







目录
复习python的time模块和pandas时间处理对象
主要time生成方法
import time
time.time()#生成时间戳timestamp
time.localtime()
#生成struct_time,可使用my_time.tm_year打印年份信息my_time.tm_mon打印月份信息,my_time.tm_mday打印日信息
time.strptime('2011-05-05 16:37:06','%Y-%m-%d %X')#格式化字符串到struct_time
time.strftime('%Y-%m-%d %X')#显示当前格式化后的时间
time.strftime('%Y-%m-%d %X', time.localtime(1657874422))#显示指定struct_time的时间
datatime模块:
1.data类
data.today()#返回当前日期
date.fromtimestamp(time.time())#返回当前日期
d1 = data(2011,06,03)#创建data对象
d1.year、d1.month、d1.day:年、月、日
d1.replace(year、month、day):生成一个新的日期对象,用参数指定的年、月、日代替原有对象中的属性。(原有对象仍保持不变)
d1.timetuple():返回日期对应的time.struct_time对象
d1.weekday():返回weekday,如果是星期一,返回0;如果是星期2,返回1,依次类推
d1.isoweekday():返回weekday,如果是星期一,返回1,如果是星期二,返回2,以此类推
d1.isoformat():返回格式如’YYYY-MM-DD‘的字符串
d1.strftime(fmt):和time模块format相同
2.dataetime类
datetime.today()#返回本地时间
datetime.strptime('10/11/2021 10:23','%d/%m/%Y %H:%M')#strptime 将字符串转化为datetime
dt = datetime.now()#返回本地时间
dt_1 = dt + timedelta(days=-1)#昨天
dt3 = dt + timedelta(days=1 )#明天
pandas时间处理
1.TimeStamp时间戳
pd.Timestamp('2022-01-01')#转换类似日期时间的字符串
pd.Timestamp(time.time(),unit="s")
pd.Timestamp(2022,1,1,12)
pd.Timestamp(year=2022,month=1,day=1)#最小要给出day
2.时间间隔Timedelta——实现datetime加减
ts = pd.Timestamp('2022-01-01 12')
ts + pd.Timedelta(-1, "D")#昨天
#计算当前时间往后100天的日期
dt = pd.Timestamp(int(time.time()),unit='s')
dt + datetime.timedelta(days=100)
3.时间转化to_datetime
1)从一个数据帧的多个列中组装日期时间
df = pd.DataFrame({'year':[2015,2016],'month':[2,3],'day':[4,5]})
pd.to_datetime(df)
2)将字符串转datetime
pd.to_datetime(["2005/11/23","2010.12.31"])
3).将unix时间转为时间戳
pd.to_datetime([1349720105,1349806505],unit="s")
4)自动识别异常
pd.to_datetime('210605',yearfirst=True)
5).配合unit参数,使用非unix时间
pd.to_datetime([1,2,3],unit='D',origin=pd.Timestamp('2020-1-11'))
6)不可转化日期/时间
#无效的转换,将使用输入的数据
pd.to_datetime(['120211204','2021.02.01'],errors="ignore")
#无效的转换,将使用NaT
pd.to_datetime(['120211204','2021.02.01'],errors="coerce")
#自动识别:
pd.to_datetime(pd.Series(["Jul 30, 2018","2018.05.10",None]))
4.生成时间戳范围date_range和bdate_range
pd.date_range(start='1/1/2021', end='1/08/2021')#默认频率使用D(天)
pd.date_range(start='1/1/2018',periods=8)
pd.date_range(start='2018-04-24',end='2018-04-27',periods=3)#频率自动生成
其他关于频率的这里不再介绍
Pandas时期:Period()
p = pd.Period('2017')
p = pd.Period('2017-1', freq='M')#频率为月
print(p+1)#频率的移动
print(p-2)
#pd.PeriodIndex
rng = pd.period_range('2021-1-1','2021-6-1',freq='M')#创建频率的范围
values = ['200103','200104','200105']
#必须指定freq
index = pd.PeriodIndex(values, freq='M')#PeriodIndex 类的构造函数允许直接使用一组字符串表示一段时期
#pd.asfreq
p = pd.Period('2021',freq='A-DEC')
print(p)
print(p.asfreq('M'))#将频率转换为月
#pd.resample
rng = pd.date_range('20170101',periods=12)
ts = pd.Series(np.arange(12),index=rng)
print(ts)
ts.resample('5D').sum()#将序列下采样到5天的数据箱中,并将放入数据箱中的时间戳相加
学习新知识Pandas处理文件
pandas数据处理的方法:
一、read_csv() 读取文本文件
read_csv() 用于读取文本文件
read_excel() 用于读取文本文件
read_json() 用于读取json文件
read_sql_query()读取sql语句
read_csv对记录数没有限制,excel对记录数有限制
流程:
1.导入库 import pandas as pd
2.找到文件位置(绝对路径=全称)(相对路径=和程序在同一个文件夹中的路径的简称)
3.变量名 = pd.读写操作方法(文件路径,具体的筛选条件)

