










 该代码段展示了一个Python函数,用于读取一个Excel文件中的所有工作表,删除指定行,然后在每张表旁添加一列标识数据来源的工作表名。最后,它将所有工作表拼接成一个新的Excel文件。这个过程适用于处理具有相似结构的多工作表数据。
该代码段展示了一个Python函数,用于读取一个Excel文件中的所有工作表,删除指定行,然后在每张表旁添加一列标识数据来源的工作表名。最后,它将所有工作表拼接成一个新的Excel文件。这个过程适用于处理具有相似结构的多工作表数据。
导入需要的包
import xlrd
import pandas as pd
from pandas import DataFrame目标文件:test.xlsx
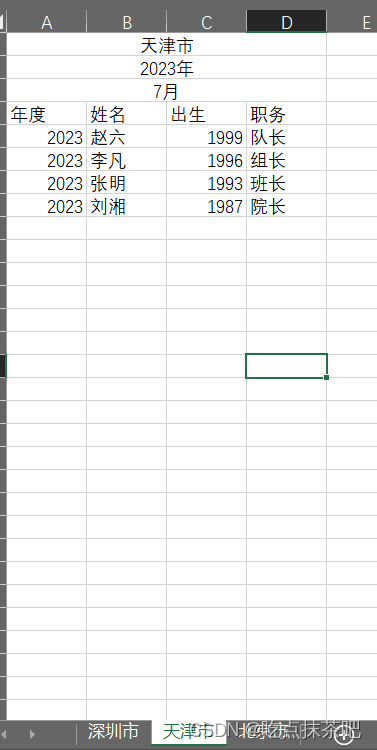
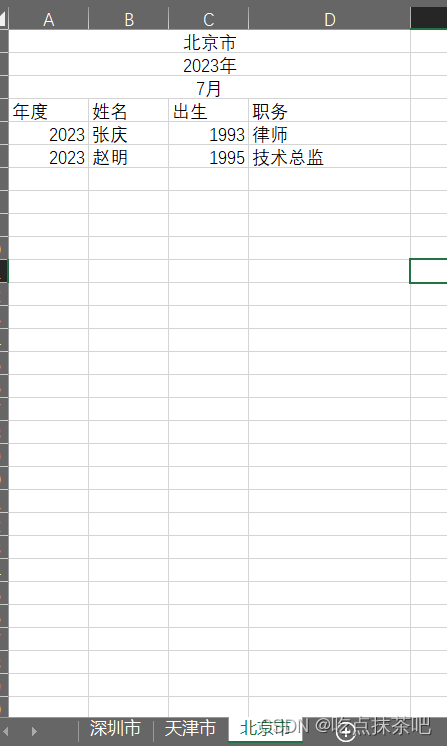
里面包含三个sheet,且每个sheet的前四行格式内容大致一样,需要提取所有人的信息
编写函数
#该函数的功能是将filename里面所有的sheet拼接按想要的行数起来存入另一个新表,并说明每行数据来源于哪一个sheet
def conect(filename,deleterow_list,outputefile):
#将excel的路径赋值
excel_name =(f'{filename}' )
wb = xlrd.open_workbook(excel_name)
sheet = wb.sheet_names()# 获取workbook中所有的表格,可以打印一下看看内容
data_xls = pd.io.excel.ExcelFile('test.xlsx')
for she in sheet:
df = pd.read_excel(data_xls, sheet_name = f'{she}',header=None,index = None)
df1 = df.drop(deleterow_list)
#在表的旁边插入一列说明数据来源于哪一个sheet,标注出sheet名字
df1.insert(df1.shape[1],'来源', f"{she}")
# print(df1)
df1.to_excel(f'{she}.xlsx', index=False)
file = []
for she in sheet:
file.append(f'{she}.xlsx')
# print(file)
li = []
for i in file:
li.append(pd.read_excel(i))
# print(li)
writer = pd.ExcelWriter(f'{outputefile}')
pd.concat(li).to_excel(writer,'Sheet1', index=False)
writer.save()
if __name__ == "__main__":
#如果需要删除每个sheet的前几行,可以用列表传入函数:[0,1,2,3]删除第0,1,2,3行
#将最后拼接好的文件输出到output.xlsx
conect('test.xlsx', [0, 1, 2, 3], 'output.xlsx')
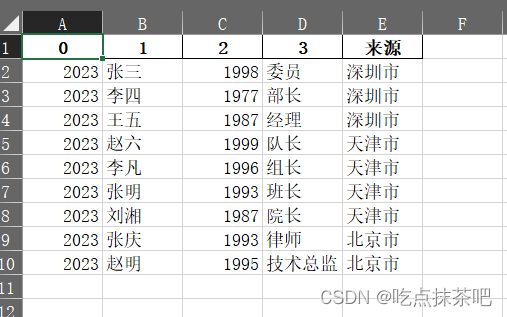
最终结果:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









