










linux vxlan设备的不同场景下的四种使用方法
在不同场景下,我们vxlan设备通常有多种使用方法
- 点对点的 VXLAN:用于实现明确的端到端隧道
- VXLAN + Bridge:用于实现明确的端到端隧道,且端与端上的服务是多对多的
- 多播模式的 VXLAN:让同一个 VXLAN 网络中容纳多个节点,形成一张vxlan连通网
- 手动维护 vtep 组:用于自己维护网络拓扑,可自由规划,如:k8s flannel cni
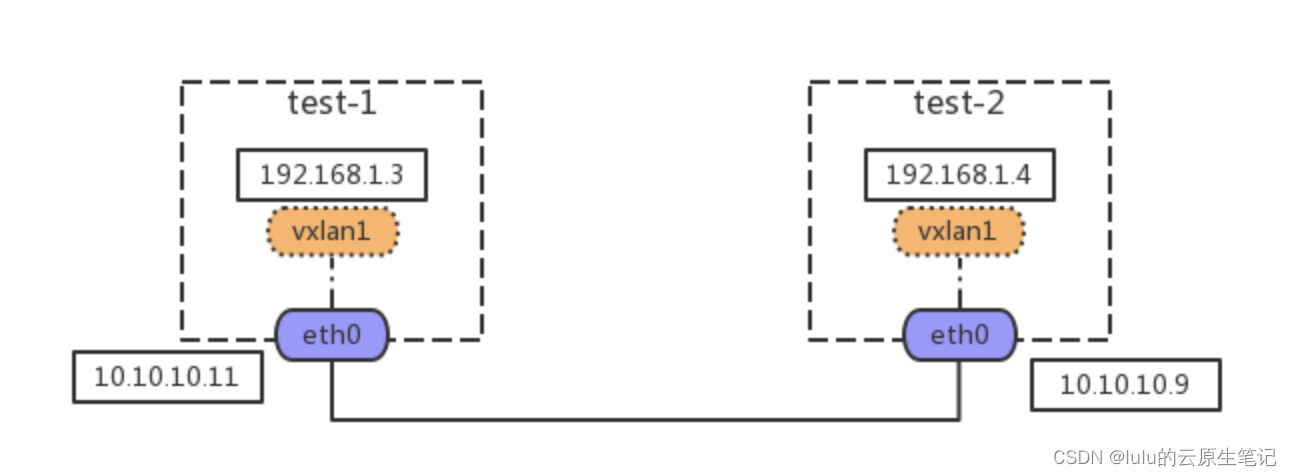
场景1:点对点的 VXLAN
点对点 VXLAN 即两台主机构建的 VXLAN 网络,每台主机上有一个 VTEP,VTEP 之间通过它们的 IP 地址进行通信。点对点 VXLAN 网络拓扑图如图所示:
实验环境示例:
# vm1
[root@test-1 ~]# uname -sr
Linux 3.10.0-693.el7.x86_64
[root@test-1 ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1446 qdisc pfifo_fast state UP qlen 1000
link/ether fa:16:3e:0c:e3:c6 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.11/24 brd 10.10.10.255 scope global dynamic eth0
valid_lft 84967sec preferred_lft 84967sec
# vm2
[root@test-2 ~]# uname -sr
Linux 3.10.0-693.el7.x86_64
[root@test-2 ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1446 qdisc pfifo_fast state UP qlen 1000
link/ether fa:16:3e:50:61:0d brd ff:ff:ff:ff:ff:ff
inet 10.10.10.9/24 brd 10.10.10.255 scope global dynamic eth0
valid_lft 84929sec preferred_lft 84929sec
开始配置
[root@test-1 ~]# ip link add vxlan1 type vxlan id 1 dstport 4789 remote 10.10.10.9 local 10.10.10.11 dev eth0
- vxlan1 即为创建的接口名称 ,type 为 vxlan 类型。
- id 即为 VNI。
- dstport 指定 UDP的目的端口,IANA 为vxlan分配的目的端口是 4789。
- remote 和 local ,即远端和本地的IP地址,因为vxlan是MAC-IN-UDP,需要指定外层IP,此处即指。
- dev 本地流量接口。用于 vtep 通信的网卡设备,用来读取 IP 地址。注意这个参数和 local参数含义是相同的,在这里写出来是为了告诉大家有两个参数存在。
