







实施原子操作(atomicoperation)的函数,简称为原子函数。
在CUDA中,一个线程的原子操作可以在不受其他线程的任何操作的影响下完成对某个(全局内存或共享内存中的)数据的一套“读-改-写”操作。 该套操作也可以说是不可分的。
1.完全在GPU中进行归约
在之前的数组归约函数中,核函数并没有做全部的计算,而只是将一个长 一些的数组d_x变成了一个短一些的数组d_y,后者中的每个元素为前者中若干元素的和。 在调用核函数之后,将短一些的数组复制到主机,然后在主机中完成了余下的求和。所有 这些操作所用时间约为5.8ms(单精度的情形)。如果用nvprof进行测试,会发现以上几个 版本的核函数所用时间都约为3.2ms,大概只有全部时间的一半。如果能在GPU中计算出 最终结果,则有望显著地减少整体的计算时间,提升程序性能。有两种方法能够在GPU中 得到最终结果,一是用另一个核函数将较短的数组进一步归约,得到最终的结果(一个数值);二是在先前的核函数的末尾利用原子函数进行归约,直接得到最终结果。
1.使用原子函数进行归约
if (tid == 0)
{
d_y[bid] = s_y[0];
}这个if 语句块的作用是将每一个线程块中归约的结果从共享内存s_y[0]复制到全局内 存d_y[bid]。为了将不同线程块的部分和s_y[0]累加起来,存放到一个全局内存地址,我 们尝试将上述代码改写如下:
if (tid == 0)
{
d_y[0] += s_y[0];
}遗憾的是,该语句不能实现我们的目的。该语句在每一个线程块的第0号线程都会被执行, 但是它们执行的次序是不确定的。在每一个线程中,该语句其实可以分解为两个操作:首先从d_y[0]中取数据并与s_y[0]相加,然后将结果写入d_y[0]。不管次序如何,只有当 一个线程的“读-写”操作不被其他线程干扰时,才能得到正确的结果。如果一个线程还未将结果写入d_y[0],另一个线程就读取了d_y[0],那么这两个线程读取的d_y[0]就是一 样的,这必将导致错误的结果。考虑bid为0和1的两个线程块中的0号线程,它们都将 执行如下计算:
d_y[0] += s_y[0]假如bid为0的线程先读取d_y[0]的值,然后计算d_y[0] + s_y[0],得到了一个数,但是当它还没有来得及将结果写入d_y[0]时,bid为1的线程也读取了d_y[0]的值。不管是哪个线程先将计算结果写入d_y[0],d_y[0]的值都不是正确的。要得到所有线程块中 的s_y[0]的和,必须使用原子函数,其用法如下:
if (tid == 0){
atomicAdd(&d_y[0],s_y[0]);
}原子函数atomicAdd(address, val)的第一个参数是待累加变量的地址address,第二个 参数是累加的值val。该函数的作用是将地址address中的旧值old读出,计算old + val, 然后将计算的值存入地址address。这些操作在一次原子事务(atomictransaction)中完成, 不会被别的线程中的原子操作所干扰。原子函数不能保证各个线程的执行具有特定的次序, 但是能够保证每个线程的操作一气呵成,不被其他线程干扰,所以能够保证得到正确的结 果。注意,这里的if语句可保证每个线程块的数据s_y[0]只累加一次。去掉这个if语句 将使得最终输出的结果放大128倍。另外要注意的是,原子函数atomicAdd的第一个参数 是待累加变量的指针,所以可以将&d_y[0]写成d_y。
if (tid == 0){
atomicAdd(d_y,s_y[0]);
}最后要注意的是,在调用该版本的核函数之前,必须将d_y[0]的值初始化为0。在本 章程序reduce.cu中,我们用如Listing9.1所示的“包装函数”对核函数进行调用并做相应的前处理与后处理工作。读者应该能理解该函数中的代码。有两点值得注意:
•这里的主机数组h_y使用的是栈(stack)内存,而不是堆(heap)内存。也就是说,传 给cudaMemcpy函数的主机内存可以是栈内存。在传输少量数据时可以这样做;但在 传输大量数据时这样做不安全,因为栈的大小是很有限的。
•“包装函数”与核函数同名(都是reduce),这是使用了C++中函数的重载(overload) 特性:两个函数可以同名,只要它们的参数列表不完全一致即可。
#include "error.cuh"
#include <stdio.h>
#include "cuda_runtime.h"
#include <cuda.h>
#include "device_launch_parameters.h"
#include<math.h>
typedef float real;
const int NUM_REPEATS = 100; //程序运行次数
const int N = 1000; //数据个数
const int M = sizeof(real) * N; //数据大小
const int BLOCK_SIZE = 128; //块的大小
void timing(const real* d_x);
