










 文章详细介绍了Prometheus的告警触发流程,包括数据采集间隔、评估周期和超时时间。当告警触发后,进入PENDING状态,经过一定时间评估后转为FIRING状态,Alertmanager接收到告警后,依据group_wait和group_interval进行分组和间隔发送。重复发送间隔由repeat_interval设定。group_wait和group_interval分别控制新告警组的发送延迟和同一组内告警的重发间隔。
文章详细介绍了Prometheus的告警触发流程,包括数据采集间隔、评估周期和超时时间。当告警触发后,进入PENDING状态,经过一定时间评估后转为FIRING状态,Alertmanager接收到告警后,依据group_wait和group_interval进行分组和间隔发送。重复发送间隔由repeat_interval设定。group_wait和group_interval分别控制新告警组的发送延迟和同一组内告警的重发间隔。
Prometheus一条告警的触发流程与等待时间
1、与告警等待时间相关的参数
prometheus.yml
global:
# 数据采集间隔
scrape_interval: 15s
# 评估告警周期
evaluation_interval: 15s
# 数据采集超时时间默认10s
# scrape_timeout
alertmanager.yml
# route标记:告警如何发送分配
route:
# group_by:采用哪个标签作为分组的依据
group_by: ['alertname']
# group_wait:分组等待的时间
group_wait: 10s
# group_interval:上下两组发送告警的间隔时间
group_interval: 10s
# repeat_interval:重复发送告警时间。默认1h
repeat_interval: 1m
# receiver 定义谁来通知报警
receiver: 'mail'
2、报警处理流程:
- 1、Prometheus通过scrape_interval定义的时间间隔,定期采集目标主机上监控数据。
- 2、当目标不可用的时候,Server端会持续的尝试从目标metrics接口中取数据,直到"scrape_timeout"时间后停止尝试。这时候把对象的状态变为“DOWN”。
- 3、Prometheus同时根据配置的"evaluation_interval"的时间间隔,定期(默认1min)的对Alert Rule进行评估;当到达评估周期的时候,发现接口A为DOWN,即UP=0为真,激活Alert,进入“PENDING”状态,并记录当前active的时间;
- 4、当下一个alert rule的评估周期到来的时候,发现UP=0继续为真,然后判断警报Active的时间是否已经超出rule里的‘for’ 持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则alert的状态变为“FIRING”;同时调用Alertmanager接口,发送相关报警数据。
- 5、AlertManager收到报警数据后,会将警报信息进行分组,然后根据alertmanager配置的“group_wait”时间先进行等待。等wait时间过后再发送报警信息。
- 6、属于同一个Alert Group的警报,在等待的过程中可能进入新的alert,如果之前的报警已经成功发出,那么间隔“group_interval”的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个group的报警信息会汇总在一个邮件里进行发送。
- 7、如果Alert Group里的警报一直没发生变化并且已经成功发送,等待‘repeat_interval’时间间隔之后再重复发送相同的报警邮件;如果之前的警报没有成功发送,则相当于触发第6条条件,则需要等待group_interval时间间隔后重复发送。
3、抓取,评估和警报

4、告警的生命周期


5、alertmanager部分等待分析

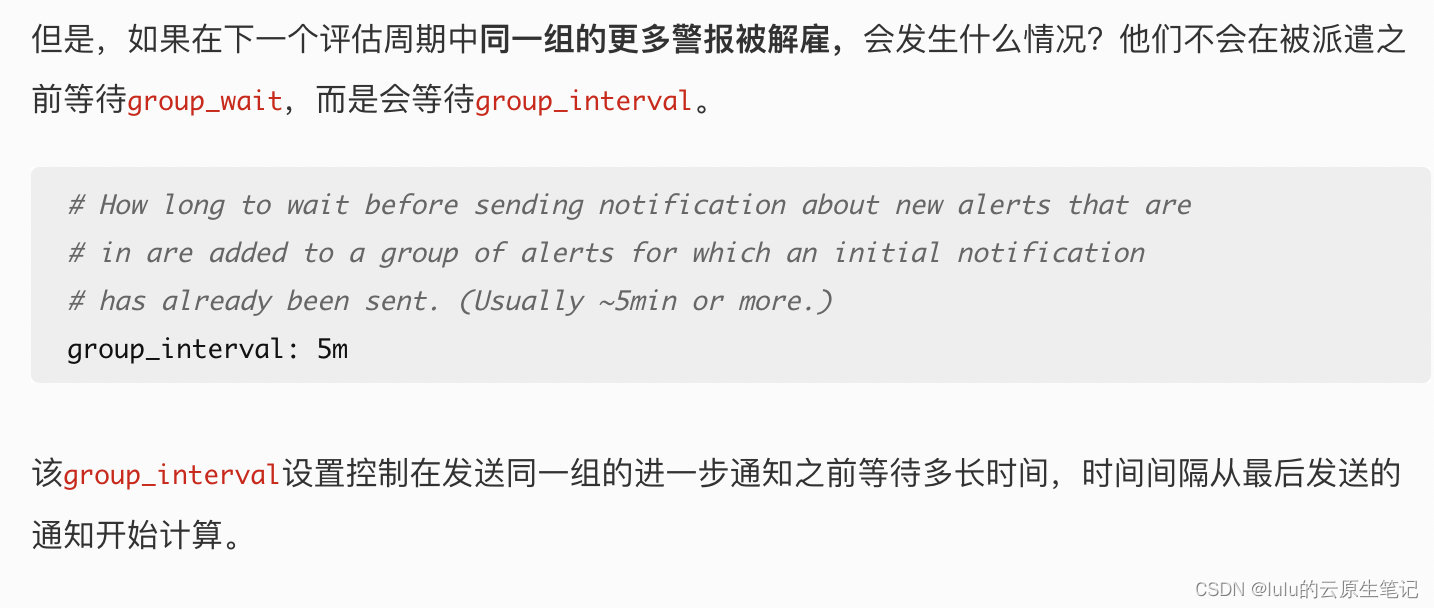
注意:group_wait与group_interval的重要区别
即:group_wait决定每一个新告警组需要等待多久才发送出去,group_interval决定同一个告警组的告警间隔。因此一条告警到了alertmanager如果是一个新组那么等待group_wait的时间,如果是加入了已经有的组,那么这个组是新组则等待group_wait的时间,否则等待group_interval的时间

















 2040
2040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