创建完成可看到
[root@test-1 ~]# ip addr show type vxlan
3: vxlan1: <BROADCAST,MULTICAST> mtu 1396 qdisc noop state DOWN qlen 1000
link/ether 86:65:ef:3d:a1:e7 brd ff:ff:ff:ff:ff:ff
接口现在还没有地址,也没有开启,接下来进行如下配置
[root@test-1 ~]# ip addr add 192.168.1.3/24 dev vxlan1
[root@test-1 ~]# ip link set vxlan1 up
[root@test-1 ~]# ip addr show type vxlan
3: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1396 qdisc noqueue state UNKNOWN qlen 1000
link/ether 86:65:ef:3d:a1:e7 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.3/24 scope global vxlan1
valid_lft forever preferred_lft forever
vxlan1已经配置完成,之后看一下路由表即vxlan 的 FDB表
#(仅列出vxlan部分)
[root@test-1 ~]# ip route
192.168.1.0/24 dev vxlan1 proto kernel scope link src 192.168.1.3
[root@test-1 ~]# bridge fdb
00:00:00:00:00:00 dev vxlan1 dst 10.10.10.9 via eth0 self permanent
# 即默认vxlan1 对端地址为 10.10.10.9,通过eth0进行报文交换
对test-2进行同样的配置,保证VNI和dstport一致。VNI一致是为了不进行vxlan隔离,
dstport一致是因为IANA 为vxlan分配的目的端口是 4789。
之后在test-1上进行测试连通性
[root@test-1 ~]# ping 192.168.1.4 -c 3
PING 192.168.1.4 (192.168.1.4) 56(84) bytes of data.
64 bytes from 192.168.1.4: icmp_seq=1 ttl=64 time=0.424 ms
64 bytes from 192.168.1.4: icmp_seq=2 ttl=64 time=0.437 ms
64 bytes from 192.168.1.4: icmp_seq=3 ttl=64 time=0.404 ms
--- 192.168.1.4 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.404/0.421/0.437/0.027 ms
场景2:VXLAN + Bridge
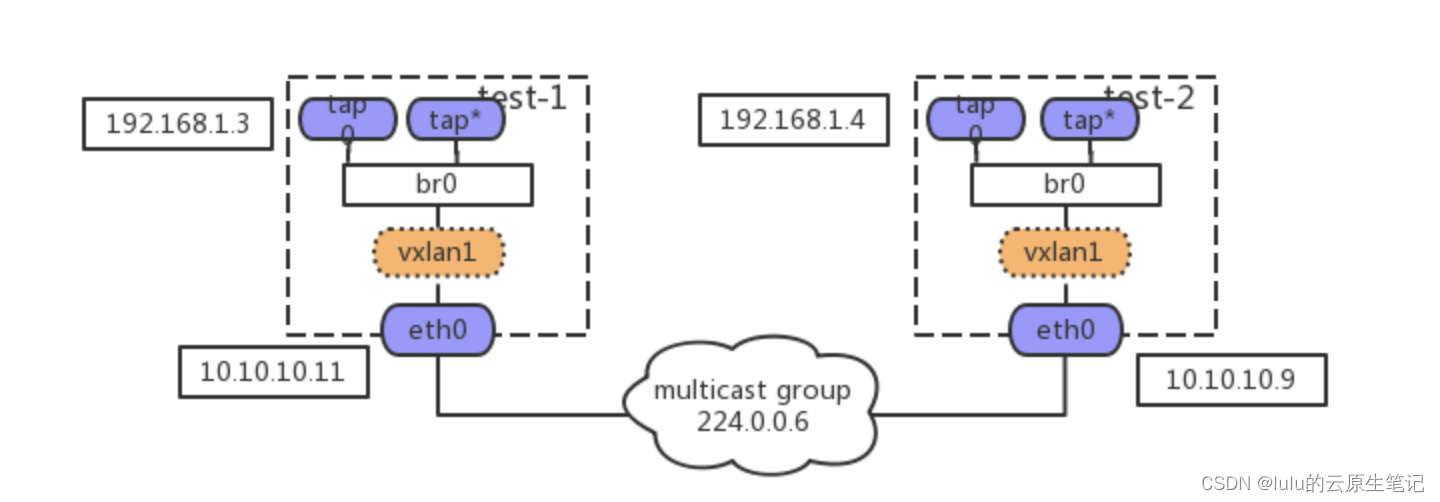
