







单表查询数据
create table emp(
id int primary key AUTO_INCREMENT not null,
name varchar(30) not null,
sex enum('male','female') default 'male' not null,
hire_date date not null,
salary double(15,2) not null,
office int,
dep_id int
);
insert into com.emp(name,sex,hire_date,salary,office,dep_id) values
('jack','male','20180202',5000,501,100),
('tom','male','20180203',5500,501,100),
('robin','male','20180202',8000,501,100),
('alice','female','20180202',7200,501,100),
('tianyun','male','20180202',600,502,101),
('harry','male','20180202',6000,502,101),
('emma','female','20180206',20000,503,102);
select * from emp;
+----+---------+--------+------------+----------+--------+--------+
| id | name | sex | hire_date | salary | office | dep_id |
+----+---------+--------+------------+----------+--------+--------+
| 1 | jack | male | 2018-02-02 | 5000.00 | 501 | 100 |
| 2 | tom | male | 2018-02-03 | 5500.00 | 501 | 100 |
| 3 | robin | male | 2018-02-02 | 8000.00 | 501 | 100 |
| 4 | alice | female | 2018-02-02 | 7200.00 | 501 | 100 |
| 5 | tianyun | male | 2018-02-02 | 600.00 | 502 | 101 |
| 6 | harry | male | 2018-02-02 | 6000.00 | 502 | 101 |
| 7 | emma | female | 2018-02-06 | 20000.00 | 503 | 102 |
