




Self-Attention with Relative Position Representations
Abstract
2017年Vaswani等人提出的Transformer需要在输入中添加绝对位置表示。作者在这篇文章中提出将元素与元素之间的相对位置表示引入了self-attention机制,在两个机器翻译(WMT 2014 EN-DE and EN-FR)的任务中,引入相对位置表示的self-attention比绝对位置编码的self-attention有明显的提升。但相对与绝对结合并不会进一步提高翻译质量。
1 Introduction
RNNs通常根据时间ttt的输入和先前的隐藏状态ht−1h_{t-1}ht−1计算隐藏状态hth_tht,通过时序结构直接获取时间维度上的相对和绝对位置。非递归模型(如Transformer)不一定顺序地考虑输入元素,因此可能需要明确地编码位置信息以便能够使用序列顺序。
一种常见的方法是使用与输入元素结合的位置编码,以将位置信息公开给模型。这些位置编码可以是位置的确定性函数或学习的表示形式。比如,卷积神经网络捕获每个卷积内核大小内的相对位置,已被证明仍然受益于位置编码。
2 Background
- self-attention
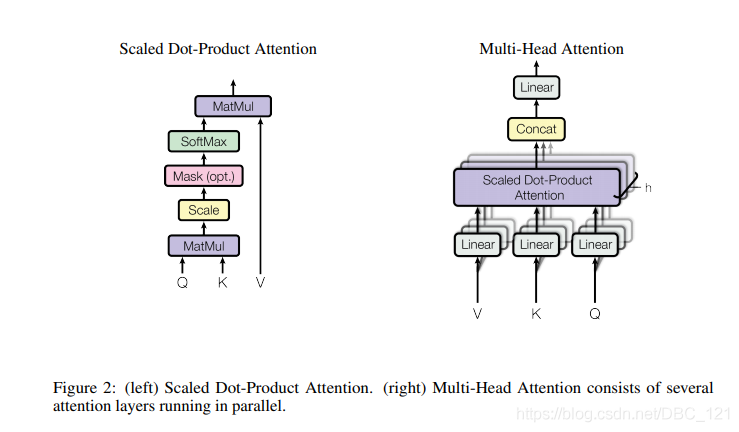
假设我们从多头注意力机制中的一个头输出后的序列是 x=(x1,x2,...,xn)x=(x_1,x_2,...,x_n)x=(x1,x2,...,xn),其中 xi∈Rdxx_i∈R^{d_x}xi∈Rdx,这个时候,我们需要通过attention计算出一个新的序列 zzz:
zi=∑j=1naij(xjWV) z_i=\sum_{j=1}^{n}a_{ij}(x_jW^V) zi=j=1∑naij(xjWV)
其中,权重系数 aija_{ij}aij是通过 softmax计算的:
aij=exp(eij)∑k=1nexp(eik) a_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^nexp(e_{ik})} aij=∑k=1nex
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