下面用 network namespace来模拟tap(vm接口),进行如下配置
#创建vxlan接口
[root@test-1 ~]# ip link add vxlan1 type vxlan id 2 dstport 4789 group 224.0.0.6 dev eth0
#创建NS
[root@test-1 ~]# ip netns add vm0
[root@test-1 ~]# ip netns exec vm0 ip link set dev lo up
#创建veth 接口,并将其中一个veth口放到 NS中
[root@test-1 ~]# ip link add veth0 type veth peer name veth1
[root@test-1 ~]# ip link set veth0 netns vm0
[root@test-1 ~]# ip netns exec vm0 ip link set veth0 name eth0
[root@test-1 ~]# ip netns exec vm0 ip addr add 192.168.1.3/24 dev eth0
[root@test-1 ~]# ip netns exec vm0 ip link set dev eth0 up
[root@test-1 ~]# ip netns exec vm0 ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
8: eth0@if7: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN qlen 1000
link/ether 9e:ab:18:d5:25:55 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.1.3/24 scope global eth0
valid_lft forever preferred_lft forever
#创建桥,并将vxlan、veth加入桥
[root@test-1 ~]# ip link add br0 type bridge
[root@test-1 ~]# ip link set vxlan1 master br0
[root@test-1 ~]# ip link set vxlan1 up
[root@test-1 ~]# ip link set dev veth1 master br0
[root@test-1 ~]# ip link set dev veth1 up
[root@test-1 ~]# ip link set dev br0 up
[root@test-1 ~]# bridge link
6: vxlan1 state UNKNOWN : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1396 master br0 state forwarding priority 32 cost 100
7: veth1 state UP @(null): <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