int main(void) {
//主机变量初始化
real* h_x = (real*)malloc(M);
for (int n = 0; n < N; ++n) {
h_x[n] = 1.23;
}
//设备变量初始化
real* d_x;
CHECK(cudaMalloc(&d_x, M));
CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice));
//核函数运行
printf("\n using atomicAdd :\n");
timing(d_x);
//释放空间
free(h_x);
CHECK(cudaFree(d_x));
return 0;
}
void __global__ reduce(const real* d_x, real* d_y, const int N) {
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
//动态共享内存
extern __shared__ real s_y[];
s_y[tid] = (n < N) ? d_x[n] : 0.0;
__syncthreads();
//折半归约
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
//归约完使用原子操作对最后结果累加。
if (tid == 0) {
atomicAdd(d_y, s_y[0]);
}
}
real reduce(const real* d_x)
{
const int grid_size = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
const int smem = sizeof(real) * BLOCK_SIZE;
real h_y[1] = { 0 }; //初始化
real* d_y;
CHECK(cudaMalloc(&d_y, sizeof(real)));
CHECK(cudaMemcpy(d_y, h_y, sizeof(real), cudaMemcpyHostToDevice));
reduce << <grid_size, BLOCK_SIZE, smem >> > (d_x, d_y, N);
CHECK(cudaMemcpy(h_y, d_y, sizeof(real), cudaMemcpyDeviceToHost));
CHECK(cudaFree(d_y));
return h_y[0];
}
void timing(const real* d_x)
{
real sum = 0;
for (int repeat = 0; repeat < NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
sum = reduce(d_x);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
printf("sum = %f.\n", sum);
}
在win上跑很容易出问题,之前的__sycnthreads();函数未声明,现在这个atomicAdd()函数也未声明。
虽然能跑,但是有个问题,只能在float情况下跑,double就会报错,有懂得大佬请教。
而且float类型跑出来的结果也差好多。
(一下是GPT解释)
在许多编程语言和操作系统中,原子操作通常是设计用来处理整数类型的数据,例如整数(int)或长整数(long)。原子操作的目的是确保多个线程或进程可以在没有竞争条件(race condition)的情况下同时访问和修改共享的数据,从而防止数据损坏或不一致。
对于浮点数类型,例如double,通常不建议使用原子操作,因为浮点数运算通常涉及到多个字节的数据,而原子操作通常是设计用来处理固定大小的数据单元(通常是字节、字或字长)。此外,浮点数操作可能不是原子的,因为它们通常需要多个CPU指令来执行,这可能导致竞争条件。
如果你需要在多线程环境下处理浮点数数据,通常更好的方法是使用锁或其他同步机制来确保线程之间的安全访问。这样可以避免竞争条件,并确保数据的完整性。不过需要注意,锁和同步机制会引入一定的开销,因此需要权衡性能和数据一致性的需求。
总之,一般情况下,浮点数类型的数据不适合用于原子操作,而应该使用其他同步方法来确保多线程环境下的数据一致性。
2.原子函数
原子函数对它的第一个参数指向的数据进行一次“读-改-写”的原子操作,即一气呵 成、不可分割的操作。第一个参数可以指向全局内存,也可以指向共享内存。对所有参与的 线程来说,该“读-改-写”的原子操作是一个线程一个线程轮流做的,但没有明确的次序。 另外,原子函数没有同步功能。
从帕斯卡架构开始,在原来的原子函数的基础上引入了两类新的原子函数。例 如,对原子函数 atomicAdd 来说,从帕斯卡架构起引入了另外两个原子函数,分别 是atomicAdd_system 和 atomicAdd_block,前者将原子函数的作用范围扩展到整个同节 点的异构系统(包括主机和所有设备),后者将原子函数的作用范围缩小至一个线程块。
