







当人类理解"银行"一词时,左脑看前文"现金",右脑看后文"利率"—这就是双向思维的本质突破
一、BERT双向机制深度解析
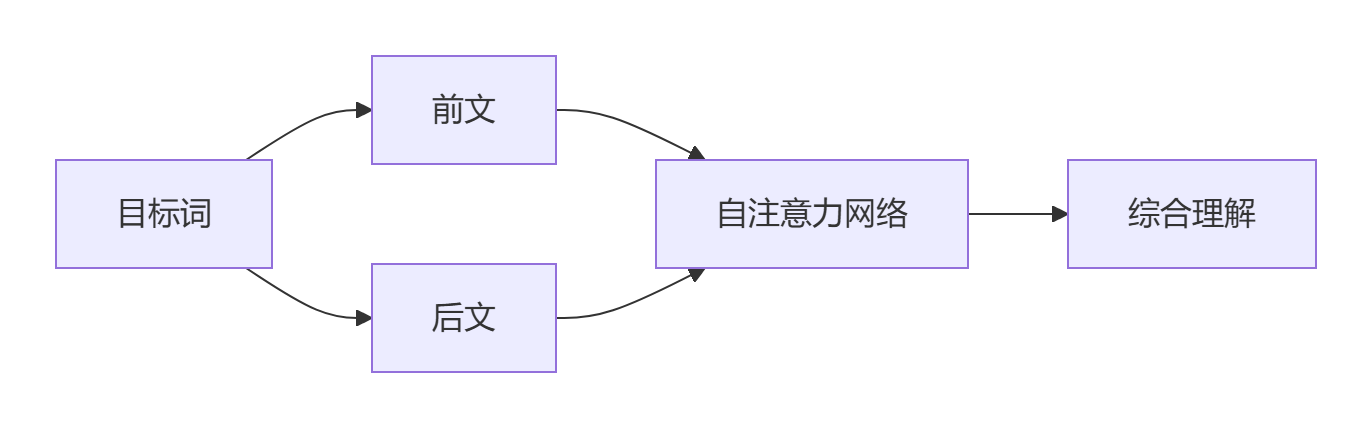
1.1 双向的本质:上下文全视角理解
技术定义:
BERT在训练过程中同时查看目标词左右两侧的上下文,通过自注意力机制动态学习词语间的全局依赖关系。
类比解释:
-
传统单向模型(如GPT):蒙住右眼从左读到右
"我带着现金去__" → 只能推测"银行/商店"
-
BERT双向视角:双眼同时看整句
"我带着现金去__办理贷款" → 确认为"银行"✅
"我带着现金去__购买水果" → 确认为"商店"✅
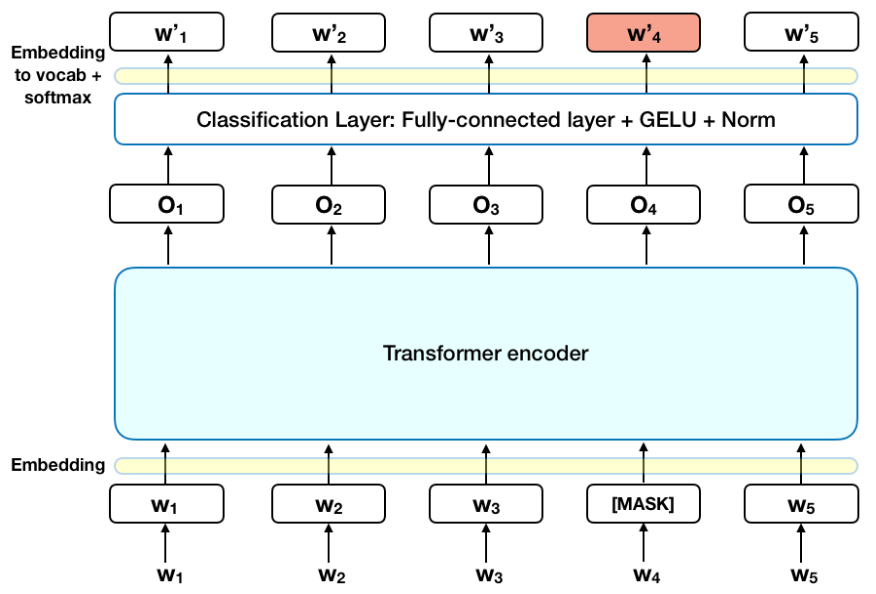
1.2 关键技术:掩码语言模型(MLM)
训练过程解密:
# 原始句子
text = "自然语言处理改变了人工智能领域"
# 随机掩码15%词语
masked_text = "自然 [MASK] 处理改变了 [MASK] 工智能领域"
# 模型训练任务
预测1: [MASK] → "语言" (根据"自然"+"处理")
预测2: [MASK] → "人" (根据"改变了"+"能领域")注意力热力图示例:
句子: "苹果股价今日大涨"
预测 "果" 时注意力分布:
苹 果 股 价 今 日 大 涨
█████ ████ ██ █ ██ █
↑ ↑ ↑ ↑ ↑ ↑
80% 60% 20% 15% 30% 5%1.3 架构实现:Transformer编码器
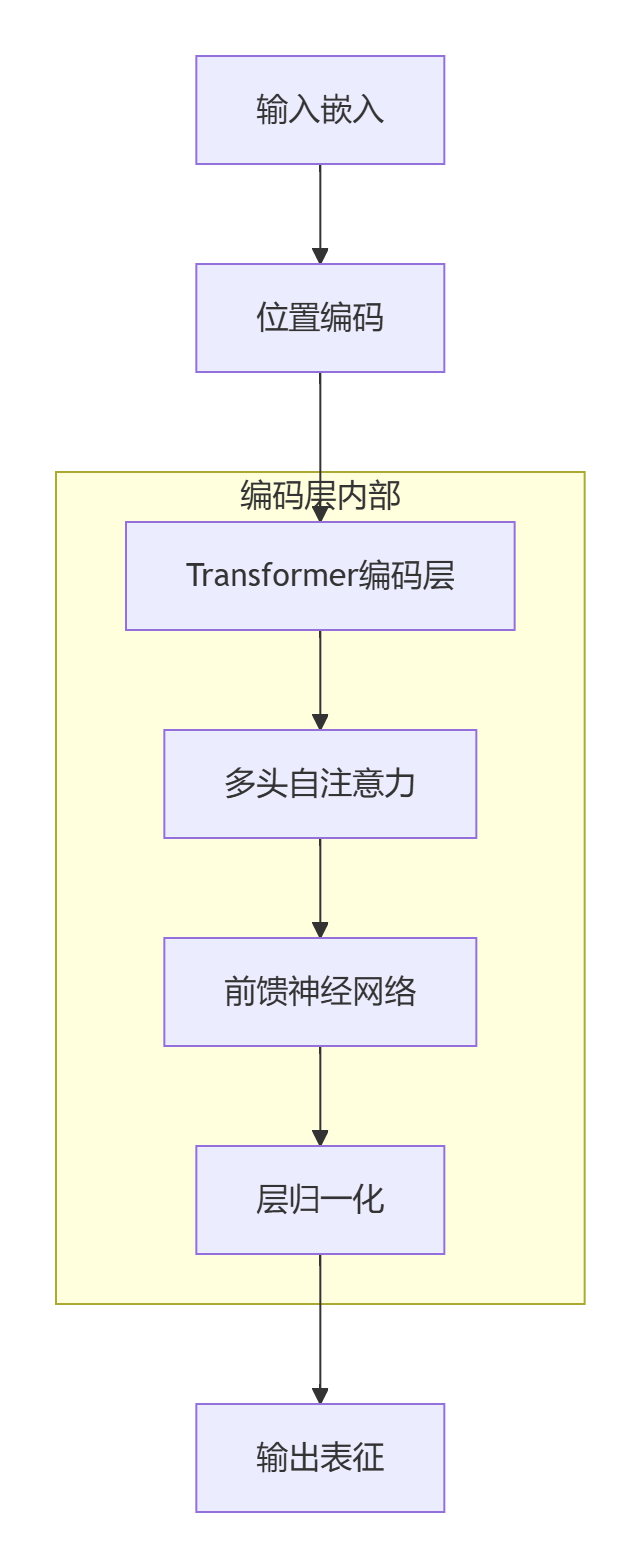
核心公式:
其中Q/K/V分别由输入序列生成,关注全局关系
二、GPT单向机制的本质差异
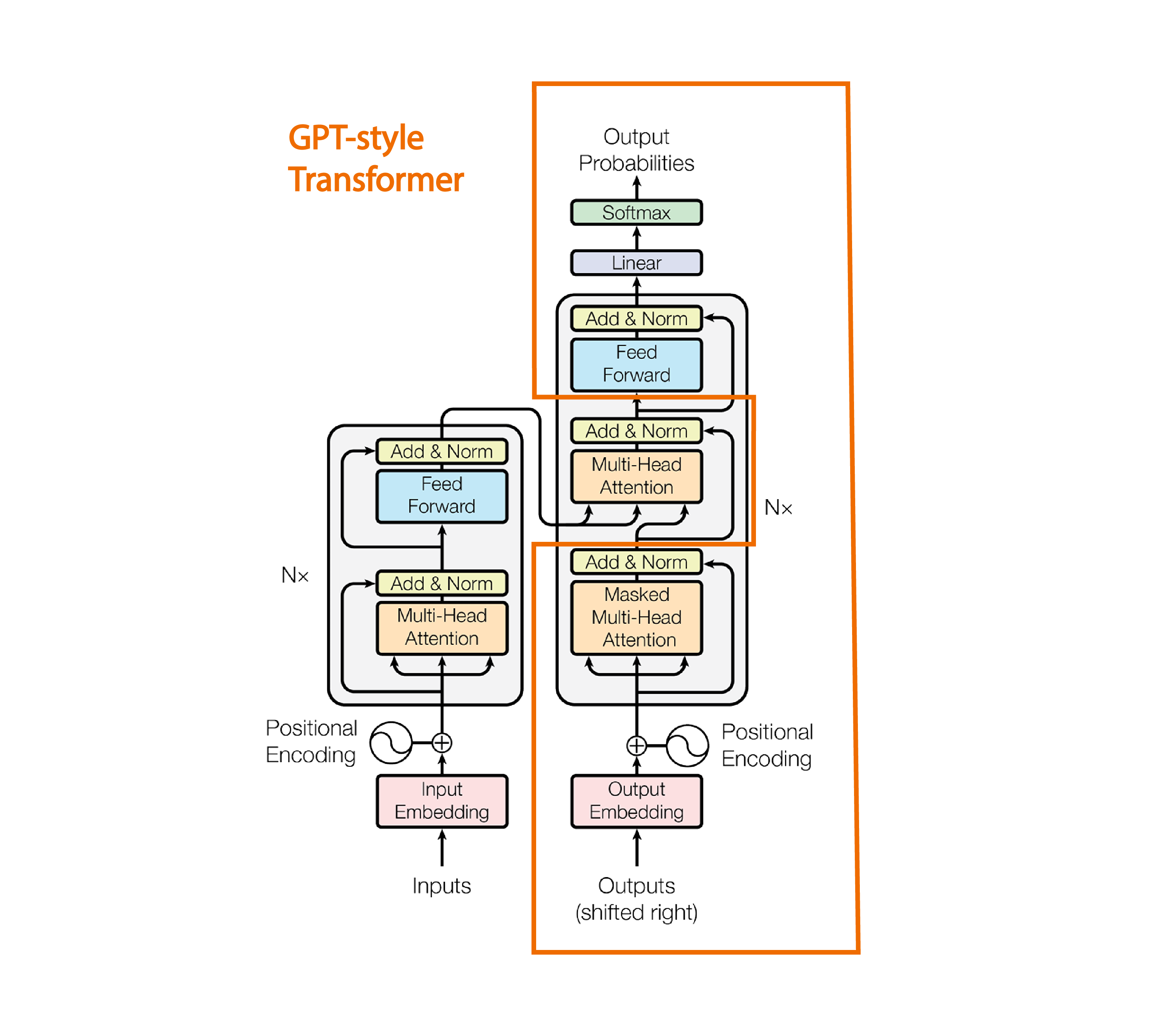
2.1 单向的本质:顺序生成模式
技术定义:
GPT系列模型采用自回归(Autoregressive) 方式,仅利用目标词左侧的上下文进行预测,严格遵循从左到右的文本生成顺序。
类比解释:
- 如同用左手写字:必须从左边开始,右边被手挡住看不见
- 像阅读古籍卷轴:展开左侧才能看到右侧内容

2.2 关键技术:因果注意力掩码
实现原理:
# GPT注意力矩阵示例 (4x4)
[[1, 0, 0, 0], # 第一个词只看自己
[1, 1, 0, 0], # 第二个词看前两个
[1, 1, 1, 0], # 第三个词看前三个
[1, 1, 1, 1]] # 最后一个词看全部
# 注:实际为softmax前的负无穷掩码训练任务对比:
| 特性 | BERT(双向) | GPT(单向) |
|---|---|---|
| 训练任务 | 预测掩码词语 | 预测下一个词 |
