




 本文介绍Word2vec模型原理及其与one-hot编码的区别,通过实战案例展示如何利用Word2vec进行文本聚类,包括数据预处理、模型训练及评估。
本文介绍Word2vec模型原理及其与one-hot编码的区别,通过实战案例展示如何利用Word2vec进行文本聚类,包括数据预处理、模型训练及评估。
基于Word2vec文本聚类
一、Word2vec
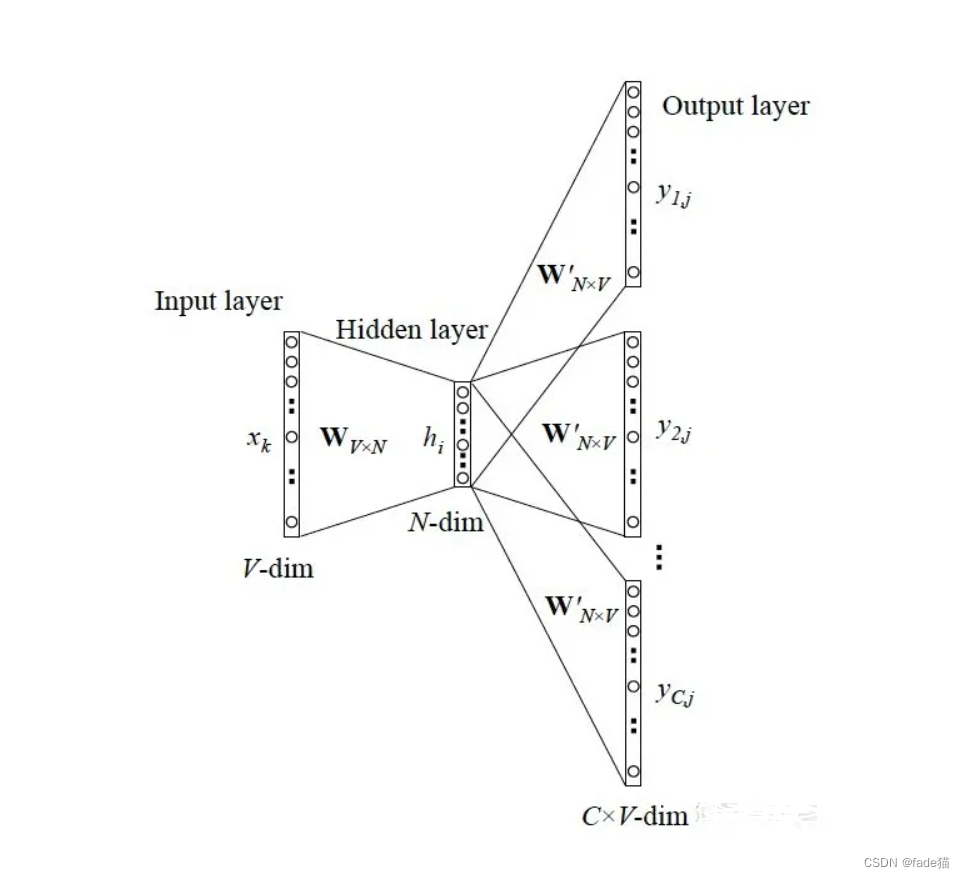
Word2vec词向量模型为Google于2013年提出,可以看为无监督神经网络模型,包括输入层-隐藏层-输出层,实现表征语义信息的词向量,根据输入层与输出层的不同,分为两个模型Skip-gram(跳字模型,输入中心词预测周边词)和CBOW(连续词袋模型,输入周边词预测中心词)。
1.Word2vec与one-hot编码关系
对比one-hot编码,明显能降低表征词向量的维度,避免one-hot维度灾难,同时降低的矩阵的稀疏性,Word2vec维度低且稠密;Word2vec可以实现词与词之间联系,而one-hot编码更像是信息孤岛,割裂了词与词之间的联系
2.Word2vec训练过程
用Skip-gram模型图解来说,即中心词预测周边词。
第一步:输入层为one-hot编码,维度为V,指定词embedding后的向量为维度为N,(输入层与隐藏层之间)之间W(VN)嵌入矩阵,最后留下该矩阵,赋予每个词向量。
第二步:隐藏层与输出层之间权重矩阵W(NV)还原成V维度向量,透过softmax函数多分类实现,还原周边词为V的向量。
第三步,softmx函数与真实one-hot编码周边词向量存在差距,这样就可以构造损失函数,model采用的是交叉熵的损失函数,判断真实模型分布与训练模型分布差距,反向更新前面权重矩阵W。
第四步:这里的softmax多分类,可以想象一个根节点,下面全是一层的叶子节点,更新所有叶子节点,消耗资源过大,最后更新的softmax结果绝大多数与softmax前的矩阵对比变动会非常小,会让人直觉上这里会有一定优化空间, 文章作者给出负采样(Negative Sample)方案,选取一小部分权重来解决softmax复杂度问题,给定这个词正例和随机抽样选取负例,实际抽样会保证高频词大概率被抽到的概率同时,会提升抽到低频词的概率!
