





原文链接:https://arxiv.org/pdf/2012.15028v2.pdf
摘要:本文介绍了一种新的图像去噪框架NBNet。与以前的工作不同,我们建议从一个新的角度来解决这个具有挑战性的问题:通过图像自适应投影来降低噪声。具体来说,我们提出通过在特征空间中学习一组重构基来训练一个能够分离信号和噪声的网络。随后,可以通过选择信号子空间的相应基并将输入投影到这样的空间中来实现图像去噪。我们的关键见解是,投影可以自然地保持输入信号的局部结构,尤其是对于光线较弱或纹理较弱的区域。为此,我们提出了SSA,这是一个非局部注意模块,我们设计它来明确地学习基生成以及子空间投影。我们进一步将SSA与NBNet结合起来,NBnet是一个UNet结构化网络,旨在基于端到端图像去噪。我们对包括SIDD和DND在内的基准进行评估,NBNet在PSNR和SSIM实现了最先进的性能,计算成本显著降低。
贡献:
1、我们从子空间投影的新角度来分析图像去噪问题。我们进一步设计了一个简单有效的SSA模块来学习子空间投影,该模块可以插入到正常的中枢神经系统中。
2、我们提出了NBNet,一个带有SSA模块的用于投影图像去噪的UNet。
3、NBNet在许多受欢迎的基准测试中取得了PSNR和SSIM最先进的表现。
4、我们对基于投影的图像去噪进行了深入的分析,证明这是一个很有前途的探索方向。
图像投影的基本概念:
其中从输入图像生成一组图像基向量,然后我们在这些基向量所跨越的子空间内重建图像。由于自然图像通常位于低秩信号子空间中,通过适当地学习和生成基向量,重建的图像可以保留大部分原始信息并且抑制与生成的基集无关的噪声。

通过子空间投影去噪:我们的神经网络学习为信号子空间生成一组基,通过将输入投影到这个空间,信号可以在重建后得到增强,以便于与噪声分离。
模型:

Figure 3:NBNet的整体架构和关键构件的结构。NBNet基于深度为5的UNet架构,我们的SSA模块(subspace attention module,子空间注意力模块)用于从编码器投射跳过连接的特征。
与使用注意模块进行区域或特征选择不同,SSA设计用于学习子空间基础和图像投影。
SSA结构:

1、生成基向量:
![]()
其中x1和x2是图像特征图,V=[v1,v2,,vK]是由基向量组成的矩阵。首先沿着信道轴将x1和x2连接为,然后将其馈送到具有K输出通道的浅残差卷积块中。然后,输出可以重新整形为HW ×K。基础生成块的权重和偏差在训练期间以端到端的方式更新。
2、投影
理论推导参考:线性代数系列(十)--子空间投影和最小二乘法_Thincor的博客-CSDN博客
N=HW,
给定上述矩阵,它的列是k维信号子空间
的基向量,我们可以将图像特征图x1通过正交线性投影投影到V上。最后,图像特征图X1能在信号子空间中被重构为Y。
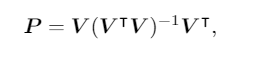
![]()
损失函数:
一个解码器的输出通过线性3×3卷积层作为噪声输入的全局残差,并输出去噪结果。网络是用干净和有噪声的图像对训练的,我们使用简单的“L1干净图像和去噪结果之间的距离”作为损失函数,写成:

x,y,G(.)分别表示干净图像,噪声图像,NBNet
实验:
我们评估了我们的方法在合成数据集和真实数据集上的性能,并将其与以前的方法进行了比较。接下来,我们描述实现细节。然后我们在五个真实图像数据集上报告结果。最后,我们进行消融研究以验证所提出方法的优越性。
1、训练设置
建议的体系结构不需要预先培训,可以通过端到端策略进行培训。对于所有模块,经验将子空间K的数量设置为16。在训练阶段,根据kaiming初始化整个网络的权重。我们使用带有动量项(0.9,0.999)的Adam 优化器。初始学习速率设置为2×104,降低学习速率的策略是余弦退火。训练过程需要700000次小批量迭代。在训练期间,从每个训练对中裁剪出128 ×128大小的补丁作为一个实例,32个实例堆叠成一个小批量。我们对图像应用随机旋转、裁剪和翻转来增加训练数据。
2、合成高斯噪声上的实验
使用Variational Denoising Network: Toward Blind Noise Modeling and Removal (VDN)中提到的训练方法:训练数据集包括来自BSD的432幅图像,来自ImageNet验证集的400幅图像,以及 Waterloo Exploration Database的4744幅图像。评估测试数据集由set5 、LIVE1 和BSD68 生成。为了实现公平的比较,我们使用与VDN相同的噪声生成算法,其中非整数高斯噪声通过以下方式生成:

其中M是空间变化的掩模。生成四种类型的掩码,一种用于训练,三种用于测试。通过这种方式,可以很好地测试降噪模型的泛化能力。
3、SIDD基准测试实验
智能手机图像去噪数据集(SIDD) 是使用五个具有代表性的智能手机相机在不同照明条件下从10个场景获得的大约30,000幅噪声图像,并通过系统的过程生成它们的地面真实图像。SIDD可以用来衡量智能手机摄像头的降噪性能。作为基准,SIDD分割了1280张彩色图像进行验证。在本节中,我们使用SIDD基准来验证我们的方法在真实世界降噪任务中的性能。

4、DND基准测试实验
DND数据集由50对真实噪声图像和相应的地面真实图像组成,对于每一对,源图像以基本的ISO水平拍摄,而有噪声的图像以较高的ISO和适当调整的曝光时间拍摄。参考图像经过仔细的后处理,包括小的相机偏移调整、线性强度缩放和低频偏差的消除。经过后处理的图像作为DND基准的基础事实。
我们在包含50幅测试图像的DND数据集上评估了我们的方法的性能。它提供了边界框,用于从每个图像中提取20个面片,总共得到1000个面片。请注意,DND数据集不提供任何训练数据,因此我们通过组合SIDD和Renoir的数据集来采用训练策略。通过使用在SIDD基准上提供最佳验证性能的同一模型,将结果提交给DND基准。
下载链接:Darmstadt Noise Dataset – Darmstadt Noise Dataset
切除研究:
我们检查了我们模型的三个主要决定因素:a)另一个网络的SSA模块,以及b)信号子空间的维数,即基向量的数量K . c) 关于投影的选项。
1、集成到DnCNN
为了评估我们提出的SSA模块的有效性,我们考虑了另一个经典架构DnCNN作为基线。为了使用等式2中所示的X1和 x2,我们将第一个卷积的特征视为x1,将最后一个卷积之前的特征视为X2。

2、不同k值的影响

3、关于投影的选项















 4437
4437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