| 注意力范围 | 全句上下文 | 左侧历史 |
| 典型架构 | Transformer编码器 | Transformer解码器 |
2.3 GPT生成示例:
输入: "人工智能正在"
生成流程:
步骤1: "人" → 输出概率 [工:0.6, 类:0.3]
选择"工" → "人工"
步骤2: "人工" → 输出概率 [智:0.7, 造:0.2]
选择"智" → "人工智"
步骤3: "人工智" → 输出概率 [能:0.9, 慧:0.1]
最终输出: "人工智能正在"三、核心差异对比矩阵
| 维度 | BERT(双向) | GPT(单向) | 本质区别 |
|---|---|---|---|
| 上下文利用 | 全句双向理解 | 仅左侧历史 | 信息完整性差异 |
| 训练任务 | 掩码词语预测 | 下个词语预测 | 目标导向不同 |
| 架构本质 | 编码器(无掩码限制) | 解码器(因果掩码) | 结构设计哲学 |
| 推理方式 | 并行计算(全句输入) | 顺序生成(逐字输出) | 计算效率差异 |
| 适用场景 | 理解任务(分类/问答) | 生成任务(写作/对话) | 专业侧重不同 |
| 模型示例 | BERT/RoBERTa | GPT-3/LLaMA | 代表生态 |
3.1 性能对比实验(SQuAD问答基准)
| 模型 | EM得分 | F1得分 | 表现原因 |
|---|---|---|---|
| BERT-large | 84.1 | 90.9 | 双向理解上下文关系 |
| GPT-3 | 76.3 | 84.2 | 无法回溯后文线索 |
案例分析:
问题: "特朗普在哪一年当选总统?"
原文: "...2016年大选中,特朗普击败希拉里当选美国第45任总统..."- BERT:同时看到"2016年"和"当选总统" → 准确定位
- GPT:生成到"特朗普"时尚未读到后文的"2016年" → 可能错误推测
四、技术融合:双向与单向的终极统一
4.1 混合架构代表:XLNet
创新点:
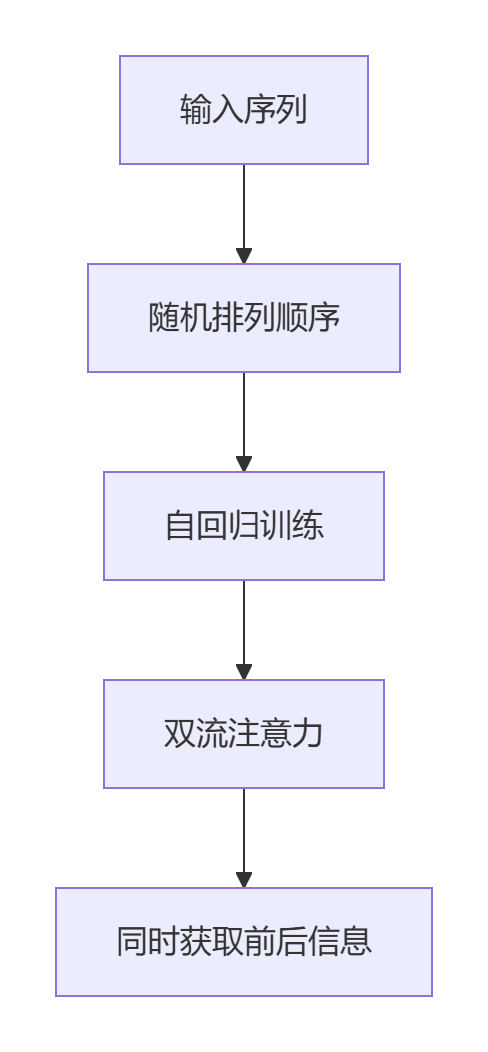
突破优势:
- 保留GPT的自回归特性
- 实现BERT的双向理解
- SQuAD得分超越BERT 2.3%
4.2 未来趋势:动态注意力机制
可切换架构原型:
class UniversalTransformer(nn.Module):
def forward(self, x, mode):
if mode == "encoding":
return self.encoder(x) # BERT模式
else:
return self.decoder(x) # GPT模式4.3 2024前沿突破:旋转变换器