+----+---------+--------+------------+----------+--------+--------+语法:
select 字段1, 字段2, ...
from 表名
[where 条件]
[order by column_name [ASC | DESC]]
[limit 行数];1.通配符 *【慎用】
1.打印某表的所有记录
select * from 表名;
select * from emp;
2.查看表的特定字段的记录:
select 字段1, 字段2 from 表名;
select id, name, sex from emp;
3.添加 WHERE 子句,选择满足条件的行
select * from 表名 where 字段 = TRUE;
select * from emp where sex = "female";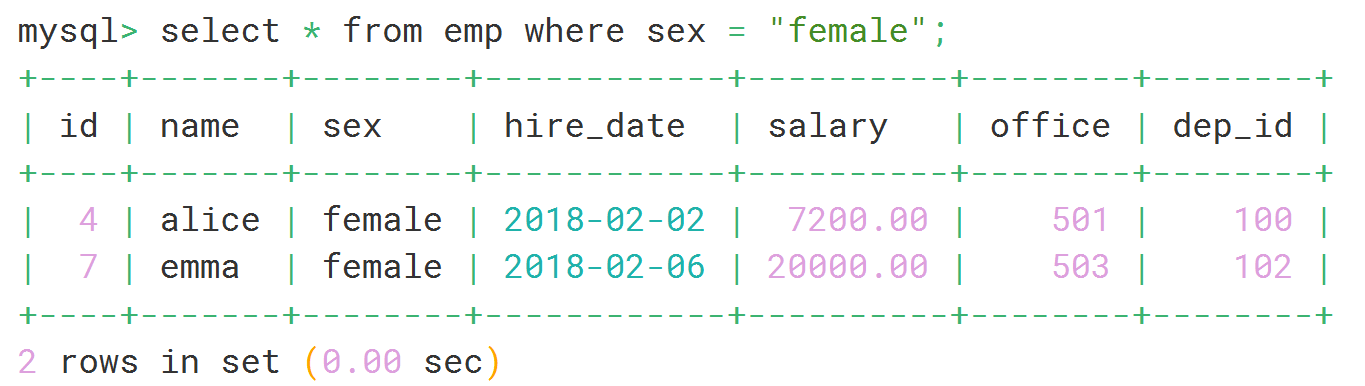
4.添加 ORDER BY 子句,按照 某字段 的升序排序
select * from 表名 order by 字段;
#添加 ORDER BY 子句,按照某列的降序排序
select * from 表名 order by 字段 DESC;
select * from emp order by salary;
select * from emp order by salary DESC;
5.添加 LIMIT 子句,限制返回的行数
select * from 表名 limit 10;
select * from emp limit 5;
2.条件运算符=, <, >, <=, >=, !=
select 字段1,字段2,...... from 表名 where salary > 1000;
select 字段1,字段2,...... from 表名 where salary < 1000;
select 字段1,字段2,...... from 表名 where id = 1001;
select 字段1,字段2,...... from 表名 where salary != 1000;3.逻辑运算符AND, OR, NOT,通配符%
OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
# 详细请看 【where】 数据查询
1.使用 AND 运算符或 &&
select 字段1,字段2,...... from 表名 where 字段1 like 'j%' AND 字段2 = TRUE;
2.使用 OR 运算符或 ||
select 字段1,字段2,...... from 表名 where 字段1 = TRUE OR 字段2 < '1990-01-01';
3. 使用 IN 子句
