









《数据分析师第二版》学习笔记2020年9月24日更新
第8章 数据规整:聚合、合并和重塑
8.2合并数据集
pandas.merge:可以根据一个或多个键将不同DataFrame中的行连接起来,效果等同于SQL中的join。pandas.concat:可以沿着一条轴将多个对象堆叠到一起;- 实例方法
combine_first可以将重复数据拼接在一起,用一个对象中的值填充另一对象中的缺失值。
数据库风格的DataFrame合并 —— merge
import pandas as pd
df1 = pd.DataFrame({'key':['b','b','a','c','a','a','b'],'data1':range(7)})
df2 = pd.DataFrame({'key':['a','b','d'],'data2':range(3)})
pd.merge(df1,df2,how='left',on='key')
参数说明
- how 默认为inner,可设为inner/outer/left/right
- on 根据某个字段进行连接,必须存在于两个DateFrame中(若未同时存在,则需要分别使用left_on和right_on来设置)
- left_on 左连接,以DataFrame1中用作连接键的列,连接时的列名不同时使用
- right_on 右连接,以DataFrame2中用作连接键的列
- left_index 将DataFrame1行索引用作连接键
- **right_index **将DataFrame2行索引用作连接键
- sort 根据连接键对合并后的数据进行排列,默认为True
- suffixes 对两个数据集中出现的重复列,新数据集中加上后缀_x,_y进行区别
注意:其中以左连为例,假设数据连接为多对多,则遵循笛卡尔积如果左边的DataFrame有3个"b"行,右边的有2 个,所以最终结果中就有6个"b"行。
索引上的合并 —— merge中right_index参数
DataFrame中的连接键位于其索引中。在这种情况下,可以传入 left_index=True或right_index=True(或两个都传)以说明索引应该被用作连接
左数据left,右数据right,通过索引相互连接
import pandas as pd
pd.merge(left,right,how = 'outer',left_index = True,right_index = True) # 通过索引进行全连接
这种写法还有一种更加简便的join写法,其作用是更加方便的使用索引进行连接,但要求没有重叠的列
left.join(right,how = 'outer'# 功能与上面那段代码相同
join连接默认使用左连接。
使用join将三个列连接起来
# 左数据 left1
# 右数据 right1
# 新数据 another
# 外连接三个数据:
left1.join(['left1','another'],how = 'outer')
轴向连接 —— concat
数据合并运算也被称作连接(concatenation)、绑定(binding)或堆叠 (stacking)。NumPy的concatenation函数可以用NumPy数组来做
# 轴向连接,可以通过np的concatenate方法实现
import numpy as np
arr = np.arange(12).reshape(3,4)
np.concatenate([arr,arr],axis = 1)
同样使用DataFrame与Series均可使用Concat进行连接
import pandas as pd
#例1
s1 = pd.Series([0,1],index=['a','b'])
s2 = pd.Series([2,3,4],index=['c','d','e'])
s3 = pd.Series([5,6],index=['f','g'])
pd.concat([s1,s2,s3],axis = 1,join='outer')
s4 = pd.concat([s1,s3])
pd.concat([s1,s4],axis= 1)
#例2
df1 = pd.DataFrame({'key':['b','c'],'data1':range(2)},index=['a','b'])
df2 = pd.DataFrame({'key':['a','d'],'data2':range(2)},index=['c','f'])
another=pd.DataFrame([[7.,8.],[9.,10.],[11.,12.] ,[16.,17.]],index=['a','c','e','f'],columns=['NewYork', 'Oregon'])
pd.merge(another,df1,how='inner',left_index=True,right_index=True) #对比项
pd.concat([df1,df2,another],axis=0 , join= 'outer')
其中axis =1 是X轴连接 默认是axis = 0得纵向连接
concat参数如下:

df3 = pd.DataFrame(np.random.randn(12).reshape(3,4),index=['a','b','c'])
df4 = pd.DataFrame(np.random.randn(6).reshape(2,3),index=['b','d'])
pd.concat([df3,df4],axis=0)
pd.concat([df3,df4],axis=0,ignore_index= True)
# 当ignore_index为True时轴向上的索引会被放弃
合并重叠数据 —— np.where
知识点补充:
np.where()可以进行三目运算:
a=pd.Series([np.nan,2.5,np.nan,3.5,4.5,np.nan],index=['f','e','d','c','b','a'])
b=pd.Series(np.arange(len(a),dtype=np.float64),index=['f','e','d','c','b','a'])
np.where(pd.isnull(a),a,b) # 当满足a中数据为空时输出a,反之输出b
8.3 重塑和轴向旋转
重塑层次化索引
层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的方式。主要功能有二:
- stack:将数据的列旋转为行(转置);*
- unstack:将数据的行旋转为列;
准备数据
data=pd.DataFrame(np.arange(6).reshape((2,3)),index=pd.Index(['Ohio','Colorado'] ,name='state'),columns=pd.Index(['one','two','three'],name='number'))
result = data.stack() # 转置
result.unstack() # 恢复
默认情况下stack操作的是DataFame的最内层即 data[1] 注释:‘data[1]’这种描述不合理,仅作为自己的理解方法
data[0] 索引层
data[1] 数据层
如果要转置外层索引,操作如下:
data=pd.DataFrame(np.arange(6).reshape((2,3)),index=pd.Index(['Ohio','Colorado'] ,name='state'),columns=pd.Index(['one','two','three'],name='number'))
result = data.stack() # 转置
result.unstack(0) # 恢复
以上操作会会将索引名称变为列名,这两个功能对于数据转置操作非常非常重要!!
stack默认会滤除缺失数据,因此该运算是可逆的
将“长格式”旋转为“宽格式”
转换 stack
读取数据
#P281
import pandas as pd
import numpy as np
data = pd.read_csv(r'C:\Users\37242\Desktop\macrodata.csv')
将日期数据从csv文件中提取出来整合成为’YYYYQ1格式
periods = pd.PeriodIndex(year = data.year,quarter = data.quarter,name = 'date')
dataframe.reindex(index = [’’,’’]) 与dataframe.reindex(columns = [’’,’’]) 均相当于一个切割效果,例子如下
columns = pd.Index(['realgdp','infl','unemp'],name = 'item')
data = data.reindex(columns = columns)
时期转为时间戳,其中’end’参数将展示的数据修改为当季度的最后一天,数据存放在data得索引上
data.index = periods.to_timestamp('D','end')
对数据进行转置,将原本的索引取消并入列(reset_index),对转置后的新列重命名
ldata = data.stack().reset_index().rename(columns = {0:'value'})
pivot(‘index=xx’,’columns=xx’,’values=xx’)
pivotde = ldata.pivot('date','item','value')
添加一列随机数据进入
ldata['value2'] = np.random.randn(len(ldata))
如果参数中不包含数据,则会DataFrame变成有层次化的列
输出文本
pivotde = ldata.pivot('date','item')
# pivotde.to_csv(r'C:\Users\37242\Desktop\macrodata2.csv')
# pivotde.to_excel(r'C:\Users\37242\Desktop\macrodata2.xlsx')
某一列取前5行
pivotde['value'][:5]
该方法等同于dataframe.pivot
unstacked = ldata.set_index(['date','item']).unstack('item')
将“宽格式”旋转为“长格式”
转换 melt
旋转DataFrame的逆运算是pandas.melt。它不是将一列转换到多个新的 DataFrame,而是合并多个列成为一个,产生一个比输入长的DataFrame。
import pandas as pd
df=pd.DataFrame({'key':['foo','bar','baz'],'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]},index=['α','β','γ'],)
pd.melt(df)
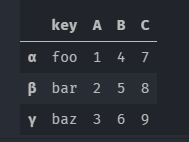
使用pandas.melt 处理
pd.melt(df,['key'])
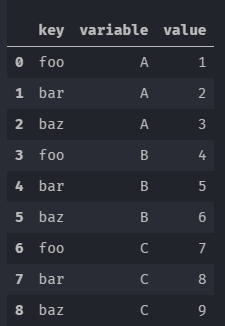
在转换时可以设置一系列参数
pd.melt(df,id_vars=['key'],value_vars=['A','B'],var_name= 'aaa',value_name='ddd')
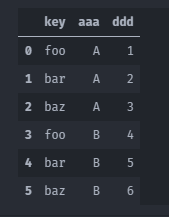
_恢复 _pivot
pivoted = melted.pivot('key','variable','value')
#等价于
melted.set_index(['key','variable']).unstack(['variable'])
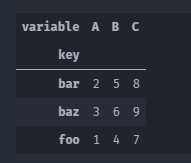
为了恢复创建了新索引,可以将索引插回数据列
pivoted.reset_index('key')
第9章 绘图和可视化
9.1 matplotlib API入门
import matplotlib.pyplot as plt
import numpy as np
data = np.arange(10)
plt.plot(data) #折线图
可以绘制出如下图
虽然seaborn这样的库和pandas的内置绘图函数能够处理许多普通的绘图任务,但 如果需要自定义一些高级功能的话就必须学习matplotlib API。
Figure和Subplot
import matplotlib.pyplot as plt
import numpy as np
data = np.arange(10)
matplotlib 的图像都位于Figre中可以用plt.figure创建一个新的Figure
图像应该是2×2的(创建2*2模板,即最多4张图),且当前选中的是4个 subplot中的第一个(编号从1开始)
fig = plt.figure() # 创建一个新的Figure
ax1 = fig.add_subplot(2,2,1) #新建多个subplot
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
绘图plot折线图、hist柱状图
ax1.plot(np.random.randn(50).cumsum(),'k--',alpha = 0.8) #'k--' 黑色虚线
ax2.hist(np.random.randn(200),bins = 20,color = 'r',alpha = 0.8) #alpha 透明度
plt.scatter(np.random.randn(50),np.random.randn(50),color = 'r') #独立绘制散点图
fig,axes = plt.subplots(2,3)
调整subplot周围的间距
利用Figure的subplots_adjust方法可以轻而 易举地修改间距
下面这个例子将四张图的间距修改为0
#格式
#subplots_adjust(left=None,bottom=None,right=None,top=None,space=None,hspace=None)
#直接创建一个2*2的Figure
fig,axes = plt.subplots(2,2,sharex=True,sharey=True)
for i in range(2):
for j in range(2):
axes[i,j].hist(np.random.randn(500),bins = 20,color = 'k',alpha = 0.8)
plt.subplots_adjust(wspace = 0,hspace = 0)
颜色、标记和线型
绿色虚线
#绿色虚线
ax.plot(x,y,'g--')
ax.plot(x,y,linestyle = '--',color = 'g') #同上
plt.plot(np.random.randn(30),'g--')
如果给图片中的数据加上端点
plt.plot(np.random.randn(30),'go--')
plt.plot(np.random.randn(30),color = 'g',linestyle = '--',marker = 'o') #同上
data = np.random.randn(30).cumsum()
plt.plot(data,'k--',label = 'Default') #label 回传图例名称
plt.plot(data,'k--',drawstyle = 'steps-post',label = 'steps-post') #drawstyle 修改图的形式,steps-post 为修改为直角折线图
plt.legend(loc = 'best') #返回图例
刻度、标签和图例 ???