相对位置编码公式:
其中m为位置索引
优势表现:
| 模型 | 上下文长度 | 推理速度 | 语言理解 |
|---|---|---|---|
| BERT | 512 token | 1x | 85.7 |
| LLaMA | 2K token | 0.7x | 83.2 |
| Rotary-BERT | 8K token | 1.5x | 87.1 |
认知科学启示:人类大脑并非纯粹单向或双向处理器——左脑负责序列逻辑(如GPT),右脑负责全局关联(如BERT)。未来的语言模型将如大脑般动态协作:写作时启用GPT模式保证连贯性,阅读理解时切换BERT模式捕捉深层语义。
当Google用BERT革新搜索,OpenAI用GPT重塑创作,两大技术路线终将在神经科学指导下殊途同归——那将是通用人工智能的语言理解黎明。
附录:BERT的数学原理与PyTorch实现详解
一、核心数学原理
1.1 自注意力机制
计算流程:
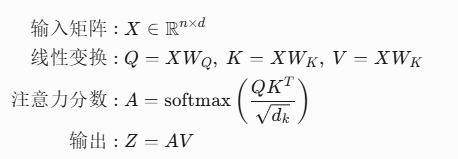
1.2 多头注意力
其中
1.3 MLM损失函数
m:掩码词数量
1.4 层归一化
二、PyTorch实现核心模块
2.1 自注意力层实现
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, _ = x.shape
# 线性变换 → [batch_size, seq_len, d_model]
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# 多头切分 → [batch_size, num_heads, seq_len, head_dim]
Q = Q.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
# 注意力分数 → [batch_size, num_heads, seq_len, seq_len]
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float))
attn_probs = torch.softmax(attn_scores, dim=-1)
# 注意力加权 → [batch_size, num_heads, seq_len, head_dim]
attn_output = torch.matmul(attn_probs, V)
# 合并多头 → [batch_size, seq_len, d_model]
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.W_o(attn_output)2.2 BERT编码层
