







文章目录
ABSTRACT
(1)推特情感分析技术:目前的研究主要集中在通过分析词汇和句法特征来获取情感特征。这些特征通过情感词、表情符号、感叹号等明确表达。
(2)本文介绍了一种基于大型twitter语料库的无监督学习的词嵌入 方法,该方法利用tweet中潜在的上下文语义关系和词语间的贡献统计特征。这些词嵌入与n-grams特征(提取特征,得到特征向量)和单词情感极性得分特征相结合,形成了一组tweet情感特征集。该特征集被集成到一个深度卷积神经网络中,用于训练和预测情感分类标签。
(3)在五个Twitter数据集上实验比较了本文的模型与基线模型(一个单词n-grams模型)的性能,结果表明本文的模型在Twitter情感分类的准确性和F1测度方面表现更好。
INTRODUCTION
(1)阐述了推特情感分析的意义,目标是自动确定推特的情绪极性是负还是正。大多数现有的推特情感分类方法是应用机器学习算法从带有手动注释的情感极性标签的推特构建分类器,而深度学习技术可以提高分类精度
(2)首先,通过在大型Twitter语料库上进行无监督学习来学习单词表示的全局向量,该语料库将单词情感信息表示为单词嵌入。之后,将这些词表示与先前的极性得分特征和现有技术特征连接起来作为情感特征集。这些特征集被组合并馈入深度卷积神经网络,以训练和预测推特的情感分类标签。提出了一种称为GloVe-DCNN的模型,该模型实现了将推文分类为负面或正面情绪类别的二元任务。实验结果表明,该方法具有良好的分类性能。
(3)本文的其余部分组织如下。第二节讨论了本专题的相关工作。我们在第三节中提出了一种用于推特情感分类的GloVe-DCNN模型。实验过程如第四节所示。第五节讨论了实验结果。最后,第六节总结了本文。
RELATED WORK
