







这两年,随着adam算法的缺陷被科学家发现,很多研究人员开始对adam进行了改进。其中中国的两位本科学霸开发出来了AdaBound算法,受到了国内媒体的关注。我是之前看到一篇 拳打Adam,脚踩Sgd的新闻,才了解到这个AdaBound算法。当时颇为震惊,因为Adam和Sgd算法都是深度学习界赫赫有名的算法。所以抱着好奇的想法看了看这篇论文,依然有一些疑问,希望能和大家一起交流学习。
Adam算法
作为深度学习界的自适应优化算法,Adam算法可谓是威名赫赫,它赋予了神经网络在更新每个参数的时候都能自适应的选择学习步长,换言之,Adam算法仅仅需要设定一个恒定的学习率,然后网络会根据梯度值谨慎选择需要训练的参数的学习步长,可以说是弥补了sgd的恒定学习率的缺陷。

这里是Adam算法的伪代码,可以看到只要有一个初始学习率,Adam算法就能让神经网络自己选择需要更新的参数的梯度步长,这对于想用sgd算法的超大样本数据量,不知道最优学习率的情况下可谓是救星。本人在没用matlab实现Adam之前可谓是调学习率参数调到吐血。。。
但是,即使是这么厉害的算法也有缺陷,那就是可能训练到算法的末期的时候会出现不收敛的情况。因为adam算法虽然赋予了神经网络自己选择学习步长的能力,但是在训练末期会出现极大极小的学习率,导致不收敛。而sgd算法虽然需要调学习率,但是它可以严格收敛。一般来说,当我知道最优学习率的值的时候,sgd算法表现的会比Adam算法好,当然Adam算法在学习初期会更快倒是另一个优点。哈哈哈哈。
AdaBound算法
好了,该说说AdaBound算法了。该篇论文首先阐述了Adam算法和Sgd算法的优势和不足,差不多就是我上面说的。AdaBound算法在想法上融合了Adam算法和Sgd算法的优势,它的想法是,在算法前期使用Adam算法,在训练的后期使用Sgd算法。前几年有人是采用硬切断的方式来强行分割整个训练过程,就是到达某个迭代次数的时候,由Adam算法转变为Sgd算法,但是这种硬切断算法稍微有点僵硬,因为我不知道什么时候该转换算法,所以可以想象这种方法的效果存在一定的偶然性,只不过是将学习率这个超参数转换为我需要转换算法的迭代次数点这个超参数,我认为没啥意义,与其纠结什么时候转换,还是老老实实调学习率的参数或者用Adam算法来的实在。
但是AdaBound算法采用一种软分割的方式,它为Adam算法的自己选择的学习率设定了一个动态边界,限定你自己选择的学习率不能超过这个边界,并且这个动态边界可以慢慢收敛到一个最终的学习率,这时候,Adam算法就倾向于变成了Sgd算法了。下面给出论文中该算法的伪代码。

其中的一些符号我这里就不赘述了,和Adam算法很像,感兴趣的朋友们可以去查论文。这里主要是这一步。
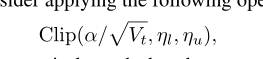
这就是限制Adam算法自己选择学习率的动态边界,后面两个一个是上边界,一个是下边界,这就像是解决梯度爆炸的梯度截断方法一样,学习率超过上边界或者低于下边界就截断,限制你的学习率。这两个边界最终会收敛到一个最终的学习率上,最终转变成Sgd算法。初看之下,确实使用的方法非常巧妙,也非常容易理解。该文中使用的边界是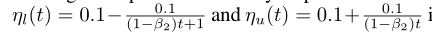
这个beta2类似于Adam算法中的beta2,该文中将它设置为0.999,和Adam一样。
部分疑问,求大神指点
我们可以分析这两个动态边界,可以发现它们分别从极大值和极小值点慢慢收敛到0.1,也就是最后转为Sgd算法的学习率值是0.1,是一个已知的固定值,换言之,这个0.1决定了算法在最终的收敛环节中转换成Sgd的性能表现。这就是我的一个很大的疑问,既然你都已经知道Sgd算法的最优学习率,或者说是差不多是最优值的学习率,那我还用AdamBound算法干嘛?直接用Sgd算法不就好了吗?如果说这个算法的目的在于仅仅是让Sgd算法在训练前期跑的像Adam算法一样快,但还是需要调参,就是调上面的那个0.1的学习率的值,那我认为,我还是倾向于用Adam算法,方便简单快捷还不用太大幅度的调参,不收敛就不收敛吧。
所以,我认为,当然只是一家之言。AdamBound算法仅仅只是对Sgd算法的一种改进,将Adam算法的前期的训练快速的优点融进了Sgd算法,但还是需要调参,不调参的话很难出现很好的结果,就不是很方便,我觉得应该没有达到媒体宣传的拳打Adam的情况吧。。
当然,针对我的问题,欢迎各位大神前来砸场,希望能有大佬给一个很好的解释。。我们共同进步。。哈哈哈哈哈。
Adam论文:ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION
AdaBound论文:ADAPTIVE GRADIENT METHODS WITH DYNAMIC BOUND OF LEARNING RATE














 5314
5314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