下面,我们列出所有原子函数的原型,并介绍它们的功能。我们约定,对每一个线程 来说,address 所指变量的值在实施与该线程对应的原子函数前为old,在实施与该线程 对应的原子函数后为new。对每一个原子函数来说,返回值都是old。另外要注意的是,这 里介绍的原子函数都是__device__函数,只能在核函数中使用。
加法 T atomicAdd(T *address,T val);
功能 new = old + val;
减法 T atomicSub(T *address,T val);
功能 new = old - val;
交换 T atomicExch(T *address,T val);
功能 new = val;
最小值 T atomicMin(T *address,T val);
功能 new = (old < val) ? old : val;
最大值 T atomicMax(T *address,T val);
功能 new = (old < val) ? old : val;
自增 T atomicInc(T *address,T val);
功能 new = (old >= val) ? 0 : (old + 1);
自减 T atomicDec(T *address,T val);
功能 new = ((old == 0) || ( old > val )) ? val : ( old - 1 );
比较-交换 T atomicCAS(T *address,T compare,T val);
功能 new = (old == compare) ? val : old;
按位与 T atomicAnd(T *address,T val);
功能 new = old & val;
按位或 T atomicOr(T *address,T val);
功能 new = old | val;
按位异或 T atomicXor(T *address,T val);
功能 new = old ^ val;
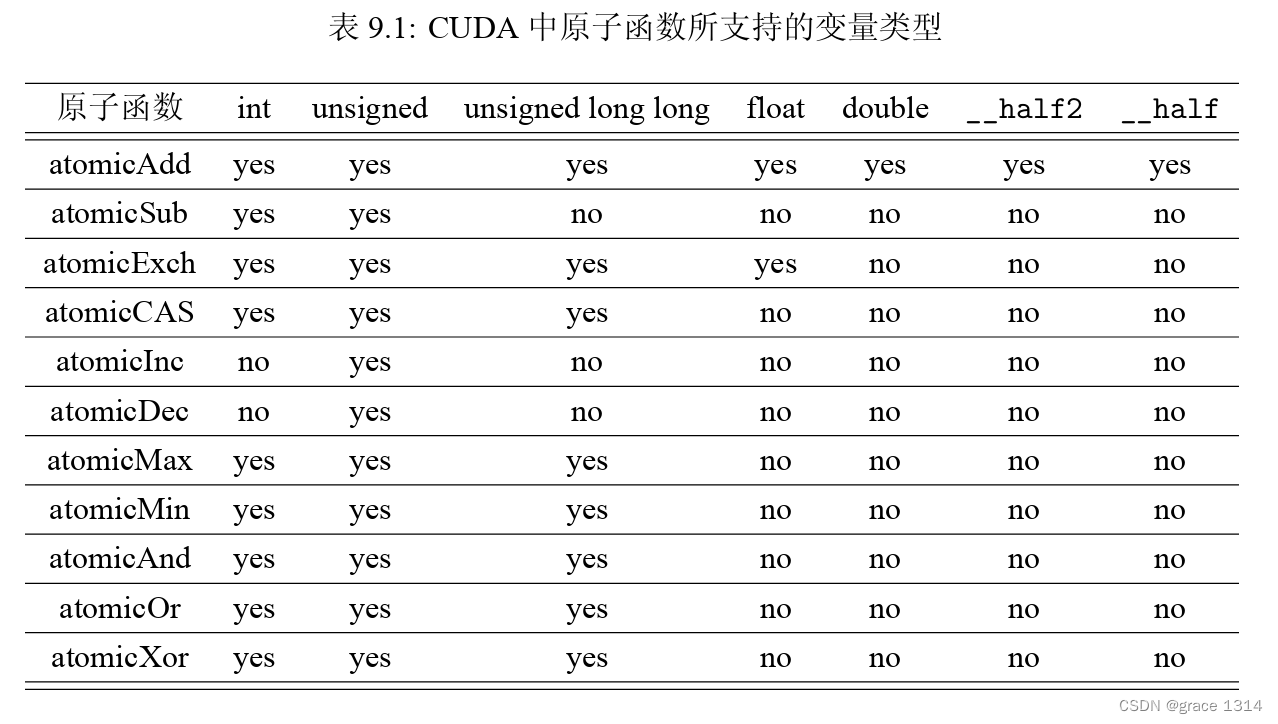
在上面所列函数中,我们用T表示相关变量的数据类型。各个原子函数对数据类型的支 持情况见表9.1。可以看出,atomicAdd对数据类型的支持是最全面的。其中,atomicAdd对 双精度浮点数类型double的支持始于帕斯卡架构,对含有两个半精度浮点数变量的结构 类型__half2的支持也始于帕斯卡架构(实际上始于计算能力5.2,但没有在CUDA运行 时API中展现),对半精度浮点数类型__half的支持始于伏特架构。
在所有原子函数中,atomicCAS函数是比较特殊的:所有其他原子函数都可以用它实现。 例如,在帕斯卡架构出现以前,atomicAdd函数不支持双精度浮点数,就有人用atomicCAS函 数自己实现一个支持双精度浮点数的atomicAdd函数,该实现来自于《CUDAC++Program mingGuide》,见Listing9.2。我们不对该实现进行讲解,但值得强调的是,该实现比帕斯卡 及更高架构提供的atomicAdd函数要慢得多。所以,在帕斯卡及更高架构的GPU中,绝对 不要使用该实现。即使在开普勒和麦克斯韦架构的GPU中,也要尽量避免使用该实现,而 考虑直接用单精度版本的atomicAdd函数(如果可以接受的话)或者通过改变算法避免使 用原子函数。
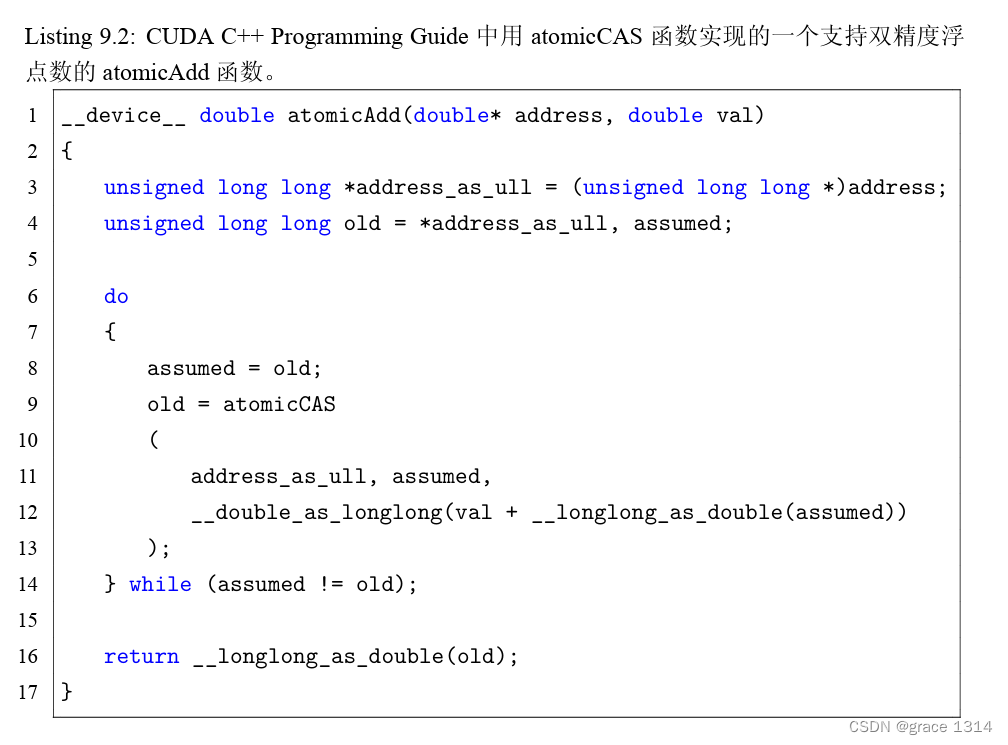
大概就是将原始类型转成longlong计算,最后转为double。
3.例子:邻居列表的建立
在系统介绍了CUDA中的原子函数之后,我们用一个建立邻居列表(neighborlist)的 例子进一步说明原子函数的使用。许多计算机模拟都用到了邻居列表,如分子动力学模拟 (moleculardynamicssimulation)和蒙特卡罗模拟(MonteCarlosimulation)。
现有一组粒子的坐标,给定个粒子的坐标ri,如何确定每个粒子的邻居个数及每个邻居的粒子指标呢?其 中,两个粒子互为邻居的判据是:它们的距离小于或等于一个给定的截断距离c。
包含全部坐标数据 的文本文件xy.txt,在https://github.com/brucefan1983/CUDA-Programming/tree/master/src/09-atomic
以及matlab绘制脚本plot_points.m也在其中。
我们的基本算法是:对每一个给定的粒子,通过比较它与所有其他粒子的距离来判断相 应的粒子对是否互为邻居。这是一个计算量正比于粒子数平方N^2的算法,或者O(N^2)算法。
这里给出的代码有两个,C++代码和CUDA版本的。
C++代码是这样的,做了一些注释自己看。
#include "error.cuh"
#include <cmath>
