






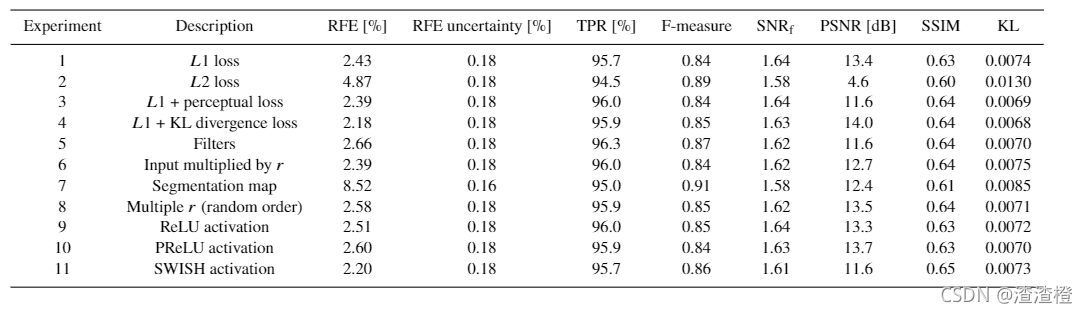
 本文介绍了一种名为AstroU-net的卷积神经网络,用于天文图像的去噪和增强。该网络能模拟长曝光图像,同时保持信息的高保真度。在哈勃太空望远镜的图像数据集上进行实验,AstroU-net成功恢复了95-9%的恒星,平均通量误差2-26%,并提高了图像的信噪比,减少了未来天文观测所需的时间。
本文介绍了一种名为AstroU-net的卷积神经网络,用于天文图像的去噪和增强。该网络能模拟长曝光图像,同时保持信息的高保真度。在哈勃太空望远镜的图像数据集上进行实验,AstroU-net成功恢复了95-9%的恒星,平均通量误差2-26%,并提高了图像的信噪比,减少了未来天文观测所需的时间。
摘要:天文图像对于探索和理解宇宙至关重要。能够进行深度观测的光学望远镜,如哈勃太空望远镜,在天文学界被大量订购。图像通常还包含加性噪声,这使得在进一步数据分析之前对数据进行后处理时,必须先去噪。为了最大限度地提高天文成像后处理的效率和信息增益,我们转向机器学习。我们提出了一种用于图像去噪和增强的卷积神经网络Astro U-net。为了证明这一概念,我们使用了来自WFC3仪器UVIS的哈勃太空望远镜图像以及F555W和F606W滤光片。