







https://leetcode.cn/study-plan/sql/?progress=jgmzq5s
第1天 选择
595. 大的国家
无
1757. 可回收且低脂的产品
枚举类型enum
enum是一个字符串对象,用于指定一组预定义的值,并可在创建表时使用,如sex取值为 ('male', 'female', 'unknown')
若要使用条件过滤,如过滤出男性,直接 sex = 'male' 就行
584. 寻找用户推荐人
is null的情况
Q:返回客户列表,列表中客户的推荐人的编号都不是2,直接 referee_id != 2
注意只写这个条件的话,推荐人编号为null的也不会输出
所以最后的过滤条件应该是 referee_id != 2 or referee_id is null
是 is null,而不是 = null
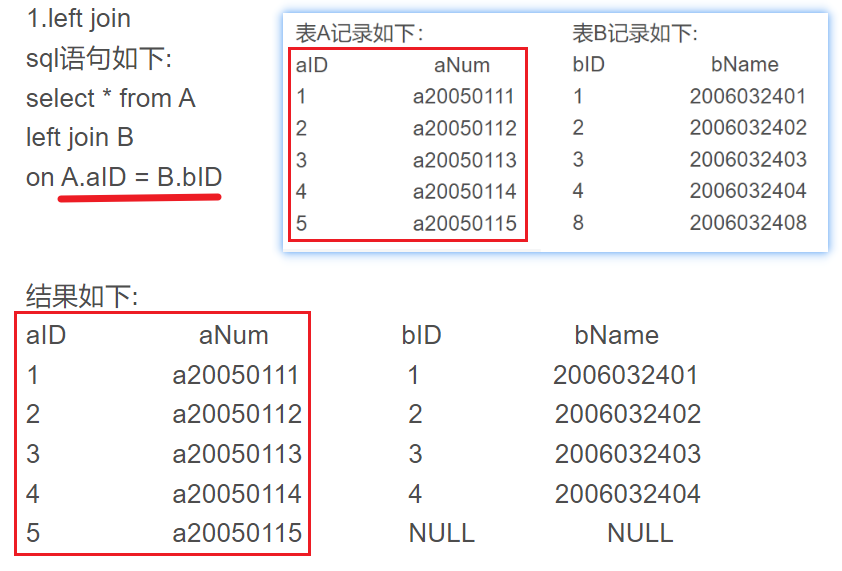
183. 从不订购的客户
Q:两个表,Customers表(有Id和Name两列)和Orders表(有Id和CustomerId两列),返回一列客户的姓名即可,列名叫Customers
select Name as Customers
from Customers a left join Orders b
on a.Id = b.CustomerId
where b.CustomerId is nullleft join ... on 连接条件 where 过滤条件
不考虑where条件下,left join会把左表所有数据查询出来,on及其后面的条件仅仅会影响右表的数据(符合就显示,不符合全部为null)
在匹配阶段,where子句的条件都不会被使用,仅在匹配阶段完成以后,where子句条件才会被使用,它将从匹配阶段产生的数据中检索过滤
where放后面:先连接生成临时查询结果,然后再筛选
on放后面:先根据条件过滤筛选,再连接生成临时查询结果
第2天 排序&修改
1873. 计算特殊奖金
Q:表Employees有3列employee_id、name、salary,返回两列employee_id、奖金bonus(结果按employee_id排序)。如果一个雇员的id是奇数,且他的名字不是以 'M' 开头,则他的奖金就是他的工资,否则奖金为0
雇员的id是奇数:employee_id % 2 != 0
名字不是以 'M' 开头:left (name, 1) <> 'M'
select employee_id,
case when employee_id%2 != 0 and left(name,1) <> 'M'
then salary
else 0 end as bonus
from Employees
order by employee_idleft(str, length)
str是要提取子字符串的字符串;length是一个正整数,指定将从左边返回的字符数
left() 函数:从左开始截取字符串,length是截取的长度
case when ... then ... else ... end
case具有两种格式 —— 简单case函数和case搜索函数
简单case函数
case sex
when '1' then '男'
when '2' then '女'
else '其他' endcase搜索函数
case when sex = '1' then '男'
when sex = '2' then '女'
else '其他' end这两种方式可以实现相同的功能。简单case函数的写法相对比较简洁,但是和case搜索函数相比,功能方面会有些限制,比如写判定式
627. 变更性别
Q:Salary表有4列,本题要将sex列的 'm' 和 'f' 互换
要求:仅使用单个update语句,且不产生中间临时表(不能使用select语句)
update Salary
set sex=(
case sex when 'm' then 'f' else 'm' end
)update ... set ... where...
