






1 分割回文串
给你一个字符串s,请你将s分割成一些子串,使每个子串都是回文串。返回s所有的可能的分割方案。
示例 1:输入:s = “aab”,输出:[[“a”,“a”,“b”],[“aa”,“b”]]
本题这涉及到两个关键问题:1)切割问题,有不同的切割方式;2)判断回文;切割问题,也可以抽象为一棵树形结构:
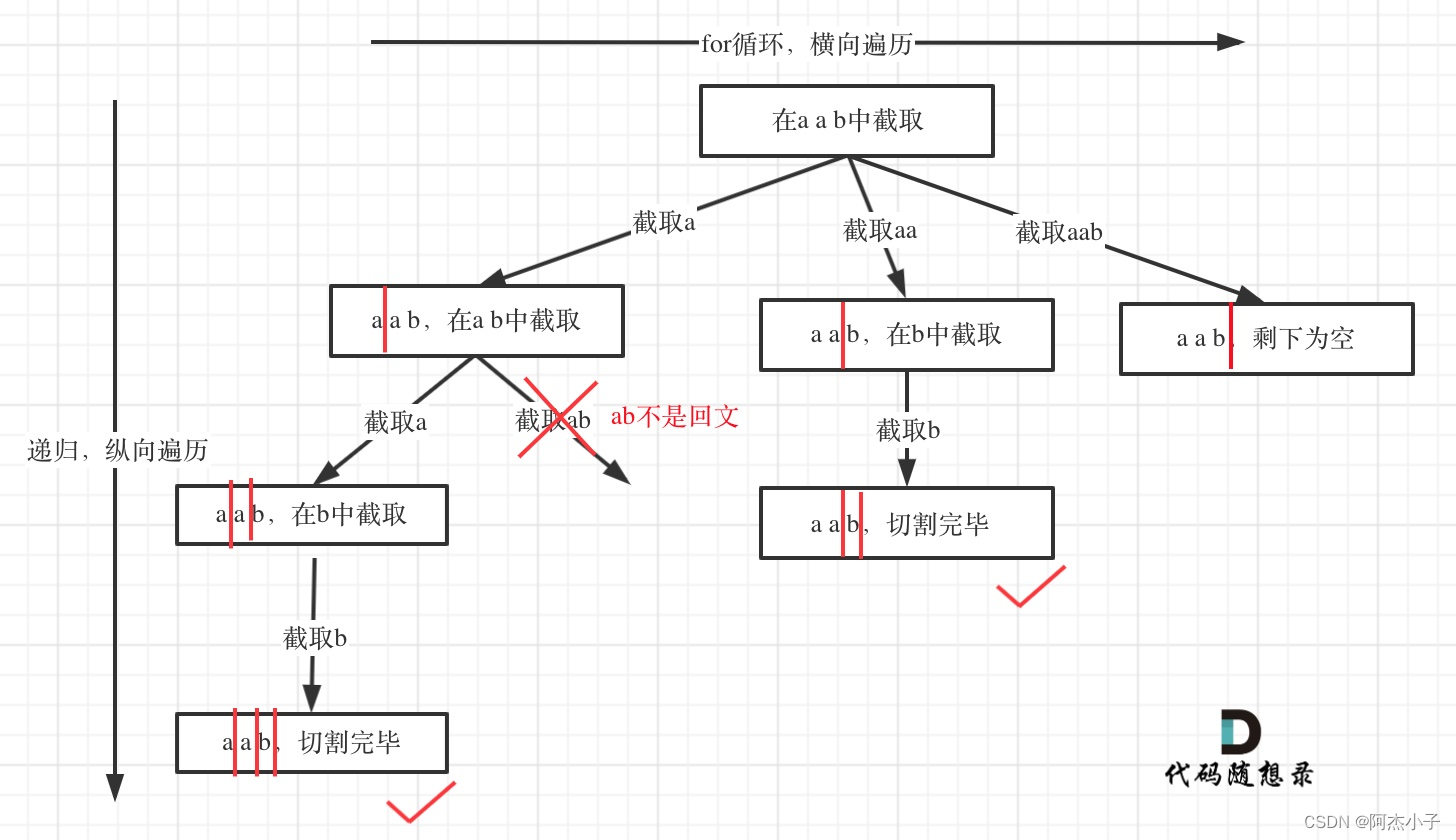
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本层递归的终止条件。在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是切割线。
因此可以写出终止条件的代码:
void backtracking(const string& s, int startIndex){
if(startIndex >= s.size()){
result.push_back(path);
return;
}
}
那么在递归循环中应该如何截取子串:即[startIndex, i]这个区间就是需要截取的子串。并且判断这个子串是不是回文,如果是回文的话,那么就要加入path这个数组当中。
for(int i = startIndex; i <= s.size(); i++){
if(isPalindrome(s, startIndex, i)){
string str = s.substr(stratIndex, i-startIndex+1);
path.push_back(str);
} else {
continue;
}
backtracking(s, i+1);
path.pop_back(); // 回溯过程
}
判断回文串:
bool isPalindrome(const string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
if (s[i] != s[j]) {
return false;
}
}
return true;
}
最终代码:
class Solution {
private:
vector<vector<string>> result;
vector<string> path; // 放已经回文的子串
void backtracking (const string& s, int startIndex) {
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome(s, startIndex, i)) { // 是回文子串
// 获取[startIndex,i]在s中的子串
