






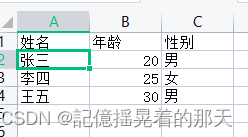
先看效果,这是一个csv表格
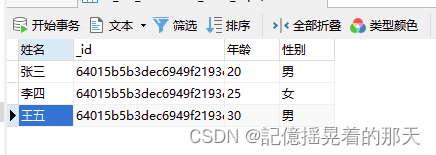
读取到MongoDB之后
技术难点
csv文件内容的编码格式
常见的中文编码格式:
- GB2312
- GBK
- GB18030
- UTF-8
- Big5
需要随所有格式进行处理
解决方案:
1、org.apache.tika用来判断文件内容编码格式
2、中文格式用对应的中文编码处理,其他的编码格式用GB18030处理
3、GB18030是GBK的超集
代码
依赖
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.5.2</version>
</dependency>
<!--解析文件的编码格式-->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>1.27</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers</artifactId>
<version>1.27</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-serialization</artifactId>
<version>1.27</version>
</dependency>
工具类
import com.mongodb.client.MongoCollection;
import com.mongodb.client.result.InsertManyResult;
import org.apache.commons.codec.binary.Hex;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.apache.tika.detect.EncodingDetector;
import org.apache.tika.io.TikaInputStream;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.parser.txt.CharsetDetector;
import org.apache.tika.parser.txt.CharsetMatch;
import org.apache.tika.parser.txt.Icu4jEncodingDetector;
import org.apache.tika.sax.BodyContentHandler;
import org.bson.Document;
import org.jetbrains.annotations.NotNull;
import org.springframework.data.mongodb.core.MongoTemplate;
import javax.annotation.Resource;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
/**
* @Author : dengzhilin
* @create 2023/3/2 9:48
*/
public class FileDataImportMongoDB {
private static MongoTemplate mongoTemplate = SpringUtil.getBean(MongoTemplate.class);
public static Boolean importMongoDB(InputStream inputStream,String fileName) throws Exception {
List<Document> documents = null;
if (fileName.endsWith(".xlsx")) {
documents = xlsxToDocuments(inputStream);
}
if (fileName.endsWith(".csv")) {
documents = csvToDocuments(inputStream);
}
if(fileName.endsWith(".xls")){
documents = xlsToDocuments(inputStream);
}
// 3. 存储数据到MongoDB
if (documents != null && documents.size() > 0) {
MongoCollection<Document> collection = mongoTemplate.getCollection("tb_file_data");
InsertManyResult insertManyResult = collection.insertMany(documents);
return insertManyResult.wasAcknowledged();
}
return false;
}
@NotNull
private static List<Document> xlsToDocuments(InputStream inputStream) throws IOException {
Workbook workbook = new HSSFWorkbook(inputStream);
Sheet sheet = workbook.getSheetAt(0);
Row headerRow = sheet.getRow(0);
int rowCount = sheet.getLastRowNum();
List<Document> documents = new ArrayList<>();
for (int i = 1; i <= rowCount; i++) {
Row row = sheet.getRow(i);
if(row != null) {
Document document = new Document();
for (int j = 0; j < headerRow.getLastCellNum(); j++) {
Cell headerCell = headerRow.getCell(j);
Cell cell = row.getCell(j);
if(cell != null){
document.append(headerCell.getStringCellValue(), getCellValue(cell));
}
}
documents.add(document);
}
}
return documents;
}
private static Object getCellValue(Cell cell) {
if (cell == null) {
return null;
}
switch (cell.getCellType()) {
case NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
return cell.getDateCellValue();
} else {
return cell.getNumericCellValue();
}
case STRING:
return cell.getStringCellValue();
case BOOLEAN:
return cell.getBooleanCellValue();
case FORMULA:
return cell.getCellFormula();
default:
return null;
}
}
@NotNull
private static List<Document> csvToDocuments(InputStream inputStream) throws Exception {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len;
while ((len = inputStream.read(buffer)) != -1) {
baos.write(buffer, 0, len);
}
byte[] bytes = baos.toByteArray();
// 由于InputStream不支持mark方法,需要转成ByteArrayInputStream
ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
// 获取文件的编码格式
String charset = detectCharset(bais);
// 用文件的编码格式读取文件
BufferedReader reader = new BufferedReader(new InputStreamReader(bais,charset));
String line = null;
String[] headers = null;
List<Document> documents = new ArrayList<>();
while ((line = reader.readLine()) != null) {
String[] fields = line.split(",");
if (headers == null) {
// 表头
headers = fields;
// 表头格式转换
convertStrings(headers,charset);
} else {
if (fields.length < headers.length) {
// 列数不足,可以选择跳过该行或者使用默认值来填充缺失的列
continue;
}
Document document = new Document();
for (int i = 0; i < headers.length; i++) {
// 内容格式转换
String content = convertBytesToString(fields[i].getBytes(Charset.forName(charset)),charset);
document.append(headers[i],content);
}
documents.add(document);
}
}
return documents;
}
public static void convertStrings(String[] strs, String charsetName) throws UnsupportedEncodingException {
for (int i = 0; i < strs.length; i++) {
String header = strs[i];
strs[i] = convertBytesToString(header.getBytes(Charset.forName(charsetName)),charsetName);
}
}
public static String convertBytesToString(byte[] bytes,String charsetName) throws UnsupportedEncodingException {
if (bytes == null) {
return null;
}
// 如果编码格式是中文的格式则用中文编码进行转换
if("UTF-8".equals(charsetName)){
return new String(bytes, "UTF-8");
}
if("GBK".equals(charsetName)){
return new String(bytes, "GBK");
}
if("GB2312".equals(charsetName)){
return new String(bytes, "GB2312");
}
if("Big5".equals(charsetName)){
return new String(bytes,"Big5");
}
// 其他编码格式和GB18030格式都用GB18030转,因为解析的文件都是中文和英文混合的
Charset charset = Charset.forName("GB18030");
String res = new String(bytes, charset);
return res;
}
public static String detectCharset(ByteArrayInputStream inputStream) throws Exception {
CharsetDetector detector = new CharsetDetector();
if(inputStream.markSupported()){
// 标记文件头
inputStream.mark(0);
}
// setText会调用mark方法
detector.setText(inputStream);
// setText执行后文件指针会在文件中间,需要调用reset重置指针到上面标记的位置,也就是文件头
inputStream.reset();
// 匹配编码格式
CharsetMatch charsetMatch = detector.detect();
// 获取编码格式
String encoding = charsetMatch.getName();
return encoding;
}
@NotNull
private static List<Document> xlsxToDocuments(InputStream inputStream) throws IOException {
// 1. 读取Excel文件
XSSFWorkbook workbook = new XSSFWorkbook(inputStream);
XSSFSheet sheet = workbook.getSheetAt(0);
// 2. 解析每行数据并转换成Java对象
List<Document> documents = new ArrayList<>();
Row headerRow = sheet.getRow(0);
for (int i = 1; i <= sheet.getLastRowNum(); i++) {
Row dataRow = sheet.getRow(i);
Document document = new Document();
for (int j = 0; j < headerRow.getLastCellNum(); j++) {
String key = headerRow.getCell(j).getStringCellValue();
Cell valueCell = dataRow.getCell(j);
Object value = null;
if (valueCell != null) {
switch (valueCell.getCellType()) {
case STRING:
value = valueCell.getStringCellValue();
break;
case NUMERIC:
value = valueCell.getNumericCellValue();
break;
case BOOLEAN:
value = valueCell.getBooleanCellValue();
break;
default:
value = null;
}
if (valueCell.getCellType() == CellType.STRING && "".equals((value + "").trim())) {
continue;
}
document.append(key, value);
}
}
documents.add(document);
}
return documents;
}
}
使用
会根据文件名判断是xls、xlsx还是csv文件。
@Test
public void uploadFile() throws Exception {
String fileName = "test.csv";
String filePath = "C:/Users/Administrator/Desktop/" + fileName;
FileInputStream inputStream = new FileInputStream(filePath);
Boolean aBoolean = FileDataImportMongoDB.importMongoDB(inputStream, fileName);
System.out.println(aBoolean);
}














 3026
3026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