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;196. 删除重复的电子邮箱
Q:表Person有两列id和email,删除所有重复的电子邮件,只保留一个id最小的唯一电子邮件
delete from Person
where id not in(
select * from(
select min(id) from Person
group by email
) t
)注意,子查询出来的结果要取别名
分析过程:
delete from Person where id not in (
select t.id from (select min(id) id from Person group by Email) t
);
步骤详解:
step1:找出经过Email分组后的最小的id,也就是id=1和id=2
select min(id) id from Person group by Email
step2:将step1的查询结果作为临时表t
select t.id from (select min(id) id from Person group by Email) t
step3:删除不在表t中的id,也就是id=3第3天 字符串处理函数/正则
1667. 修复表中的名字
Q:表Users有两列user_id和name,使name只有第一个字符是大写,其余都是小写。返回结果按user_id排序
select user_id,
concat(upper(left(name,1)), lower(right(name,length(name)-1))) as name
from Users
order by user_idconcat()、upper()、lower()
concat() 可以将多个字符串拼接在一起
upper() 将字符串中所有字符转为大写
lower() 将字符串中所有字符转为小写
1484. 按日期分组销售产品
Q:表Activities有两列sell_date和product,查找每个日期销售的不同产品的数量及名称(按词典序排列)。返回3列,分别为sell_date、num_sold、products,并按sell_date排序
select sell_date,
count(distinct product) as num_sold,
group_concat(distinct product) as products
from Activities
group by sell_date
order by sell_dategroup_concat()
SELECT id, GROUP_CONCAT(score) from score GROUP BY id;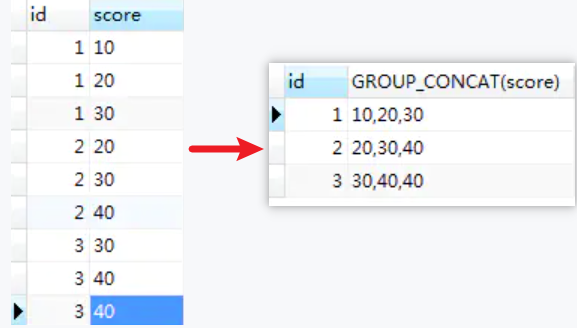
1527. 患某种疾病的患者
Q:表Patients,有三列patient_id、patient_name和conditions。其中conditions包含0个或以上的疾病代码,以空格分隔。返回还是这三列,但是是患有I类糖尿病的患者信息(I类糖尿病的代码总是包含前缀DIAB1)
select patient_id, patient_name, conditions
from Patients
where conditions like 'DIAB1%'
or conditions like '% DIAB1%'注意,第二种情况,%和DIAB1之间有一个空格
第4天 组合查询 & 指定选取
1965. 丢失信息的雇员
Q:两个表,分别是Employees(两列employee_id和name)和Salaries(两列employee_id和salary),按从小到大排序返回name或salary信息丢失的employee_id
select a.employee_id as employee_id from Employees a left join Salaries b
on a.employee_id = b.employee_id
where salary is null
union
select b.employee_id as employee_id from Employees a right join Salaries b