我们的网络能够产生具有噪声特性的图像,就像它们是以两倍的曝光时间获得的一样,并且具有最小的偏差或信息损失。从这些图像中,我们能够恢复95-9%的恒星,平均通量误差为2-26%。此外,这些图像的平均信噪比比比输入噪声图像高1-63倍,相当于至少3张输入图像的叠加,这意味着未来天文成像活动所需的望远镜时间大大减少。
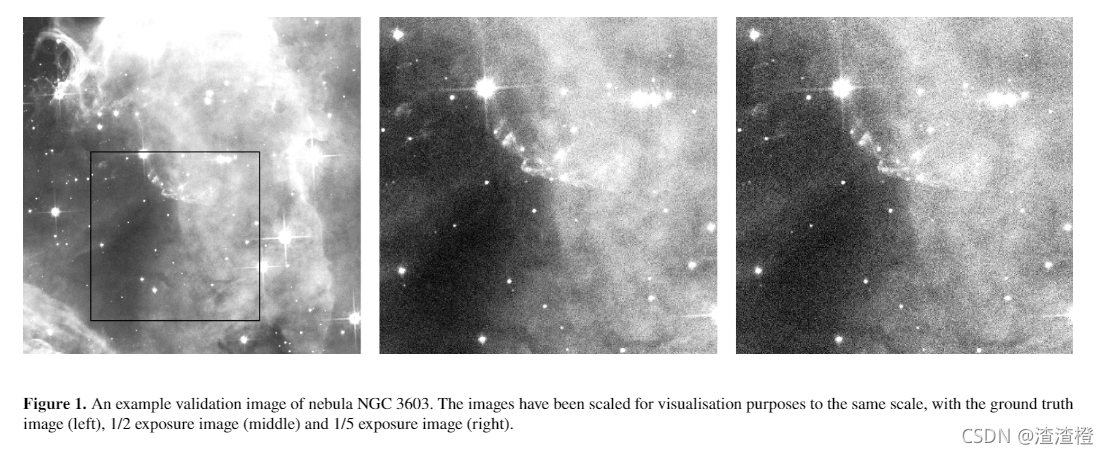
数据集:我们的数据集包含来自哈勃太空望远镜(HST)档案(图1)的200幅图像,这些图像分为160/20/20图像的训练、评估和验证数据集。数据集是人工选择的——我们通过一千多幅图像创建了最终的数据集,其中包括各种尺度的天文物体。
添加噪声:
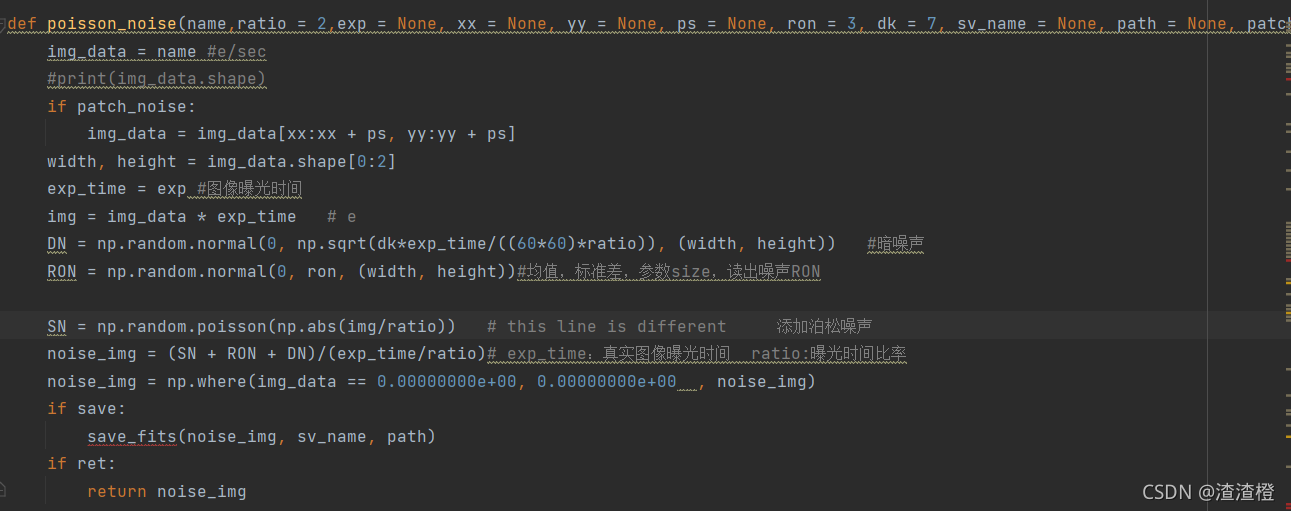
1、天文图像中的观测信号会受到各种噪声的影响。为了创建用于网络输入的合成数据,我们考虑光子散粒噪声、暗噪声和读出噪声。从远处探测到的光子数量具有固有的统计变化,与之相关的噪声是:
![]()
S是被相机捕捉的总信号,Pois(X)是X的泊松分布。
2、暗噪声来自探测器的热激发电子,它强烈地依赖于CCD的温度,并且与落在探测器上的光子无关,因此即使相机处于完全黑暗中,这种噪声也会持续存在。这个噪声也是泊松分布的,但是我们使用了由暗电流(DK)计算的高斯近似:
![]()
t:图像的曝光时间。
3、读出噪声(RON)是由CCD的电子器件引起的所有像素的均匀噪声。我们使用WFC3仪器手册1中的读出噪声和暗电流值。
曝光时间比率是真实图像的曝光时间与较短模拟图像的曝光时间之间的比率。不同比率的示例如图1所示。
在添加噪声之前,我们通过分割真实图像来创建合成的短曝光图像,通过曝光时间比𝑟:
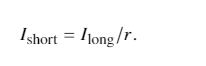
曝光时间比率是真实图像的曝光时间与较短模拟图像的曝光时间之间的比率


去噪模型:
损失函数:
1、L1loss:(最小平均值偏差)

2、L2loss(MSE loss)(最小均方误差)

![]() 2、perceptual loss(感知损失):
2、perceptual loss(感知损失):
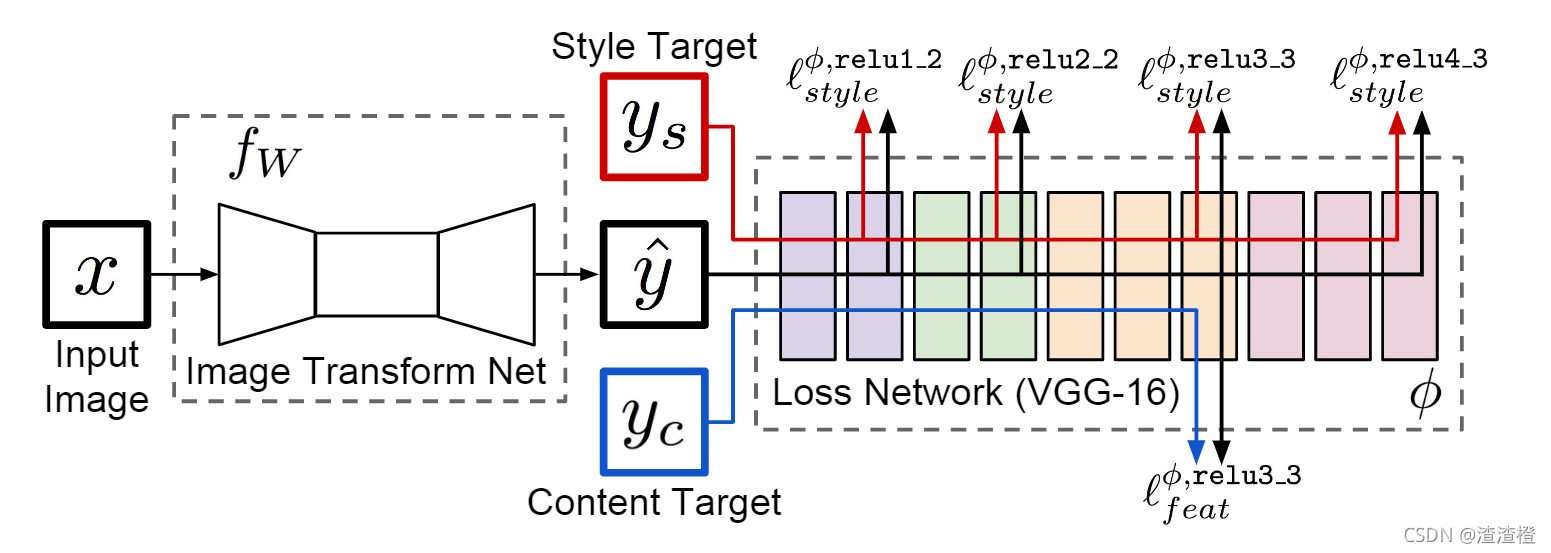
论文:Perceptual Losses for Real-Time Style Transfer and Super-Resolution。
相关代码链接:GitHub - vijishmadhavan/ArtLine: A Deep Learning based project for creating line art portraits.