对于大多数的图表装饰项,其主要实现方式有二:
- 使用过程型的pyplot接口(例 如,matplotlib.pyplot)
- 更为面向对象的原生matplotlib API
pyplot接口的设计目的就是交互式使用,含有诸如xlim、xticks和xticklabels之类的 方法。它们分别控制图表的范围、刻度位置、刻度标签等。其使用方式有以下两 种:
- 调用时不带参数,则返回当前的参数值(例如,plt.xlim()返回当前的X轴绘图 范围)。
- 调用时带参数,则设置参数值(例如,plt.xlim([0,10])会将X轴的范围设置为0 到10)
设置标题、轴标签、刻度以及刻度标签
例题代码
fig = plt.figure() #创建新的figure
ax = fig.add_subplot(1,1,1) #选择该subplot
picture = ax.plot(np.random.randn(1000).cumsum(),'k-.') # 选择图像选择并加入数据(累加)
# 输入新刻度
list_str = []
for i in range(0,1250,250):
list_str.append(i)
ticks = ax.set_xticks(list_str) #加入修改图片刻度
# rathon 控制X轴标签旋转角度 fontsize 字体大小
labels = ax.set_xticklabels(['one','two','three','four','five'],rotation = 20,fontsize = 'small')
#增加图片标题(无法使用中文标题)
title = ax.set_title('I love China')
#增加X轴标签
x_title = ax.set_xlabel('sum')
y_title = ax.set_ylabel('count',rotation = 0) #Y轴标题默认是90°旋转,如果需要横向展示需要
效果同上,可以使用如下批量设定的方式重复上面的操作
pop = {'title':'I love China','xlabel':'sum','ylabel':'count','xticklabels':['one','two','three','four','five']}
ax.set(**pop)
添加图例
如下代码进行了绘图
loc是告诉matplotlib 图例放在那里,best是默认选择一个不碍事的地方
import matplotlib.pyplot as plt
import numpy as np #载入包
fig = plt.figure(dpi=1080,frameon=False) #dpi 设置图片尺寸
ax = fig.add_subplot(1,1,1)
ax.plot(np.random.randn(1000).cumsum(),'r--',label = 'one') #插入图例名称
ax.plot(np.random.randn(1000).cumsum(),'b',label = 'two')
ax.plot(np.random.randn(1000).cumsum(),'k',label = 'three')
# 输入新刻度
list_str = []
for i in range(0,1100,100):
list_str.append(i)
ticks = ax.set_xticks(list_str)
ax.legend(loc = 'best') #添加图例
注释以及在Subplot上绘图
注意
ax.annotate方法可以在指定的x和y坐标轴绘制标签
#注释以及在Subplot上绘图
import pandas as pd
import numpy as numpy
from matplotlib import pyplot as plt
from datetime import datetime
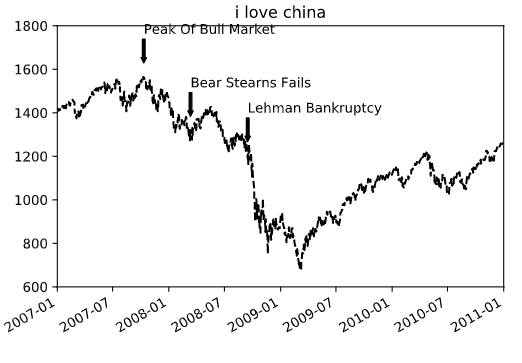
data = pd.read_csv(r'C:\Users\37242\Desktop\spx.csv',index_col=0,parse_dates=True)
spx = data['SPX']
fig = plt.figure(dpi=1080)
ax = fig.add_subplot(1,1,1)
spx.plot(ax =ax,style = 'k--')
#增加注释内容
data_c = [(datetime(2007,10,11),'Peak Of Bull Market'),
(datetime(2008,3,12),'Bear Stearns Fails'),
(datetime(2008,9,15),'Lehman Bankruptcy')]
for i,j in data_c:
#在指定X和y坐标轴上增加标签
ax.annotate(j,xy = (i,spx.asof(i)+75),xytext = (i,spx.asof(i)+255),
arrowprops = dict(facecolor = 'black',headwidth = 4,width = 2,headlength = 4),