on a.employee_id = b.employee_id
where name is null
order by employee_idleft join 和 right join
left join(左联接) —— 返回包括左表中的所有记录和右表中联结字段相等的记录
left join是以A表的记录为基础,A表可以看成左表,B表或者C表可以看成右表,left join是以左表为准的。换句话说,左表(A)的记录将会全部表示出来,而右表(B) 或者(C)只会显示符合搜索条件的记录,右表记录不足的地方均为NULL
right join(右联接) —— 返回包括右表中的所有记录和左表中联结字段相等的记录
和left join的结果刚好相反,这次是以右表(table_b)为基础的,左表不足的地方用NULL填充
inner join(等值连接) —— 只返回两个表中联结字段相等的行
inner join并不以谁为基础,它只显示符合条件的记录
1795. 每个产品在不同商店的价格
重构Products表
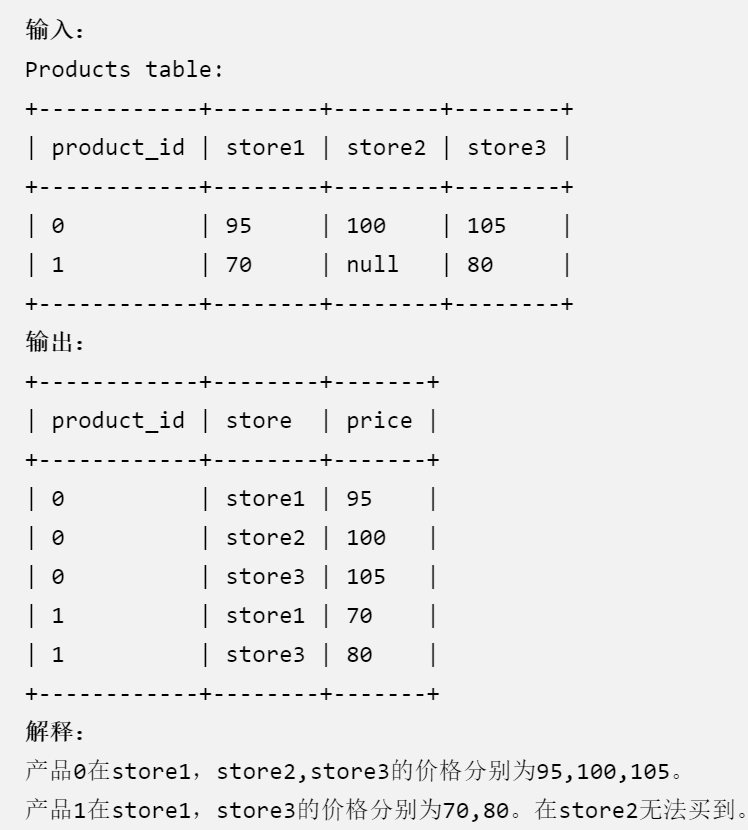
select product_id, 'store1' store, store1 price from Products
where store1 is not null
union
select product_id, 'store2' store, store2 price from Products
where store2 is not null
union
select product_id, 'store3' store, store3 price from Products
where store3 is not null'store1' 是一个字符串,而store1是指该列下的值
列名store和price也不需要加引号
union 和 union all
union和union all都是用来合并多个查询结果的
union:将多个查询结果合并在一起,并且去除重复的行
union all:将多个查询结果合并在一起,不去除重复的行
608. 树节点
Q:表tree,id是树节点的编号,p_id是它父节点的id。树中每个节点属于叶子Leaf/根Root/内部节点Inner三种类型之一。排序返回所有节点的编号及类型
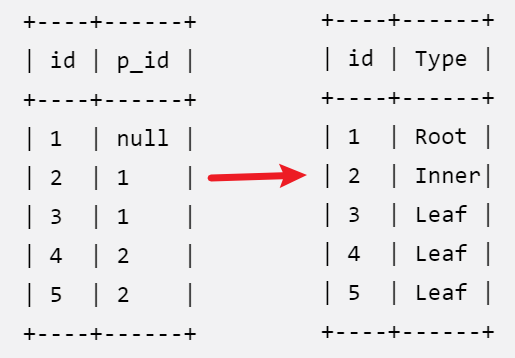
两种写法:
# 写法1
select id,
case
when p_id is null then 'Root'
when id in (select p_id from tree) then 'Inner' # in语句中不会对null值进行匹配,即查询不到null值记录
else 'Leaf'
end as Type from tree
order by id
# 写法2
select id,
case
when p_id is null then 'Root'
when id not in (select p_id from tree where p_id is not null) then 'Leaf' # not in语句后面的范围不能出现null,否则执行无效,如果后面是子查询,则需要手动增加is not null过滤条件
else 'Inner'
end as Type from tree
order by idin、not in遇到null时的情况
结论1:不管in语句后面的范围里有没有null,都不会对null值进行匹配,即查询不到null值记录
结论2:not in 后面的范围里没有null时,语句不会对null值进行匹配,即查询不到null值记录
结论3:not in 遇上null,查询无效,不会查询到任何结果,但语句正常执行不会报错(not in语句后面的范围不能出现null,否则执行无效,如果后面是子查询,则需要手动增加is not null过滤条件)
176. 第二高的薪水
Q:Employee表有两列id和salary,返回第二高的薪水SecondHighestSalary
select max(salary) as SecondHighestSalary from Employee
where salary < (select max(salary) from Employee)第5天 合并