(1)Twitter情感分析的大多数现有研究可分为监督方法和基于词典的方法。监督方法基于训练分类器(如朴素贝叶斯、支持向量机、随机森林),使用各种特征组合,如词性(POS)标记、词N-gram和推特上下文信息特征,如标签、表情符号、大写词等。基于词典的方法通过利用预先建立的单词词典,并根据其情感方向进行加权,确定给定文本的整体情感倾向,如SentiWordNet。这些方法依赖于明确表达情感信息的词汇或句法特征的存在。在很多情况下,推特的情感与上下文的语义隐含关联。在这项工作中,我们提出了情感分析的语义特征,即推文中一个词的词向量上下文表示,它可以捕获推文词中深层和隐含的语义关系信息。
(2)介绍深度学习方法在情感分类中的应用:
1、卷积神经网络,将潜在、密集和低维字向量(初始化为随机值)作为输入。使用动态卷积神经网络对电影评论和Twitter进行情感分类。实验表明,动态卷积神经网络优于n-grams模型
2、深度卷积神经网络,它利用从字符级到句子级的信息来实现短文本的情感分类。对于斯坦福Twitter情感语料库,该方法获得了86.4%的预测准确率。
3、研究了基于预训练词向量模型的卷积神经网络在句子级情感分类任务中的性能。在不同数据集上的实验表明,卷积神经网络可以提高分类性能。
4、将卷积神经网络应用于高维文本进行文本分类,并在情感分类的一些基准数据集上获得了一些最先进的性能
5、提出了一个类似4的模型,但交换了作为CNN输入的词的高维one-hot向量表示。他们的重点是对较长文本的分类
6、提出了一种使用神经网络自动获取单词情感信息表示的连续语音方法,构建微博文本情感特征向量
7、用于情感检测的递归神经张量网络,它通过词向量和解析树表示短语,然后使用相同的基于张量的合成函数计算树中较高节点的向量
DEEP CONVOLUTION NEURAL NETWORKS FOR SENTIMENT ANALYSIS(用于情感分析的深度卷积神经网络)
FEATURE REPRESENTATION(特征表示)
- 词N-grams特征
词N-grams特征模型是自然语言分析和Twitter情感分析中最简单有效的表示模型之一。一些研究表明,使用unigram模型,对Twitter数据进行情感分类具有最先进的性能。在本文中,我们使用unigram和bigram特征作为基线特征模型。
比如我们的训练文本数据是
I am a good kid