horizontalalignment = 'left',verticalalignment='top')
ax.set_title('i love china')
ax.set_xlim(['1/1/2007','1/1/2011']) #截取X轴数据边界
ax.set_ylim([600,1800]) #截取Y轴数据边界
将图片保存到文件
利用plt.savefig可以将图片输出,常用参数有2量
- 参数一:dpi= 1080
- 参数二:Bbox_inches = ‘tight’ #可以剪除当前图表周围的空白部分
#接上图数据
fig.savefig(r'C:\Users\37242\Desktop\figpath.png',dpi = 1200,bbox_inches = 'tight') #输出图片

9.2使用pandas与seaborn绘图
matplotlib实际上是一种比较低级的工具。要绘制一张图表,需要装一些基本组件。
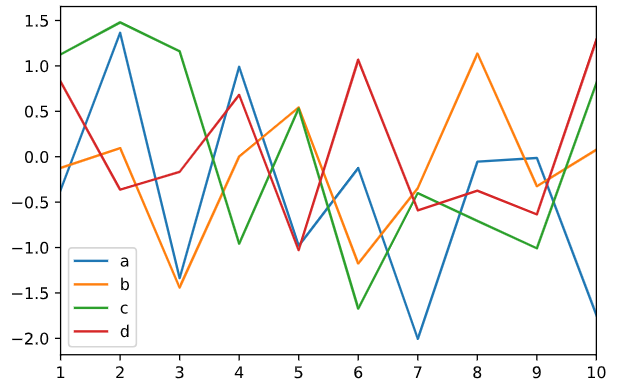
DataFrame的plot方法会给子块(subplot)中为各列绘制一条线,并且自动创建图例
df = pd.DataFrame(np.random.randn(10,4),columns= ['a','b','c','d'],index = np.arange(1,11,1))
df.plot.line()
#等同于
df.plot()
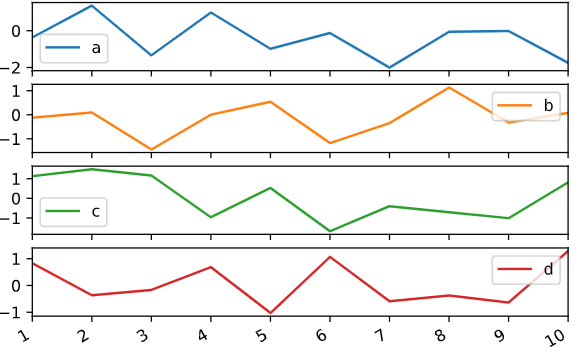
DataFram还有一些对于列灵活处理的选项可以使用(如下图)

测试代码如下
注意: 数据取自上个代码框
# 参数1
df.plot.line(subplots = True)
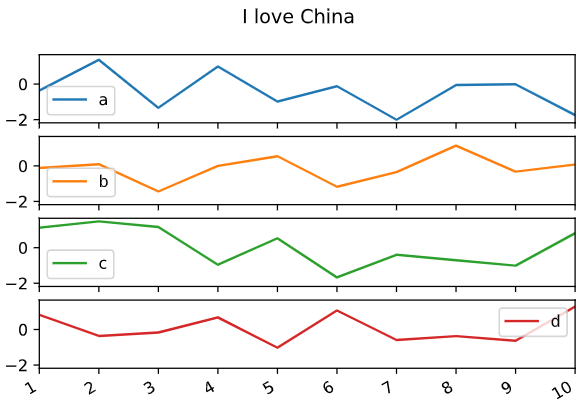
#参数3、5
df.plot.line(subplots = True,sharey = True,title = 'I love China')
柱状图 —— bar、barh
plot.bar()和plot.barh()分别绘制水平和垂直的柱状图。这时,Series和DataFrame的 索引将会被用作X(bar)或Y(barh)刻度。
例1:使用Pandas的Series(系列)绘图
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn
fig,axes = plt.subplots(2,1)
#遍历字母
x = [chr(i) for i in range(ord('a'),ord('p')+1)]
df = pd.Series(np.random.randn(16),index = x)
# 绘图并重新分类轴坐标
y_lim = [i for i in range(-2,3,1)]
# x_lim = [chr(i) for i in range(ord('a'),ord('p')+1,3)]
df.plot.bar(ax = axes[0],color = 'k',alpha = 0.7,yticks = y_lim)
df.plot.barh(ax = axes[1],color = 'k',alpha = 0.7,xticks = y_lim)
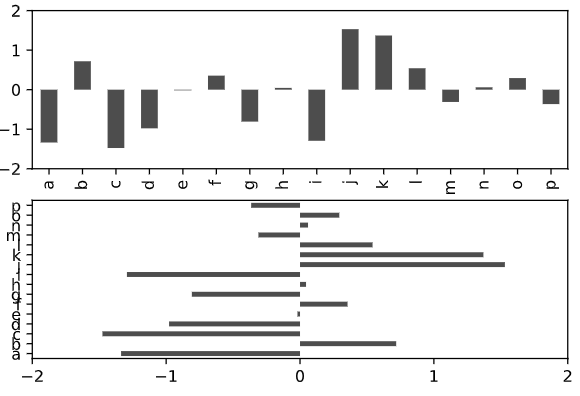
例2:使用Pandas的DataFrame(数据帧)绘图
fig,axes = plt.subplots(2,1)
y_index = [chr(i) for i in range(ord('a'),ord('f')+1)]
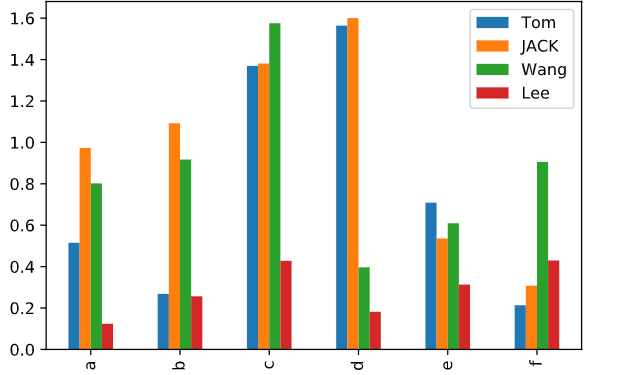
df_df = pd.DataFrame(abs(np.random.randn(6,4)),columns = ['Tom','JACK','Wang','Lee'],index = y_index)
df_df.plot.bar() #独立图片1
df_df.plot.bar(ax = axes[0]) #图片组1
df_df.plot.barh(ax = axes[1]) #图片组2
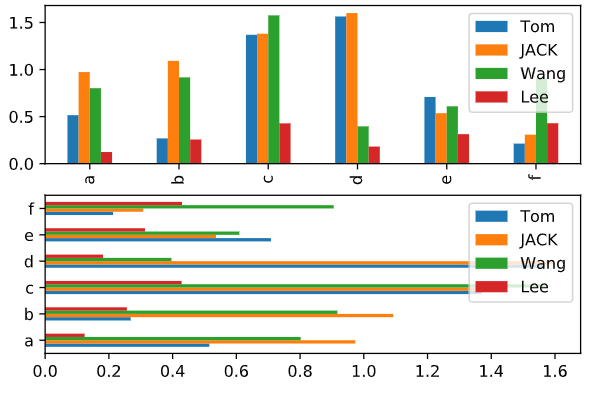
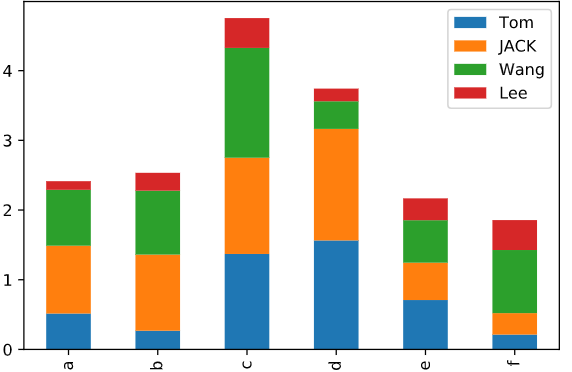
当stacked参数为真时,可以将图片转换为堆积柱状体
df_df.plot.bar(stacked = True)
df_df.plot.barh(stacked = True)
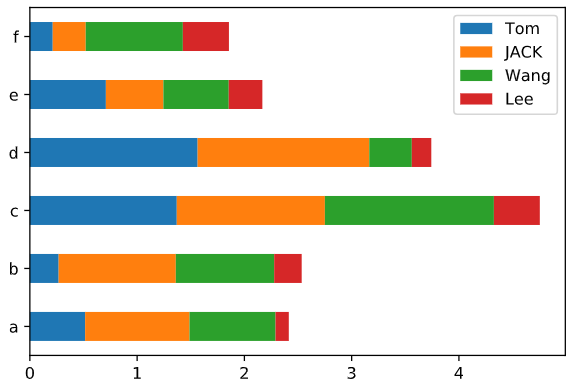
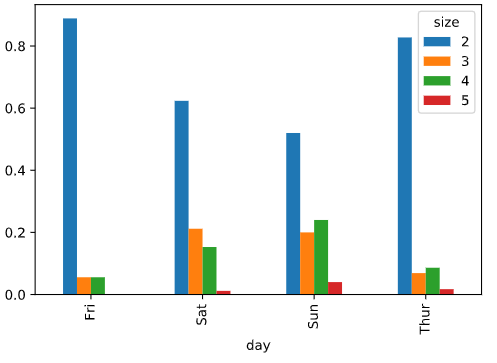
柱状图有一个非常不错的用法:利用value_counts图形化显示Series中各值的出现频率,比如s.value_counts().plot.bar()。
本次使用了交叉列表取值(pd.crosstab)
tip = pd.read_csv(r'C:\Users\37242\Desktop\tips.csv')
part_count = pd.crosstab(tip['day'],tip['size'])
#取出目标列