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else { // 不是回文,跳过
continue;
}
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
path.pop_back(); // 回溯过程,弹出本次已经添加的子串
}
}
bool isPalindrome(const string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
if (s[i] != s[j]) {
return false;
}
}
return true;
}
public:
vector<vector<string>> partition(string s) {
result.clear();
path.clear();
backtracking(s, 0);
return result;
}
};
如何优化?对回文串的判断可以再细分一下,如果一个子串的首尾不相同,那么一定不是回文串。那么如果一个子串是回文串的话,那么其充分必要条件是:s[0]=s[n-1],同时s[1:n-1]是回文字串。因此我们可以在回溯算法当中进行查询
class Solution {
private:
vector<vector<string>> result;
vector<string> path; // 放已经回文的子串
vector<vector<bool>> isPalindrome; // 放事先计算好的是否回文子串的结果
void backtracking (const string& s, int startIndex) {
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome[startIndex][i]) { // 是回文子串
// 获取[startIndex,i]在s中的子串
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else { // 不是回文,跳过
continue;
}
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
path.pop_back(); // 回溯过程,弹出本次已经添加的子串
}
}
void computePalindrome(const string& s) {
// isPalindrome[i][j] 代表 s[i:j](双边包括)是否是回文字串
isPalindrome.resize(s.size(), vector<bool>(s.size(), false)); // 根据字符串s, 刷新布尔矩阵的大小
for (int i = s.size() - 1; i >= 0; i--) {
