







本课程共五个章节,课程地址:
【Python爬虫教程】花9888买的Python爬虫全套教程2021完整版现分享给大家!(已更新项目)——附赠课程与资料_哔哩哔哩_bilibili
第二章
- 数据解析概述
- 正则表达式
- re模块
- 手刃豆瓣TOP250电影信息
- bs4解析-HTML语法
- bs4解析-bs4模块安装和使用
- 抓取让你睡不着觉的图片
- xpath解析
- 抓取猪八戒数据
目录
(九)抓取猪八戒数据
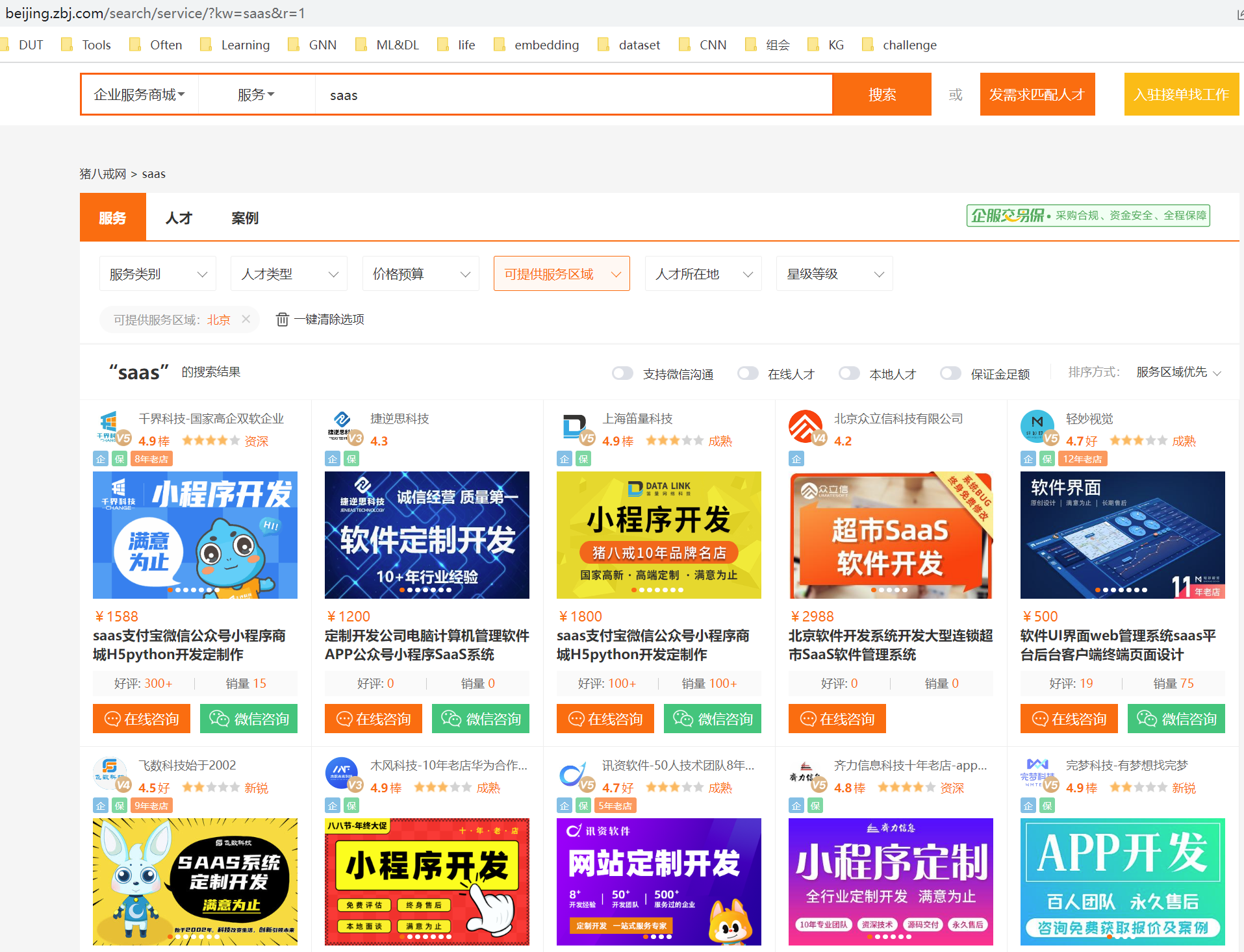
首先检查数据在不在源代码里:

发现数据在页面源代码里
思路:
- 拿到页面源代码
- 提取和解析数据
第一步:拿到页面源代码
import requests
url = "https://beijing.zbj.com/search/service/?kw=saas&r=1"
resp = requests.get(url)
print(resp.text)第二步:提取和解析数据
首先解析数据:
from lxml import etree
# 解析
html = etree.HTML(resp.text) # .HTML()作用为加载html源码以一家店铺为单位来提取数据,然后循环即可
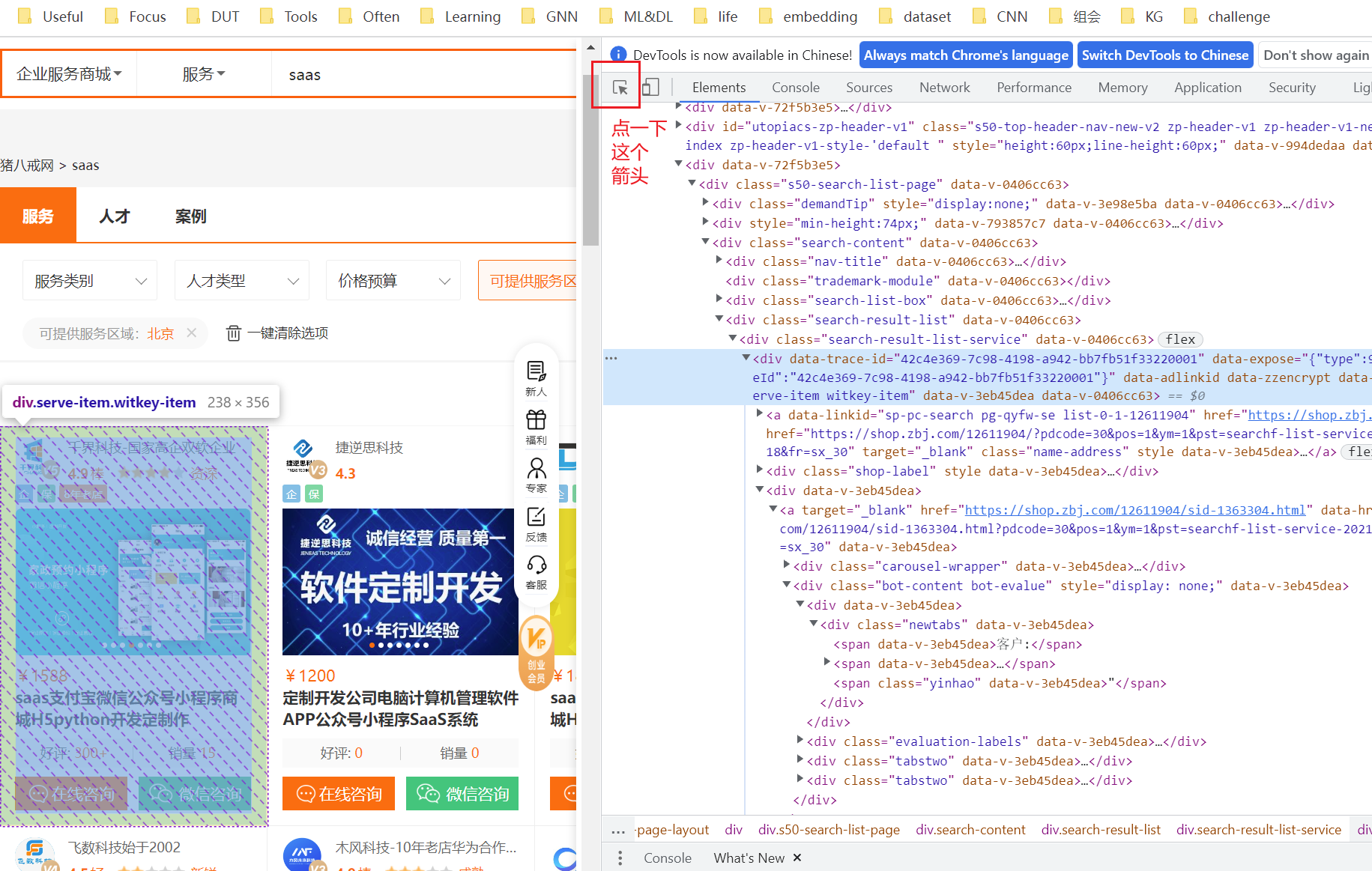