part_count = part_count.loc[:,2:5]
#div 浮动出发?? 没看懂原理
part = part_count.div(part_count.sum(1),axis = 0)
part.plot.bar()
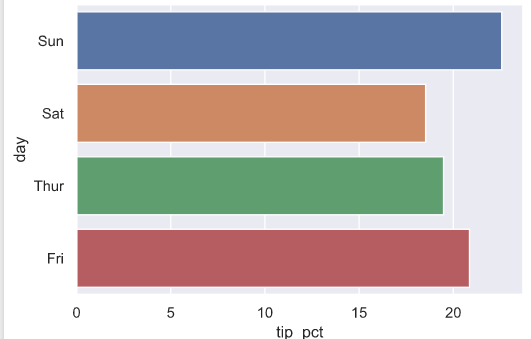
使用seaborn绘制柱状图,修改图片整体风格
数据继续使用上图
import seaborn as sns
tip['tip_pct'] = np.round(tip['tip']/(tip['total_bill']-tip['tip']) * 100,2)
sns.set(style="darkgrid") #设定风格
sns.barplot(x = 'tip_pct',y = 'day',data=tip,ci=None,orient='h')
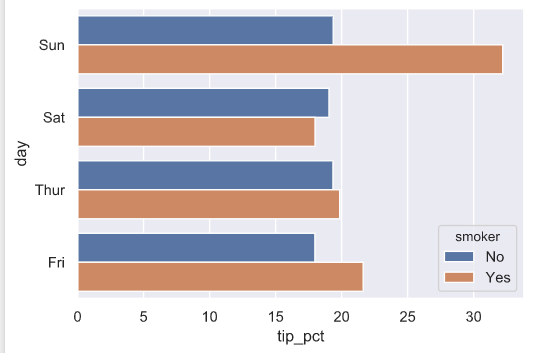
指定hue对已分组的数据进行嵌套分组(第二次分组)并绘制条形图
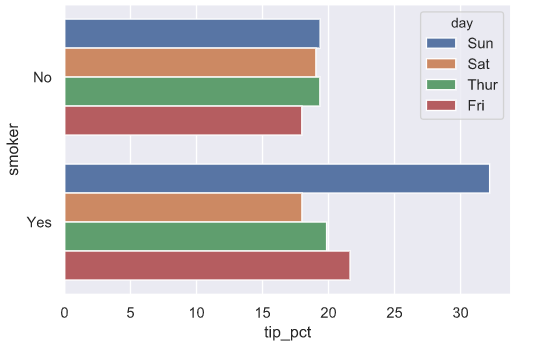
sns.barplot(x = 'tip_pct',y = 'day',hue='smoker',data=tip,ci=None,orient='h')
sns.barplot(x = 'tip_pct',y = 'smoker',hue='day',data=tip,ci=None,orient='h')
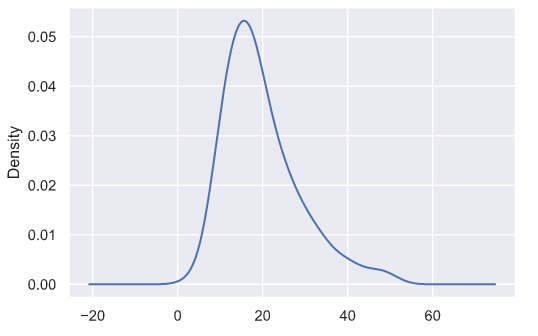
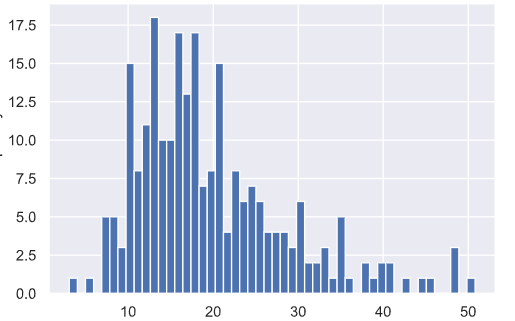
直方图与密度图 —— sns.distplot
import seaborn as sns
sns.set(style="darkgrid") #设定风格
#直方图
tip['total_bill'].plot.hist(bins = 50)
#密度图
tip['total_bill'].plot.density()
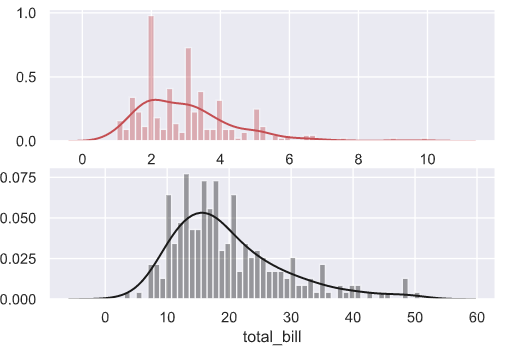
使用seaborn包同时绘制直方图与密度图,使用distplot方法
fig,axes = plt.subplots(2,1)
sns.distplot(tip['tip'],bins=50,color='r',label=True,ax = axes[0])
sns.distplot(tip['total_bill'],bins=50,color='k',label=True,ax = axes[1])
散布图或点图 —— sns.regplot(散点图)(散布图矩阵)
data = pd.read_csv(r'C:\Users\37242\Desktop\macrodata.csv')
#选出目标列
data = data[['cpi','m1','tbilrate','unemp']]
#数据取对数(log),下一行减去上一行数据(diff),删除空值(dropna)
trans_data = np.log(data).diff().dropna()
# 绘制散点图
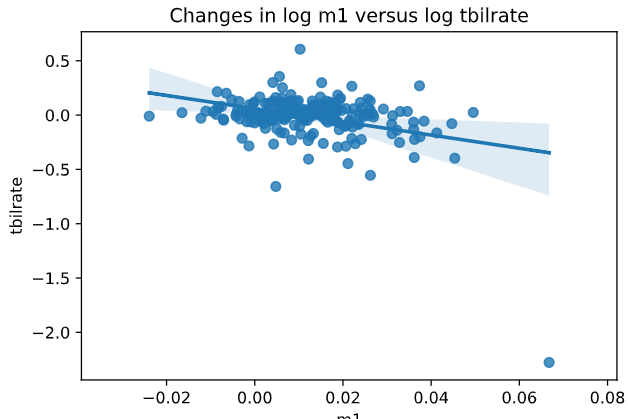
sns.regplot(x = 'm1',y = 'tbilrate',data = trans_data)
#设置图片标题
plt.title('Changes in log %s versus log %s'%('m1','tbilrate'))
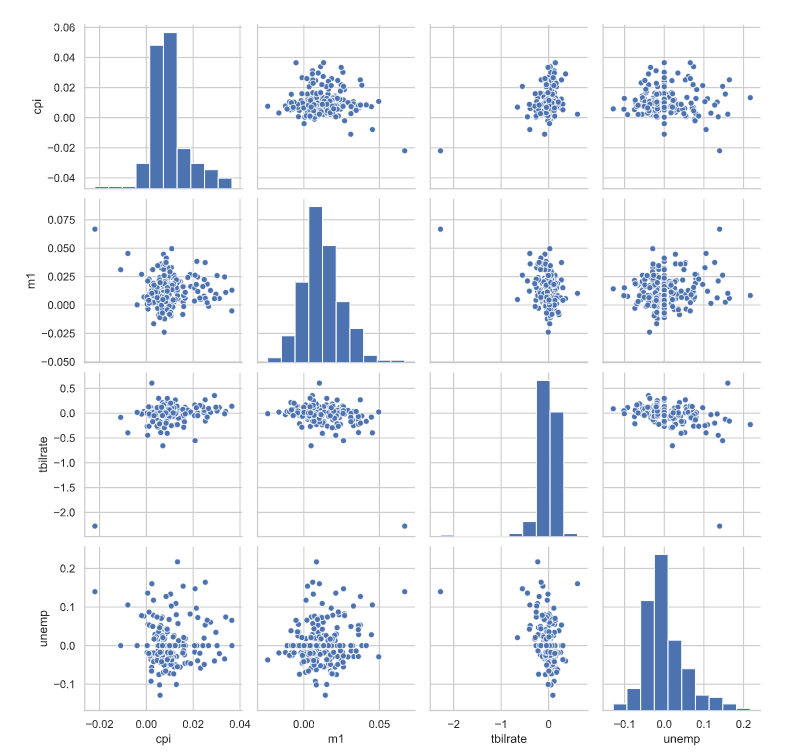
探索式数据分析工作中,同时观察一组变量的散布图是很有意义的,这也被称为** 散布图矩阵**(scatter plot matrix)。纯手工创建这样的图表很费工夫,所以 seaborn提供了一个便捷的pairplot函数,它支持在对角线上放置每个变量的直方图 或密度估计。
#设置风格
sns.set(style='whitegrid',context = 'notebook')
sns.pairplot(data= trans_data,size= 2.5)
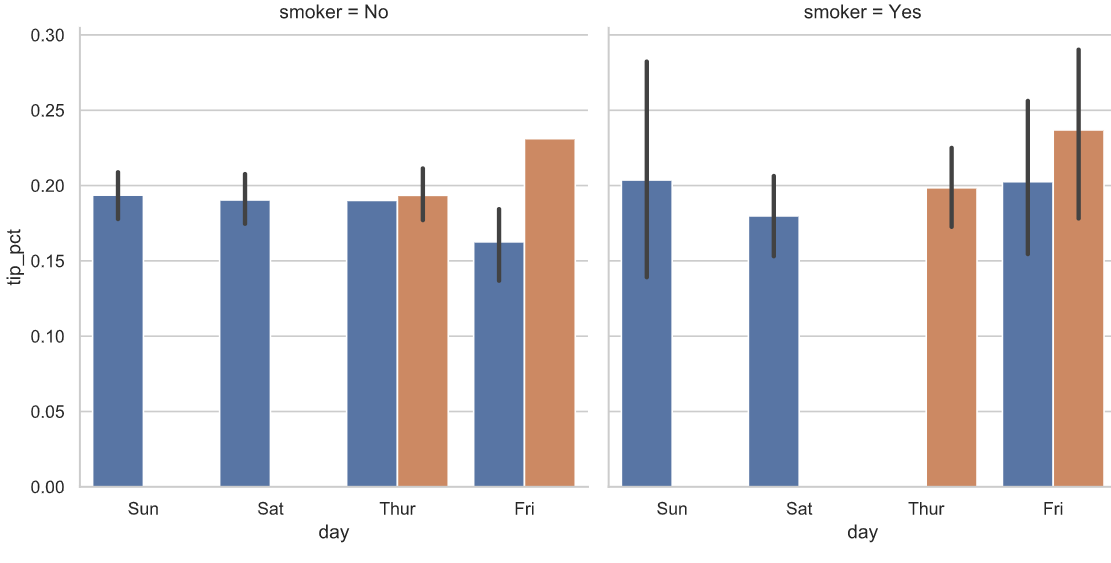
分面网格(facet grid)和类型数据 —— sns.factorplot
有多个分类变量的数据可视化的一种方法是使用 小面网格。seaborn有一个有用的内置函数factorplot,可以简化制作多种分面图
tips = pd.read_csv(r'C:\Users\37242\Desktop\tips.csv')
tips['tip_pct'] = tips['tip']/(tips['total_bill'] - tips['tip'])
# tips.head()
sns.factorplot(x='day',y='tip_pct',hue = 'time',col = 'smoker',kind = 'bar',data = tips[tips.tip_pct < 1])
除了在分面中用不同的颜色按时间分组,还可以通过给每个时间值添加一行来扩展分面网格
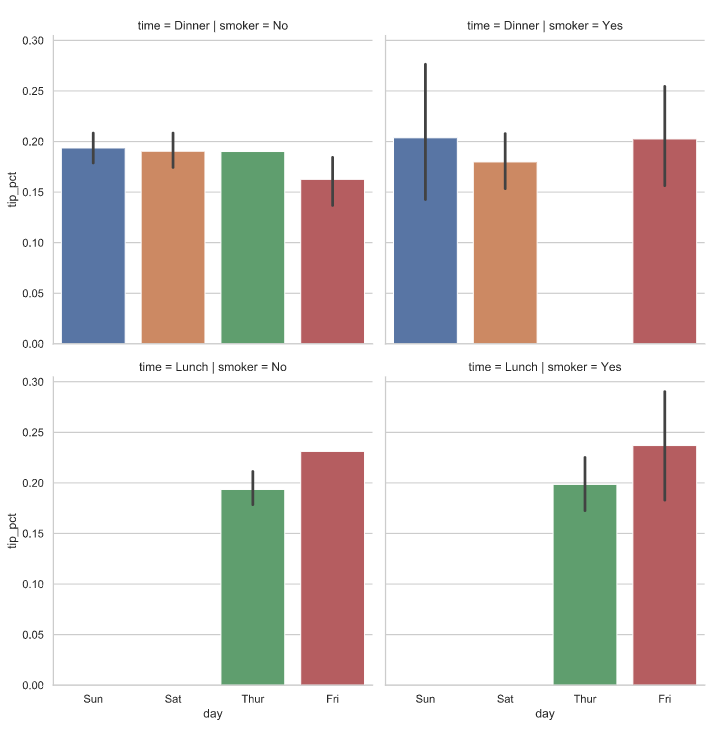