175. 组合两个表
就是一个简单的left join
1581. 进店却未进行过交易的顾客
Q:两个表Visits(有visit_id和customer_id两列)和Transactions(有transaction_id、visit_id和amount三列)。返回只光顾、没交易的顾客的customer_id,以及只光顾不交易的次数count_no_trans
select customer_id,
count(customer_id) as count_no_trans
from Visits
where visit_id not in(
select visit_id from Transactions
)
group by customer_id分析过程:

select customer_id, # 结果是30 96 54 54
count(customer_id) as count_no_trans # 结果是1 1 2
from Visits
where visit_id not in( # 结果是4 6 7 8
select visit_id from Transactions
)
group by customer_id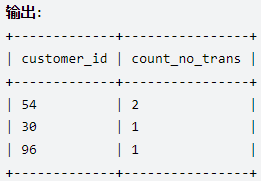
1148. 文章浏览I
查找所有浏览过自己文章的作者,其实就是 author_id = viewer_id 就行了
这题要注意的是,此表无主键,因此可能会存在重复行,所以要加一个distinct
第6天 合并
197. 上升的温度
Q:表Weather有三列,id、recordDate和temperature。查询与昨天的日期相比,温度更高的所有日期的id
select a.id from Weather a, Weather b
where a.temperature > b.temperature
and datediff(a.recordDate, b.recordDate) = 1datediff() 返回两个日期的天数
[Mysql] DATEDIFF函数
datediff(date1, date2) # 返回date1-date2的结果date1和date2两个参数需要是有效的日期或日期时间值。如果参数传递的是日期时间值,仅将日期部分用于计算,并忽略时间部分(只有值的日期部分参与计算)
607. 销售员
Q:三个表,查询没有任何与名为“RED”的公司相关订单的所有销售人员的姓名
SalesPerson表:sales_id、name、salary、commission_rate、hire_date【销售人员id、姓名、工资、佣金率、雇佣日期】
Company表:com_id、name、city【公司id、名称、所在城市】
Orders表:order_id、order_date、com_id、sales_id、amount【订单id、日期、公司id、销售人员id、支付金额】
三个表的嵌套查询
select name from SalesPerson
where sales_id not in (
select sales_id from Orders
where com_id = (
select com_id from Company
where name = 'RED'
)
)第7天 计算函数
1141. 查询近30天活跃用户数
Q:表Activity是用户在社交网站的活动记录。无主键,可能包含重复数据
user_id
session_id:每个session_id只属于一个用户【一个用户一天可能对应多个session_id】
activity_date
activity_type:enum类型,为以下四种值 ('open_session', 'end_session', 'scroll_down', 'send_message')
查询出截至2019-07-27(含),近30天的每日活跃用户数(当天只要有一条活动记录,即为活跃用户)
select activity_date as day,
count(distinct user_id) as active_users
from Activity
where datediff('2019-07-27', activity_date)<30 and datediff('2019-07-27', activity_date)>=0