# 定位到第一家商铺,其他循环即可
# 拿到每一个服务商的div
# 这里复制得到的xpath是
# //*[@id="__layout"]/div/div[3]/div/div[3]/div[4]/div[1]/div
divs = html.xpath('//*[@id="__layout"]/div/div[3]/div/div[3]/div[4]/div[1]/div')以 价格 为例,查找它们之间的层级关系:
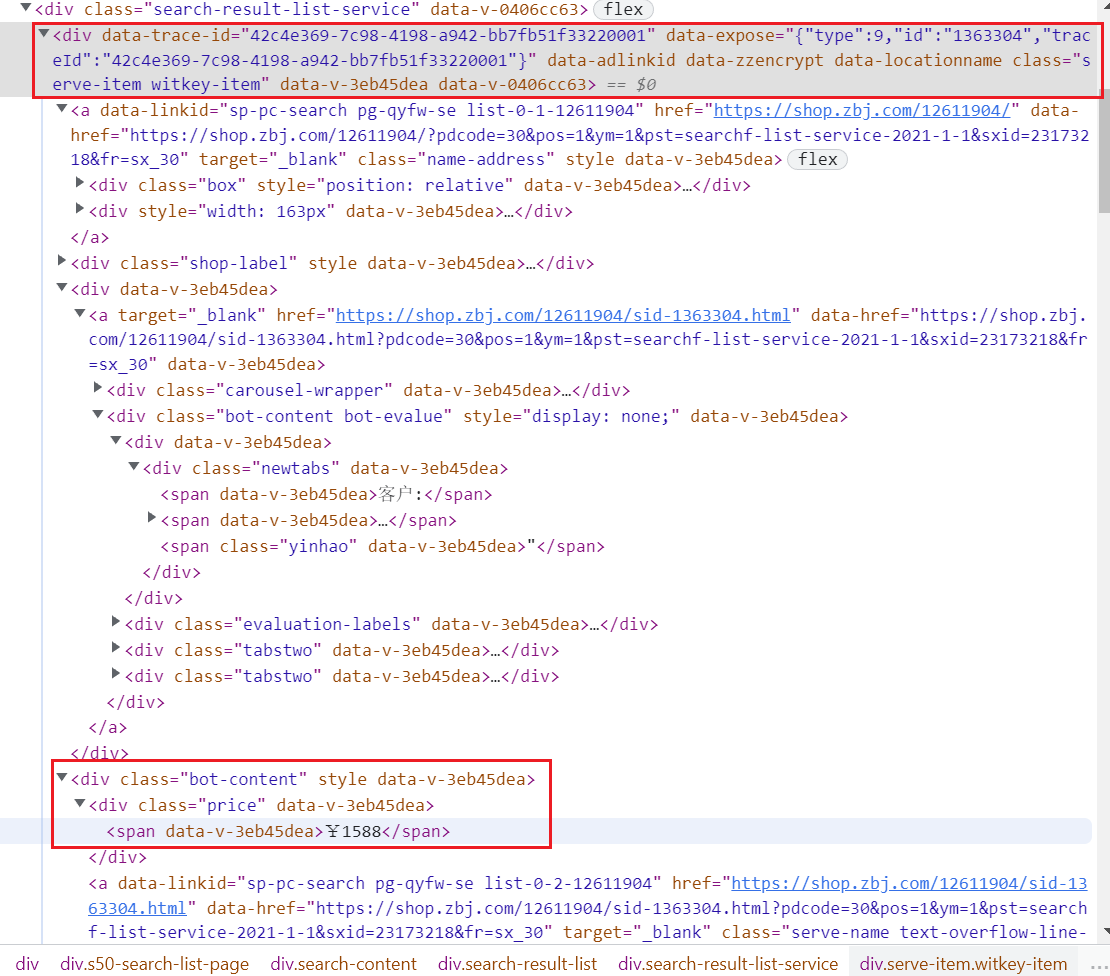
# ./div[3]/div[1]/span[1]
for div in divs: # 每一个服务商信息
price = div.xpath("./div[3]/div[1]/span[1]/text()")
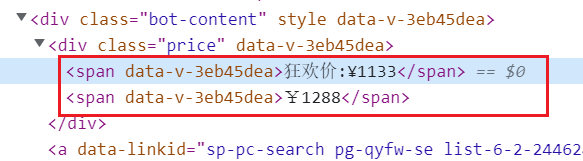
print(price)注意这里为什么是 span[1] 而不是 span:

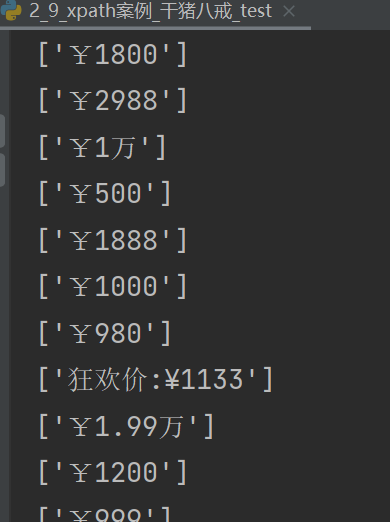
运行后结果如下:
而我们只想拿到其中的数字,代码改为:
price = div.xpath("./div[3]/div[1]/span[1]/text()")[0].strip("¥").strip("狂欢价:¥").strip("万") # [0]表示从列表里拿出来,strip()表示去掉strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