还可以绘制箱线图
sns.factorplot(x='day',y='tip_pct',kind = 'box',data = tips[tips.tip_pct < 0.5])
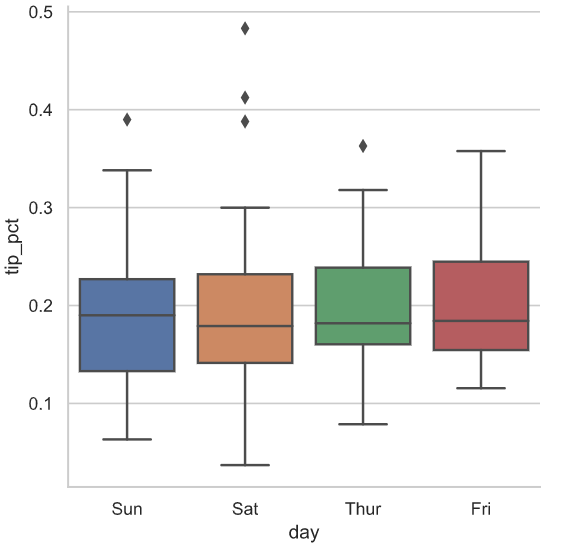
第10章 数据聚合与分组运算
本章可以学到:
- 使用一个或多个建(形式可以是函数、数组、或DataFrame列名)分割pandas对象。
- 计算分组的概述统计,比如数量、平均值或标准差,或是用户自定义函数。
- 应用数组内转换或其他运算,如格式化、线性回归、排名或选取子集等。
- 计算透视表或交叉表。
- 执行分位数分析以及其他统计分组分析。
注意:对时间序列数据的聚合(groupby的特殊用法之一)也称作重采样11章单独进行讲解
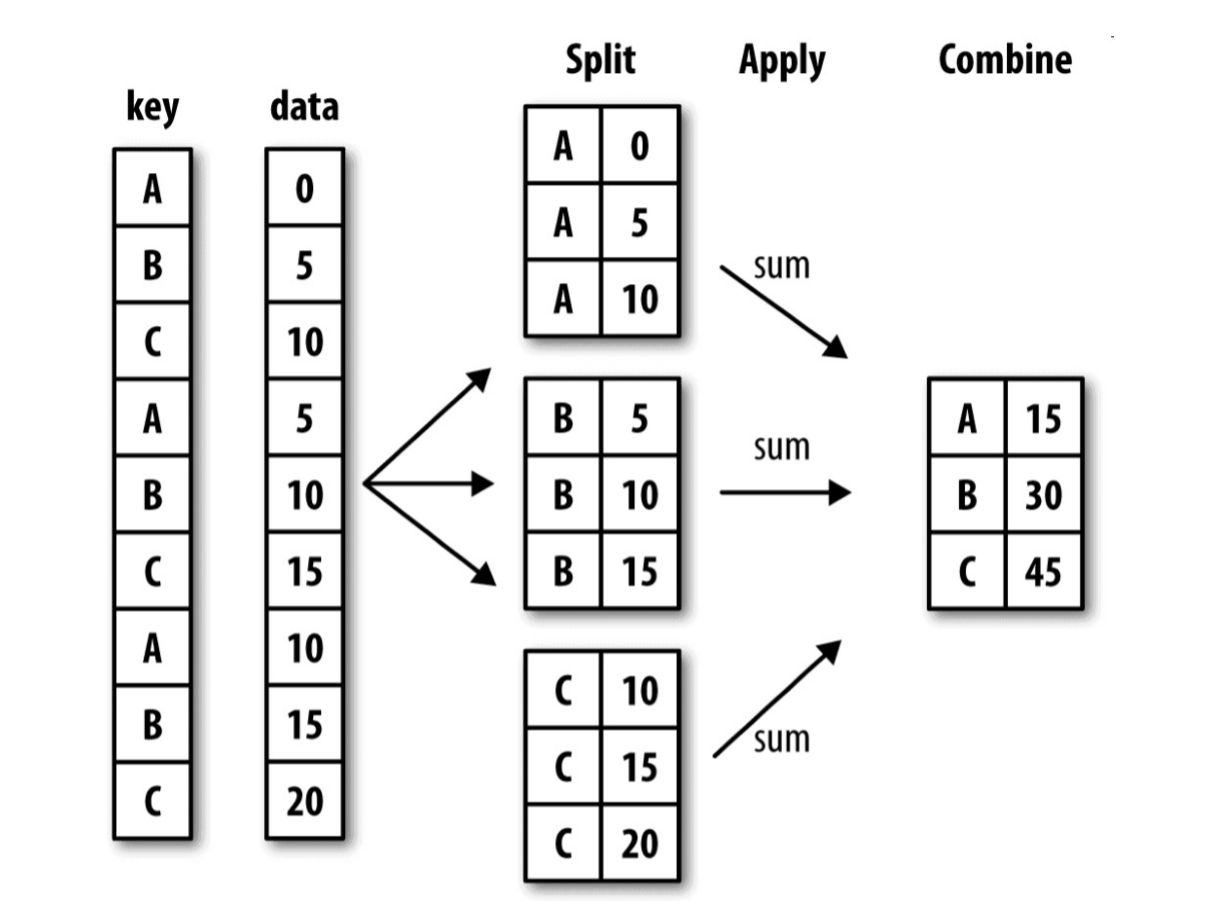
下面是一个基本的分组聚合的过程
10.1聚合 —— groupby
import pandas as pd
import numpy as np
#数据准备
df = pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two' ,'one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
#聚合
df['data1'].groupby(by = df['key1']).mean()
df[['data1','data2']].groupby(df['key1']).sum()
还可以进行反向转置
grouped = df[['data1','data2']].groupby([df['key1'],df['key2']]) #注意多列的选择方式
grouped.mean().unstack() #反向转置
分组键的使用:可以给已有的数据手动添加上列名,但是注意——列名需要跟数据列长度相同,例子如下
state = np.array(['jack','tom','wang','wang','jack'])
year = np.array(['2001','2019','2001','2199','2019'])
df['data1'].groupby(state).mean()
df['data1'].groupby(state).count()
df['data1'].groupby([state,year]).mean()
groupby 中的键值默认作用于所有列,所以下面的输出相同
df[['data1','data2']].groupby(df['key1']).mean()
df.groupby('key1').mean()
df[['data1','data2']].groupby([df['key1'],df['key2']]).sum()
df.groupby([df['key1'],df['key2']]).sum()
返回一列描述分类形状的数据,使用.size()完成
df[['data1','data2']].groupby(df['key1']).size()
df.groupby('key1').size()
df[['data1']].groupby(df['key1']).count() #size与count函数类似但又不同,size只返回一列数据
任何分组中的缺失值,都会被从结果中除去
对分组进行迭代
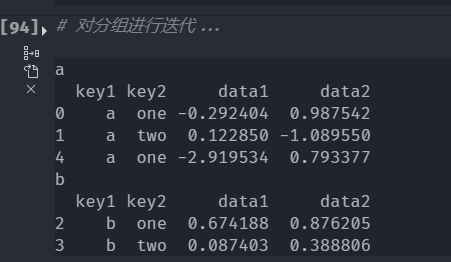
groupby对象支持迭代,可以产生一组二元元祖
for i,j in df.groupby('key1'): #单键
print(i)
print(j)
for i,j in df.groupby(['key1','key2']): #双键
# print(i)
print(j)
单键结果:
选取一列或列的子集聚合
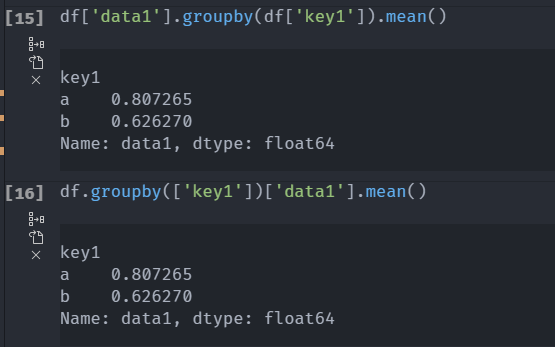
df.groupby(['key1'])['data1'].mean()
# 语法糖(功能相同但可读性更强的写法
df['data1'].groupby(df['key1']).mean()
#抽出多列聚合
df[['data1','data2']].groupby(df['key1']).mean()
通过字典或Series进行分组
#字典分组
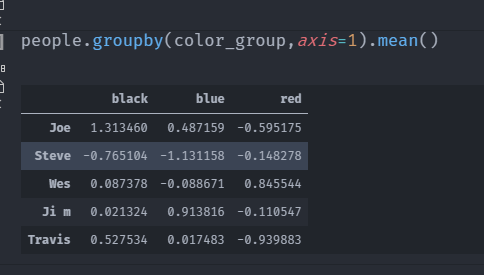
people=pd.DataFrame(np.random.randn(5,5),columns=['a','b','c','d','e'] ,index=['Joe','Steve','Wes','Ji m','Travis'])
color_group = {'a':'red','b':'red','c':'black','d':'black','e':'blue'}
people.groupby(color_group,axis=1).mean()
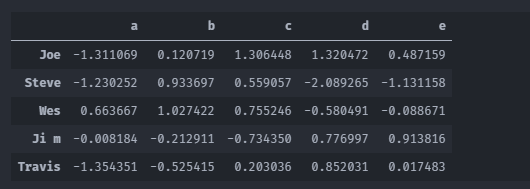
手动添加分组
10.2数据聚合
聚合指的是任何能够从数组产生标量值的数据转换过程。
聚合的种类
