







Coscheduling调度器插件原理
Kubernetes负责Kube-scheduler的小组sig-scheduler为了更好的管理调度相关的Plugin,新建了项目scheduler-plugins管理不同场景的Plugin。Coscheduling Plugin成为该项目的第一个官方插件,
基于scheduling framework实现的Coscheduling Plugin架构
PodGroup
我们通过label的形式来定义PodGroup的概念,拥有同样label的Pod同属于一个PodGroup。min-available是用来标识该PodGroup的作业能够正式运行时所需要的最小副本数。
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "2"
注意: 要求属于同一个PodGroup的Pod必须保持相同的优先级
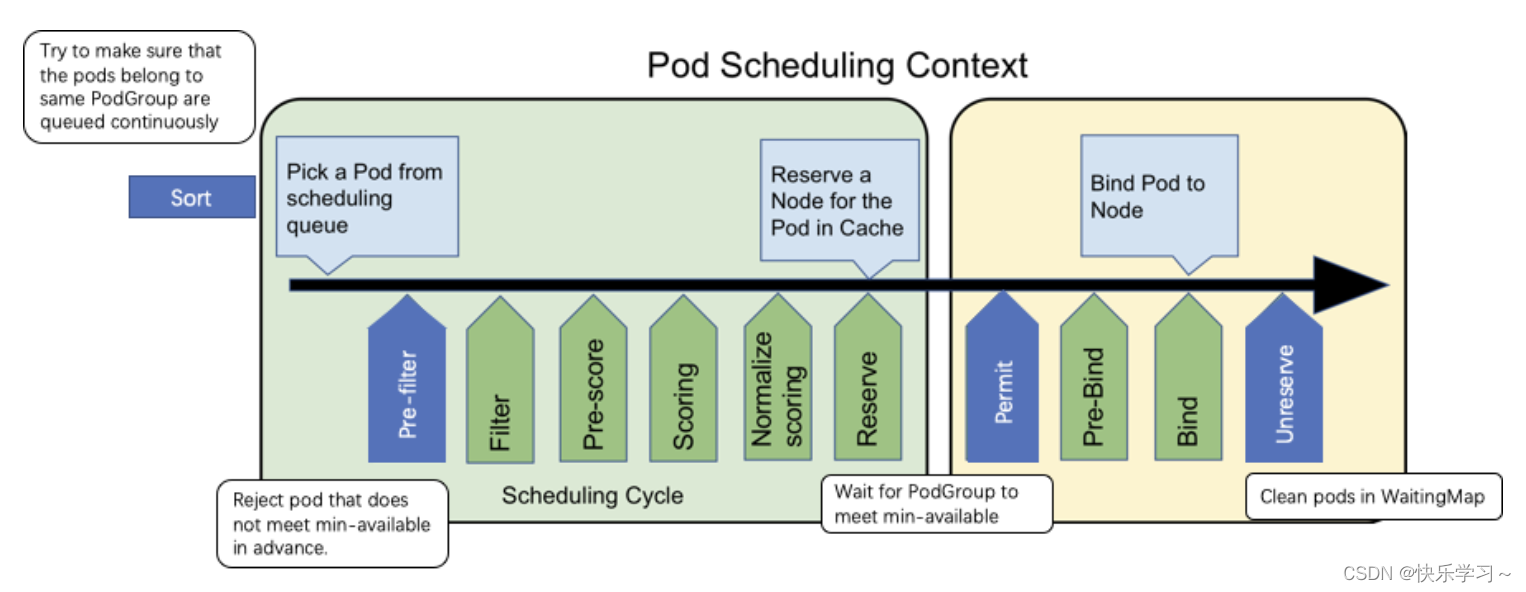
Coscheduling Plugin在每个调度环节的原理剖析
一、Permit环节
Framework的Permit插件提供了延迟绑定的功能,即Pod进入到Permit阶段时,用户可以自定义条件来允许Pod通过、拒绝Pod通过以及让Pod等待状态(可设置超时时间)。