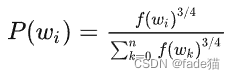
3.Word2Vec过时??
确实过时了(仅专业人士而言),现在主流都是Bert,各类开源预训练模型很多了。Word2Vec比较经典,为NLP入门模型,入门必学,理解它可以进一步了解前人Embedding思想
网上有太多Word2Vec讲述,自行检索
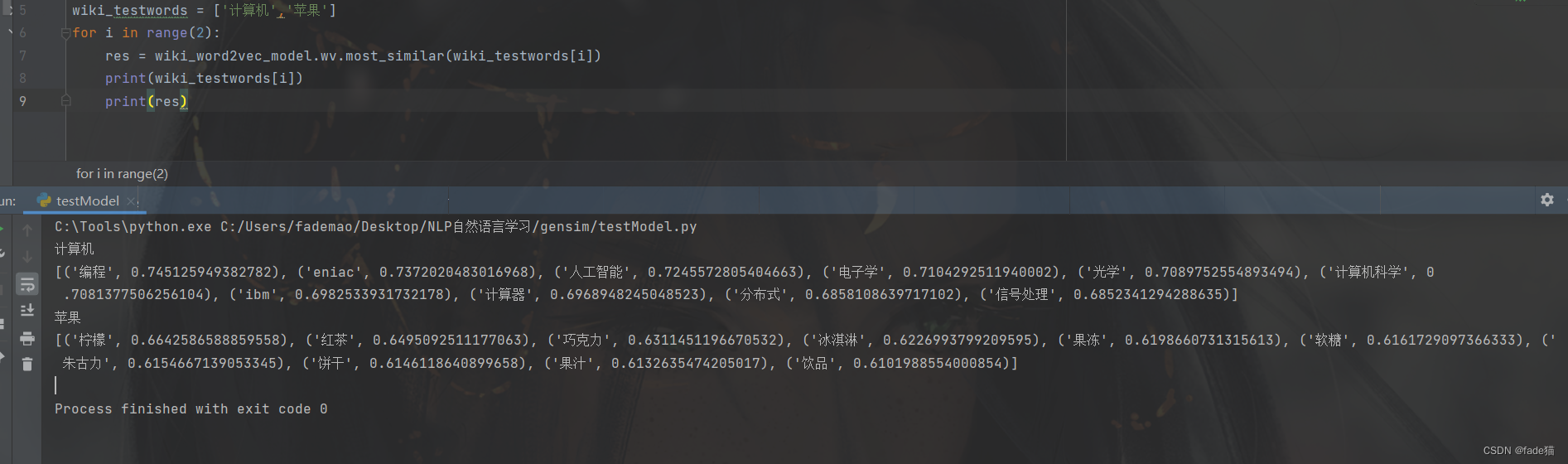
之前训练过220M的维基百科的文章,给出计算机、苹果两个字段,可以看出别人叙述计算机时通常会提到编程、eniac等,是符合正常逻辑的,如果做文本聚类、知识图谱等方面应该有不错的效果,wiki文章地址: link
代码演示
数据为网络某平台公开的2021年某月份关于笔记本的评论数据集,使用场景,面对较多的文本数据,某些工作者需要快速整理出话题,可以尝试使用该类方法
import os
import random
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
from matplotlib.ticker import MaxNLocator
from warnings import filterwarnings
filterwarnings('ignore')
import re
import numpy as np
import pandas as pd
import jieba
from gensim.models import Word2Vec
from sklearn.cluster import MiniBatchKMeans
from sklearn.metrics import silhouette_samples, silhouette_score
from sklearn.feature_extraction.text import TfidfVectorizer
SEED = 42
random.seed(SEED)
os.environ["PYTHONHASHSEED"] = str(SEED)
np.< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
























 到【灌水乐园】发言
到【灌水乐园】发言