class BERTLayer(nn.Module):
def __init__(self, d_model, num_heads, ff_dim, dropout=0.1):
super().__init__()
self.attention = SelfAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# 前馈神经网络
self.feed_forward = nn.Sequential(
nn.Linear(d_model, ff_dim),
nn.GELU(),
nn.Linear(ff_dim, d_model),
nn.Dropout(dropout)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 残差连接1
attn_output = self.attention(x)
x = x + self.dropout(attn_output)
x = self.norm1(x)
# 前馈网络
ff_output = self.feed_forward(x)
x = x + self.dropout(ff_output)
return self.norm2(x)2.3 MLM任务头
class MLMHead(nn.Module):
def __init__(self, d_model, vocab_size):
super().__init__()
self.dense = nn.Linear(d_model, d_model)
self.layer_norm = nn.LayerNorm(d_model)
self.decoder = nn.Linear(d_model, vocab_size)
def forward(self, hidden_states, masked_positions):
# 提取掩码位置的特征
batch_indices = torch.arange(hidden_states.size(0))[:, None]
features = hidden_states[batch_indices, masked_positions]
# 预测层
x = self.dense(features)
x = torch.gelu(x)
x = self.layer_norm(x)
return self.decoder(x)三、简化版BERT模型
3.1 完整模型实现
class MiniBERT(nn.Module):
def __init__(self, vocab_size, d_model=768, num_layers=12,
num_heads=12, ff_dim=3072, max_len=512):