其他设备进行类似配置(设备较多可用脚本实现)。利用命令 ip netns exec vm0 ping IP来验证连通性。
此过程为:
- ns eth0 ARP广播,通过veth1到达br0。
- br0上没有二层表,进行学习之后,每个口(除收报文口)进行转发,到达vxlan1。
- vxlan1口fdb表默认走多播,进行外层封装之后从eth0接口发出。
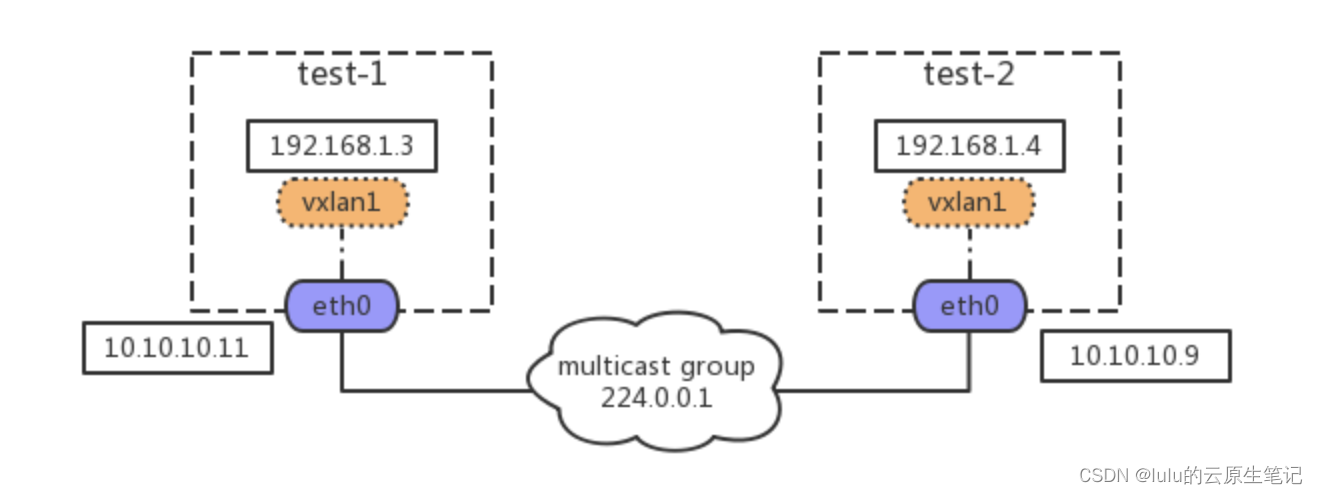
场景3:多播模式的 VXLAN
要组成同一个 vxlan 网络,vtep 必须能感知到彼此的存在。多播组本来的功能就是把网络中的某些节点组成一个虚拟的组,所以 vxlan 最初想到用多播来实现是很自然的事情。拓扑如下
[root@test-1 ~]# ip link add vxlan1 type vxlan id 2 dstport 4789 group 224.0.0.1 dev eth0
[root@test-1 ~]# ip addr add 192.168.1.3/24 dev vxlan1
[root@test-1 ~]# ip link set vxlan1 up
[root@test-1 ~]# ip route
192.168.1.0/24 dev vxlan1 proto kernel scope link src 192.168.1.3
[root@test-1 ~]# bridge fdb
00:00:00:00:00:00 dev vxlan1 dst 224.0.0.1 via eth0 self permanent
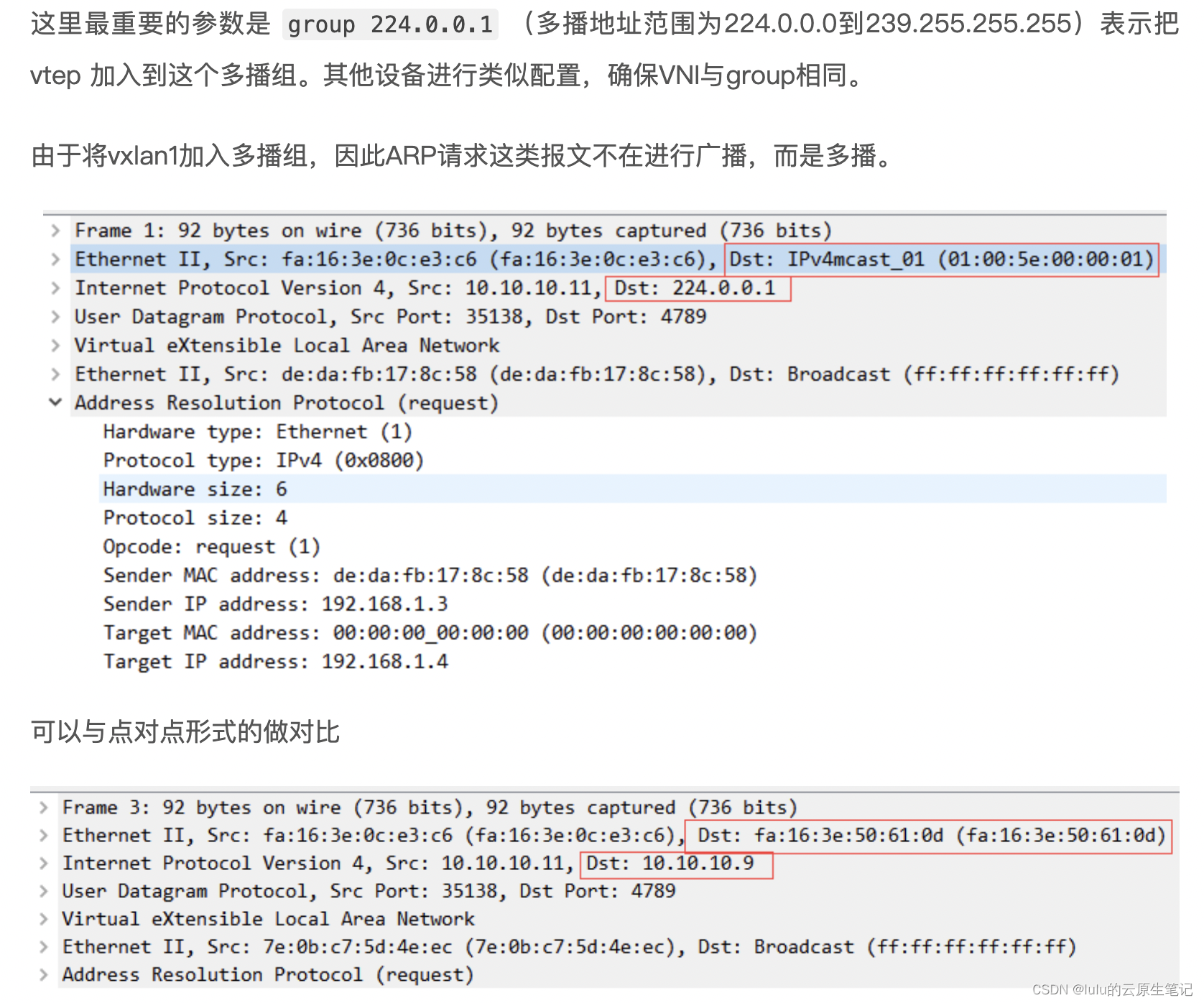
ARP回应依然是单播报文。通信结束之后,查看ARP及fdb表项为
[root@test-1 ~]# ip neigh
192.168.1.4 dev vxlan1 lladdr a6:8b:d5:2d:83:3c STALE
[root@test-1 ~]# bridge fdb
00:00:00:00:00:00 dev vxlan1 dst 224.0.0.1 via eth0 self permanent
a6:8b:d5:2d:83:3c dev vxlan1 dst 10.10.10.9 self
场景4:手动维护 vtep 组

这个问题的解决可以通过手动维护来解决
-
手动维护 vtep 组
经过上面几个实验,我们来思考一下为什么要使用多播。因为对 overlay 网络来说,它的网段范围是分布在多个主机上的,因此传统 ARP 报文的广播无法直接使用。要想做到 overlay 网络的广播,必须把报文发送到所有 vtep 在的节点,这才引入了多播。
如果有一种方法能够不通过多播,能把 overlay 的广播报文发送给所有的 vtep 主机的话,也能达到相同的功能。当然在维护 vtep 网络组之前,必须提前知道哪些 vtep 要组成一个网络,以及这些 vtep 在哪些主机上。
Linux 的 vxlan 模块也提供了这个功能,而且实现起来并不复杂。创建 vtep interface 的时候不使用 remote 或者 group 参数就行:
$ ip link add vxlan0 type vxlan
id 42
dstport 4789
dev enp0s8这个 vtep interface 创建的时候没有指定多播地址,当第一个 ARP 请求报文发送时它也不知道要发送给谁。但是我们可以手动添加默认的 FDB 表项,比如:
$ bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101
$ bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.102这样的话,如果不知道对方 VTEP 的地址,就会往选择默认的表项,发到 192.168.8.101 和 192.168.8.102,相当于手动维护了一个 vtep 的多播组。
在所有的节点的 vtep 上更新对应的 fdb 表项,就能实现 overlay 网络的连通。整个通信流程和多播模式相同,唯一的区别是,vtep 第一次会给所有的组内成员发送单播报文,当然也只有一个 vtep 会做出应答。
使用一些自动化工具,定时更新 FDB 表项,就能动态地维护 VTEP 的拓扑结构。
这个方案解决了在某些 underlay 网络中不能使用多播的问题,但是并没有解决多播的另外一个问题:每次要查找 MAC 地址要发送大量的无用报文,如果 vtep 组节点数量很大,那么每次查询都发送 N 个报文,其中只有一个报文真正有用。
-
手动维护 fdb 表
如果提前知道目的容器 MAC 地址和它所在主机的 IP 地址,也可以通过更新 fdb 表项来减少广播的报文数量。
创建 vtep 的命令:
$ ip link add vxlan0 type vxlan
id 42
dstport 4789
dev enp0s8
nolearning这次我们添加了 nolearning 参数,这个参数告诉 vtep 不要通过收到的报文来学习 fdb 表项的内容,因为我们会自动维护这个列表。
然后可以添加 fdb 表项告诉 vtep 容器 MAC 对应的主机 IP 地址:
$ bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101
$ bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.102
$ bridge fdb append 52:5e:55:58:9a:ab dev vxlan0 dst 192.168.8.101
$ bridge fdb append d6:d9💿0a:a4:28 dev vxlan0 dst 192.168.8.102如果知道了对方的 MAC 地址,vtep 搜索 fdb 表项就知道应该发送到哪个对应的 vtep 了。需要注意是的,这个情况还是需要默认的表项(那些全零的表项),在不知道容器 IP 和 MAC 对应关系的时候通过默认方式发送 ARP 报文去查询对方的 MAC 地址。
需要注意的是,和上一个方法相比,这个方法并没有任何效率上的改进,只是把自动学习 fdb 表项换成了手动维护(当然实际情况一般是自动化程序来维护),第一次发送 ARP 请求还是会往 vtep 组发送大量单播报文。