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <vector>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
int N; // 总原子数
const int NUM_REPEATS = 20; //循环次数
const int MN = 10; //每个原子的最大邻居数
const real cutoff = 1.9; // 阶段距离
const real cutoff_square = cutoff * cutoff; //判断两个原子是否为邻居的截断距离平方
void read_xy(std::vector<real>& x, std::vector<real>& y);
void timing(int* NN, int* NL, std::vector<real> x, std::vector<real> y);
void print_neighbor(const int* NN, const int* NL);
int main(void) {
std::vector<real>x, y;
read_xy(x, y);
N = x.size();
int* NN = (int*) malloc(N * sizeof(int)); //NN[n]表示第n个粒子的邻居个数
int* NL = (int*)malloc(N * MN* sizeof(int)); //NL[n*MN+k]是第n个粒子的第k个邻居的指标
timing(NN, NL, x, y);
print_neighbor(NN,NL);
free(NN);
free(NL);
return 0;
}
void read_xy(std::vector<real>& v_x, std::vector<real>& v_y) {
std::ifstream infile("xy.txt");
std::string line, word;
if (!infile) {
std::cout << "Cannot open xy.txt" << std::endl;
exit(1);
}
while (std::getline(infile,line))
{
std::istringstream words(line);
if (line.length() == 0) {
continue;
}
for (int i = 0; i < 2; i++) {
if (words >> word) {
if (i == 0) {
v_x.push_back(std::stod(word));
}
else {
v_y.push_back(std::stod(word));
}
}
else {
std::cout << "Error for reading xy.txt" << std::endl;
exit(1);
}
}
}
infile.close();
}
void find_neighbor(int* NN, int* NL, const real* x, const real* y) {
for (int n = 0; n < N; n++) {
NN[n] = 0; //将数组NN的所有元素初始化为零,因为后面要对数组元素进行累加
}
/*
循环变量n1和n2就代表两个可能互为邻居的原子。
我们知道,如果n2是n1的邻居,那么反过来,n1一定也是n2的邻居。
所以,我们只考虑n2>n1的情形,从而省去一半的计算。
*/
for (int n1 = 0; n1 < N; ++n1) {
real x1 = x[n1];
real y1 = y[n1];
for (int n2 = n1 + 1; n2 < N; ++n2) {
real x12 = x[n2]-x1;
real y12 = y[n2]-y1;
real distance_square = x12 * x12 + y12 * y12;
/*
若原子之间的距离平方小于截断距离平方,
则给原子n1添加一个邻居原子n2,
并将n1的邻居原子数NN[n1]增1。
接着,给原子n2添加一个邻居原子n1,
并将n2的邻居原子数NN[n2]增1。
第19-20行的代码充分利用了C++中的自增运算符++的功能。
注意,这里必须用后置的自增运算NN[n1]++,
不能用前置的自增运算++NN[n1],因为NN[n1]++代表先用NN[n1]的值,
再将它加1,而++NN[n1]代表先将NN[n1]加1,再用它的值。
*/
if (distance_square < cutoff_square) {
NL[n1 * MN + NN[n1]++] = n2;
NL[n2 * MN + NN[n2]++] = n1;
//NL,存放第n个粒子的第k个指标。MN=10,最多有10个邻居,NN第n个例子的邻居个数。
//这里解释就是NL前10个元素就是0号原子的10个邻居索引指标。前11~20就是1号原子的10个邻居索引指标
//对于某个任意的原子n2是n1的邻居,那么就n1 * MN + NN[n1]来索引
