









互联网大厂双十一高并发实战
文章目录
前言

双十一购物始于2009年,历年的订单创建、支付笔数与交易总额都是成倍增长,这不仅带来许多商业机遇,也给后端技术、架构等各个模块带来技术沉淀。双11为MySQL带来了高并发场景的问题与挑战,主要表现在:
1)洪峰般的并发
根据市场部部门的推广和引流、历年双11的经验,大促的起始时刻呈现接近90度上升趋势。在这么大访问流量下,所有的核心链路的增删改查都是在数据库上操作,对数据库有比较大的冲击,在大量线程并发工作时线程调度工作过多、大量缓存失效、资源竞争加剧、锁冲突严重,如果有复杂SQL或大事务的话还可能导致系统资源耗尽,整个数据库服务不可用,进而导致大促收到影响,甚至失败,比如:下单失败、网页无法打开、无法支付等。此外此类场景也会发生在在线教育、直播电商、在线协同办公等。
2)热点行更新
库存扣减场景是一个典型的热点问题,当多个用户去争抢扣减同一个商品的库存(对数据库来说,一个商品的库存就是数据库内的一行记录),数据库内对同一行的更新由行锁来控制并发。当单线程(排队)去更新一行记录时,性能非常高,但是当非常多的线程去并发更新一行记录时,整个数据库的性能会跌到趋近于零。
3)突发SQL访问
当缓存穿透或异常调用、有数据倾斜SQL、未创建索引SQL等情况发生时,在高并发场景下很容易导致数据库压力过大,响应过慢,导致应用链接释放慢,导致整个系统不可用。
一、数据库架构设计
数据库架构

如果业务的访问都用数据库支撑的话成本高昂,缓存可以代替一部分关系型数据库在读方面的请求。基于原理的设计以及成本方面考虑,缓存的读性能比关系型数据库好,性价比较高。
到数据库层面,如果是读多写少,针对于单个实例很难支撑的情况下,可以借助于只读实例。只读实例可以实现在线弹性的扩展读能力,读的业务请求可以实现隔离,例如可以把轻分析型以及拖数据类型在只读实例内完成。
此外,每个只读实例都有一个单独的链接地址,如果把某一类的业务和其他的业务区分开,例如某一类的只读的这个场景,只到某一个实例访问,可以单独链接只读实例的链接串。
如果要是想从整个层面来控制主实例和只读实例的访问,可以借助负载均衡独享代理完成。独享代理可以缓解大量短链接的场景,使用代理后不用反复变更应用类的链接地址,减少维护成本。使用独享代理之后,可以对线上的资源实现可扩展,承受更高的流量。如果是RDS的实例规格以及只读实例都已经升到最大,但仍然不能支撑业务发展的话,可以考虑把RDS的升级到Polar MySQL或者是分库分表PolarDB X 2.0,完成读写容量的扩展。
降低只读实例和主实例的延迟
针对主实例和只读实例的数据一致性的问题,例如有延迟以及中断场景。针对线上延迟的问题我们做了分析,得出原因主要包括5个方面:
1)主实例的DDL
占40%,如Alter、Drop等。需要Kill DDL语句或用DMS的无锁变更等。
2)主实例的大事务
占20%,如大批量导入、删除、更新数据。需要将大事务拆分成为小事务进行批量提交,这样只读节点就可以迅速地完成事务的执行,不会造成数据的延迟。
3)主实例写入压力过大
占20%,如主实例规格较小、压力过大。这种情况需要升级主实例和只读实例的规格。
4)只读节点规格过小
占10%,这种情况升级只读实例规格。
5)其他(无主键)
占10%, RDS目前已经支持对表添加隐式主键,但是对于以前历史创建的表需要进行重建才能支持隐式主键。
提升缓存命中率
在高并发场景下,写入压力过大,如何提升缓存的命中率?
根据以往的经验,有4种更新方式:Cache aside,Read through,Write through,Write behind caching。
缓存的更新时,应用可以从Cache里面读取数据,取到后返回,没有得到从数据库里面取,成功后再返回缓存当中;Read through是已读没有读到,就更新缓存;Right through是在数据更新时,发现缓存中没有就更新缓存;Write behind caching类似于底层的 Linux操作系统机制,如果要是用Write behind caching合并同一个数据的多次操作,以上几种方式都不能保证缓存命中率。

