法树”、“虚拟DOM”等当今前端很火热的技术的开山鼻祖,那么tokens究竟是何方神圣呢?
tokens其实是一个JS的嵌套数组,能把我们写好的模板字符串转换成一个特殊的数组,然后在这个数组的基础上结合数据对象,最后渲染成dom字符串。
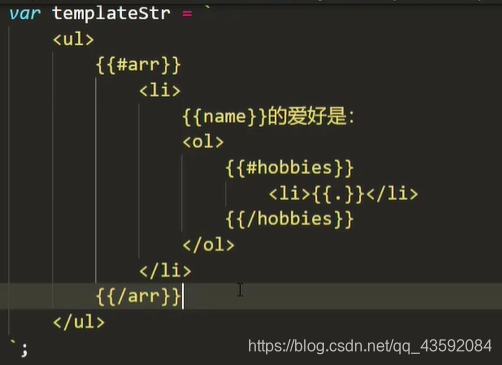
比如对于上面这样的一个模板字符串来说,mustache会先把它转换成下面的tokens:
[
["text", "<div><ol>"],
["#", "students", [
["text", "<li>学生"],
["name", "name"],
["text", "的爱好是<ul>"],
["#", "hobbies", [
["text", "<li>"],
["name", "·"],
["text", "</li>"],
]],
["text", "</ul></li>"],
]],
["text", "</ol></div>"]
]
那么mustache是如何把模板字符串编译成tokens呢?
在mustache官方源码里有一个Scanner类,专门用来扫描传递进来的字符串,该类中提供两个方法scan、scanUtil。
scan的作用:
用于跳过指定内容,没有返回值
scanUtil的作用:
用于扫描字符串,直至遇见指定内容结束,并返回结束前的字符串。
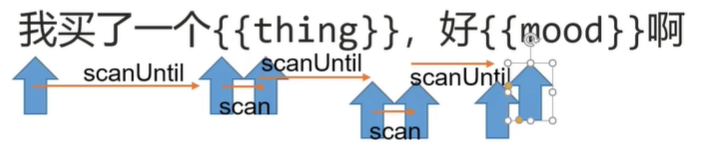
通过交替调用这两个方法,就可以将模板字符串编译成tokens。
#和/的划分
在mustache解析模板字符串时,#和/的语法能实现数组嵌套的展示,由于上面scan和scanUtil方法已经对字符串进行了初步的拆分,现在我们只需要考虑存在#和/的切分数组的问题。
这其中的用到了栈的数据结构。对于Scanner返回的数组一一寻找#和/,在遇到#时进行入栈操作,同时让当前token数组的第三个元素指向一个收集器数组专门用来存储接下来的嵌套元素;在遇到/时执行出栈操作,同时释放最内层的收集器,返回真正的token。
dom字符串的解析
dom字符串解析就是将tokens数组中name项的元素替换为对应的数据,因此只需要遍历查找替换即可。但当遇到嵌套数组时也需要特殊处理,这里用了递归算法实现,当遇到#开头的token时,就重新调用dom解析方法,并将返回值填入原来的tokens数组中。
但是在方法的实际编写中,会遇问题:当模板字符串中出现类似data.arr.num的使用 . 来进行数据定位时,数据的访问往往不认识这种写法,因为js会把地址当做字符串处理,所以我们还需要对数据地址进行专门的处理。
这里创建一个lookup函数专门处理以上的需求:
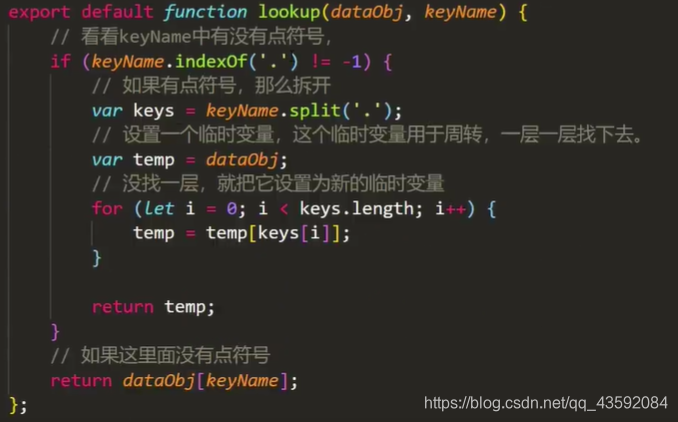
这里接收两个参数,一个是数据对象,另一个就是我们上面所说的数据访问地址(关键字),最后返回模板字符串中需要替换的数据。
完成了上面的工作,我们就可以进行递归算法替换数据了,需要注意的是,此处的递归算法循环次数是由数据决定的,比如传进来的data数组有三项,那么就循环3次自调用。
以上这些实现了dom字符串解析的工作,在mustache中是由Writer类来实现的。
文章参考尚硅谷邵老师教程














 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









