






前言
博主初次接触SVM,无论是其数学原理,还是高深的用法都缺少相应的知识储备,本文仅仅是我在学长的指导下首次成功使用SVM对几何体进行分类之后回顾所学到的内容的一个总结性学习记录。此外我会把自己在学习过程中遇到的一些困难之处讲解清楚,希望能够对像我这样的SVM乃至opencv小白起到一些启发的作用。
1.了解SVM的相关原理
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)(来自百度百科)
上面所提到的对学习样本求解的最大边距超平面其实就是对所有样本的一个分类标准类,类似于数学中区分正负数的0的概念,SVM就是要通过训练模型寻找出多维空间中的这个"0"(超平面)。

如上图所示,中间的一条斜线就是我们的训练结果,用来区分样本属于圆圈或是叉的超平面。这是二维空间的情况,可能会出现样本混杂不清,无法画出这条直线的情况,这时候上升到多维空间,总是存在一个维度可以让一个平面区分出两类物体,这就是二分类。
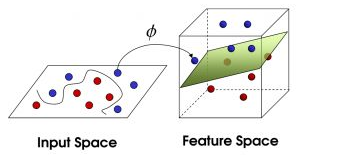 如图就是二维空间不可分到三维空间可分。
如图就是二维空间不可分到三维空间可分。
SVM学习目标是最大边距超平面,最大边距是说距离正反样本距离最大,即选择所有超平面中分类效果最好的。
上面是我对SVM原理的粗浅了解,要更加深入的了解SVM,推荐下面两篇博文:
https://blog.csdn.net/v_JULY_v/article/details/7624837
https://www.jianshu.com/p/61849d554001
2.在QT环境下使用opencv库初步实现SVM
我会把我的学习过程分阶段的展示出来,中间会穿插我遇到的一些困难。
2.1使用SVM的大致流程+代码解释
我所遇到的第一个问题就是我已经大概明白SVM是什么了,可是我还是不知道应该怎么使用SVM,因为它不像其他的opencv库函数,只需要明白参数,然后直接调用即可,在使用SVM之前还需要有很多准备工作。
2.1.1准备训练样本
由于SVM是一个学习器,在训练之前必须准备好训练样本,包括正样本和负样本 ,比如我的目的是识别几何体,就需要准备几何体的正样本,以及非几何体的负样本。如下是我使用的样本:


(该样本由我的学长采集,下面附上我自己编写的采集样本代码)
样本采集的方法是编写程序利用opencv处理拍摄的照片,选择目标物体的部分裁剪图片然后保存到文件夹。这其中的难点是如何在视频中选中目标物体。代码如下:
#include<opencv2/opencv.hpp>
#include<iostream>
using namespace cv;
using namespace std;
char son[1200];
int number_h_max =180,number_h_min=0;
int number_s_max =255,number_s_min=43;
int number_v_max =255,number_v_min=46;
int j=0,k=1;
Mat frame,hsv_Image,division_Image,blur_Image;
void take_photos();
static void division(int,void*);
int main()
{
take_photos();
return 0;
}
void take_photos()
{
/*------------------------打开摄像头,并读取画面---------------------------------*/
VideoCapture capture(-1);//打开摄像头,电脑自带的摄像头一般参数为0。
while((char)waitKey(1)!='q')//按下Q键位之前一直循环执行程序。
{
capture >>frame;
if(!frame.data)//检测frame中有没有数据
{
cout<<"false to get picture"<<endl;
}
/*--------------------------转变图像为HSV图像----------------------------*/
namedWindow("capture",WINDOW_AUTOSIZE);
cvtColor(frame,hsv_Image,COLOR_BGR2HSV);//转变图像为HSV图像,为下面的目标物分离做准备。
namedWindow("hsv_Image",WINDOW_AUTOSIZE);
/*------------------------创建滑动条,分别控制H,S,V的极值----------------------*/
createTrackbar("H_min","hsv_Image",&number_h_min,180,division,0);
createTrackbar("H_max","hsv_Image",&number_h_max,180,division,0);
createTrackbar("S_min","hsv_Image",&number_s_min,255,division,0);
createTrackbar("S_max","hsv_Image",&number_s_max,255,division,0);
createTrackbar("V_min","hsv_Image",&number_v_min,255,division,0);
createTrackbar("V_max","hsv_Image",&number_v_max,255,division,0);
division(0,0);
imshow("hsv_Image",hsv_Image);
if(!division_Image.data)
{cout<<"false to get division"<<endl;}
imshow("divisino",division_Image);
while((char)waitKey(1)!='t'){}//在这里设置一次停顿,因为需要调节滑动条需要处理上一帧画面,利用颜色分离出不同的目标物体之后再进入截取图像操作
/*---------------------------------------将通过色彩分割的图像进行二次处理,得到只剩下目标区域的部分---------------------------------------------*/
blur(division_Image,blur_Image,Size(3,3),Point(-1,-1));//对颜色分割之后的图像进行滤波处理,将目标图像外区域的干扰白色点饱和度降低。
threshold(blur_Image,blur_Image,240,255,0);//通过二值化操作将目标物体和周围经过滤波导致亮度下降的干扰因素分离,得到只存在目标物体的图像 。
imshow("blur",blur_Image);
/*--------------------------------寻找轮廓,确定坐标截取图像----------------------------------*/
vector<vector<Point>>contours;//设置二维向量储存下面寻找出的轮廓
vector<Vec4i>hierarchy;//一维向量储存轮廓的等级
findContours(blur_Image,contours,hierarchy,CV_RETR_EXTERNAL,CV_CHAIN_APPROX_NONE);
vector<Rect> boundRect(contours.size());//创建向量用于储存外接矩形坐标,长宽信息
int x,y,w,h;
for(int i=0;i<contours.size();i++)
{
boundRect[i]=boundingRect(contours[i]);
x=boundRect[i].x;
y=boundRect[i].y;//(x,y)的坐标是轮廓左上角的坐标
w=boundRect[i].width;
h=boundRect[i].height;
// rectangle(frame,Point(x,y),Point(x+w,y+h),(0,255,0),2,8);
/*--------------------------利用感兴趣区域截取图片---------------------------*/
Mat imageROI=frame(Rect(x-5,y-5,w+8,h+8));//定义轮廓外接矩形区域为感兴趣区域,设置的稍大一点可以让截取的目标物图像更完整。
Mat image;
imageROI.copyTo(image);//将感兴趣区域复制到image图像中
imshow("ROI",image);
sprintf(son,"/home/weishibo/example/s%d/%d.jpg",j,k);//这一步是按顺序储存截取到的样本图片
if(w>20)//做一个简单的筛选条件,因为经过各种处理的图片不会留下大的轮廓干扰,所以简单的长度筛选就可以排除错误保存图片,也可以设置更加细致的筛选条件。
{
imwrite(son,image);
k++;
}
}
imshow("capture",frame);
//waitKey(1);
}
}
static void division(int,void*)
{
inRange(hsv_Image,Scalar(number_h_min,number_s_min,number_v_min),Scalar(number_h_max,number_s_max,number_v_max),division_Image);
imshow("divisino",division_Image);
}
这段代码用于采集训练样本,分为两个阶段,第一阶段处理画面留下目标物体,第二阶段寻找轮廓设置感兴趣区域然后截图保存。可能会遇到的问题是出现轮廓越界,然后程序会停止。可以写代码避免越界情况,我没有做相应处理,每次程序停止后调整K的值(保存了多少张图片就设置为多少+1即可)。


这分别是HSV图像和彩色图分割图像,通过调整左边的滑动条,可以改变右边剩余的白色区域。其中H控制色调,改变H范围可以筛选颜色,S控制饱和度,改变S范围可以筛选饱和度,V控制明度,改变V范围可以筛选亮度。
然后建议不同样本分文件夹储存,就是每次更换样本就改变J的取值(前提是创建好文件夹用于保存)如下图:


2.1.2处理训练数据
收集到训练样本之后需要经过简单的处理才能够录入为训练数据。代码如下:
#include"conduct.h"
int row=30,col=30;
Mat train_data,train_mark,train_data_new;
Ptr<SVM> SVM_train = SVM::create();
void conduct()
{
char ex[255];
int j=0,i=1;
Mat ex_Image,ex1_Image,balance_Image,size_Image,ba_Image,data_Image;
for(j=0;j<6;j++)
{
for(i=1;i<200;i++)
{
sprintf(ex,"/home/weishibo/example/s%d/%d.jpg",j,i);//把字符串输入到字符数组里面,目的是让字符串可以根据变量的改变而改变。
ex_Image=imread(ex,IMREAD_GRAYSCALE);//读取样本为灰度图
if(!ex_Image.data)//检测样本读取情况
{
cout<<"no data"<<endl;
break;
resize(ex_Image,size_Image,Size(row,col),0,0,INTER_NEAREST);//统一样本图片的尺寸
data_Image=size_Image.reshape(0,1);//把样本图转化为行矩阵
train_data.push_back(data_Image);//把样本图数据储存到训练样本中,用push_back函数是直接添加到样本末尾。此外还可以使用定义感兴趣区域的办法分板块存放数据到训练集。
if(j==5)//这一步是考虑S5文件夹为负样本,标记为-1。
{
train_mark.push_back(-1);
continue;
}
train_mark.push_back(j);//给数据打上相应的标签。
}
}
train_data.convertTo(train_data_new,CV_32F);//转换数据类型为cv_32f,因为SVM训练只能用该数据类型类型
}
/*------------------------设置SVM参数-----------------------------*/
//网上有很多介绍SVM参数的文章,需要注意的是opencv3和opencv2有差异。
void train()
{
SVM_train->setType(SVM::C_SVC);//设置SVM类型
SVM_train->setKernel(SVM::LINEAR);//设置SVM核类型
SVM_train->setGamma(0.01);
SVM_train->setC(10.0);
SVM_train->setTermCriteria(TermCriteria(CV_TERMCRIT_EPS,10000,FLT_EPSILON));
cout<<"开始训练"<<endl;
SVM_train->train(train_data_new,ROW_SAMPLE,train_mark);
cout<<"结束训练"<<endl;
SVM_train->save("svm2.xml");
}
这里录入训练数据,代码中是直接转变为灰度图,然后变成一行数据,添加到训练数据集的末尾。我尝试了转变为轮廓图再录入训练数据,发现训练效果很差,因为我识别几何体轮廓比较接近。但是我觉得应该有比直接传灰度图更好的方法处理样本图,读者可以自己尝试其他办法。
代码中要强调的是SVM的设置opencv3和opencv2不一样,需要特别注意。然后SVM的参数 设置我也 是参照网上的示例设置的,没有深入研究,就没有具体注释。
2.1.3通过训练好的模型来进行预测
模型训练好之后可以不储存直接预测,由于我的代码结构的问题,我选择的是储存之后读取模型进行预测。代码如下:
#include<opencv2/opencv.hpp>
#include<iostream>
#include"collect.h"
#include"conduct.h"
using namespace cv;
using namespace std;
static void division1(int,void*);
int number_h1_max =180,number_h1_min=0;
int number_s1_max =255,number_s1_min=43;
int number_v1_max =255,number_v1_min=46;
Mat frame1;
Mat src_Image,e_Image,blur1_Image,division1_Image,Gray_Image;
int main()
{
// take_photos();
// conduct();
// train();
VideoCapture capture(-1);
// Ptr<SVM> SVM_Classifier = SVM::create();
// SVM_Classifier->clear();
Mat element = getStructuringElement(MORPH_RECT,Size(5,5));
Ptr<SVM>SVM_Classifier = Algorithm::load<SVM>("/home/weishibo/opev-learning/build-cramer4-Desktop_Qt_5_9_4_GCC_64bit-Debug/svm2.xml");//设置一个新的SVM读取我刚刚训练出来的模型 。