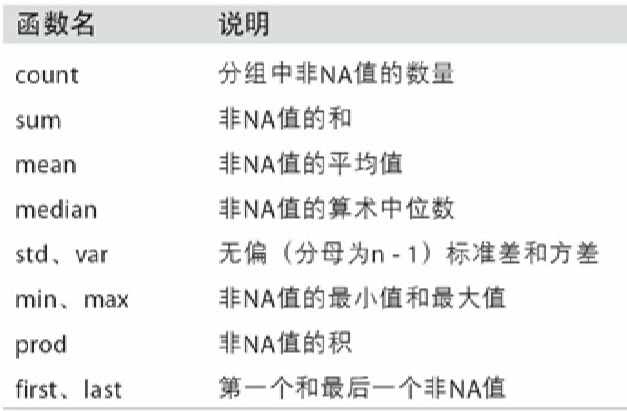
数据聚合支持自定义函数,其中系统自带的求分位数也可以在其中使用,下端代码以取0.9分位数为例。
#计算样本分位数
grouped = df.groupby(['key1'])
grouped['data1'].quantile(0.9)
可以自行定义聚合函数
#自定义聚合函数
import pandas as pd
import numpy as np
#数据准备
df = pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two' ,'one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
def group_fun(arr):
return arr.max() - arr.min()
grouped = df[['data1','data2']].groupby(df['key1'])
grouped.agg(group_fun)
注意:自定义聚合函数要比那些经过优化的默认函数慢得多。这是因为在 构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)
面向列的多函数的应用
读取数据,创建聚合函数
tip = pd.read_csv(r'C:\Users\37242\Desktop\tips.csv')
part_count = pd.crosstab(tip['day'],tip['size'])
tip['tip_pct'] = np.round(tip['tip']/tip['total_bill'] * 100,2)
# tip
grouped = tip.groupby(['day','smoker'])['tip_pct','tip'] #挑出多列列进行聚合
调用函数,可以直接输入默认函数的字符串名称,也可以使用上一节自定义的聚合函数
grouped = tip.groupby(['day','smoker'])['tip_pct','tip'] #挑出多列进行聚合
grouped.agg(['mean','std',group_fun]) #聚合函数输入,上一节的自定义函数也可以调用。
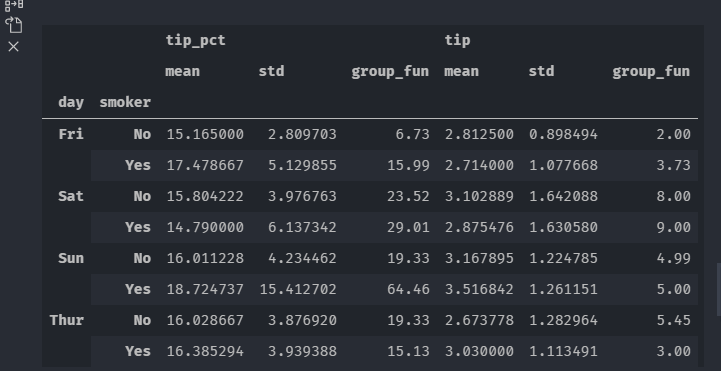
我们可以对函数进行一个重命名,格式为(name,function),其中name会被作为列明,上面的语句可以写为:
grouped.agg([('均值','mean'),('方差','std'),('自定义函数',group_fun)])
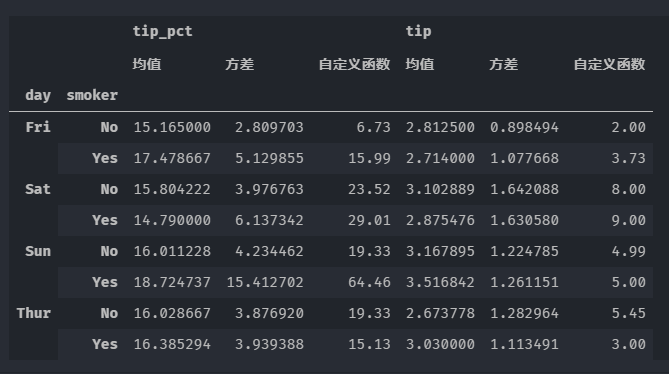
当然,同样的效果很多其他的写法
grouped.agg([('foo','mean'),('方差',np.std)])
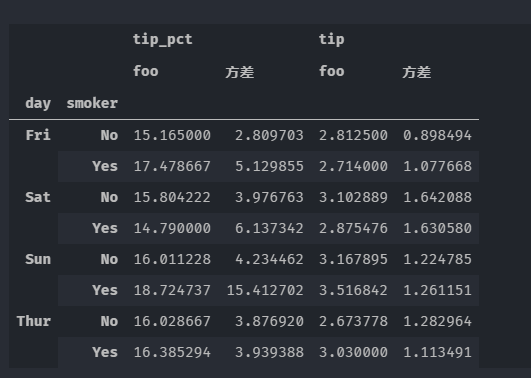
从聚合结构中取出部分数据
functin = ['mean','max','count']
grouped = tip.groupby(['smoker','day'])['tip','tip_pct']
result = grouped.agg(functin)
result['tip']
要对一个列或不同的列应用不同的函数。具体的办法是向agg传入 一个从列名映射到函数的字典
#指定列进行指定函数聚合
grouped = tip.groupby(['day','smoker'])
grouped.agg({'tip':'mean','tip_pct':'count'})
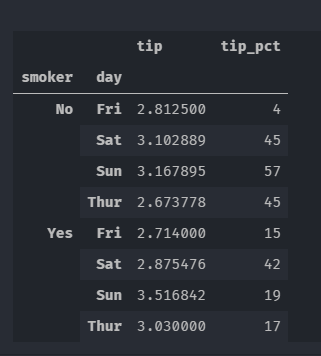
# 仅对某一列进行多函数聚合
grouped.agg({'tip_pct':['min','max','mean','std'],'size':'sum'})
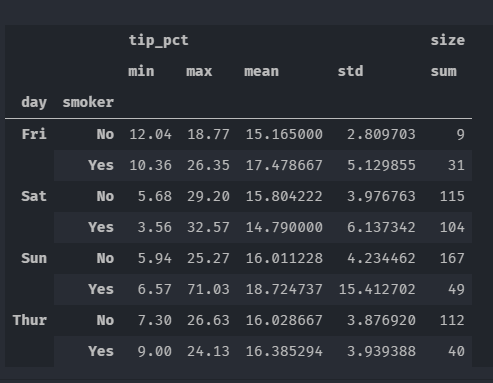
以“没有索引行”的形式返回聚合数据
# 以“没有索引行”的形式返回聚合数据
tip.groupby(['day','smoker'],as_index = False).mean()
没有索引,reset_index也能实现这种功能,as_index = False的方式实现减少了很多计算
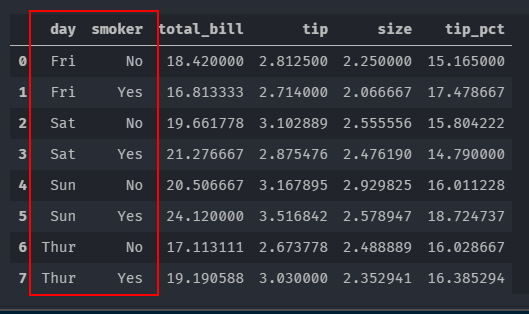
10.3 一般性的“拆分-应用-合并”—— apply
import pandas as pd
import numpy as np
tips = pd.read_csv(r'C:\Users\37242\Desktop\tips.csv')
tips['tip_pct'] = tips['tip']/tips['total_bill']
def top(df,n = 5,column = 'tip_pct'):
return df.sort_values(by = column)[-n:]
top(tips,n=6)
tips.groupby('smoker').apply(top)
#如果要接收多个参数,跟在数据后即可
tips.groupby(['day','smoker']).apply(top,n = 6,column = 'total_bill')