select 字段1,字段2,...... from 表名 where 字段 IN ('元素1', '元素2', '元素3');4.统计记录的数量:
select count(*) from 表名;
#
select count(*) from employee5;
5.统计字段得到数量:
select count(字段) from 表名;
#统计字段中的记录数量,不计算null值
select count(job_description) from employee5;
6.distinct:避免重复:对于表里面的数据有相同的,只列出一次:
select distinct 字段 from 表名;
select distinct post from employee5;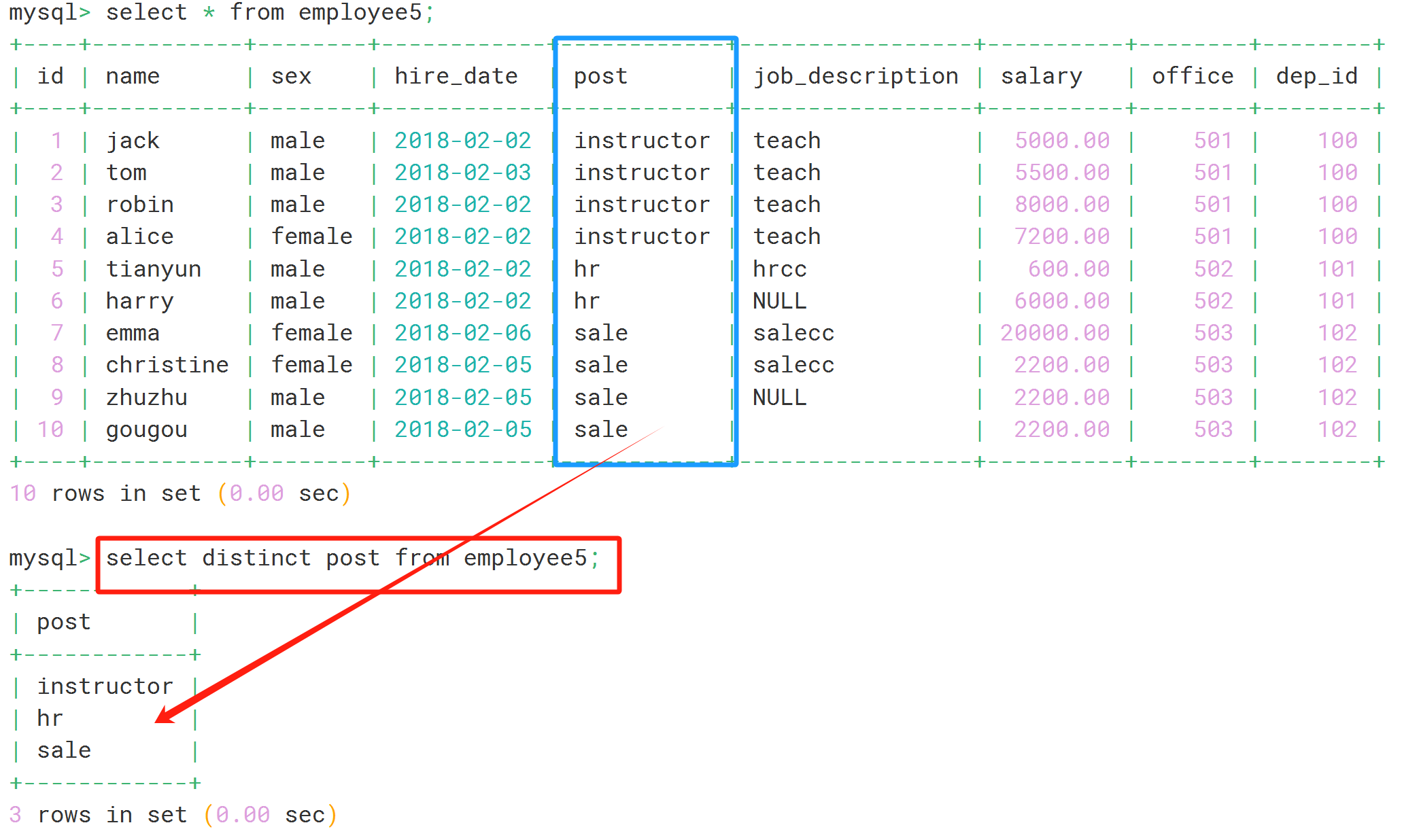
7.设置别名:as
select 字段1,字段2... as "别名" from 表名 where 条件;
#给 salary 的值起个别名,显示值的表头会是设置的别名
select id, name, salary as "salary_num" from emp where salary>=6000;
其他查询:
group by 分组查询
- group by 子句应出现在 SELECT 查询的 WHERE 子句之后和 order by 子句之前。
- SELECT 查询中的 字段 必须出现在 group by 子句中,或者是聚合函数的参数。
1.使用 group by 对单个列进行分组:
select count(*),字段1
from 表名 group by 字段1;
2.按多个列进行分组,每列都会成为分组的一部分:
select 字段1, 字段2, count(*)
from 表名 group by 字段1, 字段2;
3.计算字段1的平均工资
select 字段1, AVG(salary)
from 表名 group by 字段1;
4.获取字段1的最高工资
select 字段1, MAX(salary)
from 表名 group by 字段1;
#
select count(*),dep_id
from emp group by dep_id;
+----------+--------+
| count(*) | dep_id |
+----------+--------+
| 4 | 100 |
| 2 | 101 |
| 1 | 102 |
+----------+--------+
#
select sex, dep_id, count(*)
from emp group by sex, dep_id;
#
#查找 统计(条件:工资大于5000)的有几个人(count(name)),分别是谁(group_concat(name))