//每当有符合的邻居,那么就将其存入NL中。
}
}
}
}
void timing(int* NN, int* NL, std::vector<real> x, std::vector<real> y)
{
for (int repeat = 0; repeat < NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
while (cudaEventQuery(start) != cudaSuccess) {}
find_neighbor(NN, NL, x.data(), y.data());
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
std::cout << "Time = " << elapsed_time << " ms." << std::endl;
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
}
void print_neighbor(const int* NN, const int* NL)
{
std::ofstream outfile("neighbor.txt");
if (!outfile) {
std::cout << "Cannot open neighbor.txt" << std::endl;
}
for (int n = 0; n < N; ++n) {
if (NN[n] > MN) {
std::cout << "Error: MN is too small." << std::endl;
exit(1);
}
outfile << NN[n];
for (int k = 0; k < MN; ++k) {
if (k < NN[n]) {
outfile << " " << NL[n * MN + k];
}
else
{
outfile << "NaN";
}
}
outfile << std::endl;
}
outfile.close();
}挺经典的一篇,用到了c++的好多知识,文件的读取,写入,自增运算与索引的巧妙运用。博大精深,慢慢体会。
现在来看看cuda版本。
利用cuda计算主要是将cpu代码中的find_neighbour,改写成一个对应的核函数。
我们首先尝试从上面C++版本的find_neighbor函数出发,写出一个对应的核函数。 Listing9.4给出了程序neighbor2gpu.cu中的核函数find_neighbor_atomic。该核函数 基本上是C++版本中find_neighbor函数的翻译版。在该核函数中,我们首先将线程指标
blockIdx.x* blockDim.x+threadIdx.x对应到原子指标n1。然后,我们就可以去掉对指标n1的循环,,而改为判断语句if(n1<N)这种将C++程序中的最外层循环改成核函数中的判断语句的做法是开发CUDA程序时经常 用到的模式。当判断语句中的条件成立时,我们首先将每一个原子的邻居数目初始化为零。 如果接下来对n2的循环与原来C++版本的函数中对应的代码一样,那么将得到一个错误 的核函数。出错的地方在如下语句:
d_NL[n1*MN+ d_NN[n1]++]=n2;
d_NL[n2*MN+ d_NN[n2]++]=n1;第一句的作用是将原子n2记为原子n1的第d_NN[n1]个邻居,然后将d_NN[n1]的值加 1。第二句的作用是将原子n1记为原子n2的第d_NN[n2]个邻居,然后将d_NN[n2]的值 加1。然而,我们注意到,一个线程是和一个原子对应的。在与n1对应的线程中,第二个 语句代表我们试图对d_NN[n2]进行累加操作。但是,在与n2对应的线程中,第一个语句 表我们也试图对d_NN[n2]进行累加操作。通过本章前面的学习,我们知道,此时要利用原子函数,即将上述语句改为
d_NL[n1*MN+ atomicAdd(&d_NN[n1],1)]=n2;
d_NL[n2*MN+ atomicAdd(&d_NN[n2],1)]=n1;

不用原子操作的CUDA版本
对于一个使用了原子函数的问题,有时也可以通过改变算法,去掉对原子函数的使用。 在上面的问题中,之所以需要使用原子函数,是因为我们省去了一半对距离的判断,使得 不同的线程可能同时写入同一个全局内存地址。如果我们不省去那一半对距离的判断,就可以在一个线程中仅仅写入与之对应的全局内存地址,从而不需要使用原子函数。基于这 样的考虑,我们可以写出一个不使用原子函数的核函数。
代码:
#include "error.cuh"
#include <cmath>
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <vector>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
int N; // 总原子数
const int NUM_REPEATS = 20; //循环次数