He is a good kid, but he didn't get along with his sister much
用Unigram模型会得到:
<i, am, a, good, kid, he, but, didnt, get, along, with, his, sister, much>
用Bigram模型会得到
<(i am), (am a), (a good), (good kid), (he is), (is a), (kid but), (but he), (he didnt), (didnt get), (get along), (along with), (with his), (his sister), (sister much)>
-
Twitter特有的特征:
标签、表情符号、否定、POS和大写单词。 -
词情感极性得分特征
词情感极度得分是基于词典的情感特征,一些方法通常将其用作推特情感分析的情感特征。我们使用AFINN词典,并使用SentiWordnet(情感词典)对其进行扩展,以获得推特情感极性得分。推文的情感极性得分是推文中每个词的情绪极性得分之和。每个词的情感得分是通过使用以下公式测量词与推文的负面或正面情感分类之间的PMI(点式互信息:衡量两个事物之间的相关性)来计算的:
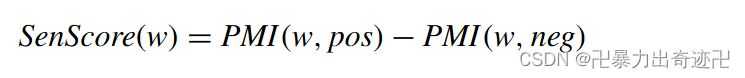
其中w是词典中的一个词,PMI(w,pos)是w和正类别之间的PMI得分,PMI(w,neg)是w和负类别之间的PMI得分。因此,正的SenScore(w)表示词w与积极情绪之间存在更强的关系,反之亦然。

-
词表示特征
从大量未标注文本语料库中学习词向量表示
大量语料库中的无监督学习的词向量表示可以捕获词的语法和语义特征。最近的研究表明,使用预训练的词嵌入可以显著提高模型的性能。在我们的研究中,我们使用GloVe模型来实现词嵌入的无监督学习。GloVe即词表示的全局向量。GloVe模型是一种全局对数双线性回归模型,结合了两个主要模型族的优点:局部上下文窗口和全局矩阵分解方法。