select count(name),group_concat(name)
from emp where salary>5000;
limit 分页查询
分页显示,就是将数据库中的结果集,一段一段显示出来需要的条件。
第一个“偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移 量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是 1,以此类推);第二个参数“行数”指示返回的记录条数。
select * from 表名 limit 行数;
select * from 表名 limit 行数,数量; #从第n+1开始,打印几行
select * from emp limit 3;
select * from emp limit 3,2;
#查询并排序
select * from emp
order by salary desc limit 0,5;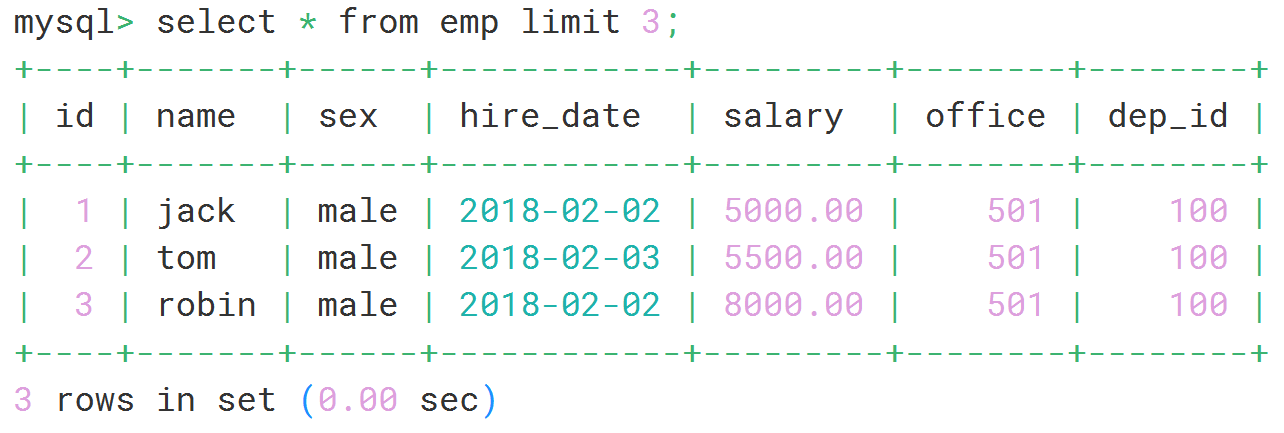
select * from 表名 limit 3 OFFSET 10;
# LIMIT 3 意味着你希望获取最多3条记录
# OFFSET 10 意味着你希望跳过前10条记录,从第11条记录开始计数。
select employee_id, last_name,salary
from employees
limit 3 OFFSET 10;
order by 排序查询
使用 order by 子句排序;ASC:升序;DESC:降序。order by子句在SELECT语句的结尾。在排序时,默认升序
1.默认从小到大排序。
select * from 表名
order by 字段;
#
select * from emp
order by salary; #-默认从小到大排序。
#
select * from emp
order by salary desc; #-降序,从大到小
2.多列排序
# 在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。
# 如果第 一列数据中所有值都是唯一的,将不再对第二列进行排序。
select *
from 表名
order by 字段1, 字段2 DESC;
#先按照salary递增排序,若salary相同,则按照hire_date逆序排序
select * from emp
order by salary, hire_date DESC;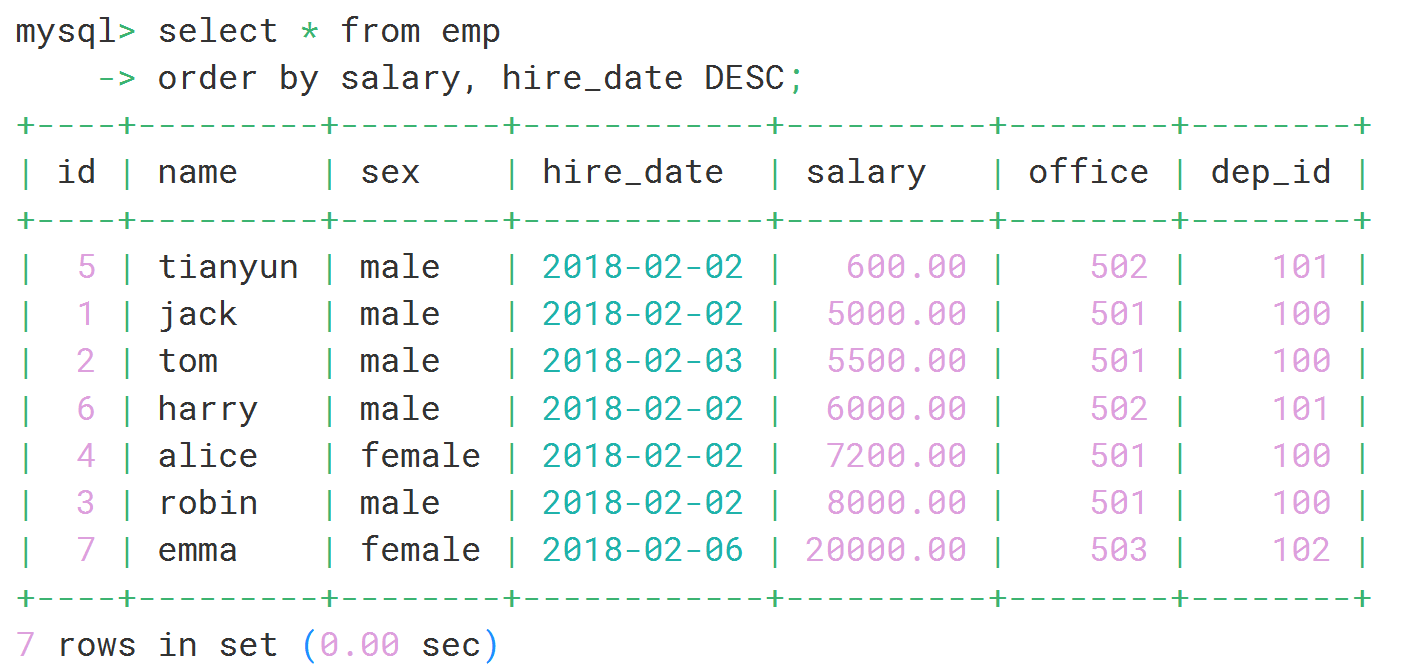
3.按别名排序
SELECT *,(salary * 0.1) AS "薪资" FROM emp