源数据:
import pandas as pd
#读取csv文件,相对路径
#df = pd.read_csv("data/my_csv.csv")
df = pd.read_csv("./data/my_csv.csv")
#os 动态取得绝对路径 os.getcwd() os.path.json
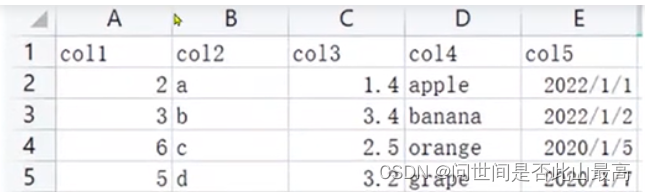
print(df,type(df))
输出:
col1 col2 col3 col4 col5
0 2 a 1.4 apple 2022/1/1
1 3 b 3.4 banana 2022/1/2
2 6 c 2.5 orange 2020/1/5
3 5 d 3.2 grape 2020/1/7 <class 'pandas.core.frame.DataFrame'>
import os
os.getcwd()
输出:'F:\\numpy'
方法详细说明:
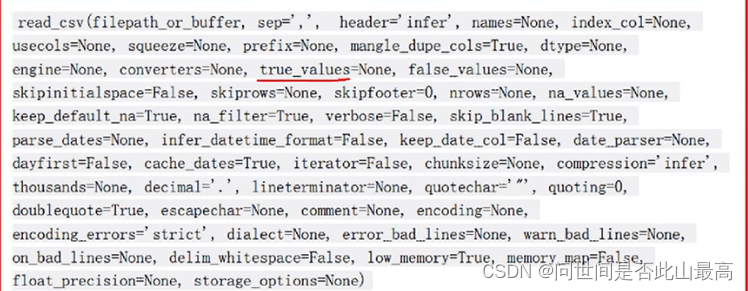
基本参数:
**1.filepath_or_buffer:**数据输入的路径:可以是文件路径、可以是URL,也可以是read方法的任意对象
如:
df = pd.read_csv("./data/my_csv.csv")
#还可以是一个URL,如果访问该URL会返回一个文件的话,那么pandas的read_csv函数
#会自动将该文件进行读取。比如,我们服务器上放的数据,将刚才的文件返回
pd.read_csv("http://my-teaching.top/static/data/studengts.csv")
#里面还可以是一个_io.TextIOWrapper,比如:
f = open(r"data\students.csv",encoding="utf-8")
pd.read_csv(f)
#pandas默认使用utf-8读取文件
2.header

3.names

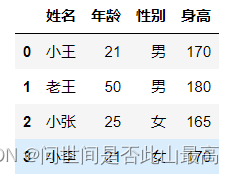
1)name没有被赋值,header也没赋值
#这种情况下,header为0,即选取文件的第一行作为表头
pd.read_csv(r"data\students.csv")
输出:
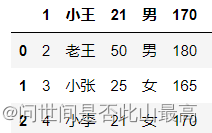
2)不指定names,指定header为1,则选取第二行当表头,第二行下面为数据:
pd.read_csv(r"data\students.csv",header=1)
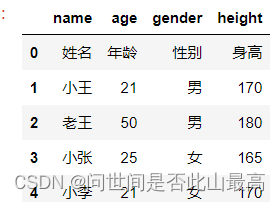
3)names被赋值,header没有被赋值:
pd.read_csv(r"data\students.csv",names=['name','age','gender','height'])
输出:

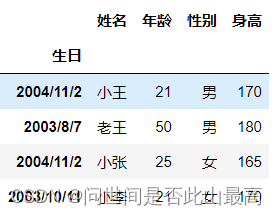
4.index_col:读取文件之后所得到的DataFrame索引默认是0,1,2…,我们可以通过set_index设定索引,也可以在读取的时候就指定某列为索引
df = pd.read_csv(r"data\students.csv", index_col="生日")
df
输出:
打印索引df.index
输出:Int64Index([170, 180, 165, 170], dtype='int64', name='身高')
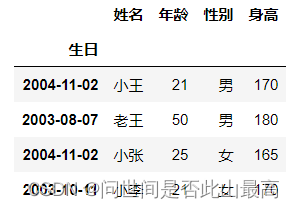
转化为datetime:
df.index = pd.to_datetime(df.index)
df.index
输出:
DatetimeIndex(['2004-11-02', '2003-08-07', '2004-11-02', '2003-10-11'], dtype='datetime64[ns]', name='生日', freq=None)
此时的df:
df
输出:
查找生日为2004-11-2的记录:
df['2004-11-2']
输出:

df['2003']
输出:

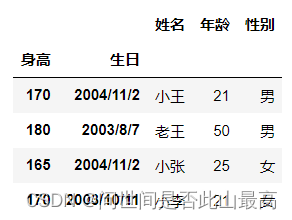
指定多列索引:
df2 = pd.read_csv(r"data\students.csv", index_col = ["身高", "生日"])
df2
输出:
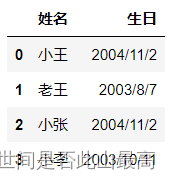
**5.usecols:返回列的子集。**如果给出了名称,则不考虑文档标题行
pd.read_csv(r"data\students.csv",usecols=["姓名 ","生日"])
输出:
二、通用解析参数
1.encoding:编码格式 utf-8, gbk
#ANSI 即gbk编码 windows
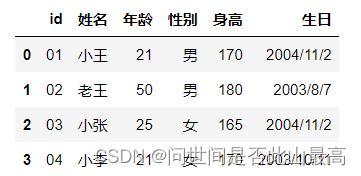
**2.dtype:在读取数据的时候,设定字段的类型。**比如公司员工的id一般:0001234.如果默认读取,显示1234.这个时候要转换为字符串类型,才能正常显示。
如:
df = pd.read_csv(r"data\students.csv")
df
输出:

df = pd.read_csv(r"data\students.csv",dtype={"id":str})
df
输出
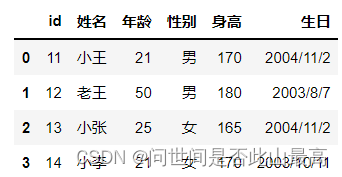
**3.converters:读取数据时对列数据进行变换。**如将Id增加10,但注意int(x),使用converters参数时,解析器默认所有列的类型为str,所以需要进行类别转换。
pd.read_csv('data\students.csv',converters={"id":lambda x:int(x) + 10})
输出:
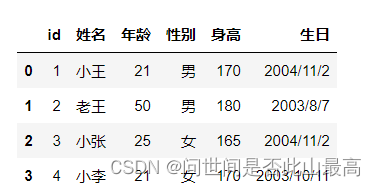
4.true_values和false_values:指定哪些值应该被清洗为True,哪些值被清洗为False
pd.read_csv('data\students.csv',true_values=['男'],false_values=['女'])
输出:
这里的替换规则是:只有当某一列的数据类别全部出现在true_values+false_values里面,才会被替换。

5.skiprows:表示过滤行
注意:先过滤,再确定表头
pd.read_csv('data\students.csv',skiprows=[0,3])
输出:
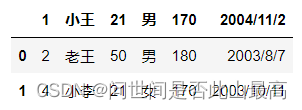

pd.read_csv('data\students.csv',skiprows=lambda x:x>0 and x%2==0)
输出:
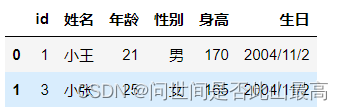
索引大于0,是为了保证表头不被过滤。
6.skipfooter:从文件末尾过滤行
pd.read_csv('data\students.csv',skipfooter=1)
输出:
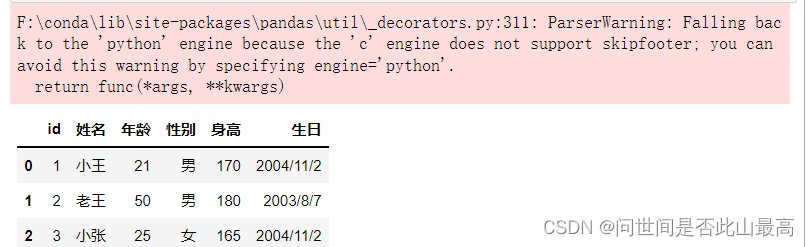

pd.read_csv('data\students.csv',skipfooter=1,engine="python",encoding="utf-8")
输出:
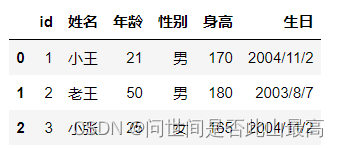
7.nrows:设置一次性读入的文件行数,在读入大文件时很有用,比如16G内存的PC无法容纳几百G的大文件
pd.read_csv('data\students.csv',nrows=2)
输出:
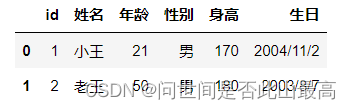
三、空值处理相关参数
na_values:该参数可以配置哪些值需要处理成NaN
pd.read_csv('data\students.csv',na_values=["女","小张"])
输出:
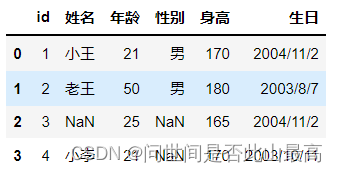
四、时间处理相关参数
1.parse_dates:指定某些列为时间类型,这个参数一般搭配date_parser使用
**2.date_parser:用来配合parse_dates参数的。**因为有的列虽然是日期,但没办法直接转化,需要我们指定一个解析格式。
如:
df = pd.read_csv("data\students.csv", parse_dates=["生日"])
df
输出:
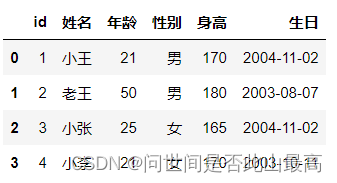 看一下df的类型
看一下df的类型df.dtypes
输出:

date_parser
df2 = pd.read_csv('data\students.csv',
parse_dates=['生日'],
date_parser=lambda x:datetime.strftime(x,"%Y年%m月%d日"))
print(df2)
df2.dtypes
报错:

五、分块读入相关参数
1.iterator:迭代器,iterator为bool类型,默认为False.若为true,那么返回一个TextFileReader对象,以便逐块处理文件。在文件很大、内存无法容纳所
有数据时,可以分批读入,依次处理。
如:
chunk = pd.read_csv('data\students.csv', iterator=True)
chunk
输出:
<pandas.io.parsers.readers.TextFileReader at 0x1203fc86100>
print(chunk.get_chunk(2))
输出:
id 姓名 年龄 性别 身高 生日
0 1 小王 21 男 170 2004/11/2
1 2 老王 50 男 180 2003/8/7
若不够我们指定的行数,有多少返回多少
print(chunk.get_chunk(100))
输出:
id 姓名 年龄 性别 身高 生日
2 3 小张 25 女 165 2004/11/2
3 4 小李 21 女 170 2003/10/11
但是在读取完毕之后,再读的话就会报错了:
try:
# 但是在读取完毕之后,再读的话就会报错了
chunk.get_chunk(5)
except StopIteration as e:
print("读取完毕")
输出:
读取完毕
2.chunksize:整型,默认为None,设置文件块的大小
chunk = pd.read_csv('data\students.csv', chunksize=2)
#还是返回一个类似于迭代器的对象
print(chunk)
#调用get_chunk,如果不指定行数,那么就是默认的chunksize
print(chunk.get_chunk())
输出:
<pandas.io.parsers.readers.TextFileReader object at 0x000001203FCB3580>
id 姓名 年龄 性别 身高 生日
0 1 小王 21 男 170 2004/11/2
1 2 老王 50 男 180 2003/8/7
六、 缺失值
缺失值类型
在pandas中,缺失数据显示为None,有3种表示方法:np.nan,None,pd.NA
1.np.nan
缺失值的特点:不等于任何值,包括它自己,若使用nan和其他任何值比较都会返回nan
如:np.nan == np.nan
输出:
False
nan在Numpy中的类型是浮点,因此整形列会转化为浮点;而字符型由于无法转化为浮点型,只能归并为object(‘o’),原来是浮点型的默认不变。
如:
print("nan的类型:",type(np.nan))
print("原Series类型:",pd.Series([1,2,3]).dtype)
print("有nan值的Series类型:",pd.Series([1,np.nan,3]).dtype)
s_time = pd.Series([pd.Timestamp('20220101')]*3)
print("原TimeSeries类型:\n",s_time,sep="")
s_time[2] = np.nan
print("有值的TimeSeries类型:\n",s_time,sep="")
输出:
nan的类型: <class 'float'>
原Series类型: int64
有nan值的Series类型: float64
原TimeSeries类型:
0 2022-01-01
1 2022-01-01
2 2022-01-01
dtype: datetime64[ns]
有值的TimeSeries类型:
0 2022-01-01
1 2022-01-01
2 NaT
dtype: datetime64[ns]
2.None
与自己相等
None == None
输出:
True
None传入后,会自动变为np.nan
pd.Series([1,None])
输出:
0 1.0
1 NaN
dtype: float64

3.NA标量

s_new = pd.Series([1,2],dtype="Int64")
s_new[1] = pd.NA
s_new
输出:
0 1
1 <NA>
dtype: Int64
pd.NA的一些常用算术运算和比较运算的示例:
加法:print("pd.NA + 1:\t",pd.NA + 1)
输出:
pd.NA + 1: <NA>
print("np.add(pd.NA, 1):\t", np.add(pd.NA, 1))
输出:
np.add(pd.NA, 1): <NA>
乘法:print('"a" * pd.NA:\t', "a" * pd.NA)
输出:
"a" * pd.NA: <NA>
指数为1:
print("pd.NA ** 0:\t", pd.NA ** 0)
print("1 ** pd.NA:\t", 1 ** pd.NA)
输出:
pd.NA ** 0: 1
1 ** pd.NA: 1
比较运算:
print("pd.NA == pd.NA:\t", pd.NA == pd.NA)
print("pd.NA < 2.5:\t", pd.NA < 2.5)
输出:
pd.NA == pd.NA: <NA>
pd.NA < 2.5: <NA>
缺失值判断