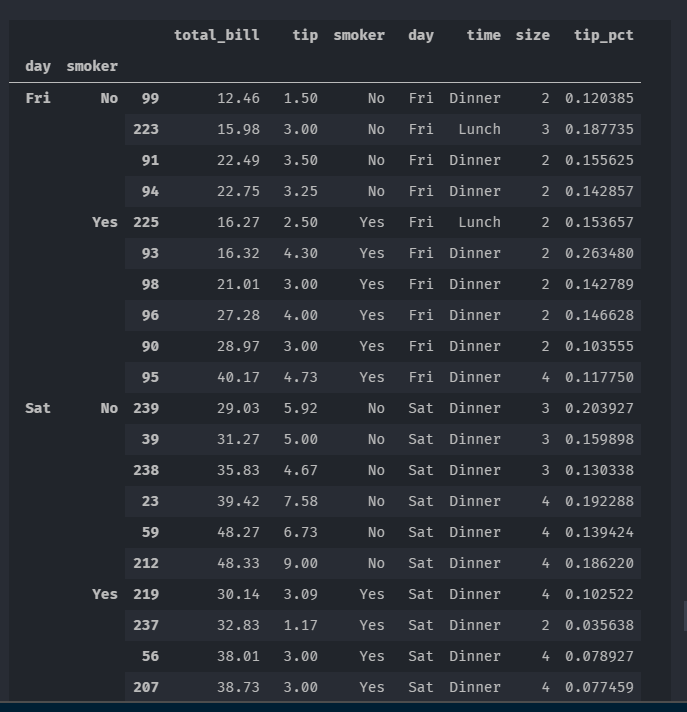
笔记:除这些基本用法之外,能否充分发挥apply的威力很大程度上取决于你的 创造力。传入的那个函数能做什么全由你说了算,它只需返回一个pandas对象 或标量值即可。
禁止分组件 —— group_keys = False
从上面的例子中可以看出,分组键会跟原始对象的索引共同构成结果对象中的层次 化索引。将group_keys=False传入groupby即可禁止该效果:
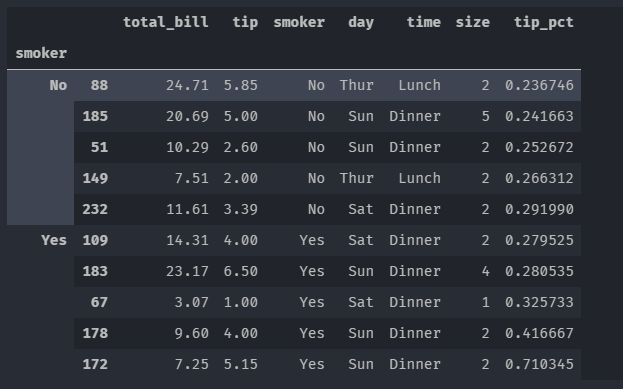
tips.groupby('smoker',group_keys = False).apply(top)
分位数和桶分析 —— cut、qcut
下面的代码为使用pd.cut给学生的分数评级操作
rank_no = np.random.randint(0,100,size = 20)
df = pd.DataFrame()
df['score'] = rank_no
#随机一个学生名称
df['student'] = [pd.util.testing.rands(3) for i in range(len(rank_no))]
#分数区分
bins = [0,60,70,80,90,100]
scort_cut = pd.cut(df['score'],bins,labels=['E','D','C','B','A'])
# pd.value_counts(scort_cut) #计数
df['rank'] = scort_cut
使用cut将已有的数据进行自定义区间聚合,以一个1000*2的DataFrame为例
首先建立需要用来聚合的函数
#建立函数
def group_by(group):
return({'均值':group.mean(),'最大值':group.min(),'最大值':group.max(),'数量':group.count()})
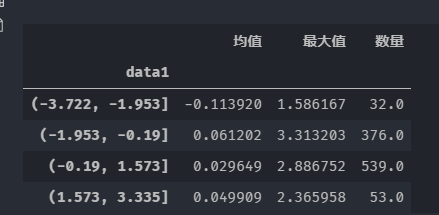
将DataFrame的第一列也就是data1使用**cut**分割区间,当bins = 4的含义为,将数据以data1的最大值与最小值为边界,将整个区间平均分为四份,然后对data2进行自定义函数的聚合
#建立数据集
frame = pd.DataFrame({'data1' : np.random.randn(1000),'data2' : np.random.randn(1000)})
rank_no = pd.cut(frame['data1'],4)
grouped = frame['data2'].groupby(rank_no)
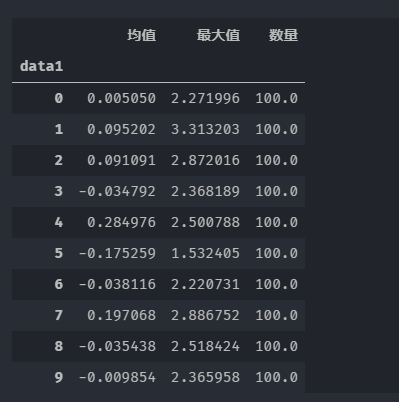
grouped.apply(group_by).unstack()
将DataFrame的第一列也就是data1使用**qcut**分割区间,bins = 10的含义为,将数据总条数平均分为10份
group_no = pd.qcut(frame['data1'],10,labels=False)
grouped = frame['data2'].groupby(group_no)
grouped.apply(group_by).unstack()
从执行结果可以看出,1000行数据被平均分成了10份,每份100行
用于特殊分组的值填充缺失值 —— fillna
对于缺失数据的清理工作,有时你会用dropna将其替换掉,而有时则可能会希望用 一个固定值或由数据集本身所衍生出来的值去填充NA值。这时就得使用fillna了
Series空值补充
import pandas as pd
import numpy as np
#使用数据均值填充NA
s = pd.Series(np.random.randn(6))
s[::2] = np.nan
s.fillna(np.mean(s))
#效果同上,写法不同
s.fillna(s.mean())
DataFrame空值补充
df = pd.DataFrame({'data1':(np.random.randn(6)),'data2':(np.random.randn(6))})
df[::2] = np.nan
df.fillna(df.mean())
#第二种写法
fill_mean = lambda g:g.fillna(g.mean())
df.apply(fill_mean)
分组填充缺失值
#准备包含空值的数据
states = ['Ohio','NewYork','Vermont','Florida','Oregon','Nevada','California','Idaho']
data = pd.Series(np.random.randn(8),index=states)
data[['Vermont','Nevada','Idaho']]=np.nan
#根据东西部求均值
# data.groupby(group_key).mean()
group_key = ['East'] * 4 + ['Wast'] * 4
#分组补充空值