// 需要倒序计算, 保证在i行时, i+1行已经计算好了
for (int j = i; j < s.size(); j++) {
if (j == i) {isPalindrome[i][j] = true;}
else if (j - i == 1) {isPalindrome[i][j] = (s[i] == s[j]);}
else {isPalindrome[i][j] = (s[i] == s[j] && isPalindrome[i+1][j-1]);}
}
}
}
public:
vector<vector<string>> partition(string s) {
result.clear();
path.clear();
computePalindrome(s);
backtracking(s, 0);
return result;
}
};
2 复原IP地址
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。
例如:“0.1.2.201” 和 “192.168.1.1” 是 有效的 IP 地址,但是 “0.011.255.245”、“192.168.1.312” 和 “192.168@1.1” 是 无效的 IP 地址。
示例 1:
输入:s = “25525511135” 输出:[“255.255.11.135”,“255.255.111.35”] 示例 2:
输入:s = “0000” 输出:[“0.0.0.0”] 示例 3:
输入:s = “1111” 输出:[“1.1.1.1”]
示例 4:
输入:s = “010010” 输出:[“0.10.0.10”,“0.100.1.0”] 示例 5:
输入:s = “101023”
输出:[“1.0.10.23”,“1.0.102.3”,“10.1.0.23”,“10.10.2.3”,“101.0.2.3”]
本质上仍然是切割模型,抽象成树形结构
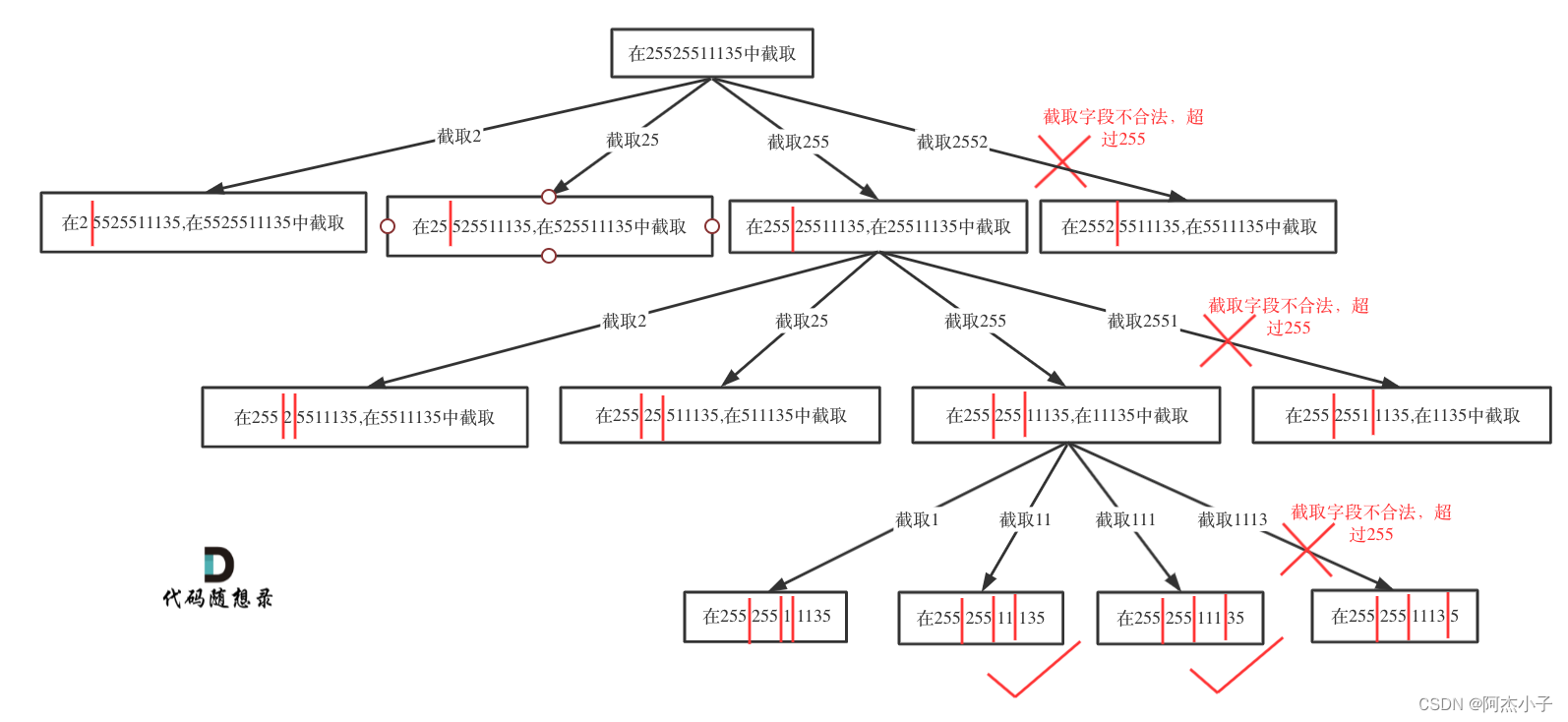
递归函数很明确,但是在本题当中因为要还原出可能的IP地址,所以要加入一个记录逗号的数量。
vector<string> result;
void backtracking(string& s, int startIndex, int pointNum)
本题要求只会被分为4段,因此以分割的段数作为终止条件,当逗号数量达到3个时意味着分成四段了,此时需要判断一下第四段是否合法。
if(pointNum == 3){
if(isValid(s, startIndex, s.size()-1)){
result.push_back(s);
}
return;
}