导入表格:
df = pd.read_excel(r"data\data_test.xlsx")
df
输出:
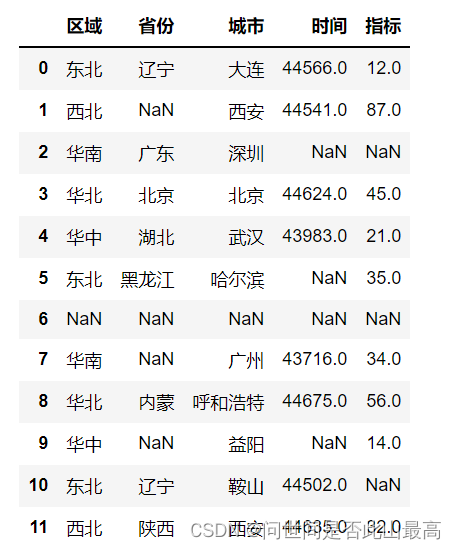
1.查看缺失值:df.info()
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12 entries, 0 to 11
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 区域 11 non-null object
1 省份 8 non-null object
2 城市 11 non-null object
3 时间 8 non-null float64
4 指标 9 non-null float64
dtypes: float64(2), object(3)
memory usage: 608.0+ bytes
2.缺失值的判断:
isnull():判断具体的某个值是否是缺失值df.isnull()
输出:
区域 省份 城市 时间 指标
0 False False False False False
1 False True False False False
2 False False False True True
3 False False False False False
4 False False False False False
5 False False False True False
6 True True True True True
7 False True False False False
8 False False False False False
9 False True False True False
10 False False False False True
11 False False False False False
3.删除缺失值
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
axis:{0或‘index', 1或'columns'},默认为0,确定是否删除了包含缺少值得行和列
*0或“索引”:删除包含缺少值的行
*1或“列”:删除包含缺少值的列
how:{'any','all'},默认为'any',确定是否从DataFrame中删除行或列,至少有一个NA或所有NA
*"any":如果存在任何NA值,请删除该行或列
*"all":如果所有值都为NA,请删除该行或列
thresh=int:需要至少非NA值数据个数
subset:定义在哪些列中查找缺失的值
inplace:是否更改源数据
首先,定义一个dataframe结构:
df = pd.DataFrame({"name":['Alfred','Batman','Catwoman'],
"toy":[np.nan,'Batmobile','Bullwhip'],
"born":[pd.NaT,pd.Timestamp("1940-04-25"),pd.NaT]})
df
输出:
name toy born
0 Alfred NaN NaT
1 Batman Batmobile 1940-04-25
2 Catwoman Bullwhip NaT
注意:时间类型的数据的缺失值用NaT表示,其他类型用NaN表示
删除至少缺少一个元素的行:df.dropna()
输出:
name toy born
1 Batman Batmobile 1940-04-25
删除至少缺少一个元素的列:df.dropna(axis='columns')
输出:
name
0 Alfred
1 Batman
2 Catwoman
删除缺少所有元素的行:df.dropna(how='all')
输出:
name toy born
0 Alfred NaN NaT
1 Batman Batmobile 1940-04-25
2 Catwoman Bullwhip NaT
仅保留至少有2个非NA值的行:df.dropna(thresh=2)
输出:
name toy born
1 Batman Batmobile 1940-04-25
2 Catwoman Bullwhip NaT
定义在哪些列中查找缺少的值:df.dropna(subset=['toy'])
输出:
name toy born
1 Batman Batmobile 1940-04-25
2 Catwoman Bullwhip NaT
在同一个变量中保留操作数据:
df.dropna(inplace=True)
df
输出改变了df:
name toy born
1 Batman Batmobile 1940-04-25
4.缺失值补充
一般有0补充,平均值补充,众数补充,向前填充(用缺失值上一行对应段的值填充),向后填充等方式
df.fillna(value=None,method=None,axis=None,inplace=False,limit=None,downcast=None,)
value:用于填充的值(比如0),或者是一个dict/Series/DataFrame值,指定每个索引(对于一个系列)或列(对于一个数据帧)使用哪个值。不在data/Series/DataFrame中的值会不会填充。此值不能是列表。
method:ffill-->将上一个有效观察值向前传播
bfill-->将下一个有效观察值向后传播
axis:用于填充缺失值的轴
inplace:是否操作源数据
limit:要向前/向后填充的最大连续数NaN值数
首先新建一个dataframe结构:
df = pd.DataFrame([
[np.nan,2,np.nan,0],
[3,4,np.nan,1],
[np.nan,np.nan,np.nan,np.nan],
[np.nan,3,np.nan,4]
],
columns=list("ABCD")
)
df
输出:
A B C D
0 NaN 2.0 NaN 0.0
1 3.0 4.0 NaN 1.0
2 NaN NaN NaN NaN
3 NaN 3.0 NaN 4.0
将所有NaN元素替换为0:df.fillna(0)
输出:
A B C D
0 0.0 2.0 0.0 0.0
1 3.0 4.0 0.0 1.0
2 0.0 0.0 0.0 0.0
3 0.0 3.0 0.0 4.0
向前或向后传播非空值:df.fillna(method="ffill")
输出:
A B C D
0 NaN 2.0 NaN 0.0
1 3.0 4.0 NaN 1.0
2 3.0 4.0 NaN 1.0
3 3.0 3.0 NaN 4.0
df.fillna(method="bfill")
输出:
A B C D
0 3.0 2.0 NaN 0.0
1 3.0 4.0 NaN 1.0
2 NaN 3.0 NaN 4.0
3 NaN 3.0 NaN 4.0
将列"A"“B”“C”"D"中所有NaN元素分别替换为0、1、2、3
values = {"A":0,"B":1,"C":2,"D":3}
df.fillna(value=values)
输出:
A B C D
0 0.0 2.0 2.0 0.0
1 3.0 4.0 2.0 1.0
2 0.0 1.0 2.0 3.0
3 0.0 3.0 2.0 4.0
只替换第一个NaN元素:
df.fillna(0,limit=1)
输出:
A B C D
0 0.0 2.0 0.0 0.0
1 3.0 4.0 NaN 1.0
2 NaN 0.0 NaN 0.0
3 NaN 3.0 NaN 4.0
当使用数据填充时,替换会沿着相同的列名和索引进行:
df2 = pd.DataFrame(np.random.rand(4,4),columns=list("ABCE"))
print(df2)
df.fillna(value=df2)
输出:
A B C E
0 0.408530 0.625778 0.467280 0.365601
1 0.877066 0.398835 0.269028 0.816598
2 0.489596 0.818440 0.616384 0.752099
3 0.834430 0.624923 0.779432 0.332843
A B C D
0 0.408530 2.00000 0.467280 0.0
1 3.000000 4.00000 0.269028 1.0
2 0.489596 0.81844 0.616384 NaN
3 0.834430 3.00000 0.779432 4.0
七、统计函数


company=["A","B","C"]
[company[x] for x in np.random.randint(0,len(company),10)]
输出:
['C', 'C', 'A', 'C', 'C', 'A', 'C', 'B', 'A', 'B']
company=["A","B","C"]
data = pd.DataFrame({
"company":[company[x] for x in np.random.randint(0,len(company),10)],
"salary":np.random.randint(5,50,10),
"age":np.random.randint(15,50,10)
})
data
输出:
company salary age
0 C 22 28
1 B 45 28
2 A 29 39
3 A 16 28
4 C 26 25
5 C 29 43
6 A 38 35
7 B 13 39
8 A 27 23
9 C 44 23
1.Groupby的基本原理
将上面的数据集按company字段进行划分:
group = data.groupby("company")
group
输出:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000012040496850>
得到一个DataFrameGroupBy对象。我们把group转化为list来看一下:list(group)
输出:
[('A',
company salary age
2 A 29 39
3 A 16 28
6 A 38 35
8 A 27 23),
('B',
company salary age
1 B 45 28
7 B 13 39),
('C',
company salary age
0 C 22 28
4 C 26 25
5 C 29 43
9 C 44 23)]
转化为列表的形式:
group.groups
输出:
{'A': [2, 3, 6, 8], 'B': [1, 7], 'C': [0, 4, 5, 9]}
第一个元素是组别,第二个元素是对应组别下的DataFrame

