






Transformer是现在NLP主流的应用模型,现在大语言模型也是基于Transformer架构,主要解决序列到序列的任务,该模型能建立较长序列依赖,构造更深层的网络。从特征提取角度来理解,Transformer模型框架与CNN模型类似,是数据特征提取的一种方式。
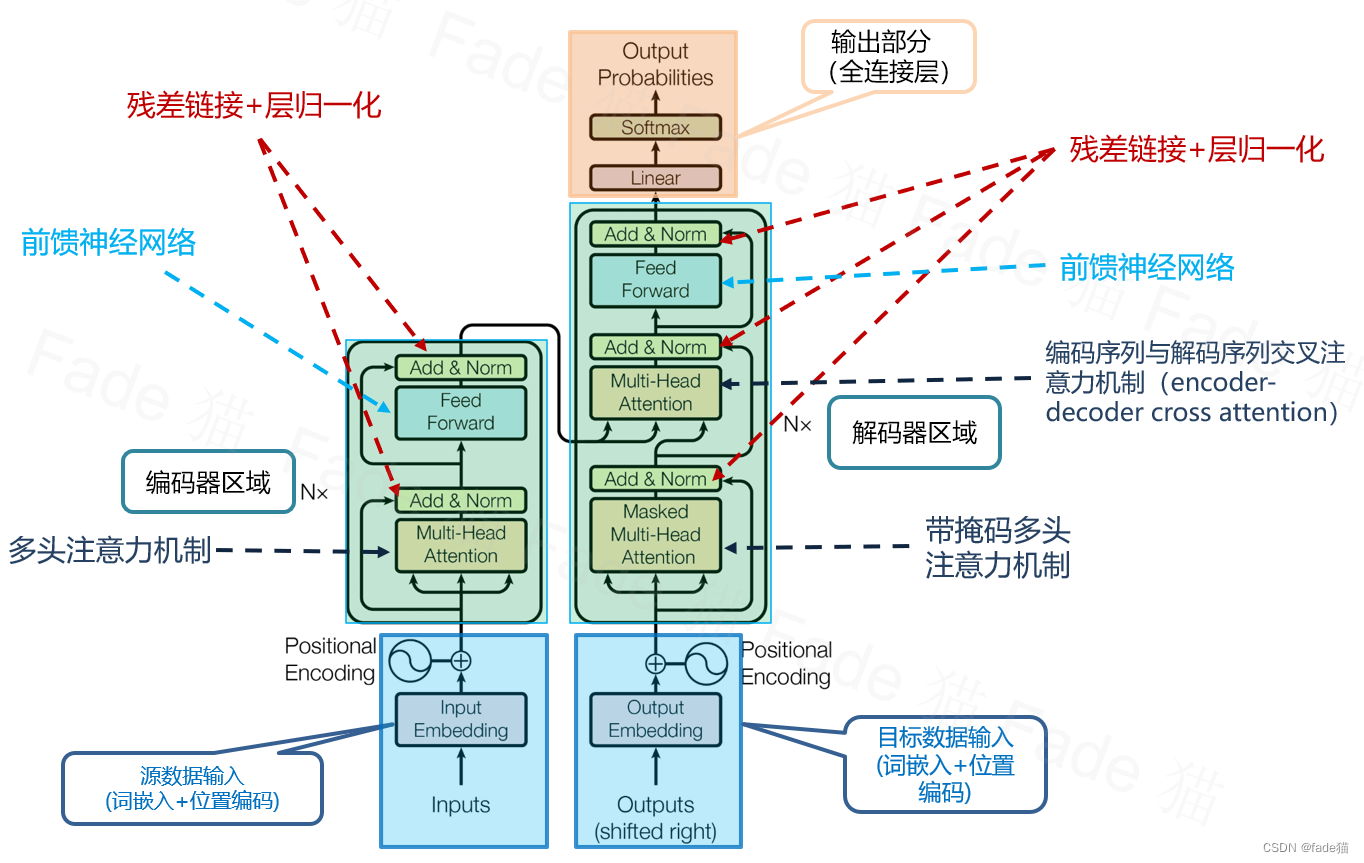
如图,模型结构由输入部分、输出部分、编码器区域部分、解码器区域部分构成
1.输入部分:
目标数据和源数据通过词嵌入(Word Embedding)后,与位置编码(Positional Encoding)结合
2.输出部分:即模型接入全连接层,输出最终模型结果。
3.编码器部分:
由多个编码器层堆叠构成,包含多头注意力机制与前馈神经网络构成的(残差模块+层归一化)两个子层结构
4.解码器部分:
解码器区域由多个解码器层堆叠构成,比编码器区域多了一个将解码器与编码器连接交叉注意力机制
5.共同的组件Add & Norm(残差链接+层归一化)
在编码器与解码器层都有Add & Norm层,Add指的是残差链接(Residual Connection),指的是层的输出与输入相加,有助于保留信息和防止梯度消失;Norm指的是层归一化,是常用的模型训练技巧,由于输入的数据都有不同的分布,归一化通过调整维度的均值和方差,可以消除这种影响,更加关注层内特征之间相互关系,改善梯度消失和梯度爆炸问题,有效提高模型的性能和训练时间
Transformer主要两个理解点,(词嵌入+位置编码)与注意力机制,其中注意力机制是Transformer的核心
1.1词嵌入+位置编码
1.1.1词嵌入(Word Embedding):
以翻译序列信息为例:源语言:今天是星期二 目标语言:Today is Tuesday
当我们将[今天,是,星期二]直接当做向量传入数据时,显然是不合理的,需要通过将文字表示成向量形式,机器才能将识别,在Transformer中一般选择512维度,假设今天,是,星期二通过词嵌入映射的对应的词向量是:
[[a0,a1,a2…………………………a511],[b0,b2,b3…………………………b511],[c0,c1,c2…………………………c511]],同理对应的目标语言也通过词嵌入进行转化
1.1.2位置编码(Positional Encoding):