用法:str.strip([chars])
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符
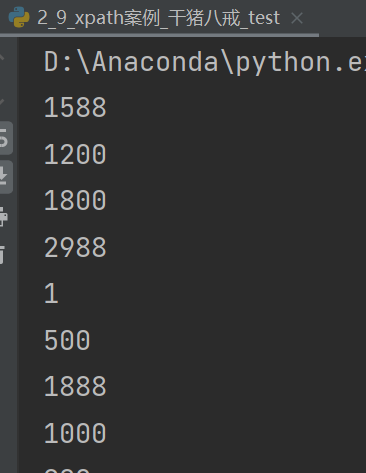
再次运行后得到仅为数字的价格:
完整代码:
import requests
from lxml import etree
url = "https://beijing.zbj.com/search/service/?kw=saas&r=1"
resp = requests.get(url)
# print(resp.text)
# 解析
html = etree.HTML(resp.text) # .HTML()作用为加载html源码
# 定位到第一家商铺,其他循环即可
# 拿到每一个服务商的div
divs = html.xpath('//*[@id="__layout"]/div/div[3]/div/div[3]/div[4]/div[1]/div') # 由于相对路径里有"",所以外面要用''括起来,不能再用""
for div in divs: # 每一个服务商信息
price = div.xpath("./div[3]/div[1]/span[1]/text()")[0].strip("¥").strip("狂欢价:¥").strip("万") # [0]表示从列表里拿出来,strip()表示去掉
title = div.xpath("./div[3]/a/text()")[0]
company_name = div.xpath("./a/div[2]/div[1]/div/text()")[0]
print(company_name)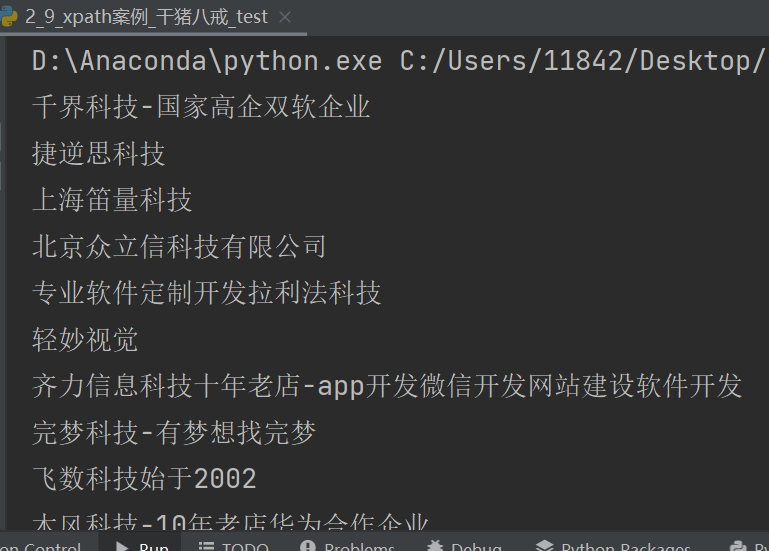
补充:
原视频中在对商品的 title 进行处理时,由于我们搜索的关键词为 “saas”,标题中的 "saas" 均被高亮,未被获取到,从而原视频中的代码在对 title 处理时做了一个 .join() 拼接处理
# 由于saas在原页面中做了高亮显示,所以没拿出来,但是可以拼接
title = "saas".join(div.xpath("./div/div/a[1]/div[2]/div[2]/p/text()"))但可能因为网站改版了,这次爬取没有遇到这个问题,所以不需要进行这个处理,单纯记录一下~
















 1065
1065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