Permit的延迟绑定的功能,刚好可以让属于同一个PodGruop的Pod调度到这个节点时,进行等待,等待积累的Pod数目满足足够的数目时,再统一运行同一个PodGruop的所有Pod进行绑定并创建。
举个实际的例子,当JobA调度时,需要4个Pod同时启动,才能正常运行。但此时集群仅能满足3个Pod创建,此时与Default Scheduler不同的是,并不是直接将3个Pod调度并创建。而是通过Framework的Permit机制进行等待。
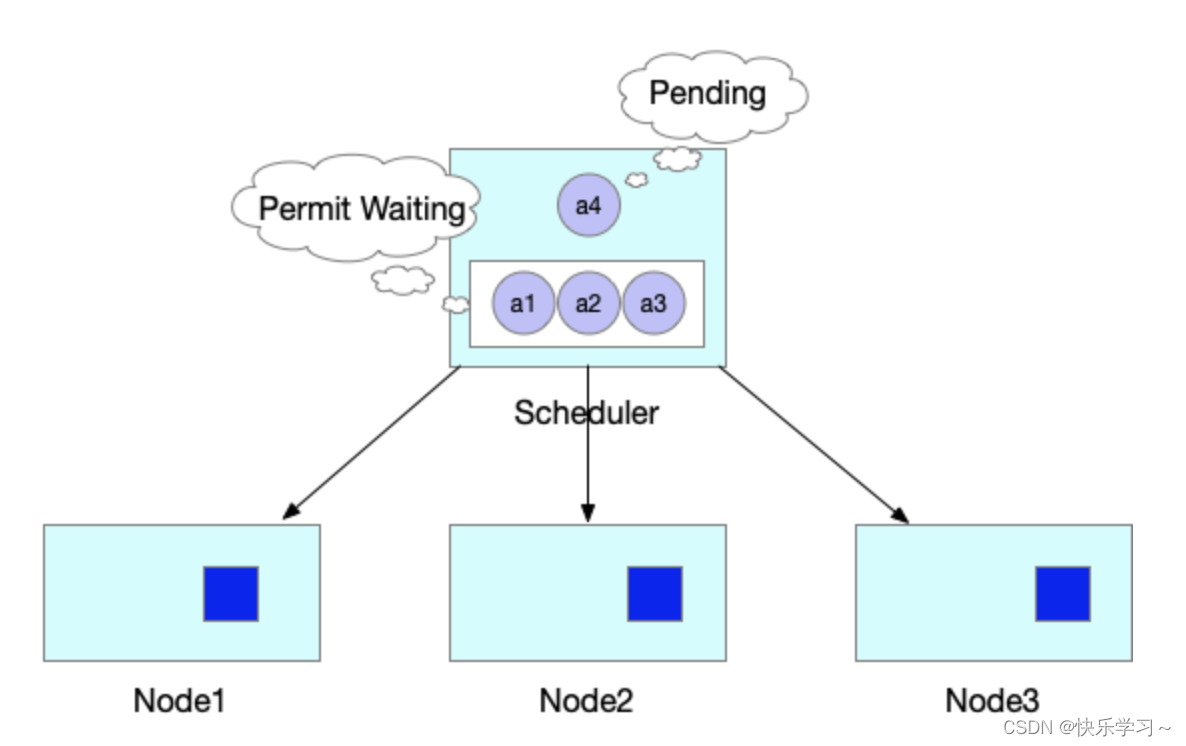
此时当集群中有空闲资源被释放后,JobA的中Pod所需要的资源均可以满足。
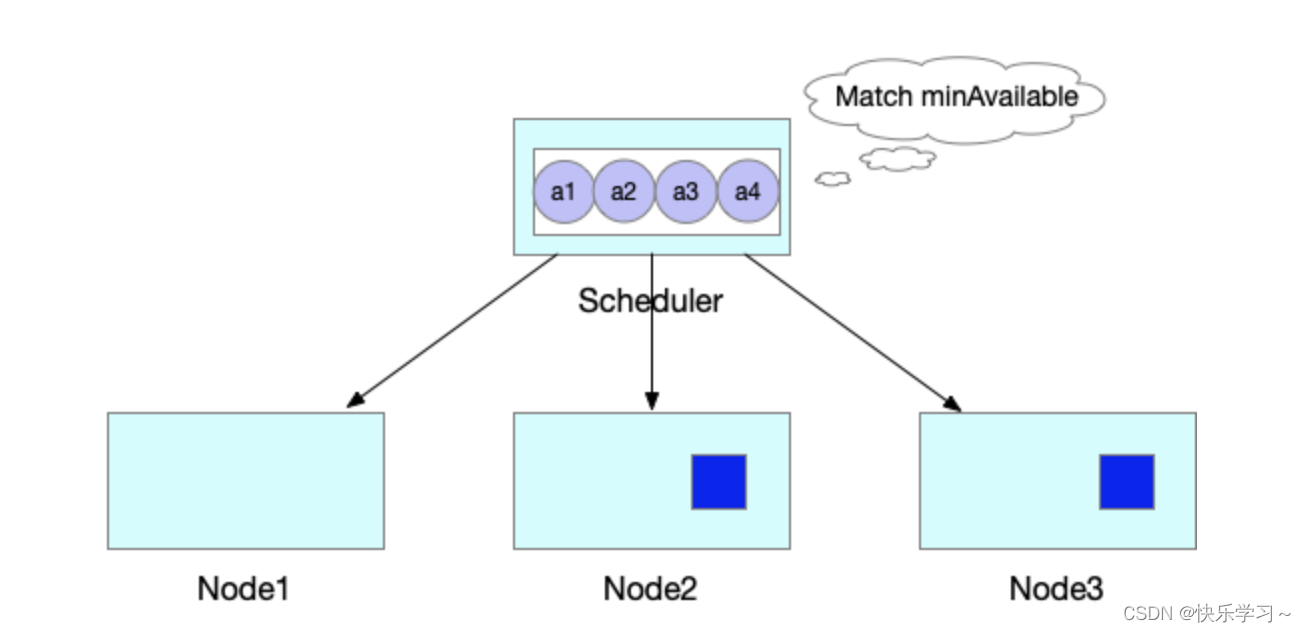
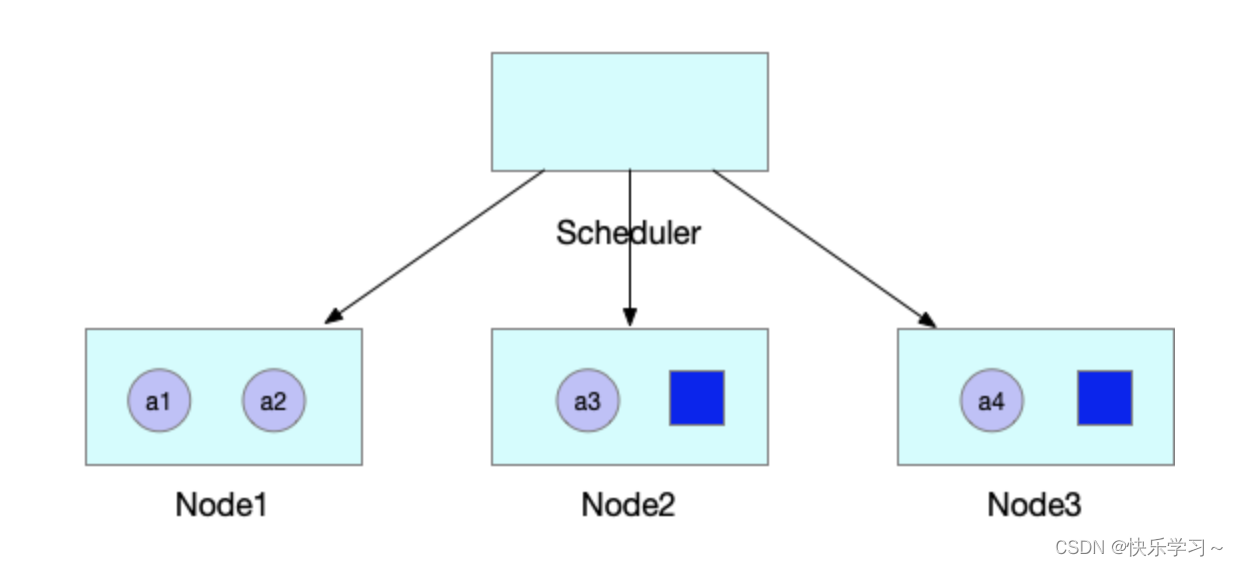
则JobA的4个Pod被一起调度创建出来,正常运行任务。
二、QueueSort环节
由于Default Scheduler的队列并不能感知PodGroup的信息,所以Pod在出队时处于无序性(针对PodGroup而言)。如下图所示,a和b表示两个不同的PodGroup,两个PodGroup的Pod在进入队列时,由于创建的时间交错导致在队列中以交错的顺序排列。

