







森林的逻辑结构
森林是m(m≥0)棵互不相交的树的集合。
森林的前序遍历:前序遍历森林中的每一棵数。
森林的后序遍历:后序遍历森林中的每一棵树。
森林通常有这两种方式。
树、森林与二叉树的转换
1.树转换为二叉树
①加线——树中所有相邻兄弟结点之间加一条线。
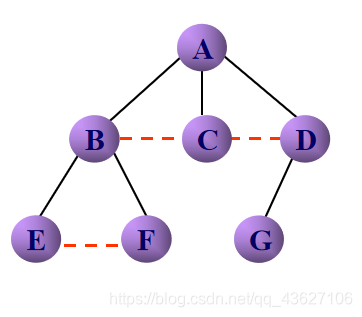
②去线——对树中的每个结点,只保留它与第一个孩子结点之间的连线,删去它与其他孩子结点之间的连线。
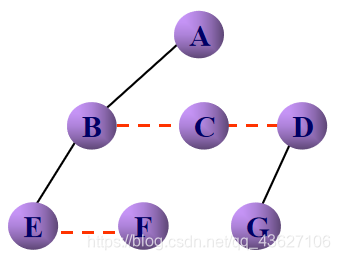
③层次调整——按照二叉树结点之间的关系进行层次调整。
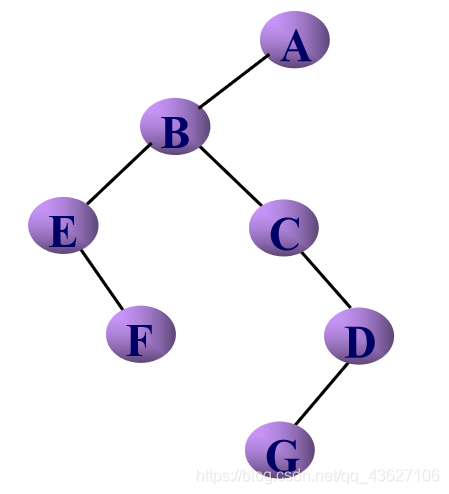
2.森林转换为二叉树
①将森林中的每棵树转换成二叉树。
②从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树根结点的右孩子。
③按照二叉树结点之间的关系进行层次调整。
3.二叉树转换为树或森林
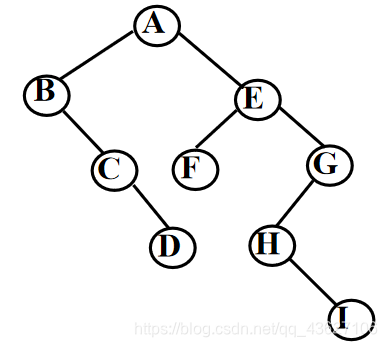
①加线——若某结点x是其双亲y的左孩子,则把结点x的右孩子、右孩子的右孩子、……,都与结点y用线连起来。
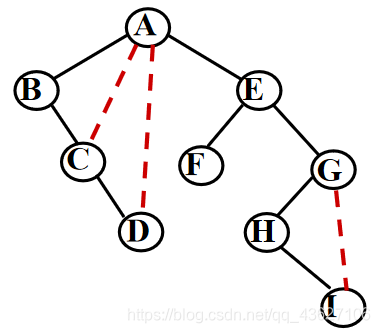
②去线——删去原二叉树中所有的双亲结点与右孩子结点的连线。
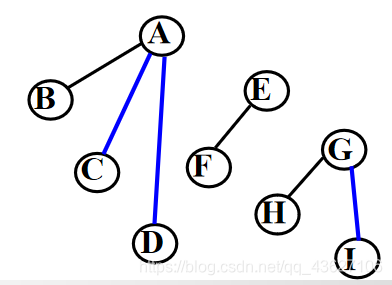
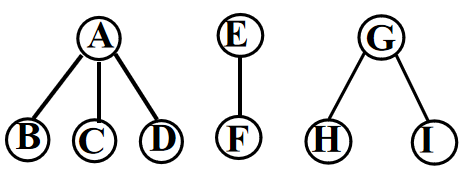
③层次调整——整理①、②两步所得到的树或森林,使之层次分明。
最优二叉树
一、哈夫曼算法
哈夫曼树:给定一组具有确定权值的叶子结点,带权路径长度最小的二叉树。
特点:
1.权值越大的叶子结点越靠近根结点,而权值越小的叶子结点越远离根结点。
2.只有度为0(叶子结点)和度为2(分支结点)的结点,没有度为1的结点。
哈夫曼算法基本思想:
算法:HuffmanTree
输入:n个权值{w1,w2,w3,···,wn}
输出:哈夫曼树
1.初始化:由给定的n个权值{w1,w2,…,wn}构造n棵只有一个根结点的二叉树,从而得到一个二叉树集合F={T1,T2,…,Tn};
2.重复下述操作,直到集合F中只剩下一颗二叉树
2.1选取与合并:在F中选取根结点的权值最小的两棵二叉树分别作为左、右子树构造一棵新的二叉树,这棵新二叉树的根结点的权值为其左、右子树根结点的权值之和。
2.2删除与加入:在F中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到F中。
哈夫曼算法的伪代码:
算法:HuffmanTree
输入:n个权值w[n]
输出:哈夫曼树huffmanTree[2n-1]
1.数组huffTree初始化,所有元素结点的双亲、左右孩子都置为-1。
2. 数组huffTree的前n个元素的权值置给定值w[n]。
3. 循环变量k从n~n-2进行n-1次合并:
3.1 选取两个权值最小的根结点,其下标分别为i1, i2。
3.2 将二叉树i1、i2合并为一棵新的二叉树k(初值为n,依次递增)。
代码:
/*
weight:权值域,保存该结点的权值;
lchild:指针域,结点的左孩子结点在数组中的下标;
rchild:指针域,结点的右孩子结点在数组中的下标;
parent:指针域,该结点的双亲结点在数组中的下标。
*/
struct element
{ int weight;
int lchild, rchild, parent;
};
void HuffmanTree(element huffTree[], int w[],int n){
for (i=0; i<2*n-1; i++){
huffTree [i].parent= -1;
huffTree [i].lchild= -1;
huffTree [i].rchild= -1;
}
for (i=0; i<n; i++)
huffTree [i].weight=w[i];
for (k=n; k<2*n-1; k++) {
Select(huffTree, &i1, &i2);
huffTree[k].weight=huffTree[i1].weight+huffTree[i2].weight;
huffTree[i1].parent=k;
huffTree[i2].parent=k;
huffTree[k].lchild=i1;
huffTree[k].rchild=i2;
}
}















 1690
1690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