const int MN = 10; //每个原子的最大邻居数
const real cutoff = 1.9; // 阶段距离
const real cutoff_square = cutoff * cutoff; //判断两个原子是否为邻居的截断距离平方
void read_xy(std::vector<real>& x, std::vector<real>& y);
void timing(int* , int* ,const real*, const real*,const bool);
void print_neighbor(const int*, const int* ,const bool);
int main(void) {
std::vector<real>v_x, v_y;
read_xy(v_x, v_y);
N = v_x.size();
int mem1 = sizeof(int) * N;
int mem2 = sizeof(int) * N * MN;
int mem3 = sizeof(real) * N;
int* h_NN = (int*)malloc(mem1);
int* h_NL = (int*)malloc(mem2);
int* d_NN, * d_NL;
real* d_x, * d_y;
CHECK(cudaMalloc(&d_NN, mem1));
CHECK(cudaMalloc(&d_NL, mem2));
CHECK(cudaMalloc(&d_x, mem3));
CHECK(cudaMalloc(&d_y, mem3));
CHECK(cudaMemcpy(d_x, v_x.data(), mem3, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_y, v_y.data(), mem3, cudaMemcpyHostToDevice));
std::cout << std::endl << "using atomicAdd:" << std::endl;
timing(d_NN, d_NL, d_x, d_y, true);
std::cout << std::endl << "not using atomicAdd:" << std::endl;
timing(d_NN, d_NL, d_x, d_y, false);
CHECK(cudaMemcpy(h_NN, d_NN, mem1, cudaMemcpyDeviceToHost));
CHECK(cudaMemcpy(h_NL, d_NL, mem2, cudaMemcpyDeviceToHost));
print_neighbor(h_NN, h_NL,false);
CHECK(cudaFree(d_NN));
CHECK(cudaFree(d_NL));
CHECK(cudaFree(d_x));
CHECK(cudaFree(d_y));
free(h_NN);
free(h_NL);
return 0;
}
void read_xy(std::vector<real>& v_x, std::vector<real>& v_y) {
std::ifstream infile("xy.txt");
std::string line, word;
if (!infile) {
std::cout << "Cannot open xy.txt" << std::endl;
exit(1);
}
while (std::getline(infile, line))
{
std::istringstream words(line);
if (line.length() == 0) {
continue;
}
for (int i = 0; i < 2; i++) {
if (words >> word) {
if (i == 0) {
v_x.push_back(std::stod(word));
}
else {
v_y.push_back(std::stod(word));
}
}
else {
std::cout << "Error for reading xy.txt" << std::endl;
exit(1);
}
}
}
infile.close();
}
void __global__ find_neighbor_atomic(
int* d_NN, int* d_NL, const real* d_x, const real* d_y,
const int N, const real cutoff_square
)
{
const int n1 = blockIdx.x * blockDim.x + threadIdx.x;
if (n1 < N) {
d_NN[n1] = 0;
const real x1 = d_x[n1];
const real y1 = d_y[n1];
for (int n2 = n1 + 1; n2 < N; ++n2) {
