






论文地址:https://arxiv.org/abs/2203.12926
定义生成任务是帮助语言学习者不熟悉的单词提供解释
本文提出了任务——简单定义生成Simple Definition Generation(SDG)
很明显挑战就是缺乏监督训练的数据,也就是学习者的很多语言的字典,文本提出了一个多任务框架SimpDefiner,只需要一个带有复杂定义的标准字典和一个包含任意简单文本的语料库,能够为目标词生成相关的简单定义。
1.引言
智能计算机辅助语言学习(ICALL)领域一个重要课题:帮助语言学习者理解有疑问的词
近年来研究人员研究的是自动生成单词的定义而不是制定一个单词目录,因为:
(1)对用户来说不知道在当前环境下单词应该是哪种意义
(2)预定义的词典耗时而且不能及时更新
本文提出的SDG任务可以生成更简单的定义,而没有那些长难单词,更容易看懂,而且有一些学习者缺乏语言字典,比如中文作为第二语言(CSL)的人没有合适的字典
SDG从复杂的标准词典学习然后生成简单的定义,是无监督的,pipeline方法是首先生成定义然后简化他们,但是需要复杂-简单句子对的数据集,但是除了英语以外的语言很难找到。
本文的框架是多任务框架SimpDefiner执行三个子任务:定义生成、文本重建、语言建模任务生成简单定义,由一个完全共享的编码器和两个部分共享的解码器组成。
Contributions:
(1)首次提出了SDG任务,在无监督情况下生成定义
(2)多任务框架联合训练三个子任务同时生成复杂和简单的定义
(3)自动和人类评估,在英语测试集和中文低级别的词的生成定义上表现很好(HSK level1-3,就是一个中文非第一语言的汉语水平考试初级)
2.相关工作
(1)定义生成任务(Noraset, 2017)
AdaGram向量解决多义词生成不同的定义问题,根据语境生成不同的定义成为主流方法
使用预先训练好的语言模型获得语境化的嵌入
本文提出的SimpDefiner将给定的单词和上下文作为输入,基于MASS(Song et al, 2019)一个预训练的encoder-decoder模型适合于生成任务
(2)句子简化
将句子简化任务视为机器翻译MT的一个单语变体。
本文使用generation-simplification pipeline方法作为baseline,使用ACCESS(Martin et al, 2019)和MUSS(Martin et al, 2020)模型进行简化,可以直接生成简单的定义,减少了累积的错误。
(3)无监督风格迁移style transfer
风格迁移就是在保留内容的同时改变风格,文本的复杂性就是风格属性之一,例如转换图像的不同风格、生成特定风格的标题。
在层级规范化机制中学习复杂度相关参数的洞察力,将语言建模任务引入SimpDefiner增强解码器,对文本复杂性更加敏感。
3.方法
3.1SDG的相关定义
SDG任务是为一个给定的词和语境(w*,c)生成一个简单的定义dsim,c是包含w*的句子,是完全无监督的
3.2多任务框架
Zero-shot manner零样本学习
定义生成任务:在给定单词和上下文的情况下建立一个复杂定义的概率模型
文本重建任务:给定文本破坏的版本,模拟一个简单句子的概率
假设复杂性和语义信息由解码器的不同参数控制,通过一个参数共享方案将复杂性因素从文本中分离出来,推理阶段通过将编码后的隐藏状态送入重建解码器得到一个简单的定义。
语言建模任务增强重建编码器,更专注于简单文本的生成。
3.3参数共享架构
两类参数:与复杂性无关的参数和与复杂性有关的参数,前者在解码器之间共享,后者不共享,图3蓝色的是共享参数,绿色是不共享参数
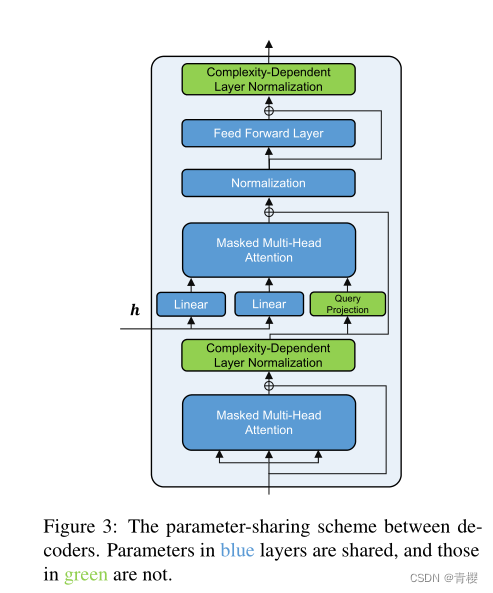
(1)依赖复杂度的层规范化
层规范化与目标文本风格有关,复杂性作为风格的一个属性,解码器的不共享的层规范化将参数缩放和移位,公式8将一个层的激活量x规范化为z
![]()
(2)复杂度相关查询投影
解码层通过交叉注意力机制从编码的隐藏状态提取信息,参数不共享,模型可以从编码的隐藏状态获得不同的信息。
4.Datasets
英文数据集:牛津词典OD和牛津高级学习者词典OALD构建,OALD针对于语言学习者,比较简单,所以通过OD定义生成训练,使用OALD进行简单定义生成的验证。
