







Aspect Sentiment Quad Prediction as Paraphrase Generation
Abstract
现有的研究通常考虑对部分情绪要素的检测,而不是一次预测四个要素。
本文引入了方面情感四元预测任务(ASQP),旨在联合检测一个特定意见句的四元情感元素,以揭示一个更全面、更完整的方面层面情感结构。
作者进一步提出了一个新的paraphrase范式,将ASQP任务转换为一个生成过程。一方面,生成公式允许端到端的方式求解ASQP,减轻了使用管道潜在的误差传播。另一方面,通过学习以自然语言的形式生成情感元素,可以充分利用情感元素的语义。
大量实验表明了方法的优越性。
1 Introduction
一般而言,ABSA包含四个基本的情感要素,包括方面术语(aspect term)、方面类别(aspect category)、意见术语(opinion term)和情绪极性(sentiment polarity)。例句“The pasta is over-cooked!”,其中四个情感元素分别为“food quality”、“pasta”、“overcooked”和“negative”。
早期的研究集中在单一元素的预测,而最近的研究建议同时提取多个相关的情绪元素。为此,本文引入了方面情绪四分量预测任务(ASQP),这个新任务弥补了以前任务的不足,并帮助我们全面理解用户的方面级意见。
为了解决ASQP问题,一个简单的想法是将四次预测问题分解成几个子任务,并以pipeline的方式解决它们。然而,这种多阶段的方法会产生严重的误差传播。此外,子任务通常表现为token或sequence分类问题,不能充分利用语义信息。
在本文中,作者提出以seq2seq的方式处理ASQP。一方面,四种情绪元素可以端到端进行预测,减轻了pipeline中的误差传播;另一方面,通过学习生成自然语言形式的情感元素,可以充分利用丰富的标签语义信息。
ASQP任务主要面临两个挑战:
- 如何将期望的情绪信息线性化以促进seq2seq学习
- 我们如何利用预训练模型来处理任务,这也是目前解决各种ABSA任务的常见做法
所以本文提出了一种新的paraphrase范式,可以将ASQP任务转换为释义生成问题。
例如,可以将情绪四分量*(food quality, pasta, overcooked, negative)转换成句子“Food quality is bad because pasta is overcooked”,这样一个目标序列可以与输入句“the pasta is overcooked!”*作为模型的映射,然后对这种输入目标对进行微调,无缝地利用大型预训练模型。
因此,情感元素的语义以自然句的形式与预训练模型融合在一起,而不是直接将情感四元素序列作为生成目标。
本文贡献:
- 提出了一个新的课题,即方面情绪四元素预测(ASQP),并引入了两个数据集,对每个样本进行情绪四元素标注,旨在分析更全面的方面层面情绪信息。
- 提出将ASQP作为一个释义生成问题来处理,该问题可以一次预测情感四元组,并充分利用自然语言标签的语义信息。
- 大量实验表明,所提出的paraphrase模型能够有效地处理ASQP和其他ABSA任务,在所有情况下都优于以往的最先进的模型。
- 实验还表明,在统一的框架下,该方法促进了相关任务间的知识转移,在低资源环境下尤其有效。
2 Related Work
3 Methodology
3.1 Problem Statement
给定一个句子 x x x,相位情绪四元预测(ASQP)的目标是预测与方面类别、方面术语、意见词、情绪极性分别对应的所有情绪四元组 { ( c , a , o , p ) } \{(c, a, o, p)\} { (c,a,o,p)}。方面类别 c c c属于方面类别集 V c V_c Vc;方面术语 a a a和意见术语 o o o通常是在句子 x x x中的文本跨度,而如果没有明确提到目标,方面术语也可以为空: a ∈ V x ∪ { ∅ } a \in V_{\boldsymbol{x}} \cup\{\varnothing\} a∈Vx∪{ ∅}; o ∈ V x o∈V_x o∈Vx,其中 V x V_x Vx表示包含 x x x的所有可能连续空间的集合;情绪极性 p p p属于一个情绪类 { P O S , N E U , N E G } \{POS, NEU, NEG\} { POS,NEU,NEG},分别表示积极、中性和消极情绪。
3.2 ASQP as Paraphrase Generation
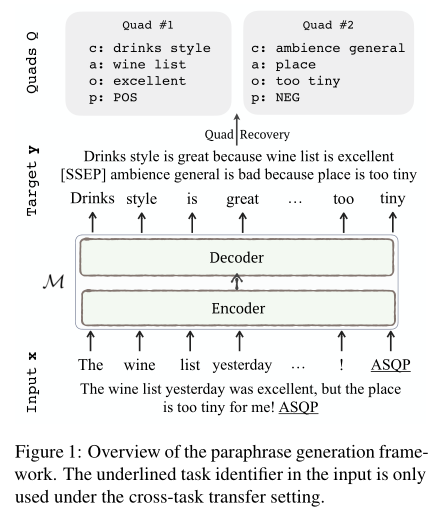
给定一个句子 x x x,目标是生成一个目标序列 y y y,其encoder-decoder为 M : x → y M: x→y M:x→y,其中 y y y包含所有需要的情感元素。然后从 y y y中恢复情绪四元组 Q = { ( c , a , o , p ) } Q = \{(c, a, o, p)\} Q={ (c,a,o,p)}进行预测。
PARAPHRASE Modeling 为了促进seq2seq学习,给定句子标签对 ( x , Q ) (x, Q) (x,Q),paraphrase模型的一个重要组成部分是将情感四元组 Q Q Q线性化为自然语言序列 y y y,以构建输入目标对 ( x , y ) (x, y) (x,y)。理想情况下,我们的目的是在释义过程中,忽略输入句中不必要的细节,而突出目标句中主要的情感成分。所以,作者将情绪四元组 q = ( c , a , o , p ) q = (c, a, o, p) q=(c,a,o,p)线性化为一个自然句子,如下所示:

其中 P z ( ⋅ ) \mathcal{P}_{z}(·)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