该模型通过仅在词-词共现矩阵中训练非零元素,而不是在整个稀疏矩阵上或在大型语料库中的单个上下文窗口上,有效地利用了统计信息。该模型学习词向量时使用的是同现概率的比率,而不是概率本身。具体地说,假设我们对热力学相关的概念感兴趣,我们可以取wi=冰,wj=蒸汽。这些词的关系可以通过研究它们与各种探测词wk的共现概率的比率来检验。设Pij是词j出现在词wi的上下文中的概率。对于与冰有关但不与蒸汽有关的词k,比如wk=固体,我们预计比值Pik/Pjk将很大。类似地,对于与蒸汽而非冰相关的词wk,比如wk=气体,该比率应该很小。对于像水或时尚这样既与冰有关又与蒸汽有关,或者两者都不相关的词,比例应该接近1。因为同义词和相似段落通常具有相似的上下文,所以它们被映射到彼此接近的特征向量。
通过GloVe模型训练后,单词向量可以表示为推特的语义特征。这些向量可以作为推文的语义情感特征。这里使用200亿twitter语料库训练GloVe模型,并归纳出200维单词向量。未预先训练集的词作随机初始化
TWEETS PREPROCESSING(推文预处理)
推文通常由不完整的表达、各种噪音和结构不良的句子组成,因为首字母缩略词、不规则语法、格式错误的单词和非词典术语的频繁出现。噪声和非结构化推特数据将影响推特情感分类的性能。在特征选择之前,对推文进行了一系列预处理,以降低文本中的噪声
预处理是:
删除推文中的所有非ASCII和非英语字符
删除所有URL链接
删除数字
替换否定引用
将首字母缩略词和俚语扩展为完整的单词形式
删除停止词
替换表情符号
使用Tweet-NLP进行标记化(词性标注)
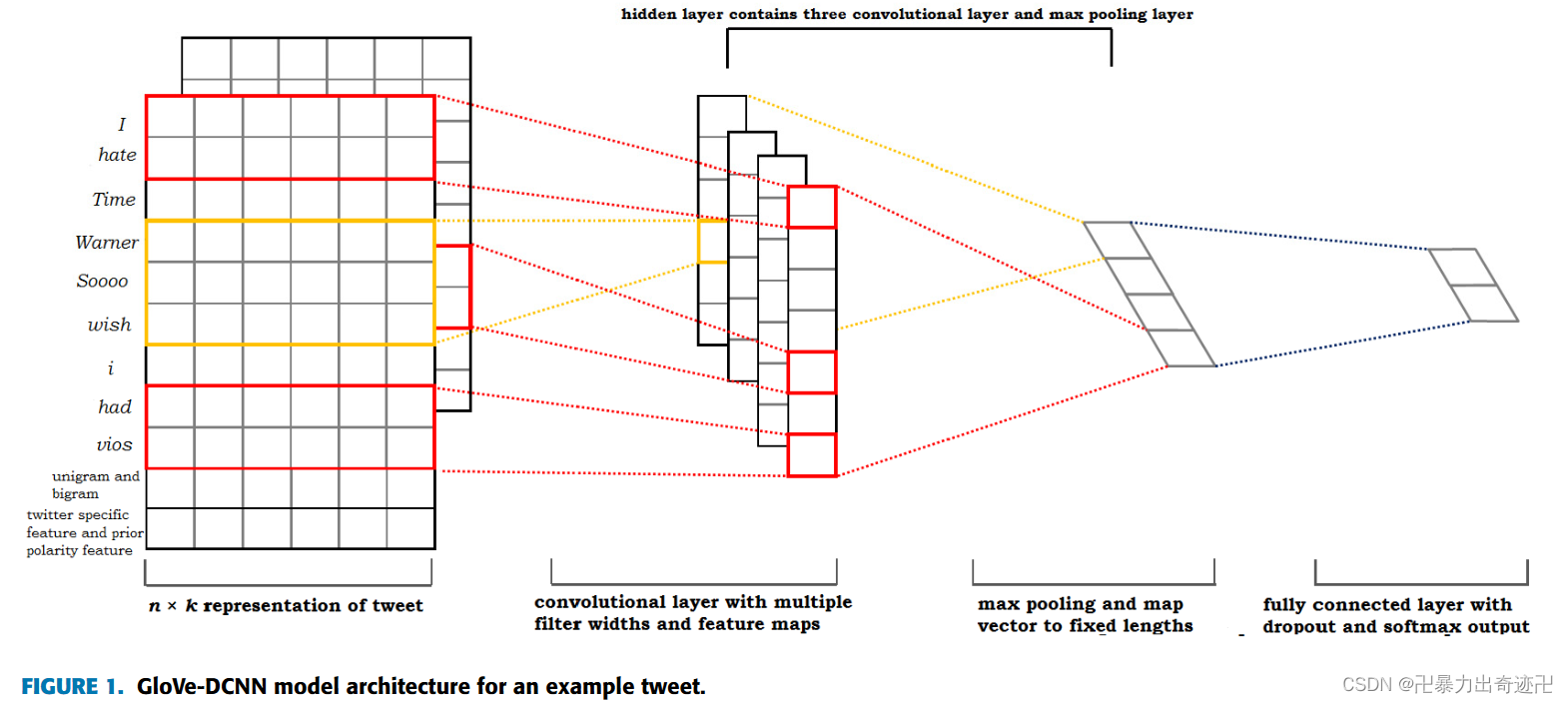
DEEP CONVOLUTION NEURAL NETWORKS MODEL