高质量的图像可以通过定义和优化perceptual loss函数来生成,该损失函数基于使用预训练好的网络提供的高层的特征。有强的惩罚,对小的error的惩罚低,忽略了图像内容本身的影响。实际上人眼视觉系统(HVS)对图像中的无纹理区域的亮度和颜色变化更敏感。而目前使用的感知域损失,即Perceptual loss,个人认为在得到感知域内容的过程中,对图像的内容进行了一次提炼,因此在感知域空间中计算损失相当于结合图像内容的损失,会使得复原后的图像视觉效果上更好。
它是将真实图片卷积得到的feature(一般是用vgg16或者vgg19来提取)与生成图片卷积得到的feature作比较(一般用MSE损失函数),使得高层信息(内容和全局结构)接近,也就是感知的意思。
也就是说,给定两张图,我们不直接比较他们的像素级差异,而是均将他们放入同一网络中,获取某一中间层的输出特征图,然后再用一些传统的loss计算特征图之间的差异即可。在Perceptual Losses for Real-Time Style Transfer and Super-Resolution一文中使用的网络是VGG16,也可以使用一些其他的预训练深度网络(如ResNet, GoogLeNet,VGG19),不过一般VGG16的效果最好。
例:使用vgg19、MES
import torch.nn as nn
import torch
import torch.nn.functional as F
from torchvision.models import vgg16_bn
class FeatureLoss(nn.Module):
def __init__(self, loss, blocks, weights, device):
super().__init__()
self.feature_loss = loss
assert all(isinstance(w, (int, float)) for w in weights)#w不是int或float类型则抛出异常
assert len(weights) == len(blocks)#权重和选择的层数长度一致
self.weights = torch.tensor(weights).to(device)#
#VGG16 contains 5 blocks - 3 convolutions per block and 3 dense layers towards the end
assert len(blocks) <= 5
assert all(i in range(5) for i in blocks)
assert sorted(blocks) == blocks
#首先是导入torchvision中的vgg16,利用eval和requires_grad=False将权重冻结,方便我们输出特征图
vgg = vgg16_bn(pretrained=True).features
vgg.eval()
for param in vgg.parameters():
param.requires_grad = False
vgg = vgg.to(device)
#接着是取出vgg16中五个块的输出。这五个块都以max pool结尾,但是考虑到max pool层以及其上的relu层对比较特征图没有帮助(存疑),因此这里取出的是max pool前两层的batch norm层作为五个块的输出:
bns = [i - 2 for i, m in enumerate(vgg) if isinstance(m, nn.MaxPool2d)]
assert all(isinstance(vgg[bn], nn.BatchNorm2d) for bn in bns)
#然后,对于我们指定的blocks(需要取出哪几层的输出),将相应bn层使用register_forward_hook方法来获取其输出:
self.hooks = [FeatureHook(vgg[bns[i]]) for i in blocks]
#features其实就是一个精简的vgg16。我们需要哪几层的输出,就保留这几层之前的结构。如果我们只需要前两块的输出,那么后面三块其实就可以去掉了,减少运算量。
self.features = vgg[0: bns[blocks[-1]] + 1]
def forward(self, inputs, targets):
# normalize foreground pixels to ImageNet statistics for pre-trained VGG
mean, std = [0.485, 0.456, 0.406], [0.229, 0.224, 0.225]
inputs = F.normalize(inputs, mean, std)
targets = F.normalize(targets, mean, std)
#最后,将input和target输入网络,利用hook提取出特征图,对这些特征图进行对比,即可求解feature loss:
# extract feature maps
self.features(inputs)
input_features = [hook.features.clone() for hook in self.hooks]
self.features(targets)
target_features = [hook.features for hook in self.hooks]
loss = 0.0
# compare their weighted loss
for lhs, rhs, w in zip(input_features, target_features, self.weights):
lhs = lhs.view(lhs.size(0), -1)
rhs = rhs.view(rhs.size(0), -1)
loss += self.feature_loss(lhs, rhs) * w
return loss
class FeatureHook:
def __init__(self, module):
self.features = None
self.hook = module.register_forward_hook(self.on)
def on(self, module, inputs, outputs):
self.features = outputs
def close(self):
self.hook.remove()
def perceptual_loss(x, y):
F.mse_loss(x, y)
def PerceptualLoss(blocks, weights, device):
return FeatureLoss(perceptual_loss, blocks, weights, device)

3、KL divergence loss

代码实现:
import torch.nn.functional as F
# p_logit: [batch, class_num]
# q_logit: [batch, class_num]
def kl_categorical(p_logit, q_logit):
p = F.softmax(p_logit, dim=-1)
_kl = torch.sum(p * (F.log_softmax(p_logit, dim=-1)
- F.log_softmax(q_logit, dim=-1)), 1)
return torch.mean(_kl)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