2.agg聚合操作

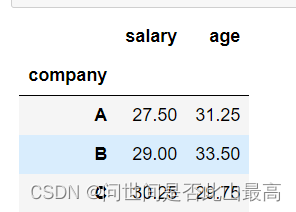
计算员工的平均年龄和平均薪水:
data.groupby("company").agg('mean')
输出:
或者:data.groupby("company").mean()
输出:
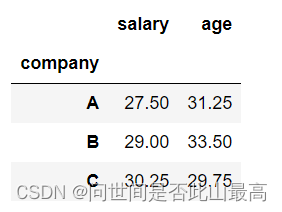

data.groupby('company').agg({'salary':'median','age':'mean'})
输出:

3.transform转换值
如果现在需要在原数据集中新增一列avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?
按照正常的步骤来看,需要先求得不同公司的平均薪水,然后按员工和公司的对应关系填充到对应的值,不用transform的话:
先求平均薪水,有好几种方式:data.groupby('company').mean()['salary']或者data.groupby('company')['salary'].mean()或者data[['salary','company']].groupby('company').mean()
输出:
company salary
0 A 27.50
1 B 29.00
2 C 30.25
然后用to_dict 将表格中的数据转换为字典格式:
avg_salary_dict=data.groupby('company')['salary'].mean().to_dict()
avg_salary_dict
输出:
{'A': 27.5, 'B': 29.0, 'C': 30.25}
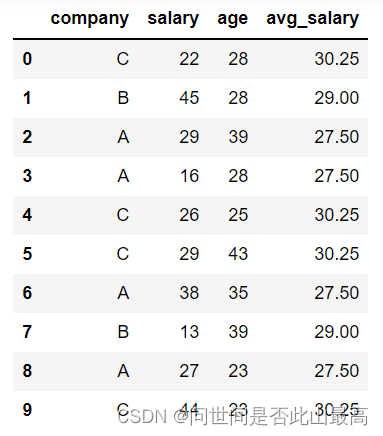
最后用map()函数按映射关系添加到源数据集
map()函数可以作为用于Series对象或DataFrame对象的一列,返回经过函数或字典映射处理后的值:
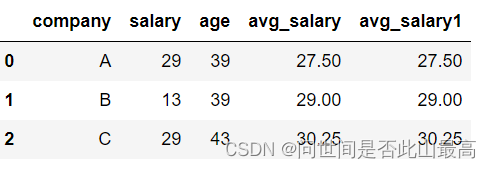
data["avg_salary"] = data['company'].map(avg_salary_dict)
data
输出:
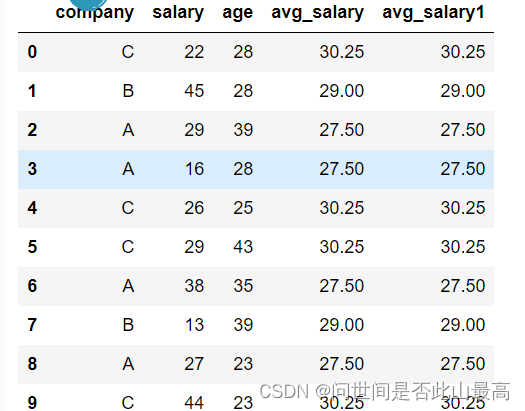
如果我们使用transfrom,仅需要一行代码:
data['avg_salary1'] = data.groupby('company')['salary'].transform('mean')
data
#分组之后的数据3条 A-值 B-值 C-对应的值
输出:
data.groupby('company')['salary'].transform('mean')
输出:
0 30.25
1 29.00
2 27.50
3 27.50
4 30.25
5 30.25
6 27.50
7 29.00
8 27.50
9 30.25
Name: salary, dtype: float64
4.apply
更加灵活,能传入任意自定义的参数
 例如,现在需要获得各个公司年龄最大的员工的数据:
例如,现在需要获得各个公司年龄最大的员工的数据:
def get_oldest_staff(x):
#输入的数据按age字段进行排序
df = x.sort_values(by = 'age', ascending=True)
#返回最后一条数据
return df.iloc[-1]
oldest_staff = data.groupby('company', as_index=False).apply(get_oldest_staff)
oldest_staff
输出:


pd.merge(left,right,how:str=‘inner’,on=None,left_on=None,right_on=None,left_index:bool=False,right_index:bool=False,sort:bool=False,suffixes(‘_x’,‘_y’),copy:bool=True,indicator:bool=False,validate=None)
首先新建两张表:
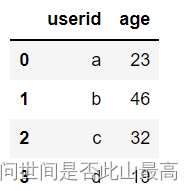
df_1 = pd.DataFrame({
'userid':['a','b','c','d'],
'age':[23,46,32,19]
})
df_1
输出:
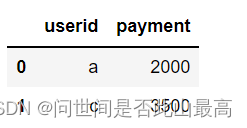
df_2 = pd.DataFrame({
'userid':['a','c'],
'payment':[2000,3500]
})
df_2
输出:
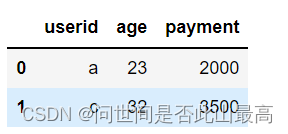
使用userid连接两张表:pd.merge(df_1,df_2,on='userid')或df_1.merge(df_2,on="userid")
输出:
用’left’进行merge:
df_1 = pd.DataFrame({
'userid':['a','b','c','d'],
'age':[23,46,32,19]
})
df_2 = pd.DataFrame({"userid":['a','c','e'],
"payment":[2000,3500,600]
})
pd.merge(df_1,df_2,how="left",on="userid")
输出:
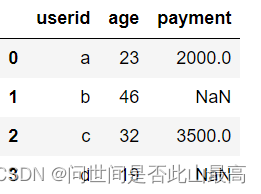
以左边表格的所有键为基准进行配对,e不在左表中,故不会配对。
若how="right",则会以右边的表格为基准进行配对。
其他
set_index
专门将某一列设置为index的方法
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
keys:要设置为索引的列名(如果有多个应放在一个列表里)
drop:将设置为索引的列删除,默认为True
append:是否将新的索引追加到原索引后(即是否保留原索引),默认为False
inplace:是否在原DataFrame上修改,默认为False
verify_integrity:是否检查索引有无重复,默认为False
示例:
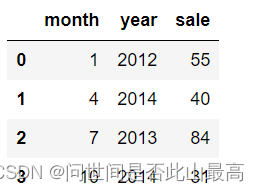
df = pd.DataFrame({'month':[1,4,7,10],
'year':[2012,2014,2013,2014],
'sale':[55,40,84,31]})
#将索引设置为"MONTH"列
df.set_index('month')
输出:
year sale
month
1 2012 55
4 2014 40
7 2013 84
10 2014 31
将month列设置为index之后,并保留原来的列:df.set_index('month',drop=False)
输出:
 保留原来的列:
保留原来的列:
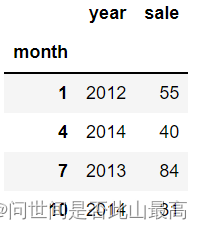
df.set_index('month',append=True)
df
输出:
使用Inplace参数取代原来的对象:
df.set_index('month',inplace=True)
df
输出:
pandas去重函数:drop_duplicates()
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
subset:表示要去重的别名,默认是None
keep:有三个可选参数:first,last,False,默认为first,表示只保留第一次出现的重复项,删除其余重复项,last表示只保留最后一次出现的重复项,False则表示删除所有重复项
inplace:布尔值参数,默认为False表示删除重复项后返回一个副本,若为True则表示直接在源数据上删除重复项
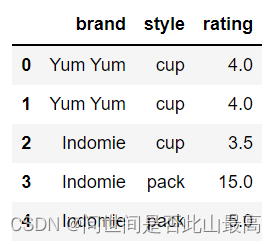
df = pd.DataFrame({
'brand':['Yum Yum','Yum Yum','Indomie','Indomie','Indomie'],
'style':['cup','cup','cup','pack','pack'],
"rating":[4,4,3.5,15,5]
})
print(df)
#默认情况下,它会基于所有列删除重复的行
df.drop_duplicates()
输出:
删除后:
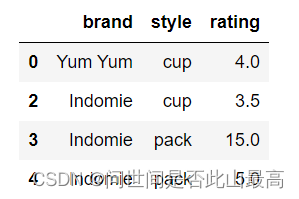
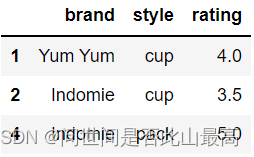
删除重复项并保留最后出现的项,请使用"保留":
df.drop_duplicates(subset=['brand','style'],keep='last')
输出:
tolist():
用于将一个系列或数据帧中的列转换为列表
如:
df.index
输出:
RangeIndex(start=0, stop=5, step=1)
df.index.tolist()
输出:
`
[0, 1, 2, 3, 4]
df['brand']
输出:
0 Yum Yum
1 Yum Yum
2 Indomie
3 Indomie
4 Indomie
Name: brand, dtype: object
八、str方法简介