应用程序把写请求到 RDS,读请求到 Redis。RDS实时获取变更数据,通过订阅数据变更的方式拿到增量数据后,更新Redis。这种思路其实比上面几种策略更有突破性。
二、系统调优
1.扩容优化
有两种方式,分为本机扩容和跨机扩容:

2.参数调优

连接相关的参数,back_log值表示在MySQL暂时停止响应新请求之前的这段短时间内可以堆叠多少请求。如果在短时间内有大量的连接请求时,主线程会在一段时间内或者是瞬间检查连接数并启动新连接。
table_open_cache是所有线程打开表的数量,性能较小时会导致性能下降,但也不能设置过大,否则可能会造成 OOM。
IO相关的参数,sync_binlog大家不会陌生,我们在每年的双11会将这些数值调到最优。io_capacity和刷脏是IO两个比较重要的参数。
内存相关的主要参数是innodb_buffer_pool_instances。在5.6之前,相对来说innodb_buffer_pool_instances只有一个时,如果内存越大,它的性能越不稳定,因为刷脏的时候要锁。当有buffer_pool_instances了之后,把 Buffer Pool按buffer_pool_instances拆分。这种情况下,每一个内存都会维护自己的List和锁结构,性能会提升很多。此外还有和几个连接相关的参数,例如join_buffer以及临时表。
针对影响性能几个主要的参数,用户可以单独设置。这里我们已经将对性能影响较大的参数调到高性能模板中,应用时可以找到对应的参数,应用到对应的实例上即可。
三、稳定可用
1 .设置超时时间

稳定性相关,不要因为人为的因素给系统造成压力,可以通过设置DMS来执行的这些SQL,不让它超过一定的时间,超过一定时间则Kill掉。
2 . 禁用部分语法

可针对DDL、DML设置部分语法不允许在大促期间执行。
3 . 异步清理大表

AliSQL支持通过异步删除大文件的方式保证系统稳定性。使用InnoDB引擎时,直接删除大文件会导致POSIX文件系统出现严重的稳定性问题,因此InnoDB会启动一个后台线程来异步清理数据文件。当删除单个表空间时,会将对应的数据文件先重命名为临时文件,然后清除线程将异步、缓慢地清理文件。
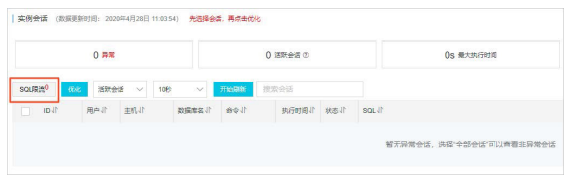
4 . 突发SQL访问控制
·内核特性–并发控制
当业务流量突然暴涨,或出现 Bad SQL 时,DBA要考虑做限流,止损恢复业务。AliSQL设计了基于语句规则的并发控
制,Statement Concurrency Control,简称 CCL。
·DAS限流
为防止数据库压力过大,一般都会在应用端做优化和控制。但在以下场景,也需要在数据库端做优化控制,如:
1)某类SQL并发急剧上升;
2)有数据倾斜SQL;
3)未创建索引SQL。
5 .数据恢复
DMS数据追踪


·功能
1)在线搜索日志内容,无需手工下载 Binlog;
2)支持数据的插入/更新/删除日志搜索,无需手工解析Binlog;
3)支持逐条数据恢复,无需手工生成回滚语句。
·支持的Binlog
1)OSS Binlog(RDS会定时将Binlog备份到OSS上);
2)本地热Binlog(数据库服务器上Binlog)。
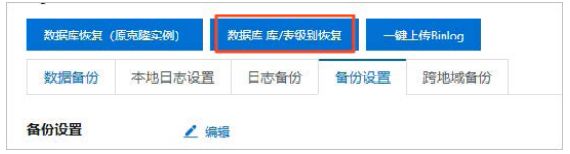
控制台克隆实例/库表级别恢复
数据恢复还可通过备份来实现,可分为克隆整个实例恢复与库表级别恢复,还可以通过DBS数据库备份来恢复。
路径:RDS管理控制台->实例列表->单击实例ID->备份恢复
总结
总结以上内容,系统调优主要从架构设计,稳定可用等方面实现。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