这里词嵌入转化后的向量是没有任何位置信息,即不知道输入信息的前后的顺序,这时候Transformer引入位置编码(Positional Encoding)进行解决,标注序列信息的空间位置,比较RNN和LSTM,因为RNN与LSTM模型网络结构本身就是一个循环结构,自带位置信息,此外,LSTM由于特有门控机制可以有效筛选重要信息,可以更好的增强长序列的的理解能力。
这里我们定义位置编码(Positional Encoding),
PEpos,2i = sin(pos/f(i)) (偶数维度)
PEpos,2i+1 = cos(pos/f(i))(奇数维度)
其中表示成f(i) = 100002i/dmodel
dmodel = 512 这里维度仍然选择512维,与前面词嵌入的维度保持一致,偶数维度用sin函数表示,奇数维度用cos函数表示
那么对应的位置编码信息为[sin,cos,sin…………………………sin,cos]形式,我们将这个信息加入前面的词嵌入的[a0,a1,a2…………………………a511]这个向量后,我们最后的的序列向量,是包含位置信息的
1.1.2.1这样构造出位置编码,是否合理?
首先回忆一组三角函数和积化差公式
sin(α+β) = sin(α)cos(β)+cos(α)sin(β)
cos(α+β) = cos(α)cos(β)-sin(α)sin(β)
根据定义位置的信息,根据三角函数形式的转化如下:
x与y表示的词的位置
PEx+y,2i = sin((x+y)/f(i))
= sin(x/f(i)+y/f(i))=sin(x/f(i))cos(y/f(i))+cos(x/f(i))sin(y/f(i))
=PEx,2iPEy,2i+1+PEx,2i+1PEy,2i
PEx+y,2i+1 = cos((x+y)/f(i))
= cos(x/f(i)+y/f(i))=cos(x/f(i))cos(y/f(i))-sin(x/f(i))sin(y/f(i))
=PEx,2i+1PEy,2i+1-PEx,2iPEy,2i
首先,这个公式是被证明对的,我们可以看出Transformer可以线性变换表示位置x和y之间的相对关系,这样构造出的线性关系可以表达各个位置的相对关系。
以[今天,是,星期二]为例,星期二这个词位置是3,3:=1+2:=1*2+1*2,当我定义3这个位置,已经包含了前面的位置关系。这个理解起来有点抽象,当然这样效果其实后来被认为是有缺陷,在后来的模型选择了其他的编码模式,但大致的思想是想通的,无非就是相对位置和绝对位置之间的关系
1.1.3这里会产生一个疑问,词嵌入向量+位置编码后的向量,会不会影响词向量本身的在空间上的映射关系?