深度卷积神经网络模型,将推特分类为负面或正面情绪。以具有m个令牌的tweet t为例。首先,通过查找词向量表L,将tweet中的每个标记映射到相应的词向量∈ Rn×|V|由GloVe模型生成,其中V是单词的词汇表,n是单词向量的维数。每个词w都映射到向量wi∈ Rn。映射之后,tweet被表示为单词嵌入连接的向量。然后是单字和双字特征向量(unigram和bigram特征)、twitter特定特征向量和词情感极性特征向量可以与词嵌入向量串联,作为推特t的特征向量v。
计算公式为
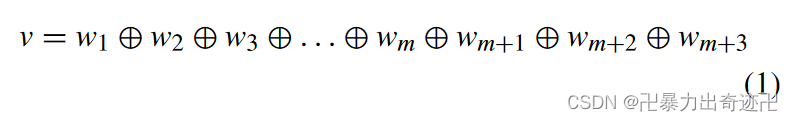
⊕ 是向量的级联运算符,wm+1∈ R是tweet t的词情感极性特征向量,wm+2∈ {0,1}l是tweet t,的单字和双字特征向量wm+3∈ Rl′是tweet t的twitter特定特征向量
为了统一不同长度tweet的矩阵表示,将数据集中所有tweet最大长度用作tweet矩阵的固定长度。对于较短的tweet,在tweet矩阵的后面填充零向量
在第一卷积层,使用具有可变窗口大小h的多个滤波器执行卷积计算,并为每个可能的词窗口大小生成局部情感特征向量xi。以及为每个滤波器生成偏置项b∈ R和转移矩阵W∈ Rhu×hn,其中hu是卷积层中隐藏单元的数量。每个卷积运算在字窗口h中生成一个新的上下文局部特征向量xi。
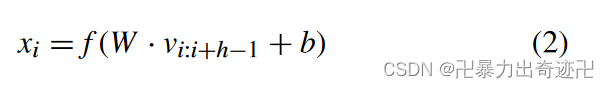
其中f是非线性主动函数,vi:i+h−1是从位置i到位置i+h-1的局部向量
卷积滤波器为推文中的每个可能的词窗口生成局部特征映射向量,然后完成卷积运算以生成新向量,该向量可以表示为:
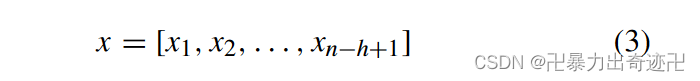
在卷积运算之后,对生成的新特征向量x采用K-Max池运算
K-Max池将向量x映射为固定长度向量。向量的长度是由用户确定的超参数,并且对应于卷积层中隐藏单元的数量。局部句子特征被集成到所有特征中。常用的池化操作是平均池化和k-max池化。在这项工作中,使用了k-max池。对于情感分类,最具决定性的词或短语通常只有几个,但并不是均匀地分散在整个文本中。k-max池只是一些最有区别的语言片段。