group by activity_date注意“截至date1(包含date1这天)近30天”的写法:
datediff(date1, 日期列) between 0 and 291693. 每天的领导和合伙人
重点在于知道group by后面可以加多个字段就行
1729. 求关注者的数量
无
第8天 计算函数
586. 订单最多的客户
这里注意,求出每个客户的订单数后,可以把订单数降序排序,再limit 1即是订单数最多的那个
511. 游戏玩法分析I
查询每位玩家第一次登录平台的日期,对日期取min() 即可
1890. 2020年最后一次登录
跟上题相反,最后一次登录,对日期取max() 即可
1741. 查询每个员工花费的总时间
这里注意,在一天之内,同一员工是可以多次进入和离开办公室的,所以需要sum() 求总时间,同时group by的时候,需要对event_day(同一天)和emp_id(同一员工)都处理
第9天 控制流
1393. 股票的资本损益
Q:表Stocks,名为stock_name的某支股票在operation_day这一天的操作价格
stock_name
operation:枚举类型 ('Sell', 'Buy') 保证股票的每次Sell前都有相应Buy操作
operation_day
price
查询每支股票的资本损益(是一次或多次买卖股票后的全部收益或损失)
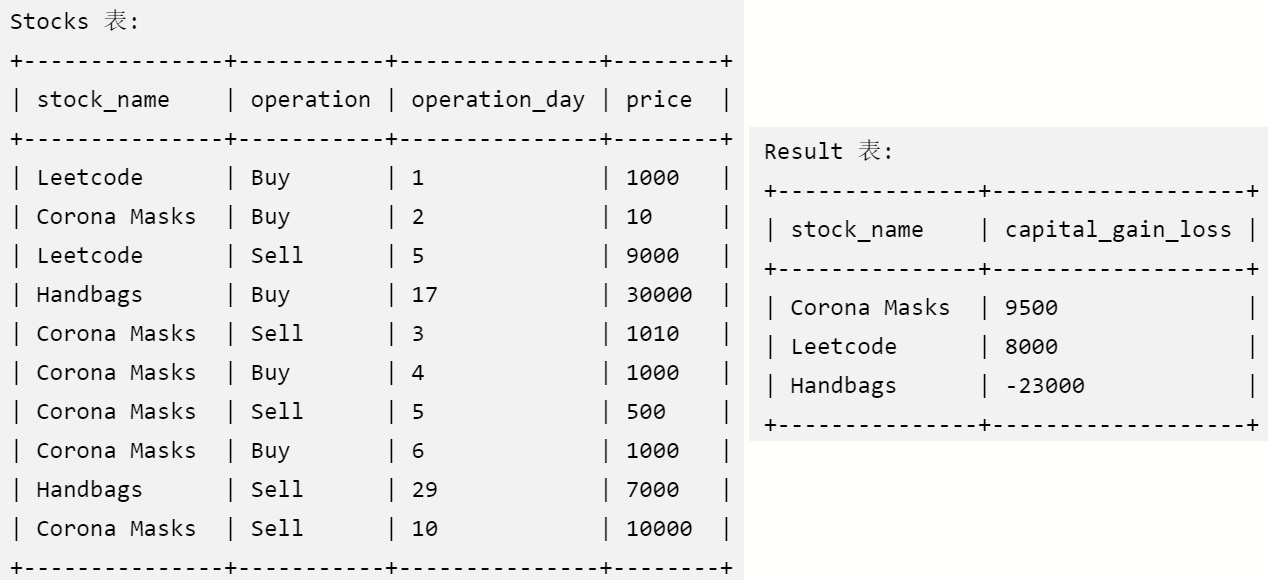
select stock_name,
sum(
case
when operation = 'Sell' then price
when operation = 'Buy' then -price
end
) as capital_gain_loss
from Stocks
group by stock_name1407. 排名靠前的旅行者
Q:表Users有2列id和name,表Rides有三列id,user_id和distance
查询每个用户的旅行距离,返回name和travelled_distance两列,结果以travelled_distance降序排列,如果有两个或者更多用户旅行了相同距离,再以name升序排列
这题有个坑,就是存在一些用户,它的id在Rides里是不存在的,即没有旅行过,所以如果写成下面这样是有问题的:
select name, sum(distance) as travelled_distance
from Users a, Rides b
where a.id = b.user_id
group by name
order by travelled_distance desc, name asc
正确的写法是:
# 法1
select name, sum(distance) as travelled_distance
from Users a, Rides b
where a.id = b.user_id
group by name
union
select name, 0 as travelled_distance
from Users
where id not in (select user_id from Rides)
order by travelled_distance desc, name ascifnull(A, B) 如果A不为null,则返回A,否则返回B的结果
还有一种更简洁的写法:
select name, ifnull(sum(distance),0) as travelled_distance
from Users a left join Rides b
on a.id = b.user_id
group by name
order by travelled_distance desc, name ascsum不对null值进行计算,所以要判断是否为null,对null赋0
1158. 市场分析I
Q:表Users有三列(user_id、join_date、favorite_brand),该表记录了购物网站的用户信息
表Orders有五列(order_id、order_date、item_id、buyer_id、seller_id)
表Items有两列(item_id、item_brand)
查询每个用户的注册日期和在2019年作为买家的订单总数