super().__init__()
self.d_model = d_model
self.token_emb = nn.Embedding(vocab_size, d_model)
self.pos_emb = nn.Embedding(max_len, d_model)
self.layer_norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
# 堆叠BERT层
self.layers = nn.ModuleList([
BERTLayer(d_model, num_heads, ff_dim)
for _ in range(num_layers)
])
# 任务特定头
self.mlm_head = MLMHead(d_model, vocab_size)
def forward(self, input_ids, attention_mask=None, masked_positions=None):
batch_size, seq_len = input_ids.shape
device = input_ids.device
# 嵌入层
token_emb = self.token_emb(input_ids)
pos_ids = torch.arange(seq_len, device=device).unsqueeze(0)
pos_emb = self.pos_emb(pos_ids)
# 融合嵌入
embeddings = token_emb + pos_emb
x = self.layer_norm(embeddings)
x = self.dropout(x)
# 编码层处理
for layer in self.layers:
x = layer(x)
# MLM预测
mlm_logits = self.mlm_head(x, masked_positions)
return mlm_logits3.2 训练代码示例
# 配置参数
config = {
'vocab_size': 30000,
'd_model': 768,
'num_layers': 6,
'num_heads': 12,
'ff_dim': 3072,
'max_len': 512
}
model = MiniBERT(**config).cuda()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
# 简化数据加载
def create_masked_samples(texts):
# 实际应用需替换为真实的掩码逻辑
token_ids = torch.randint(0, config['vocab_size'], (32, 128)) # [batch, seq]