当时这个方法给了我们很重要的提示:如果实现知道 vxlan 网络的信息,vtep 需要的信息都是可以自动维护的,而不需要学习。
-
手动维护 ARP 表
除了维护 fdb 表,arp 表也是可以维护的。如果能通过某个方式知道容器的 IP 和 MAC 地址对应关系,只要更新到每个节点,就能实现网络的连通。
但是这里有个问题,我们需要维护的是每个容器里面的 ARP 表项,因为最终通信的双方是容器。到每个容器里面(所有的 network namespace)去更新对应的 ARP 表,是件工作量很大的事情,而且容器的创建和删除还是动态的,。linux 提供了一个解决方案,vtep 可以作为 arp 代理,回复 arp 请求,也就是说只要 vtep interface 知道对应的 IP - MAC 关系,在接收到容器发来的 ARP 请求时可以直接作出应答。这样的话,我们只需要更新 vtep interface 上 ARP 表项就行了。
创建 vtep interface 需要加上 proxy 参数:
$ ip link add vxlan0 type vxlan
id 42
dstport 4789
dev enp0s8
nolearning
proxy这条命令和上部分相比多了 proxy 参数,这个参数告诉 vtep 承担 ARP 代理的功能。如果收到 ARP 请求,并且自己知道结果就直接作出应答。
当然我们还是要手动更新 fdb 表项来构建 vtep 组,
$ bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.101
$ bridge fdb append 00:00:00:00:00:00 dev vxlan0 dst 192.168.8.102
$ bridge fdb append 52:5e:55:58:9a:ab dev vxlan0 dst 192.168.8.101
$ bridge fdb append d6:d9💿0a:a4:28 dev vxlan0 dst 192.168.8.102然后,还需要为 vtep 添加 arp 表项,所有要通信容器的 IP - MAC二元组都要加进去。
$ ip neigh add 10.20.1.3 lladdr d6:d9💿0a:a4:28 dev vxlan0
$ ip neigh add 10.20.1.4 lladdr 52:5e:55:58:9a:ab dev vxlan0在要通信的所有节点配置完之后,容器就能互相 ping 通。当容器要访问彼此,并且第一次发送 ARP 请求时,这个请求并不会发给所有的 vtep,而是当前由当前 vtep 做出应答,大大减少了网络上的报文。
借助自动化的工具做到实时的表项(fdb 和 arp)更新,这种方法就能很高效地实现 overlay 网络的通信。
-
动态更新 arp 和 fdb 表项
尽管前一种方法通过动态更新 fdb 和 arp 表避免多余的网络报文,但是还有一个的问题:为了能够让所有的容器正常工作,所有可能会通信的容器都必须提前添加到 ARP 和 fdb 表项中。但并不是网络上所有的容器都会互相通信,所以添加的有些表项(尤其是 ARP 表项)是用不到的。