k-max池选择对应于多个隐藏层的前k个特征,以便可以保留最重要的情感特征信息。同时,单词序列和每个单词的上下文信息也在池操作中被考虑。这解决了传统方法无法表达推文中的负面词语并影响推文感情的问题。
数学表达式为
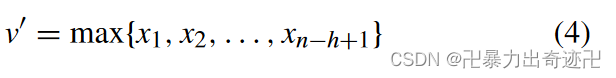
为了获得更好的特征信息,我们将k-max池生成的固定长度向量馈送到卷积层以再次获得新向量。在模型中,我们选择隐藏层包含三个卷积层和三个k-max池层。
架构的输出层是一个softmax层,它生成积极或消极情绪的概率值。输出层使用完全连接的softmax层来调整输入层的情感特征,并给出情感分类标签的概率分布。
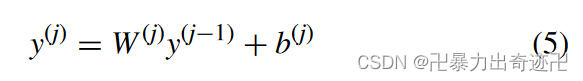
其中y(j)是softmax层的输出向量,y(j−1) 是池层的输出向量,W(j)是softmax层的转移矩阵,b(j)为softmax层偏置因子。情绪标签上的概率分布为:
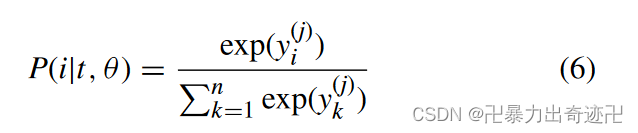
由于需要学习大量的超参数,卷积神经网络的深度存在过拟合问题。我们对完全连通的层应用了丢弃正则化(随机的丢弃一些单元),以消除大量隐藏单元和它们之间的连接的问题。
EXPERIMENT
在五个不同的数据集上测试网络
BASELINE
为了给深度卷积神经网络(DCNN)结果提供参考点,我们使用两种方法作为基线。首先,我们使用RBF核支持向量机和逻辑回归(LR),利用unigram和bigram特征。结合形成Bow-SVM和Bow-LR。然后,我们还尝试将unigram、bigram、词情感极性特征、twitter特定特征和词向量特征与RBF核支持向量机和逻辑回归分类器(得到的是GloVe-SVM与GloVe-LR)相结合。
DATASETS
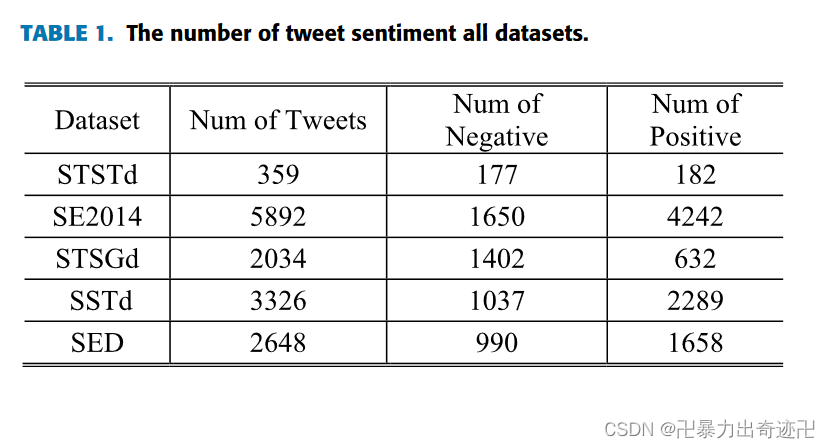
使用了在相关Twitter情感分类文献中广泛应用的五个数据集,分别是:
(1)斯坦福推特情绪测试(STSTd)数据集,由182条正面和177条负面情绪推文组成