当一个新的Pod创建后,入队后,无法跟与其相同的PodGroup的Pod排列在一起,只能继续以混乱的形式交错排列。

这种无序性就会导致如果PodGroupA在Permit阶段处于等待状态,此时PodGroupB的Pod调度完成后也处于等待状态,相互占有资源使得PodGroupA和PodGroupB均无法正常调度。这种情况即是把死锁现象出现的位置从Node节点移动到Permit阶段,无法解决前文提到的问题。
针对如上所示的问题,我们通过实现QueueSort插件, 保证在队列中属于同一个PodGroup的Pod能够排列在一起。我们通过定义QueueSort所用的Less方法,作用于Pod在入队后排队的顺序:
func Less(podA *PodInfo, podB *PodInfo) bool
首先,继承了默认的基于优先级的比较方式,高优先级的Pod会排在低优先级的Pod之前。
然后,如果两个Pod的优先级相同,我们定义了新的排队逻辑来支持PodGroup的排序。
1、如果两个Pod都是regularPod(普通的Pod),则谁先创建谁在队列里边排在前边。
2、如果两个Pod一个是regularPod,另一个是pgPod(属于某个PodGroup的Pod),
我们比较的是regularPod的创建时间和pgPod所属PodGroup的创建时间,
则谁先创建谁在队列里边排在前边。
3、如果两个Pod都是pgPod,我们比较两个PodGroup的创建时间,则谁先创建谁在队列里边排在前边。
同时有可能两个PodGroup的创建时间相同,我们引入了自增Id,
使得PodGroup的Id谁小谁排在前边(此处的目的是为了区分不同的PodGroup)。
通过如上的排队策略,我们实现属于同一个PodGroup的Pod能够同一个PodGroup的Pod能够排列在一起。

当一个新的Pod创建后,入队后,会跟与其相同的PodGroup的Pod排列在一起。

三、Prefilter环节
为了减少无效的调度操作,提升调度的性能,我们在Prefilter阶段增加一个过滤条件,当一个Pod调度时,会计算该Pod所属PodGroup的Pod的Sum(包括Running状态的),如果Sum小于min-available时,则肯定无法满足min-available的要求,则直接在Prefilter阶段拒绝掉,不再进入调度的主流程。
四、UnReserve环节
如果某个Pod在Permit阶段等待超时了,则会进入到UnReserve阶段,我们会直接拒绝掉所有跟Pod属于同一个PodGroup的Pod,避免剩余的Pod进行长时间的无效等待。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