const real x12 = d_x[n2] - x1;
const real y12 = d_y[n2] - y1;
const real distance_square = x12 * x12 + y12 * y12;
if (distance_square < cutoff_square) {
d_NL[n1 * MN + atomicAdd(&d_NN[n1], 1)] = n2;
d_NL[n2 * MN + atomicAdd(&d_NN[n2], 1)] = n1;
}
}
}
}
void __global__ find_neighbor_no_atomic
(
int* d_NN, int* d_NL, const real* d_x, const real* d_y,
const int N, const real cutoff_square
)
{
const int n1 = blockIdx.x * blockDim.x + threadIdx.x;
if (n1 < N)
{
int count = 0;
const real x1 = d_x[n1];
const real y1 = d_y[n1];
for (int n2 = 0; n2 < N; ++n2)
{
const real x12 = d_x[n2] - x1;
const real y12 = d_y[n2] - y1;
const real distance_square = x12 * x12 + y12 * y12;
if ((distance_square < cutoff_square) && (n2 != n1))
{
d_NL[(count++) * N + n1] = n2;
}
}
d_NN[n1] = count;
}
}
void timing(int* d_NN, int* d_NL, const real* d_x, const real* d_y, const bool atomic)
{
for (int repeat = 0; repeat < NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
while (cudaEventQuery(start) != cudaSuccess) {}
int block_size = 128;
int grid_size = (N + block_size - 1) / block_size;
if (atomic) {
find_neighbor_atomic << <grid_size, block_size >> >
(d_NN, d_NL, d_x, d_y,N, cutoff_square);
}
else {
find_neighbor_no_atomic << <grid_size, block_size >> >
(d_NN, d_NL, d_x, d_y, N, cutoff_square);
}
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
std::cout << "Time = " << elapsed_time << " ms." << std::endl;
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
}
void print_neighbor(const int* NN, const int* NL, const bool atomic)
{
std::ofstream outfile("neighbor.txt");
if (!outfile) {
std::cout << "Cannot open neighbor.txt" << std::endl;
}
for (int n = 0; n < N; ++n) {
if (NN[n] > MN) {
std::cout << "Error: MN is too small." << std::endl;
exit(1);
}
outfile << NN[n];
for (int k = 0; k < MN; ++k) {
if (k < NN[n]) {
int tmp = atomic ? NL[n * MN + k] : NL[k * N + n];
outfile << " " << tmp;
}
else
{
outfile << " NaN ";
}
}
outfile << std::endl;
}
outfile.close();
}代码就是以上这些。但感觉要搞懂还是要花大段时间。
先这样大改过一遍吧。后面会继续更新。
总结一下,原子操作就是单个线程完成较为复杂的读写运算,不会被别的线程干扰。意思就是先让我一个人干,我干的差不多了,咱们再看看。

















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