ORDER BY "薪资" ;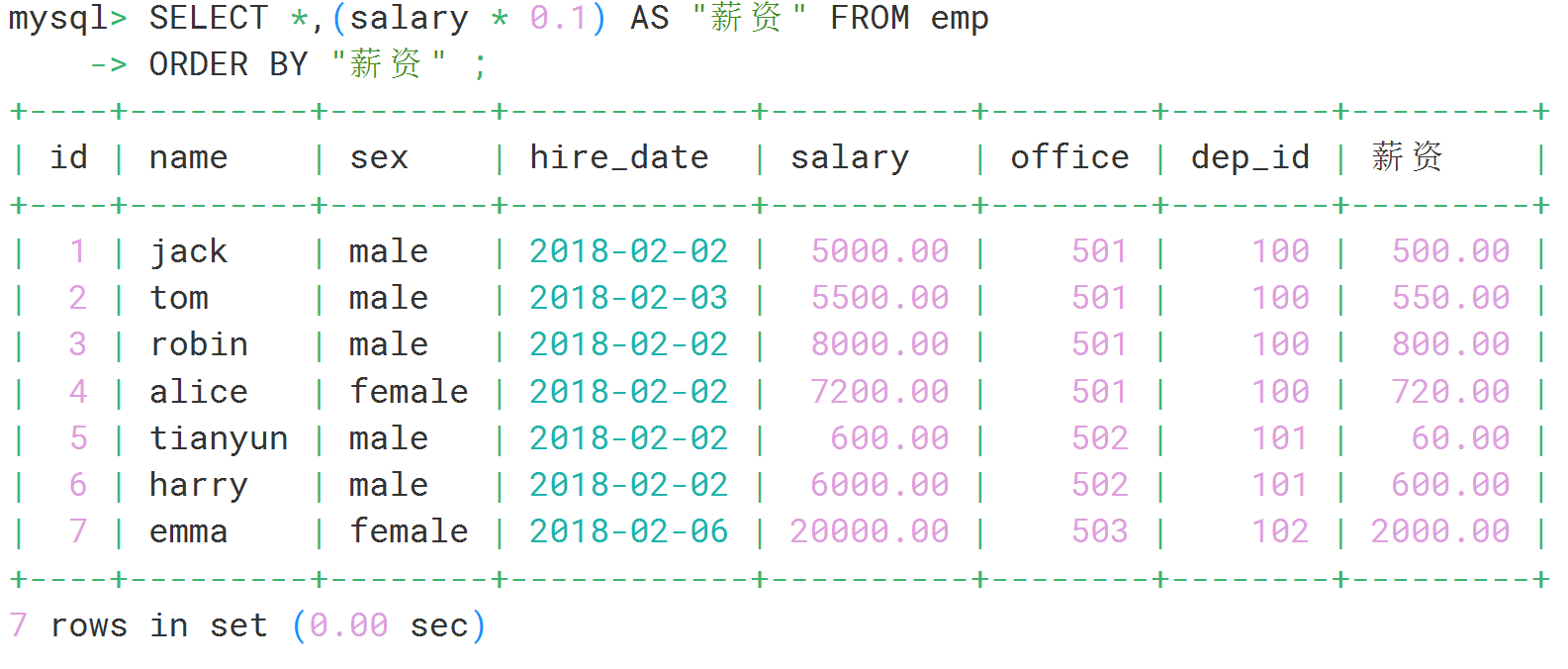
between A and B 范围查询
大于等于A,小于等于B时返回真,否则返回假。
select 字段,字段2 from 表名
where 字段 between A and B;
# not:给条件取反
select * FROM emp
where salary between 5000 and 8000;
#
select * FROM emp
where salary NOT between 5000 and 8000;
in 集合查询
IN运算符用于判断给定的值是否是IN列表中的一个值,如果是则返回1,否则返回0。如果给 定的值为NULL,或者IN列表中存在NULL,则结果为NULL。
select 字段1,字段2 from 表名
where 字段 in (记录1,记录2,记录3,......);
#
select* FROM emp
where salary in (4000,5000,6000,7000,8000,9000);
#
select* FROM emp
where salary not in (4000,5000,6000,7000,8000,9000);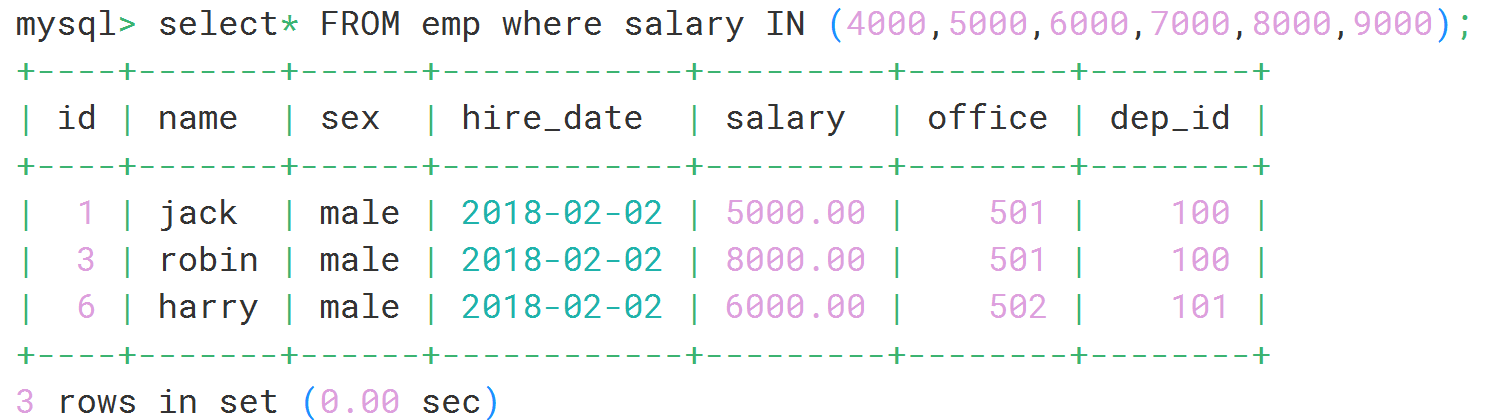
is null / is not null--空值/非空查询
select 字段,字段2 from 表名 where 字段 is null;
#取反:不为null
select 字段,字段2 from 表名 where 字段 is not null;
#
NULL说明:
1、等价于没有任何值、是未知数。
2、NULL与0、空字符串、空格都不同,NULL没有分配存储空间。
3、对空值做加、减、乘、除等运算操作,结果仍为空。
4、比较时使用关键字用“is null”和“is not null”。
5、排序时比其他数据都小(索引默认是降序排列,小→大),所以NULL值总是排在最前。注意:
SELECT employee_id,commission_pct FROM employees WHERE commission_pct = NULL;
在MySQL 5.7中,当你想匹配NULL值时,你使用IS NULL而不是等号=, 因为NULL表示未知,它不与任何值相等,包括它自己。
在 MySQL 8.0 中,处理 NULL 的逻辑与之前的版本相同。NULL 代表一个未知或缺失的值,并且不能使用等号(=)来检查,因为 NULL 不等于任何值,包括它自己。
多表查询数据
1.等值连接:
等值连接是指:使用等值条件将两个或多个表的相关联字段连接在一起,从而获取符合条件的数据。
select 别名1.字段1,...别名2.字段2,...