(2)SE2014数据集,数据集包含tweet ID及其相应的情绪标签,这些标签已被注释为正、负和中性
(3)斯坦福推特情绪黄金(STSGd)数据集,包含2034条推文,标注了负面或正面情绪标签
(4)情绪评估数据集(SED),它由990条负面和1658条正面情绪推文组成
(5)情感强度推特数据集(SSTd),它包含1037条负面和2289条正面情绪推文
表1显示了每个数据集中正面和负面推特的分布。
EXPERIMENTAL SETUP
在本文中,我们对每个数据集应用10倍交叉验证。对于所有数据集,应用相同的预处理步骤。对于每个实验,我们在训练集上训练卷积神经网络,并在验证集中获得最高精度点,并报告测试集的精度。我们对每个数据集重复了100次交叉验证实验,因此每次重复都是10倍的交叉验证。我们记录了每个复制的平均性能,并报告了在交叉验证的100次复制中观察到的平均精度值。最后,我们使用五组实验的准确度、F1度量、准确度和召回率的平均值作为每个数据集的最终评估指标。在实验中,我们将批量大小设置为128,学习率设置为0.001。在网络中的完全连接层上应用了具有0.5的退出率的正则化。我们用不同的过滤窗口组合进行测试,显示过滤窗口7是一个合适的组合。在实验中,我们发现激活函数双曲ReLu对于卷积层的性能优于校正线性单元。
EXPERIMENTAL RESULTS
实验评估指标是正推特和负推特分类中的准确率和准确率、召回率、F1测量的平均值。
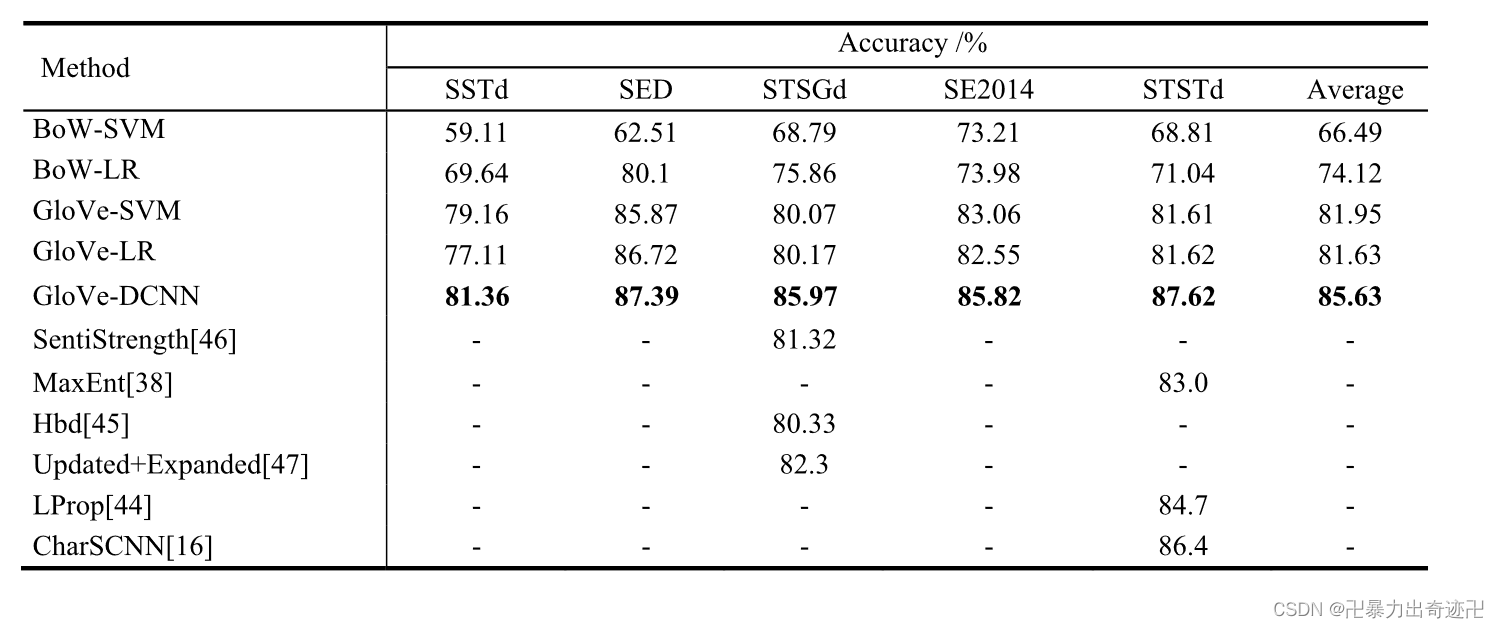
表2报告了所有数据集上情绪预测的准确性。最高准确率为87.62%,这是在STSTd数据集上使用GloVe-DCNN实现的。从平均值来看,GloVe-DCNN实现了19.14%的最大精度改进,与基线方法相比,3.68%的最小改进。从表2可以看出,GloVe-DCNN模型比基线方法具有更好的性能。在表2中,我们比较了GloVe-DCNN方法与相关文献中提出的方法的性能。GloVe-DCNN在预测精度上优于先前的方法。
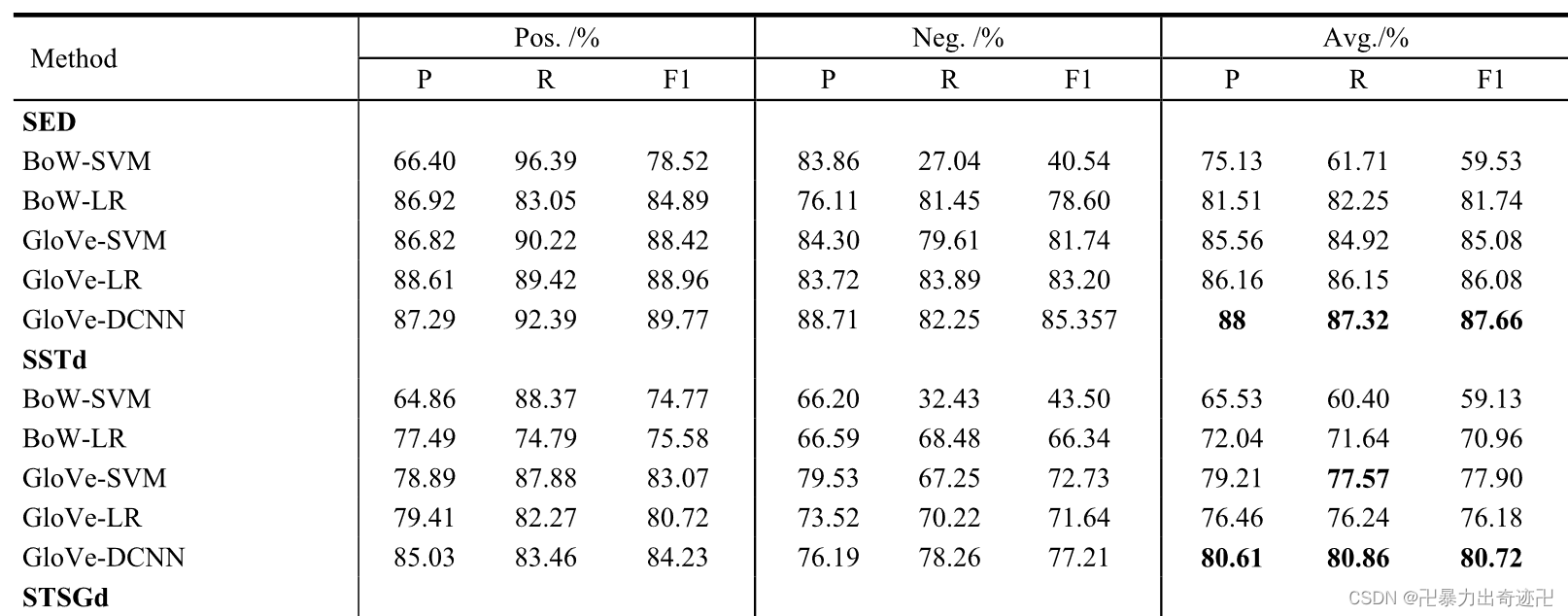