应该不会,引入一个例子,一个人在北京国贸,属于北京市,还有一个人在上海陆家嘴,属于上海市,突然我们按照某种规则,让这两个人同时向东走5公里,从空间上来看,他们较之前空间上的位置发生了移动,但是他们的空间关系并没有改变,依然相隔这么远。进一步,从高维上试着去理解,首先维度越高,高维上的点和点之间区别越明显,刚才我们取的512维向量,点和点之间区分非常明显,我们按照某种规则去影响这些点,只是统一影响了这些点空间点的位置,原来之间的空间映射关系并没有发生实质性改变。
1.2注意力机制
注意力描述的是序列元素的加权平均值,其权重基于输入查询(Query)和元素的键(Key)动态计算,权重信息与值(Value)融合,总结过来就是,我们想要动态地的决定我们想要那些信息参与输入。
1.2.1Q、K、V含义
这里的QKV分别代表的是Query(查询)、Key(键)、Vaule(值)
Query:查询是一个特征向量,描述了我们在序列中寻找的内容,即我们可能想要关注的内容。
Key:对于每个输入元素,我们都有一个键,它也是一个特征向量。这个特征向量粗略的描述了元素“提供什么”,或者它什么时候可能最重要。键的设计应使我们可以根据查询识别要关注的元素。
Value:输入每个元素对应的特征向量
这里可以这样理解,当我们在淘宝上去搜索某件商品时可以看成Query,这时淘宝后台数据库系统里有Key和Value,Key代表着商品相关的列表,商品列表对应的Value就是商品信息,Key与Value一一对应。当Query等于“笔记本”时,笔记本与后台商品列表Key作一个匹配,找出相关程度最高的笔记本商品,同时将商品的具体信息Values提取出来展示最终结果。
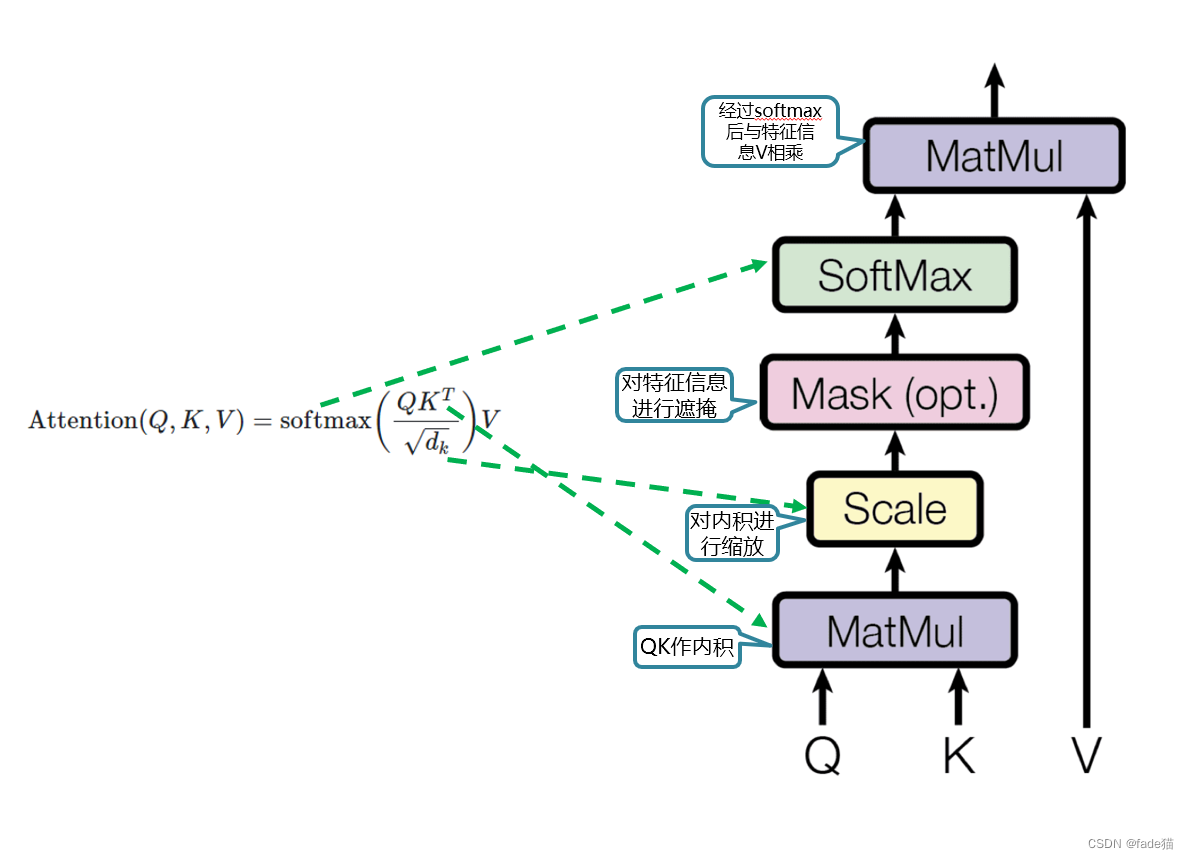
1.2.2 缩放点积注意力(Scaled Dot-Product Attentio)
如图:由图可知首先由Q与K作内积,对于向量的内积,如果内积等于0,此时在互相垂直的,两者没有相关性,这里可以理解成,内积越大,说明两者相似性越好,QK相乘最终是算出序列信息内部的权重信息,除以向量的维度的平方根(这里主要是防止QK相乘的值过大,在后续softmax中,权重过高估计,概率出现极端值,对数据进行缩放,让数据更加平稳),Mask(opt.)对部分特性信息进行遮掩,SoftMax输出序列信息的权重值,与原来的输入的信息的特征向量V进行相乘。