masked_pos = torch.randint(0, 128, (32, 20)) # 每句掩码20词
mask_labels = torch.randint(0, config['vocab_size'], (32, 20))
return token_ids, masked_pos, mask_labels
# 训练循环
for epoch in range(5):
token_ids, masked_pos, mask_labels = create_masked_samples(...)
# 模型前向
logits = model(token_ids.cuda(), masked_positions=masked_pos.cuda())
# MLM损失计算
loss = nn.CrossEntropyLoss()(
logits.view(-1, config['vocab_size']),
mask_labels.view(-1).cuda()
)
# 反向传播
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
print(f"Epoch {epoch} | Loss: {loss.item():.4f}")四、关键数学推导补充
4.1 位置编码公式
4.2 GELU激活函数
![\text{GELU}(x) = x \cdot \Phi(x) \approx 0.5x(1 + \tanh[\sqrt{2/\pi}(x + 0.044715x^3)])](https://latex.csdn.net/eq?%5Ctext%7BGELU%7D%28x%29%20%3D%20x%20%5Ccdot%20%5CPhi%28x%29%20%5Capprox%200.5x%281%20+%20%5Ctanh%5B%5Csqrt%7B2/%5Cpi%7D%28x%20+%200.044715x%5E3%29%5D%29)
4.3 AdamW优化器
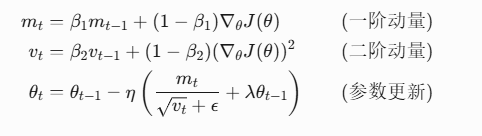
性能提示:完整BERT训练需分布式数据并行(DDP),使用混合精度(AMP)可减少30%显存占用并提速25%。实际应用推荐使用Hugging Face Transformers库。
通过数学原理与代码实现的结合,我们可以深入理解BERT如何通过自注意力机制实现语言建模的革命性突破。这种结构奠定了当代大语言模型的基础,成为自然语言处理领域的里程碑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