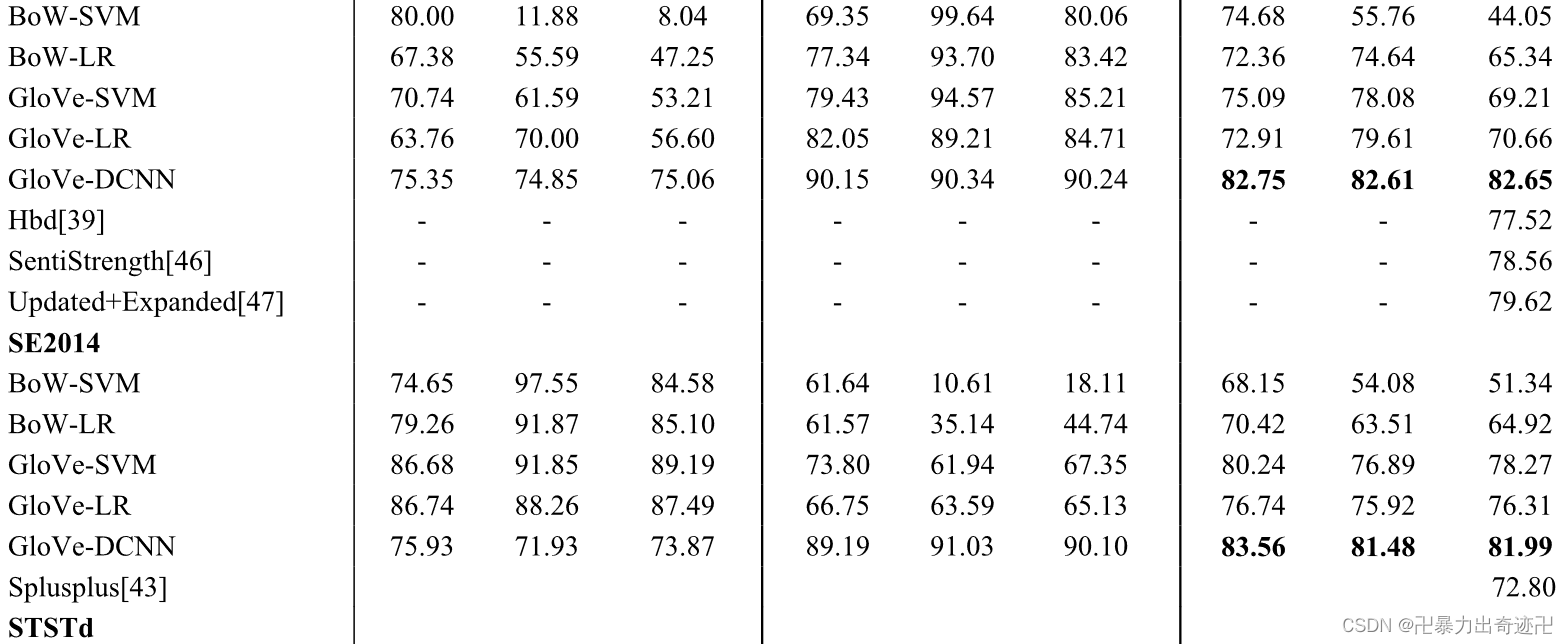
在表3中,我们给出了基线和GloVe-DCNN模型的正面和负面情绪预测性能的精度(P)、召回率(R)和F1测量(F1)结果。在该表中,可以观察到,GloVe-DCNN在平均精度、召回率和F1测量方面比基线表现更好。与文献提出的其他方法相比,GloVe-DCNN方法分别在STSGd和SE2014数据集上的F1平均值方面优于其他方法。

DISCUSSION
实验结果清楚地表明,GloVe-DCNN模型可以获得良好的情感分类性能。将深度卷积神经网络和基线方法用于Twitter情感分类算法进行比较,结果表明,深度卷积网络在五个数据集上具有明显的优势。这表明深度卷积神经网络可以有效地构造文本语义。与使用BoW模型的SVM分类器相比,卷积神经网络可以更有效地捕捉tweet中的上下文情感信息,保留词序信息,并减少数据稀疏问题。卷积神经网络直接从文本中建模上下文情感特征,并有效地选择推文中最重要的特征。它避免了错误传播,提高了分类性能。通过在Twitter语料库上学习预训练的词向量表示可以更好地描述Twitter中词之间的相似性,并提取推特中词之间隐含的语义关系和情感特征信息。
CONCLUSION
在这项工作中,我们利用深度卷积神经网络对Twitter上的情感进行分类。我们的方法将基于 GloVe 词情感极性特征的情感词典和n-grams特征作为tweet的情感特征向量生成的预训练 word embedding 特征连接起来,并将特征集输入到深度卷积神经网络。我们的模型捕获具有循环结构的上下文信息,并使用卷积神经网络构造文本的表示。我们在五个数据集中报告了我们的实验结果。我们的模型比最先进的方法和基线模型表现得更好。我们最终可以得出结论,利用预先训练的词向量的深度卷积神经网络在Twitter情感分析任务中具有良好的性能。















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