在for (int i = startIndex; i < s.size(); i++)循环中 [startIndex, i] 这个区间就是截取的子串,需要判断这个子串是否合法。如果合法就在字符串后面加上符号.表示已经分割。如果不合法就结束本层循环,如图中剪掉的分支:
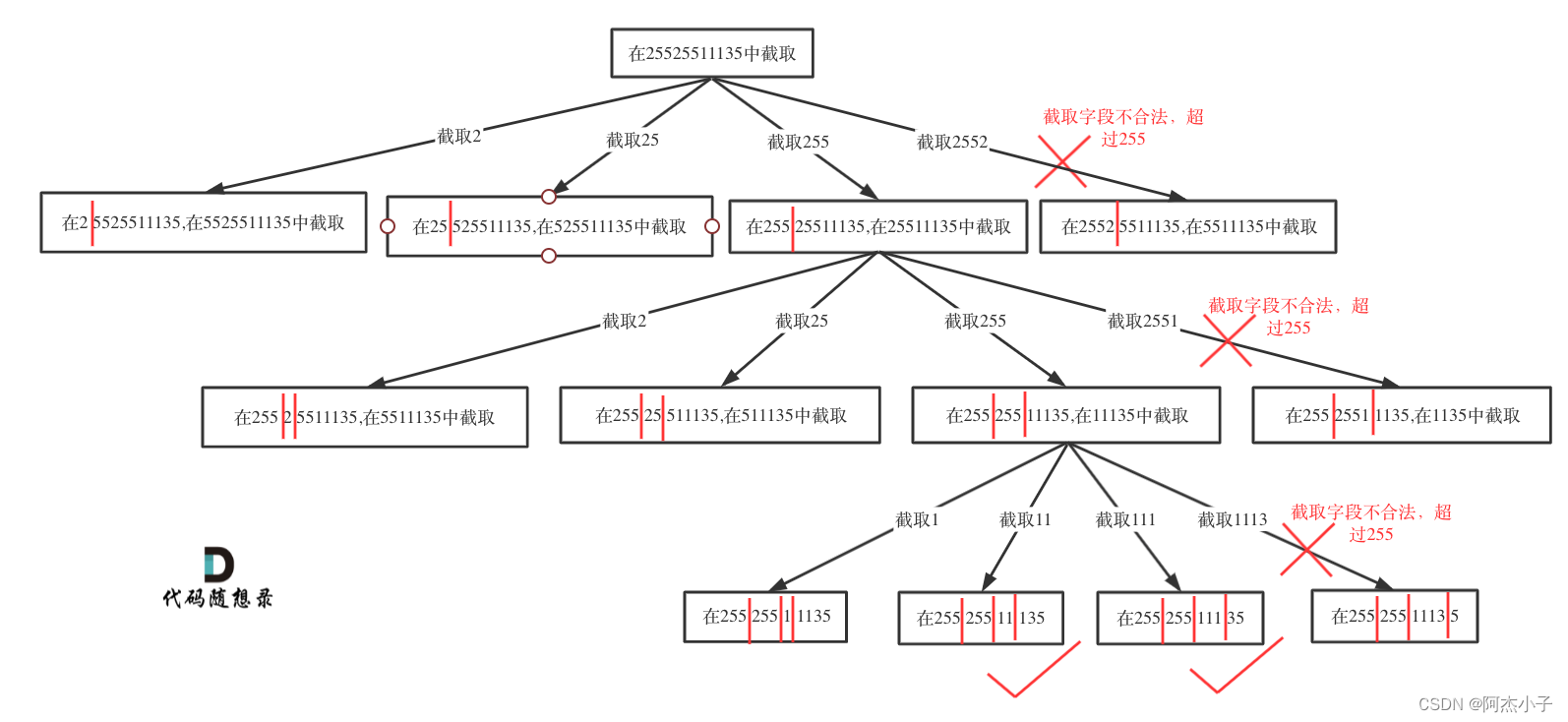
然后就是递归和回溯的过程:递归调用时,下一层递归的startIndex要从i+2开始(因为需要在字符串中加入了分隔符.),同时记录分割符的数量pointNum 要 +1。回溯的时候,就将刚刚加入的分隔符. 删掉就可以了,pointNum也要-1。
代码如下:
for (int i = startIndex; i < s.size(); i++) {
if (isValid(s, startIndex, i)) { // 判断 [startIndex,i] 这个区间的子串是否合法
s.insert(s.begin() + i + 1 , '.'); // 在i的后面插入一个逗点
pointNum++;
backtracking(s, i + 2, pointNum); // 插入逗点之后下一个子串的起始位置为i+2
pointNum--; // 回溯
s.erase(s.begin() + i + 1); // 回溯删掉逗点
} else break; // 不合法,直接结束本层循环
}
判断是否合法:
// 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) { // 0开头的数字不合法
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
return false;
}
num = num * 10 + (s[i] - '0');
if (num > 255) { // 如果大于255了不合法
return false;
}
}
return true;
}
最终代码:
class Solution {
private:
vector<string> result;// 记录结果
// startIndex: 搜索的起始位置,pointNum:添加逗点的数量
void backtracking(string& s, int startIndex, int pointNum) {
if (pointNum == 3) { // 逗点数量为3时,分隔结束
// 判断第四段子字符串是否合法,如果合法就放进result中
if (isValid(s, startIndex, s.size() - 1)) {
result.push_back(s);
}
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isValid(s, startIndex, i)) { // 判断 [startIndex,i] 这个区间的子串是否合法