from 表1 别名1,表2 别名2
where 条件1 and 条件2;
# 查询员工的员工id、姓氏、部门名称、城市
select t1.employee_id, t1.last_name, t2.department_name, t3.city
from employees t1,departments t2,locations t3
where t1.department_id = t2.department_id
and t2.location_id = t3.location_id
and t1.last_name = "King";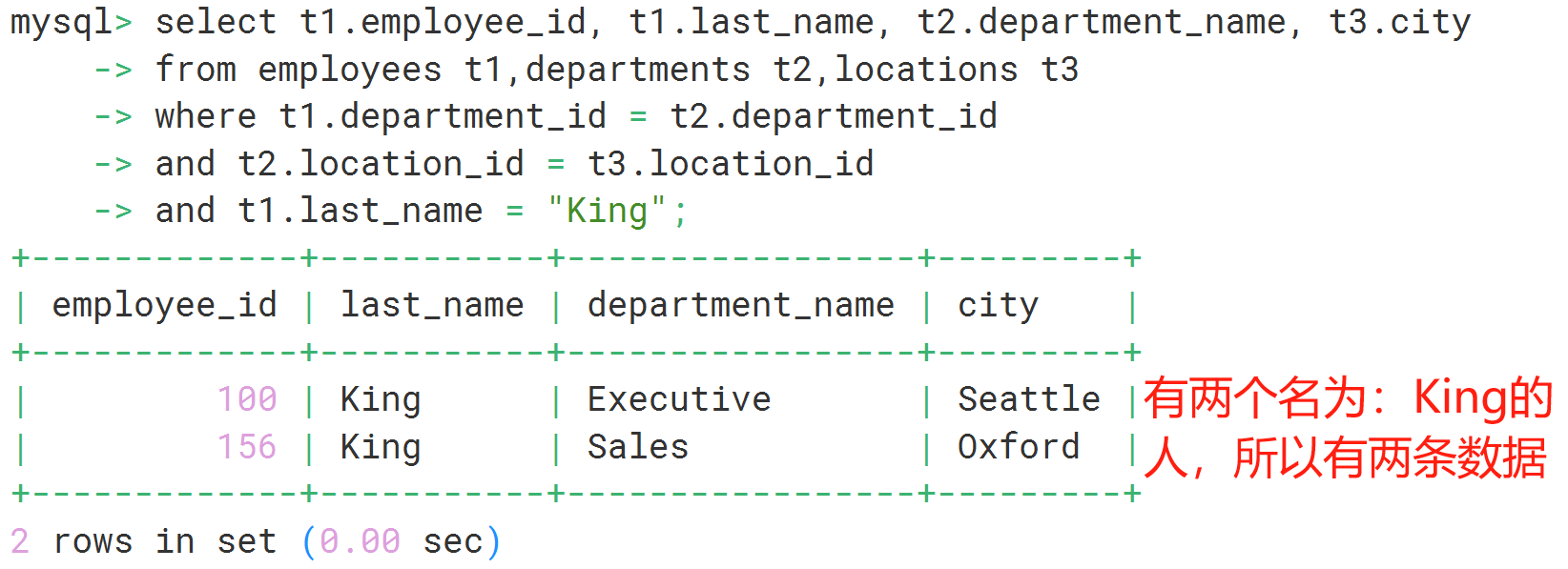
2.非等值连接【重点】
非等值连接是指使用非等值条件(如 <, >, <=, >=, != 等)将两个或多个表的相关联字段连接在一起,从而获取符合条件的数据。
select 别名1.字段1,...别名2.字段2,...
from 表1 别名1, 表2 别名2