举例:
1.pd.str.lower()字母转小写
s = pd.Series(['C','Python','java','go',np.nan,'1125','javascript'])
s.str.lower()
输出:
0 c
1 python
2 java
3 go
4 NaN
5 1125
6 javascript
dtype: object
2.pd.str.upper()字母转大写
s = pd.Series(['C','Python','java','go',np.nan,'1125','javascript'])
s.str.upper()
输出:
0 C
1 PYTHON
2 JAVA
3 GO
4 NaN
5 1125
6 JAVASCRIPT
dtype: object
3.pd.str.len()获取字符串的长度
s = pd.Series(['C','Python','java','go',np.nan,'1125','javascript'])
s.str.len()
输出:
0 1.0
1 6.0
2 4.0
3 2.0
4 NaN
5 4.0
6 10.0
dtype: float64
4.pd.str.strip()去除字符两边的空格(包括换行符)
s = pd.Series(['C ','Python\t\n',' java ','go\t',np.nan,'\t1125','\tjavascript'])
#s.str.strip()
s.str.strip(" ")
输出:
0 C
1 Python\t\n
2 java
3 go\t
4 NaN
5 \t1125
6 \tjavascript
dtype: object
打印:
print(s[1])
输出:
Python
5.pd.str.split(" ")用指定的分隔符分割字符串
s = pd.Series(['Zhang hua','Py thon\n','java','go',np.nan,'11 25','javascript'])
#s.str.split()
s.str.split(" ")
输出:
0 [Zhang, hua]
1 [Py, thon\n]
2 [java]
3 [go]
4 NaN
5 [11, 25]
6 [javascript]
dtype: object
6.pd.str.cat(sep=“”)用指定的分隔符连接字符串元素
s = pd.Series(['C','Python','java','go',np.nan,'1125','javascript'])
s_cat = s.str.cat(sep="_")#会自动忽略NaN
s_cat
输出:
'C_Python_java_go_1125_javascript'
还原:
pd.Series(s_cat.split("_"))
输出:
0 C
1 Python
2 java
3 go
4 1125
5 javascript
dtype: object
7.pd.str.contains(pattern)是否包含字符串
s = pd.Series([' C',' Python','java','go',np.nan,'1125','javascript'])
s.str.contains(" ")
输出:
0 True
1 True
2 False
3 False
4 NaN
5 False
6 False
dtype: object
取出s中包含空格的元素:
s = pd.Series([' C',' Python','java','go','1125','javascript'])
s[s.str.contains(" ")]
输出:
0 C
1 Python
dtype: object
8.pd.str.replace(a,b)将值a替换成值b
s = pd.Series(['C','Python','java','go',np.nan,'1125','javascript'])
s.str.replace("java","python")
输出:
0 C
1 Python
2 python
3 go
4 NaN
5 1125
6 pythonscript
dtype: object
9.pd.str.count(pattern)返回每个字符串出现的次数
s = pd.Series([' C',' Python','java','go',np.nan,'1125','javascript'])
s.str.count('Python')
输出:
0 0.0
1 1.0
2 0.0
3 0.0
4 NaN
5 0.0
6 0.0
dtype: float64
10.pd.str.startswith(pattern)
如果Series中的元素以指定的字符串开头,则返回True
s = pd.Series([' C',' Python','java','go',np.nan,'1125','javascript'])
print(s.str.startswith("j"))
输出:
0 False
1 False
2 True
3 False
4 NaN
5 False
6 True
dtype: object
11.pd.str.endswith(pattern)
如果Series中的元素以指定的字符串结尾,则返回True
s = pd.Series([' C',' Python','java','go',np.nan,'1125','javascript'])
print(s.str.endswith("a"))
输出:
0 False
1 False
2 True
3 False
4 NaN
5 False
6 False
dtype: objec
12.pd.str.findall(pattern)以列表的形式返回出现的字符串
s = pd.Series([' C',' Python','java','go',np.nan,'1125','javascript'])
print(s.str.findall("a"))
输出:
0 []
1 []
2 [a, a]
3 []
4 NaN
5 []
6 [a, a]
dtype: object
13.pd.str.find(pattern)
返回字符串第一次出现的索引位置
s = pd.Series([' C',' Python','java','go',np.nan,'1125','javascript'])
print(s.str.find("a"))
输出:
0 -1.0
1 -1.0
2 1.0
3 -1.0
4 NaN
5 -1.0
6 1.0
dtype: float64
14.pd.str.repeat(int)
将字符串重复int次
s = pd.Series([' C',' Python','java','go',np.nan,'1125','javascript'])
print(s.str.repeat(3))
输出:
0 C C C
1 Python Python Python
2 javajavajava
3 gogogo
4 NaN
5 112511251125
6 javascriptjavascriptjavascript
dtype: object
补充:map()、apply()、applymap()函数

1.apply()方法
是一般性的“拆分-应用-合并”方法。
df.apply(func, axis=0, raw=False, result_type=None, args=(), **kwgs)
func:函数应用于每一列或每一行
axis:
0或“索引”:将函数应用于每一列
1或“列”:将函数应用于每一行
新建一个列表:
df = pd.DataFrame([[4,9]]*3,columns=['A','B'])
df
输出:
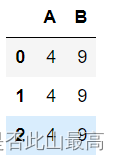
对每一列求和df.apply(np.sum)
输出:
A 12
B 27
dtype: int64
对每一行求和:df.apply(np.sum, axis=1)
输出:
0 13
1 13
2 13
dtype: int64
或者使用lambda函数做简单的运算:df.apply(lambda x: x+1)
输出:
A B
0 5 10
1 5 10
2 5 10
但是这样并不方便,每次都要定义lambda函数,因此可以def定义一个函数,
然后调用函数完成相应的处理:
如:
def cal_result(df, x, y):
df['C'] = (df['A'] + df['B'])*x
df['D'] = (df['A'] + df['B'])*y
return df
df.apply(cal_result, x=3, y=8, axis=1)
#或者df.apply(cal_result, args=(3,8), axis=1)
#或者df.apply(cal_result,**{'x':3,'y':8},axis=1)
输出:
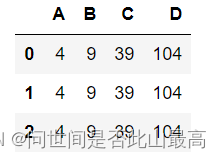

**2.applymap()方法
针对DataFrame中的元素进行操作**
df.applymap(lambda x: '%.2f'%x)
输出:
A B
0 4.00 9.00
1 4.00 9.00
2 4.00 9.00

#取列
df[['A']].applymap(lambda x:'%.2f'%x)
输出:
A
0 4.00
1 4.00
2 4.00
若:df['A'].applymap(lambda x:'%.2f'%x)#异常
输出:


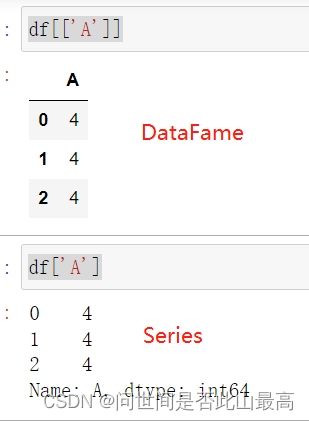
3.map()方法:用在Series中的
df['A'].map(lambda x:'%.2f'%x)
输出:
0 4.00
1 4.00
2 4.00
Name: A, dtype: object















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