s.insert(s.begin() + i + 1 , '.'); // 在i的后面插入一个逗点
pointNum++;
backtracking(s, i + 2, pointNum); // 插入逗点之后下一个子串的起始位置为i+2
pointNum--; // 回溯
s.erase(s.begin() + i + 1); // 回溯删掉逗点
} else break; // 不合法,直接结束本层循环
}
}
// 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) { // 0开头的数字不合法
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
return false;
}
num = num * 10 + (s[i] - '0');
if (num > 255) { // 如果大于255了不合法
return false;
}
}
return true;
}
public:
vector<string> restoreIpAddresses(string s) {
result.clear();
if (s.size() < 4 || s.size() > 12) return result; // 算是剪枝了
backtracking(s, 0, 0);
return result;
}
};
3 子集问题
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例: 输入: nums = [1,2,3] 输出: [ [3], [1], [2], [1,2,3], [1,3], [2,3], [1,2], [] ]
仍然是抽象成树形结构:
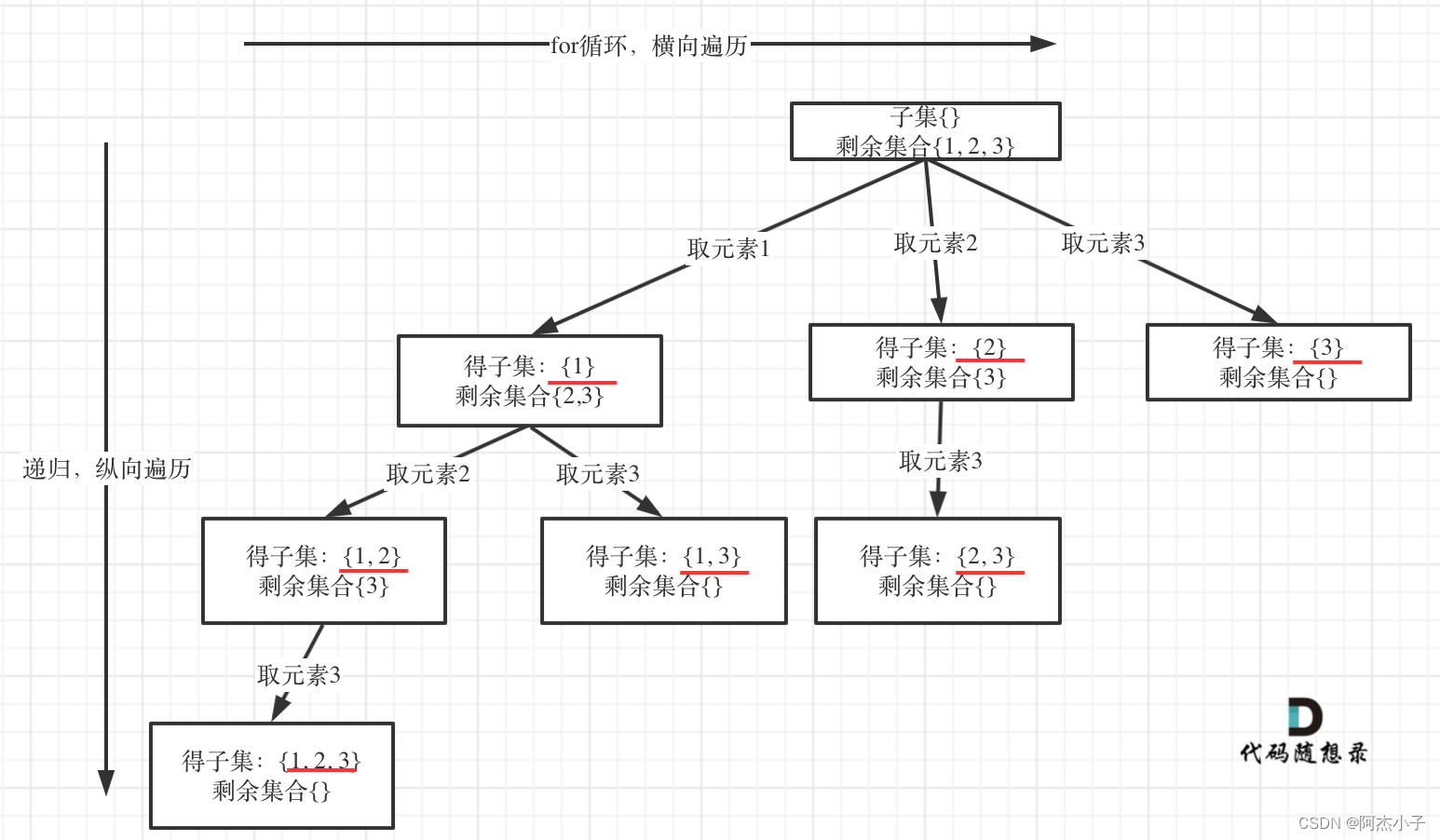
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉自己
if (startIndex >= nums.size()) { // 终止条件可以不加
return;
}
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsets(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
4 子集II
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
输入: [1,2,2]
输出: [ [2], [1], [1,2,2], [2,2], [1,2], [] ]