where 别名1 between 字段2 and 字段3;
# 或
select 别名1.字段1,...别名2.字段2,...
from 表1 别名1, 表2 别名2
where 条件1 and 条件2;
# 查询每位员工的工资等级
select t1.last_name, t1.salary , t2.grade_level
from employees t1,job_grades t2
where t1.salary between t2.lowest_sal and t2.highest_sal;
#
select t1.last_name, t1.salary , t2.grade_level
from employees t1,job_grades t2
where t1.salary >= t2.lowest_sal and t1.salary <= t2.highest_sal;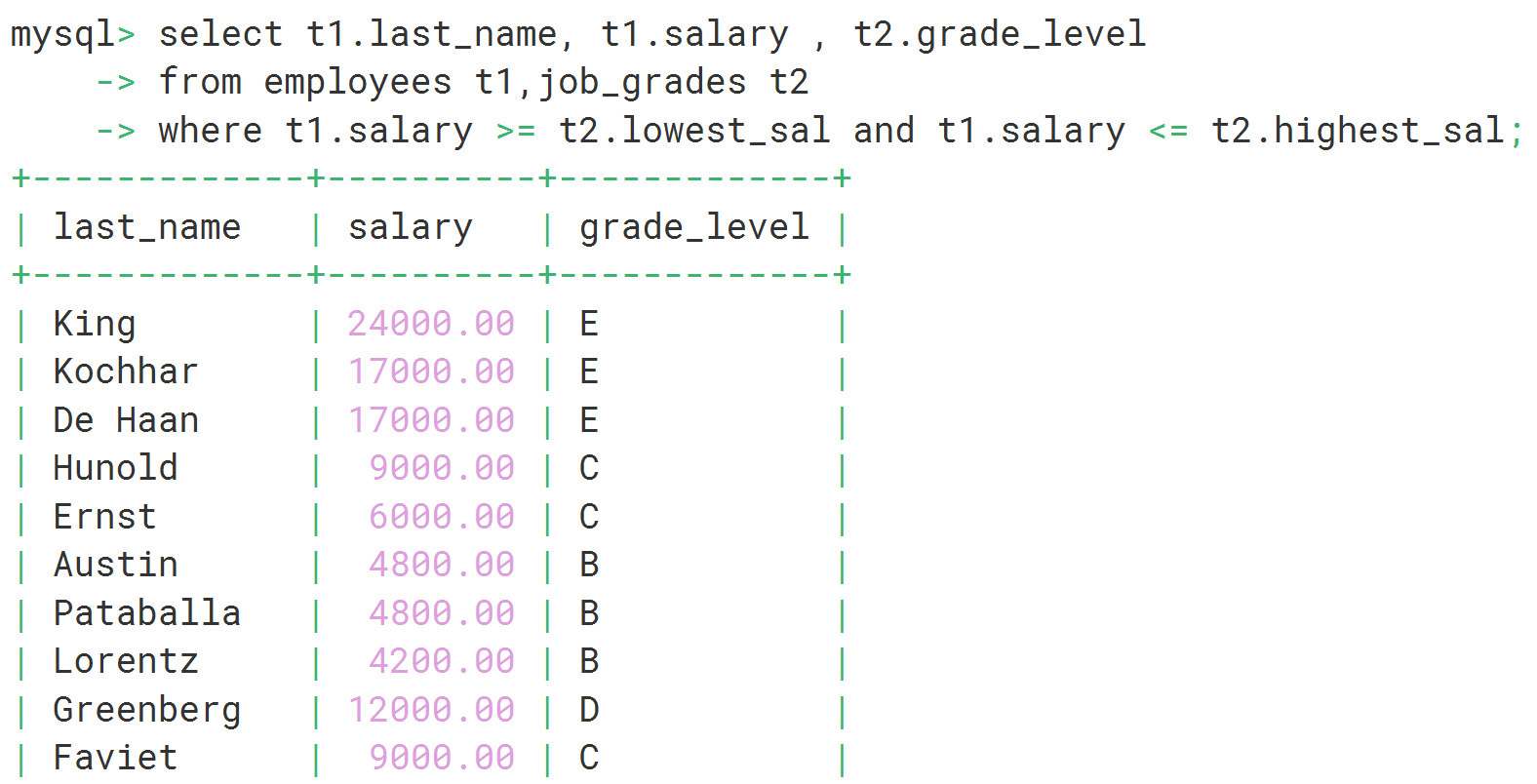
3.自连接