这里对mask(opt.)做一下解释:
在解码器和编码器区域中:在上下文句子和句子的长度不一致时,我们可以通过Padding Mask将长度不一致的部分,类似CNN对原来的图片特征向量在加上一个0值的padding,防止边缘信息的遗漏
在解码器区域中:除了将句子序列信息对齐外,还有一个重要的功能防止序列信息的超前预测,在编码器区域称之为带掩码张量的注意力(Masked Multi-Head Attention)比如今天 是 星期二,当我关注“是”这个信息时,由于“星期二”这个信息时在后面,因此,我需要将这星期二部分信息需要遮盖掉,防止后面信息干扰到前面的信息。在实际翻译中推理过程,生成的翻译是逐字逐句翻译的, 【源语言:今天是星期二 目标语言:Today is Tuesday】,当我将源语言"是"翻译成"is"的时候,这时候我们是不希望朝前预测产生“Tuesday”,训练期间我们需要对其进行遮掩,实际会填充一个很大的负数,在SoftMax后,这部分数据会变成0,这样后续的信息被遮掩了
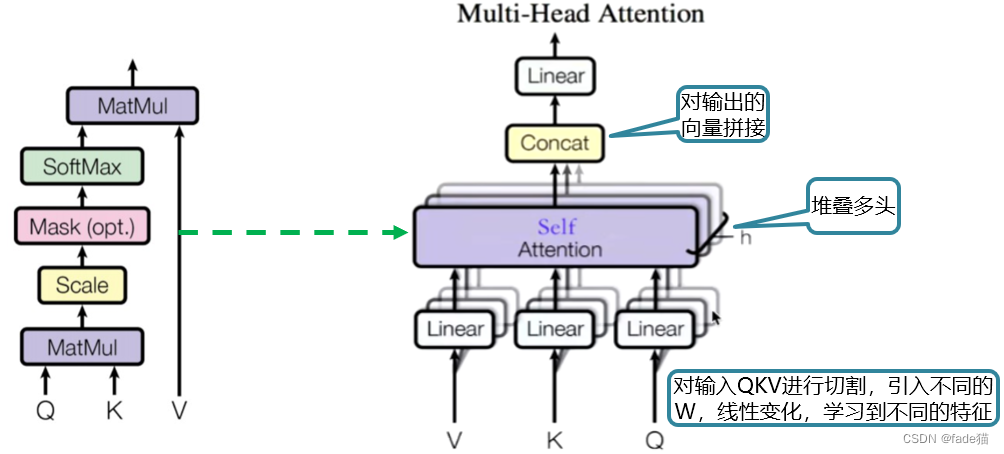
1.2.3 多头注意力(Multi-Head Attention)
对输入的QKV首先进行切割,一般选择8个头,通过线性层(Linear)与不同的W学习到不同的向量的特征,进过注意力机制,对将多个头注意力输出的向量进行拼接,保证获取全面的序列特征信息,类似CNN模型用不同的卷积核对图片信息进行提取。这里自注意力(Self-Attention)表示是Q=K=V
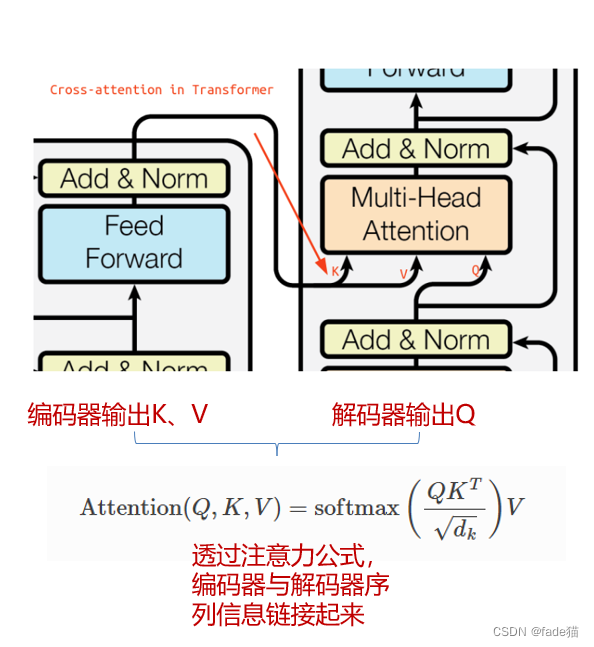
1.2.4编码器-解码器交叉注意力(Encoder-Decoder Cross Attention)
如图:编码器传入K、V,解码器输出Q,通过注意力公式,将编码器与解码器链接起来,这里可以这样理解,由于编码器区域输入是源数据,解码器输入的目标数据,由于解码器看到是当前词,且表达的意思通过注意力输出都包含在这个词向量中,用这些信息来聚焦编码器中与当前词相关的信息,这可以生成更为准确的上下文向量来帮助解码。

















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