生成定义数据集:OD(Gadetsky et al, 2018)33128words,97855entries,每个条目三元组(w*,c,dcom)
测试:手动注释OD的词和上下文与OALD的定义对齐,3881words, 5111entries,每个词条都包括一个复杂定义和一个简单定义
提取不在测试集的OALD定义构建简单文本语料库,有32395个句子,平均长度12.12,定义生成数据集和简单文本语料库分别作为小批量随机抽样
中文数据集:中文词网CWN(Huang et al, 2010)是一个语义词典,提供一个意义区分的知识库,按照8:1:1分成训练、验证、测试,训练集有6574words和67861entries
很明显这个中文数据集数量少于英文的
简单文本语料库,从一些初级汉语教科书提取了58867个句子,平均长度14.62
没有合适的词典用来评估,中文数据集没有golden simple definitions,因此统计定义中单词的难度来估计是否简单,还使用人工评估
5.实验
5.1实验设置
Baselines:SimpDefiner与生成-简化pipelines相比较。
LOG-CAD(lshiwatari et al, 2019)和MASS(Song et al, 2019)生成定义,ACCESS(Martin et al, 2019)和MUSS(Martin et al, 2020)简化定义。有这四个pipelines的baseline,并且只应用在英文数据集上。中文SDG任务,使用中文Gigaword第五版语料库从头预训练一个MASS-ZH模型。
SimpDefiner使用MASS模型的参数初始化两个编码器和解码器,对于文本重建任务的句子破坏,以0.2的概率随机删除单词,并随机打乱5个token的单词顺序。语言建模任务将输入表示设置为0,使用简化的文本作为输出。
5.2评估指标
生成的定义评估两方面:准确性、简单性
分别进行自动和手动评估
自动指标:
BLEU:生成的结果与标准答案的接近程度,分别计算复杂和简单定义
SSim语义相似度:sentence-transformers toolkit将生成的定义和引用转换成句子向量并计算余弦相似度
SARI:衡量简化的模型添加、删除和保留的单词的好坏程度,用于评估简单性
HSK level:汉语水平考试九个等级,计算级别1-3和7+的单词比例,1-3级说明定义更容易被理解,7+级说明定义更难理解
手动评估:
从中文测试集随机选择200单词和上下文,使用MASS和SimpDefiner生成定义,与黄金复杂定义混在一起,三个母语者的注释者进行评分。分别评价准确性(定义和单词的语义相关性)和简单性(定义简单程度),标准是1-3分,然后对三个注释者取平均。
6.结果分析
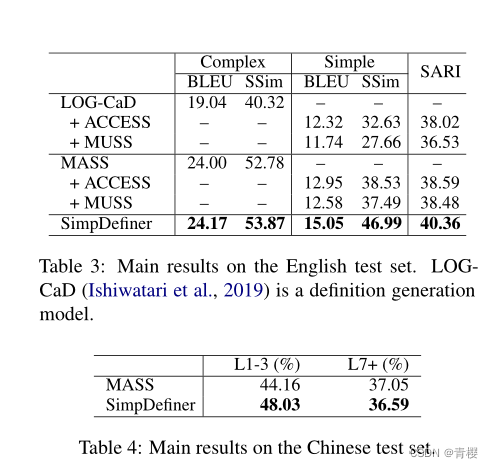
SimpDefiner方法在中文和英文上都优于基线
英文结果在生成复杂定义和简单定义方面BLEU, SSim, SARI指标都更优
中文结果在HSK1-3级词占比增加,7+级词占比减少
表5人工评估
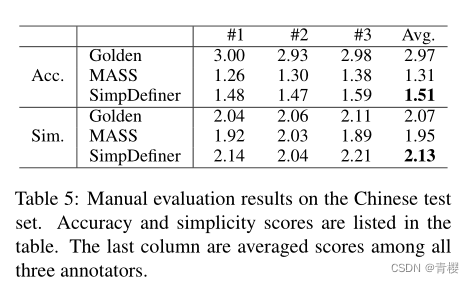
SimpDefiner方法在准确性和简单性方面优于MASS方法,准确性不优于黄金定义,简单性略微优于黄金定义。
不足:准确性方面黄金定义表现更好,文中提出可能因为是由于模型知识不足造成。可以通过使用更大的预训练模型例如BART(Lewis et al, 2019)
消融实验
语言建模LM和文本重建TR任务,通过将权重设置为0消除他们,对于作为参数共享层的层归一化LN和查询投影QP通过共享他们模型之间的参数来消除。
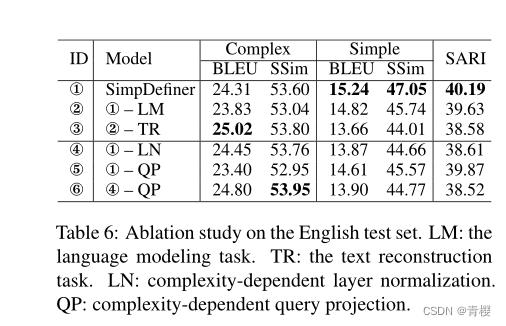
表6 在简单定义的两个方面,原模型更好。在生成复杂的定义的方面,去掉LM和TR的BLEU分数更高,去掉LN和QP的SSim更好。但是本文目标是生成简单的定义,因此达到了要求。
展望:
将当前模型和提示方法相结合,可以让用户自主调节生成定义的复杂性















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