自连接是指在同一张表内进行连接查询,通常用于在表的不同行之间建立关系。这种连接可以使用表的别名来区分同一个表的不同实例。自连接在处理层次结构或关联关系的数据时非常有用。
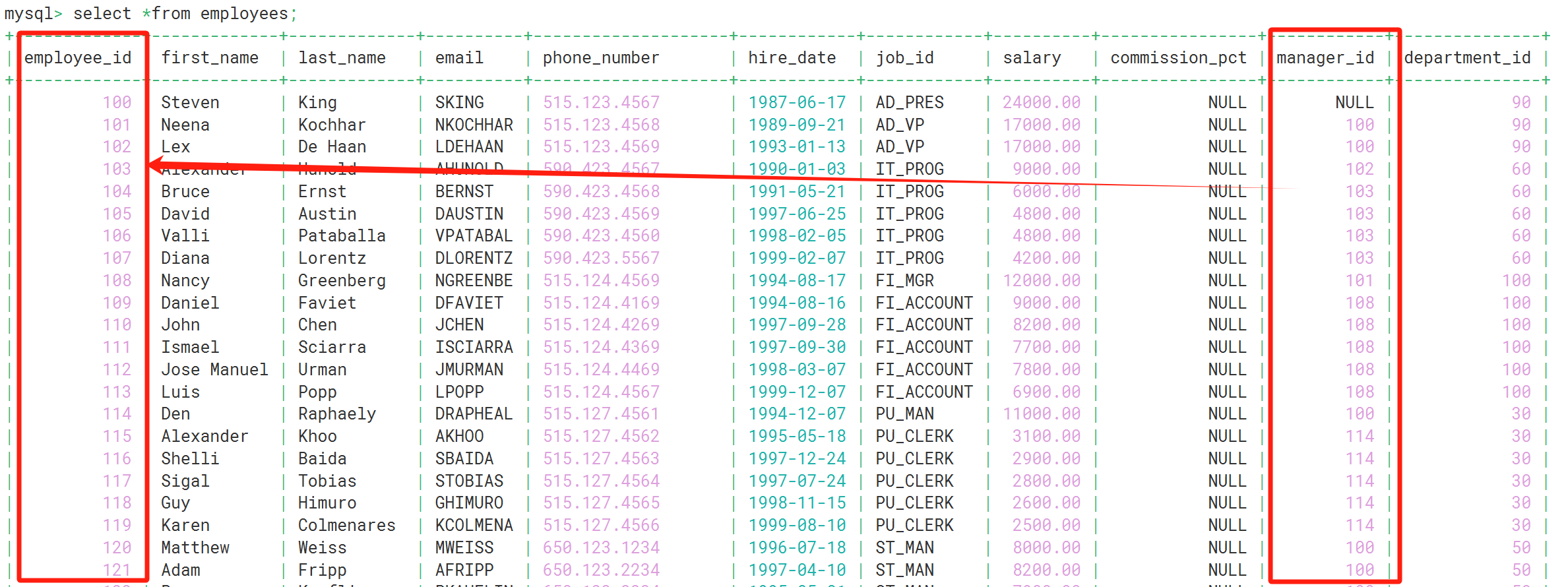
如上:每位员工都有一个对应的管理者:查询所有员工的管理者姓名
select t1.employee_id, t1.last_name as "员工姓名", t2.last_name as "管理者姓名" , t2.manager_id
from employees t1, employees t2
where t1.manager_id = t2.employee_id; --员工id与管理者id是相对应的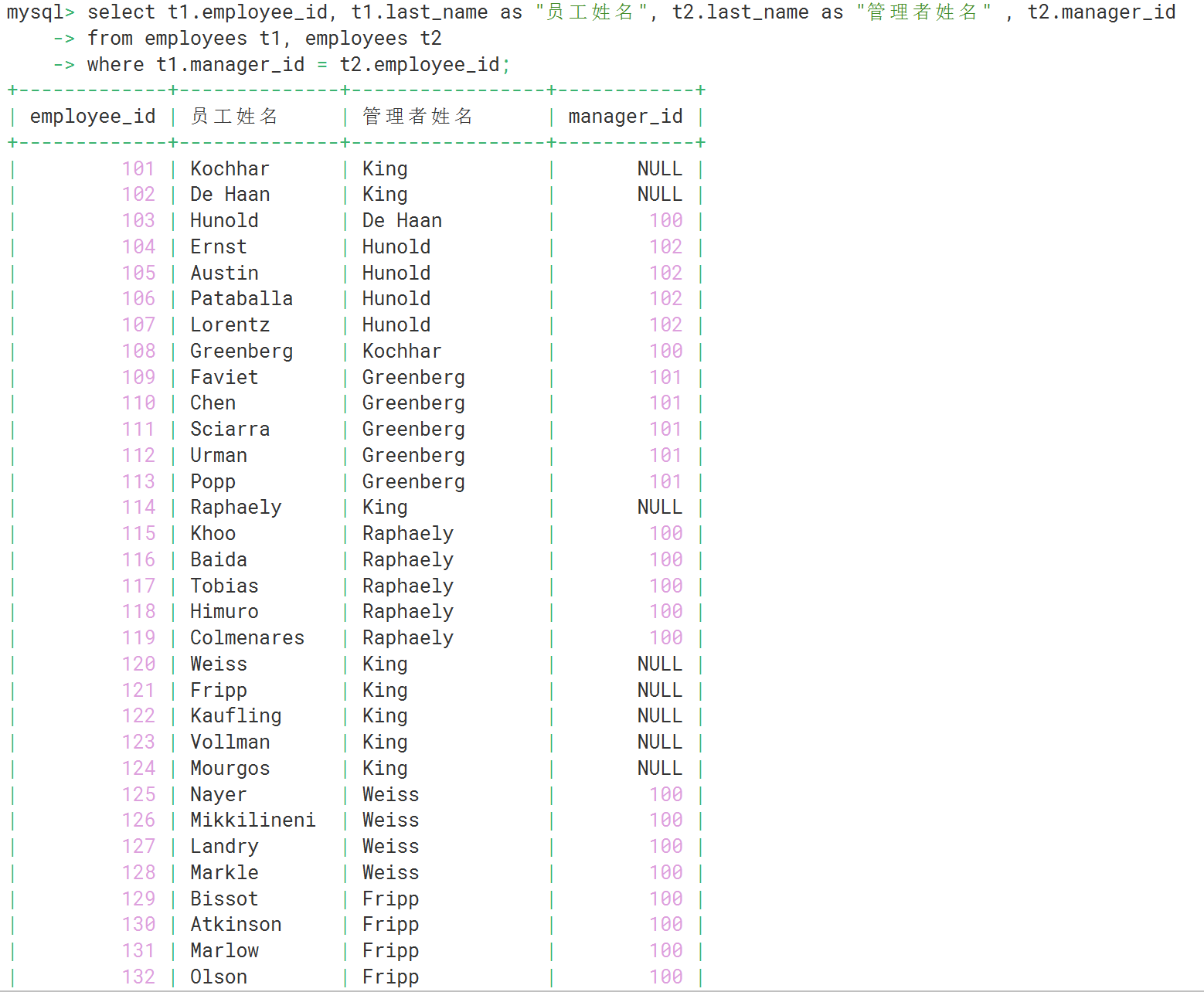















 3830
3830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