即子集问题+去重处理的代码整合。剪枝方式如下:一定要先对集合进行排序
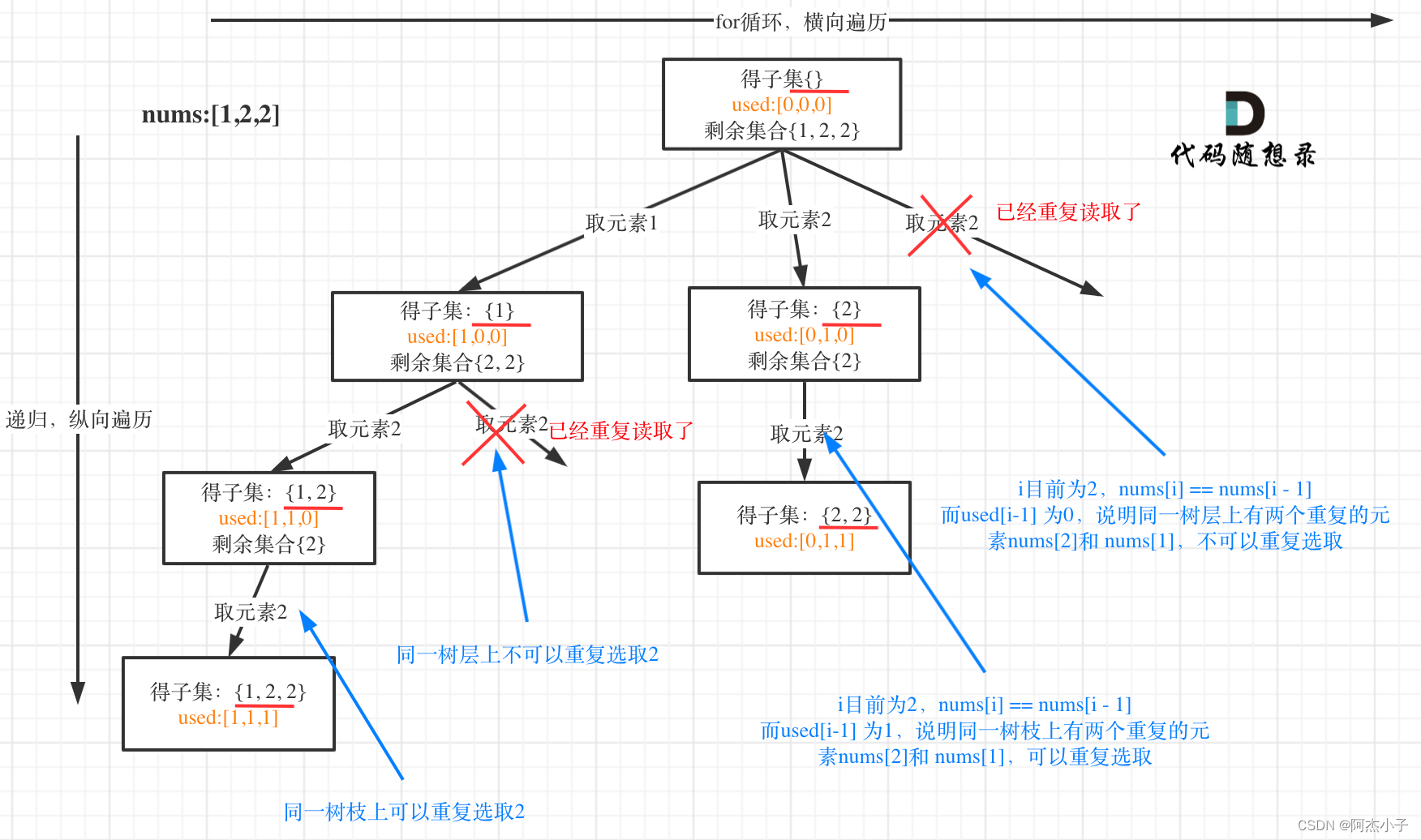
class Solution{
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex, vector<bool>& used){
result.push_back(path);
for(int i = startIndex; i < nums.size(); i++){
//对同一树层使用过的元素进行跳过
if(i>0 && nums[i]==nums[i-1] && used[i-1]==false){
continue;
}
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, i+1, used);
used[i] = false;
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums){
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
sort(nums.begin(), nums.end());
backtracking(nums, 0, used);
return result;
}
}
5 递增子序列
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
示例:
输入: [4, 6, 7, 7] 输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7],
[6, 7, 7], [7,7], [4,7,7]] 说明:给定数组的长度不会超过15。 数组中的整数范围是 [-100,100]。 给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况
本题的特点是要求不能有相同的递增子序列,而本题求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。所以不能使用之前的去重逻辑。
终止条件是遍历树形结构找每一个节点,可不加终止条件,startIndex每次都会加1,并不会无限递归。但要求递增子序列大小至少为2
if (path.size() > 1) {
result.push_back(path);
// 注意这里不要加return,因为要取树上的所有节点
}
单层搜索逻辑:
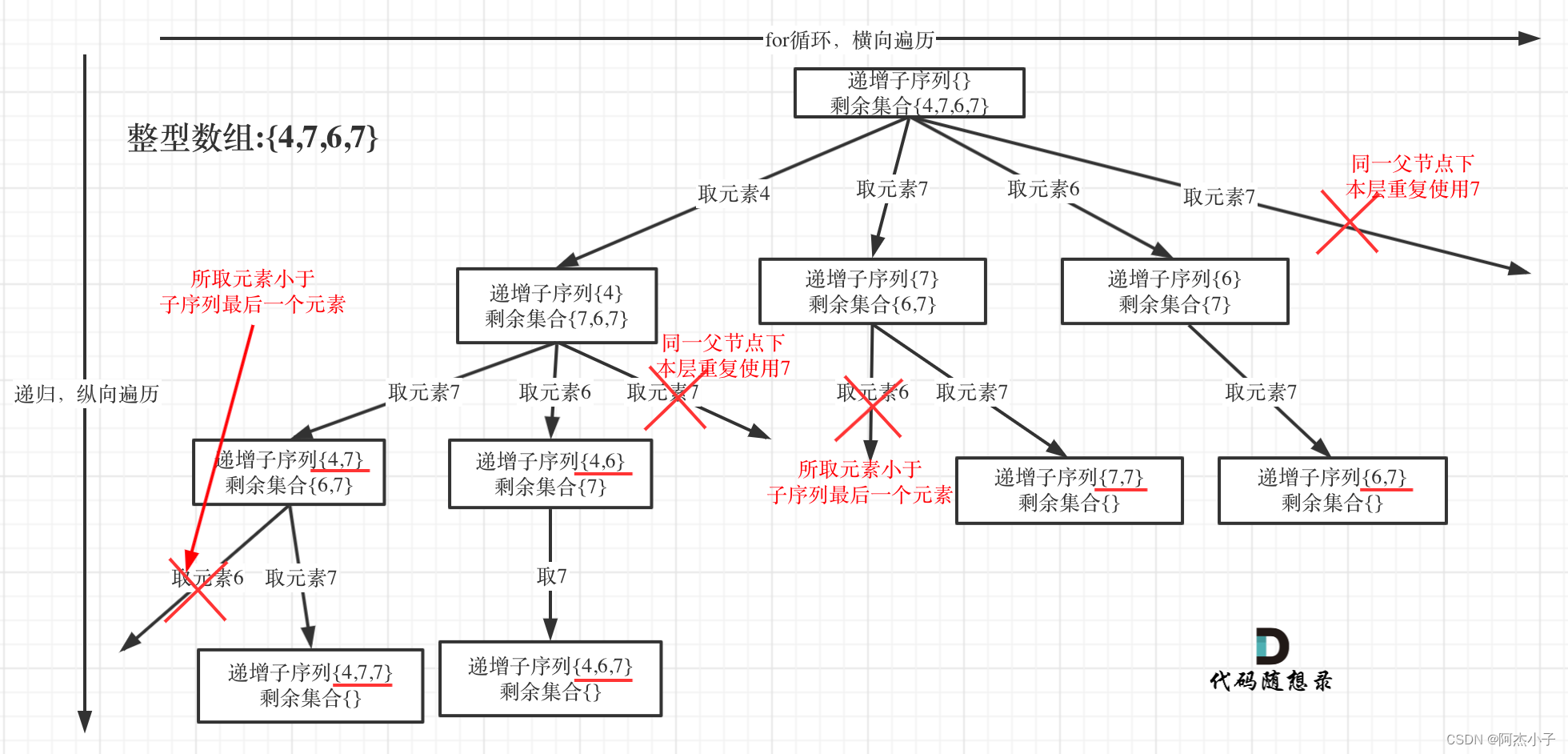
同一父节点下的同层上使用过的元素就不能再使用了,同时对本层的遍历过的元素应该进行记录,不可以再被访问,直到下一层时uset数组再被重新定义,此时单层搜索的代码为:
unordered_set<int> uset;
for(int i = startIndex; i < nums.size(); i++){
if((!path.empty() && nums[i]<path.back()) || (uset.find(nums[i])!= uset.end())
continue;
uset.insert(nums[i]); //记录这个元素在本层用过了,本层后面不能再用了
path.push_back(nums[i]);
backtracking(nums, i+1);
path.pop_back();
}
整体代码:
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
if (path.size() > 1) {
result.push_back(path);
// 注意这里不要加return,要取树上的节点
}
unordered_set<int> uset; // 使用set对本层元素进行去重
for (int i = startIndex; i < nums.size(); i++) {
if ((!path.empty() && nums[i] < path.back())
|| uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]); // 记录这个元素在本层用过了,本层后面不能再用了
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> findSubsequences(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
6 全排列
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3] 输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
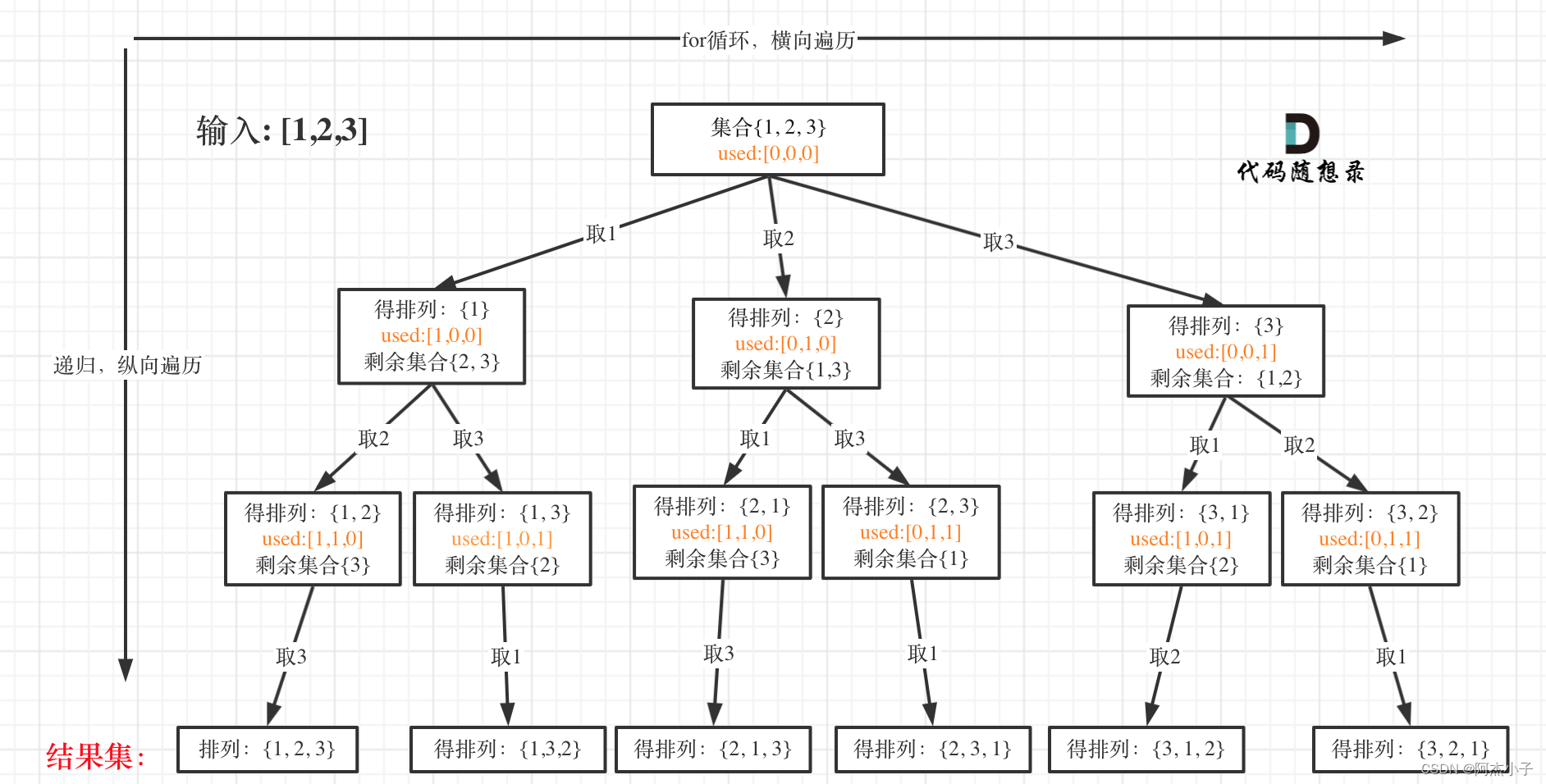
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used) {
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
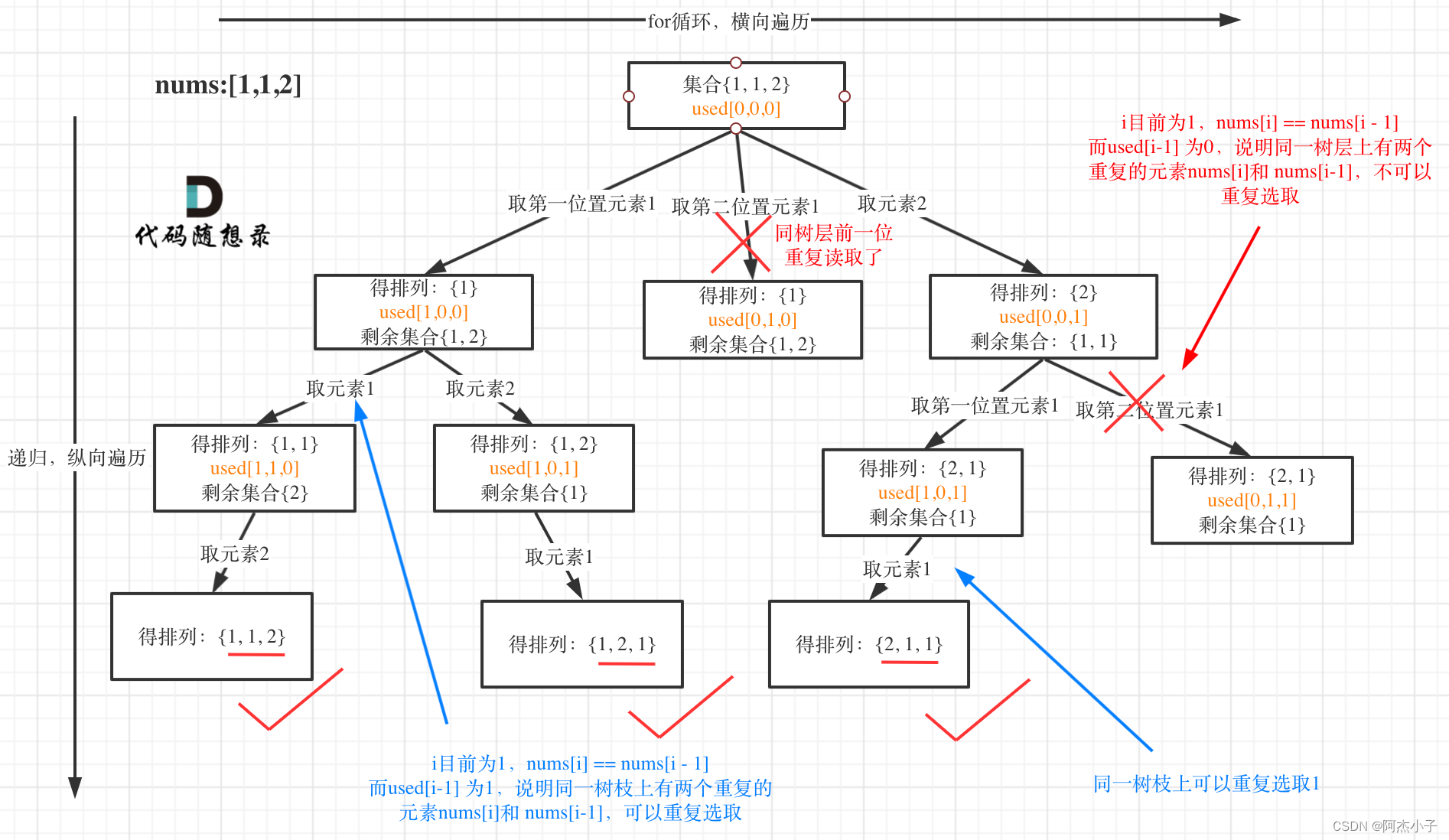
举一反三:给定一个可包含重复数字的序列 nums ,按任意顺序返回所有不重复的全排列。
还要强调的是去重一定要对元素进行排序,这样我们才方便通过相邻的节点来判断是否重复使用了。
我以示例中的 [1,1,2]为例 (为了方便举例,已经排序)抽象为一棵树,去重过程如图