Linux 提供了另外一种方法,内核能够动态地通知节点要和哪个容器通信,应用程序可以订阅这些事件,如果内核发现需要的 ARP 或者 fdb 表项不存在,会发送事件给订阅的应用程序,这样应用程序从中心化的控制拿到这些信息来更新表项,做到更精确的控制。
要收到 L2(fdb)miss,必须要满足几个条件:
- 目的 MAC 地址未知,也就是没有对应的 fdb 表项
- fdb 中没有全零的表项,也就是说默认规则
- 目的 MAC 地址不是多播或者广播地址
要实现这种功能,创建 vtep 的时候需要加上额外的参数:
$ ip link add vxlan0 type vxlan
id 42
dstport 4789
dev enp0s8
nolearning
proxy
l2miss
l3miss这次多了两个参数 l2miss 和 l3miss:
- l2miss:如果设备找不到 MAC 地址需要的 vtep 地址,就发送通知事件
- l3miss:如果设备找不到需要 IP 对应的 MAC 地址,就发送通知事件
ip monitor 命令能做到这点,监听某个 interface 的事件,具体用法请参考 man 手册。
root@node0:~# ip monitor all dev vxlan0
如果从本节点容器 ping 另外一个节点的容器,就先发生 l3 miss,这是 l3miss 的通知事件:root@node0:~# ip monitor all dev vxlan0
[nsid current]miss 10.20.1.3 STALE
l3miss 是说这个 IP 地址,vtep 不知道它对应的 MAC 地址,因此要手动添加 arp 记录:$ ip neigh replace 10.20.1.3
lladdr b2:ee:aa:42:8b:0b
dev vxlan0
nud reachable上面这条命令设置的 nud reachable 参数意思是,这条记录有一个超时时间,系统发现它无效一段时间会自动删除。这样的好处是,不需要手动去删除它,删除后需要通信内核会再次发送通知事件。 nud 是 Neighbour Unreachability Detection 的缩写, 当然根据需要这个参数也可以设置成其他值,比如 permanent,表示这个记录永远不会过时,系统不会检查它是否正确,也不会删除它,只有管理员也能对它进行修改。
这时候还是不能正常通信,接着会出现 l2miss 的通知事件:
root@node0:~# ip monitor all dev vxlan0
[nsid current]miss lladdr b2:ee:aa:42:8b:0b STALE类似的,这个事件是说不知道这个容器的 MAC 地址在哪个节点上,所以要手动添加 fdb 记录:
root@node0:~# bridge fdb add b2:ee:aa:42:8b:0b dst 192.168.8.101 dev vxlan0
在通信的另一台机器上执行响应的操作,就会发现两者能 ping 通了。















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