fill_mean = lambda g:g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
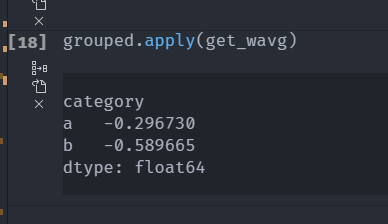
分组加权平均数和相关系数
计算加权平均数 —— average
#分组加权平均数
import pandas as pd
import numpy as np
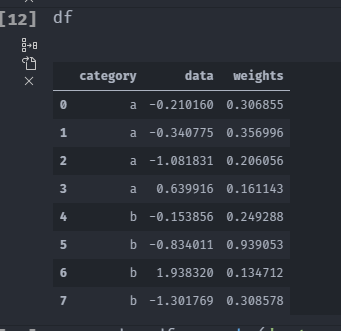
#准备数据
df=pd.DataFrame({'category':['a','a','a','a','b','b','b','b'],'data':np.random.randn(8),'weights':np.random.rand(8)})
#然后可以利用category计算分组加权平均数:
grouped = df.groupby('category')
get_wavg = lambda g : np.average(g['data'],weights=g['weights'])
grouped.apply(get_wavg)
计算相关系数 —— corrwith
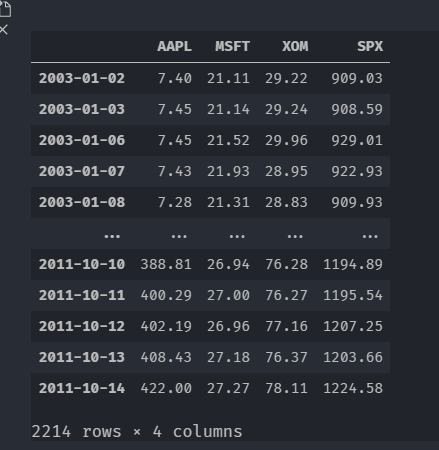
首先读取道琼斯500数据,其中_parse_dates_``=``True``,``_index_col_``=``0分别是将第一列作为索引并设置为日期格式
close_px = pd.read_csv(r'C:\Users\37242\Desktop\stock_px_2.csv',parse_dates=True,index_col=0)
使用自定义函数,计算日收益率与SPX之间的年度相关系数组成的DataFrame,下面自定义函数用来计算每列与SPX的成对相关系数
spx_corr = lambda x : x.corrwith(x['SPX'])
pct_change计算close_px的百分比变化;
pct_change 用来计算对比前一个数据的差值百分比,可以通过axis控制是前一列或前一行的数据;
rets = close_px.pct_change().dropna()
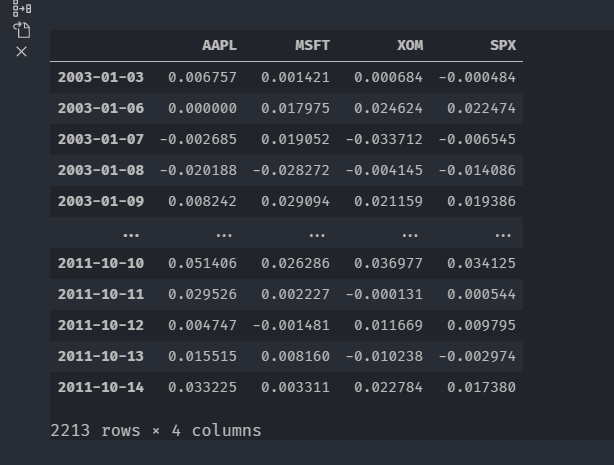
用年对百分比变化进行分组,可以用一个一行的函数,从每行的标签返回每个datetime标签的year属性
get_year = lambda x : x.year
by_year = rets.groupby(get_year)
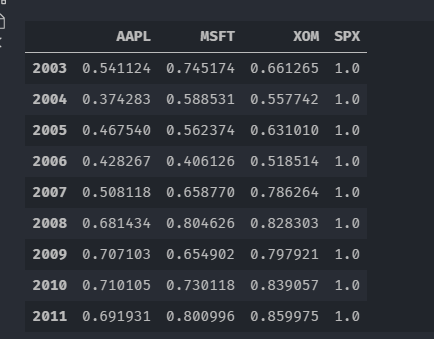
按年分组计算每一列与SPX的相关系数
by_year.apply(spx_corr)
透视表和交叉表
透视表 —— pivot_table
# 使用pandas自带的pivot_table可以快速生成透视表
tips = pd.read_csv(r'C:\Users\37242\Desktop\tips.csv')
tips.pivot_table(index=['day','smoker'])
#这个功能使用groupby可以达到相同的效果
tips.groupby(['day','smoker']).mean()
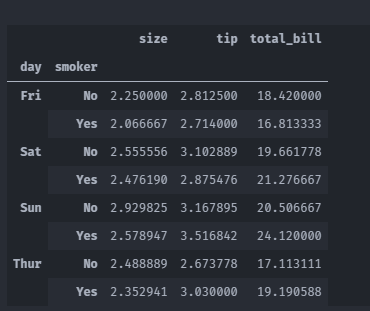
给透视表添加新的条件,其中values为用来透视的数据(默认是取均值),index为索引,columns为列名称
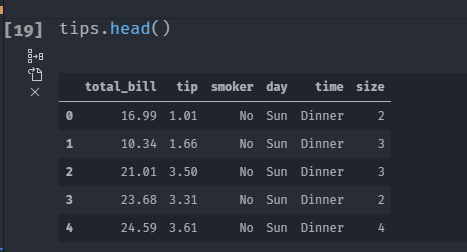
tips.head()
tips.pivot_table(values=['tip','total_bill','size'],index=['time','day'],columns=['smoker'])
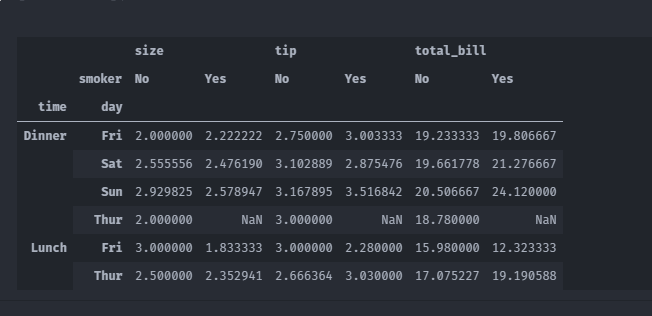
还可以对这个表作进一步的处理,传入margins=True添加分项小计。这将会添加标 签为All的行和列,其值对应于单个等级中所有数据的分组统计。
tips.pivot_table(values=['tip','total_bill','size'],
index=['time','day'],
columns=['smoker'],
margins=True,
margins_name='全数据')
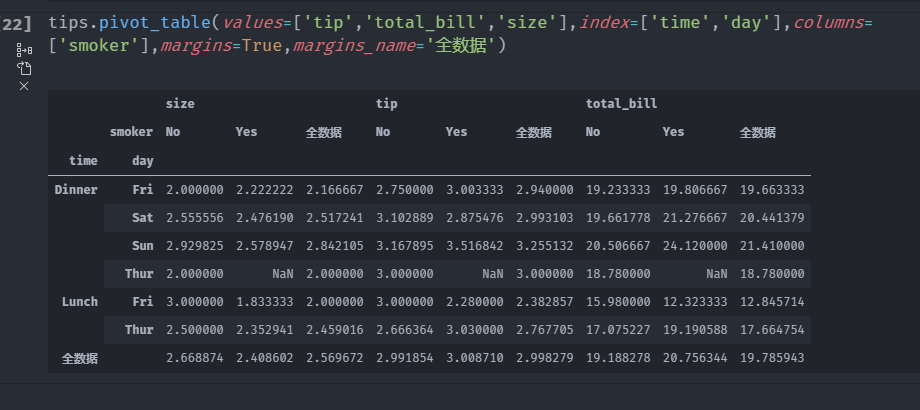
这里,All值为平均数:不单独考虑烟民与非烟民(All列),不单独考虑行分组两个 级别中的任何单项(All行)。
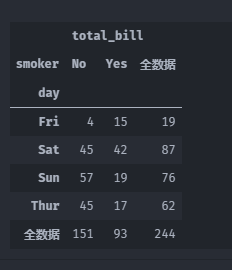
透视表函数默认为求均值,可以通过aggfunc修改
tips.pivot_table(values=['total_bill'],
index=['day'],
columns=['smoker'],
margins=True,
margins_name='全数据',
aggfunc='count')















 4140
4140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