图中我们对同一树层,前一位(也就是nums[i-1])如果使用过,那么就进行去重。
一般来说:组合问题和排列问题是在树形结构的叶子节点上收集结果,而子集问题就是取树上所有节点的结果。
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used) {
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
// used[i - 1] == true,说明同一树枝nums[i - 1]使用过
// used[i - 1] == false,说明同一树层nums[i - 1]使用过
// 如果同一树层nums[i - 1]使用过则直接跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
if (used[i] == false) {
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end()); // 排序
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
7重新安排行程
给定一个机票的字符串二维数组 [from,
to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从
JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。提示:
如果存在多种有效的行程,请你按字符自然排序返回最小的行程组合。例如,行程 [“JFK”, “LGA”] 与 [“JFK”, “LGB”]
相比就更小,排序更靠前 所有的机场都用三个大写字母表示(机场代码)。 假定所有机票至少存在一种合理的行程。 所有的机票必须都用一次 且
只能用一次。 示例 1:输入:[[“MUC”, “LHR”], [“JFK”, “MUC”], [“SFO”, “SJC”], [“LHR”, “SFO”]]
输出:[“JFK”, “MUC”, “LHR”, “SFO”, “SJC”] 示例 2:输入:[[“JFK”,“SFO”],[“JFK”,“ATL”],[“SFO”,“ATL”],[“ATL”,“JFK”],[“ATL”,“SFO”]]
输出:[“JFK”,“ATL”,“JFK”,“SFO”,“ATL”,“SFO”] 解释:另一种有效的行程是
[“JFK”,“SFO”,“ATL”,“JFK”,“ATL”,“SFO”]。但是它自然排序更大更靠后。















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