注意,这题可以用sum,也可以用count,但是要弄清楚两者的区别。而且这题有好几种写法
select user_id as buyer_id,
join_date,
sum(case when year(order_date) = '2019' then 1 else 0 end) # 这里还有一种写法:sum(if(year(order_date)='2019', 1, 0))
as orders_in_2019
from Users a left join Orders b
on a.user_id = b.buyer_id
group by user_id上面是sum的两种写法
若要写成count,只要把0改成null就行了:
select user_id as buyer_id,
join_date,
count(case when year(order_date) = '2019' then 1 else null end)
as orders_in_2019
from Users a left join Orders b
on a.user_id = b.buyer_id
group by user_idsum()和count()的区别
sum为求和/累加(把列的所有值进行汇总求和),不计算null
count为求行的个数/累计,认为没有null(只要值不为null,就会增加1)
但是有个例外,就是count(*),在不指定列的情况下,即使此列中所有行都是null,在汇总行数时仍然会+1
第10天 过滤
182. 查找重复的电子邮箱
注意分组之后再过滤,用的语句是group by... having...
having是在分好组后找出特定的分组,通常是以筛选聚合函数的结果
group by... having...

聚合函数如min()、max()、sum()、avg()、count()
1050. 合作过至少三次的演员和导演
就是两个字段group by,再having过滤合作次数
1587. 银行账户概要II
无
1084. 销售分析III
Q:表Product有三列(product_id、product_name和unit_price),显示每个产品的名称和价格;表Sales有六列(seller_id、product_id、buyer_id、sale_date、quantity和price),该表无主键,可以有重复的行
查询2019年春季(即仅在2019-01-01至2019-03-31(含)之间出售的商品)才售出的产品
分析思路就是:仅在2019年春季才售出,说明总的销售记录次数count(sale_date) 就等于 2019-01-01至2019-03-31(含)之间的销售记录次数
不过这题有个坑,先看看错误的写法:
select a.product_id, product_name
from Product a left join Sales b
on a.product_id = b.product_id
group by product_id
having count(case
when sale_date between '2019-01-01' and '2019-03-31' then 1
else null
end)
= count(sale_date)提交之后发现有个测试用例没通过,问题如下:

简单来说就是,有部分产品没有被销售过,所以其product_id在Product表里有,但是在Sales表里不存在。其实改动的时候很简单,把Sales表作为主表就行了,即把left join改成right join
select a.product_id, product_name
from Product a right join Sales b
on a.product_id = b.product_id
group by product_id
having count(case
when sale_date between '2019-01-01' and '2019-03-31' then 1
else null
end)
= count(sale_date)















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