while(1)
{
capture>>frame1;
if(!frame1.data)
{
cout<<"false data"<<endl;
continue;
}
namedWindow("frame1",WINDOW_AUTOSIZE);
imshow("frame1",frame1);
cvtColor(frame1,Gray_Image,COLOR_BGR2GRAY);
while((char)waitKey(1)!='k')//由于我发现我的几何体在 环境中依靠固定的代码不容易分离出来,所以所以设置了一个循环让我可以在调整参数之后进行图像的分割预测。
{
cvtColor(frame1,src_Image,COLOR_RGB2HSV);
createTrackbar("H_min","inrange",&number_h1_min,180,division1,0);
createTrackbar("H_max","inrange",&number_h1_max,180,division1,0);
createTrackbar("S_min","inrange",&number_s1_min,255,division1,0);
createTrackbar("S_max","inrange",&number_s1_max,255,division1,0);
createTrackbar("V_min","inrange",&number_v1_min,255,division1,0);
createTrackbar("V_max","inrange",&number_v1_max,255,division1,0);
division1(0,0);
}
morphologyEx(division1_Image,e_Image,MORPH_OPEN,element);//进行开运算去除小的白色噪点。之前我运用的是先均值滤波,再二值化图像。
imshow("e_Image",e_Image);
vector<vector<Point>>contours;
vector<Vec4i>hierarchy;
findContours(e_Image,contours,hierarchy,CV_RETR_EXTERNAL,CHAIN_APPROX_SIMPLE,Point(0,0));
for(int i=0;i<contours.size();i++)//循环读取轮廓,取得轮廓的外包围矩形,用于截取目标物体。
{
vector<Rect> boundRect(contours.size());
int x,y,w,h;
boundRect[i]=boundingRect(contours[i]);
x=boundRect[i].x;
y=boundRect[i].y;
w=boundRect[i].width;
h=boundRect[i].height;
/*---------------------使用得到的轮廓外包围矩形坐标截取物体----------------------*/
if(w>15)
{
Mat imageROI=Gray_Image(Rect(x,y,w,h));//利用感兴趣区域截图
Mat image,size1_Image,size1_Image_new,reshape_iamge;
imageROI.copyTo(image);
resize(image,size1_Image,Size(30,30),0,0,INTER_NEAREST);//变化截取的图像尺寸和训练图像相同。
reshape_iamge=size1_Image.reshape(0,1);//转化为一行的矩阵
reshape_iamge.convertTo(size1_Image_new,CV_32F);//转变数据类型
float mark=SVM_Classifier->predict(size1_Image_new);//进行预测,返回相应的预测结果赋值给mark。
cout<< mark<<endl;//输出查看预测结果
}
}
waitKey(1);
}
return 0;
}
static void division1(int,void*)
{
inRange(src_Image,Scalar(number_h1_min,number_s1_min,number_v1_min),Scalar(number_h1_max,number_s1_max,number_v1_max),division1_Image);
imshow("inrange",division1_Image);
}
由于我写代码的时候是多文件编写的,这是主文件,看起来可能有些混乱。这一部分的逻辑是先通过颜色分割大致选择出几何体,然后通过求轮廓,再取得外包围矩形,然后截取图片调整后进行预测。截取出的图片需要做和样本图片进行训练时的相同处理。


可以看到由于参数调整不当,识别效果很差,没有识别到中间的正方体。

参数调整恰当后,可以看到就能比较准确的识别出正方体(即返回数字3).
关于需要针对物体调整参数的问题,原因之一是我测试的地方周围干扰因素过多,如果在外部环境简单的地方,就可以确定参数不需要手动调参了。















 2127
2127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









